
ZooKeeper集群相关问题处理大全

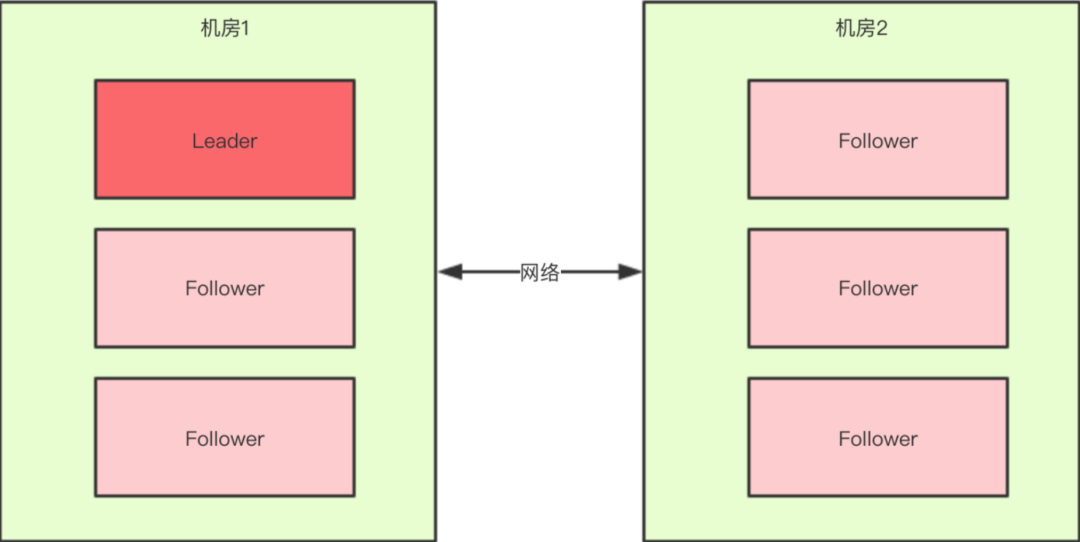

假死:由于心跳超时(网络原因导致的)认为Leader死了,但其实Leader还存活着。
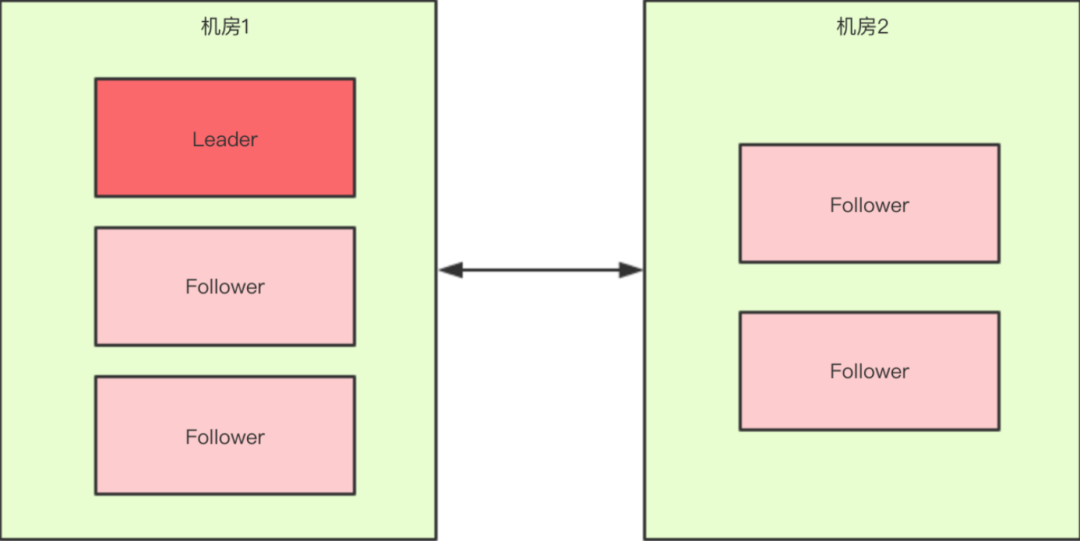
脑裂:由于假死会发起新的Leader选举,选举出一个新的Leader,但旧的Leader网络又通了,导致出现了两个Leader ,有的客户端连接到老的Leader,而有的客户端则连接到新的Leader。
Quorums(法定人数)方式:比如3个节点的集群,Quorums = 2,也就是说集群可以容忍1个节点失效,这时候还能选举出1个lead,集群还可用。比如4个节点的集群,它的Quorums = 3,Quorums要超过3,相当于集群的容忍度还是1,如果2个节点失效,那么整个集群还是无效的。这是ZooKeeper防止“脑裂”默认采用的方法。
采用Redundant communications(冗余通信)方式:集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
Fencing(共享资源)方式:比如能看到共享资源就表示在集群中,能够获得共享资源的锁的就是Leader,看不到共享资源的,就不在集群中。
仲裁机制方式。
启动磁盘锁定方式。
集群中最少的节点数用来选举Leader保证集群可用。
通知客户端数据已经安全保存前集群中最少数量的节点数已经保存了该数据。一旦这些节点保存了该数据,客户端将被通知已经安全保存了,可以继续其他任务。而集群中剩余的节点将会最终也保存了该数据。
添加冗余的心跳线,例如双线条线,尽量减少“裂脑”发生机会。
启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下 参考IP,不通则表明断点就出在本端,不仅"心跳"、还兼对外"服务"的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
end
推荐阅读:
如有收获,点个在看,诚挚感谢