
服务端大量处于 TIME_WAIT/CLOSE_WAIT 状态连接的原因
大家好,我是小林。
之前有位读者面字节被问到两个很经典的 TCP 问题:
第一个问题:服务端大量处于 TIME_WAIT 状态连接的原因。
第二个问题:服务端大量处于 CLOSE_WAIT 状态连接的原因。
这两个问题在面试中很常问,主要也是因为在工作中也很常遇到这个问题。
这次,我们就来聊聊这两个问题。

服务端出现大量 TIME_WAIT 状态的原因有哪些?
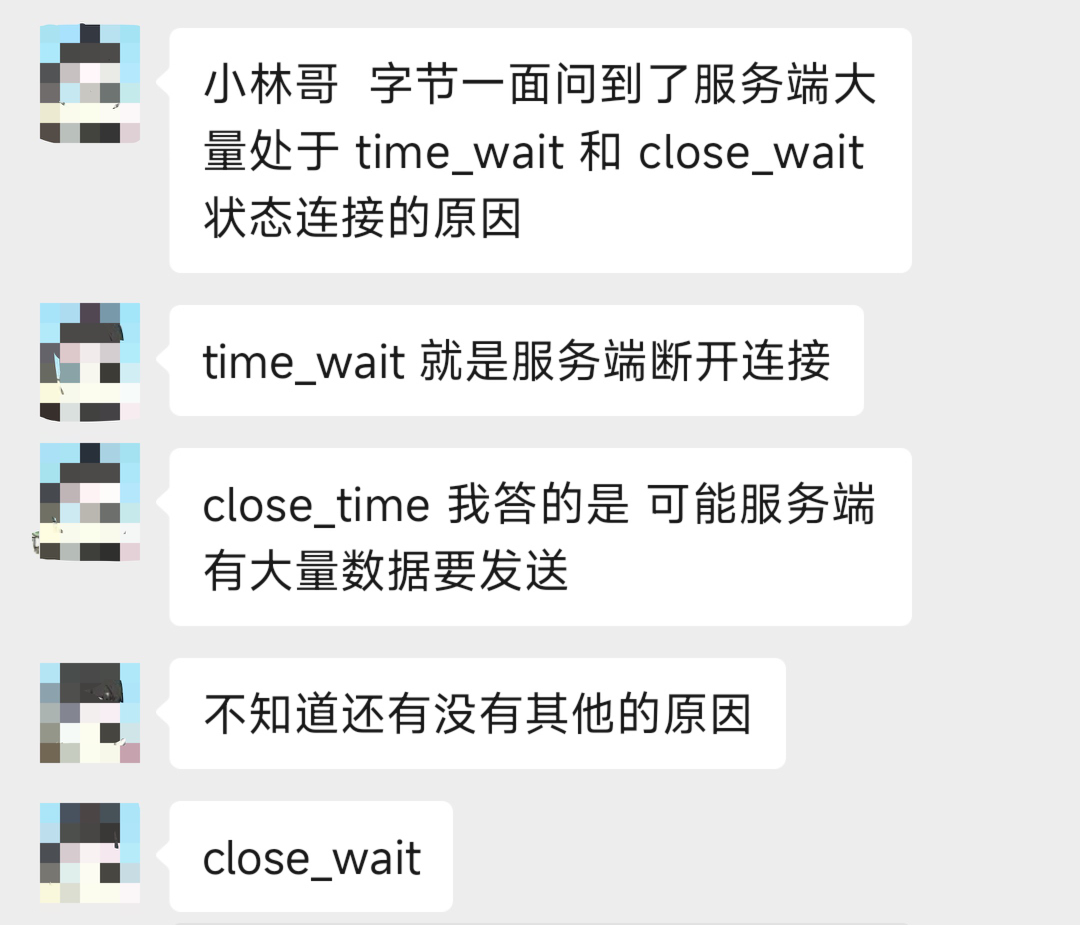
我们先来看一下 TCP 四次挥手的流程吧,看看 TIME_WAIT 状态发生在哪一个阶段。
下面这个图,是由「客户端」作为「主动关闭方」的 TCP 四次挥手的流程。
从上面我们可以知道,TIME_WAIT 状态是「主动关闭连接方」才会出现的状态。而且 TIME_WAIT 状态会持续 2MSL 时间才会进入到 close 状态。在 Linux 上 2MSL 的时长是 60 秒,也就是说停留在 TIME_WAIT 的时间为固定的 60 秒。
为什么需要 TIME_WAIT 状态?(老八股文了,帮大家复习一波)主要有两个原因:
保证「被动关闭连接」的一方,能被正确的关闭。TCP 协议在关闭连接的四次挥手中,在主动关闭方发送的最后一个 ACK 报文,有可能丢失,这时被动方会重新发 FIN 报文, 如果这时主动方处于 CLOSE 状态 ,就会响应 RST 报文而不是 ACK 报文。所以主动方要处于 TIME_WAIT 状态,而不能是 CLOSE。 防止历史连接中的数据,被后面相同四元组的连接错误的接收。TCP 报文可能由于路由器异常而 “迷路”,在迷途期间,TCP 发送端可能因确认超时而重发这个报文,迷途的报文在路由器修复后也会被送到最终目的地,这个原来的迷途报文就称为 lost duplicate。在关闭一个 TCP 连接后,马上又重新建立起一个相同的 IP 地址和端口之间的 TCP 连接,后一个连接被称为前一个连接的化身,那么有可能出现这种情况,前一个连接的迷途重复报文在前一个连接终止后出现,从而被误解成从属于新的化身。为了避免这个情 况, TIME_WAIT 状态需要持续 2MSL,因为这样就可以保证当成功建立一个 TCP 连接的时候,来自连接先前化身的重复报文已经在网络中消逝。
很多人误解以为只有客户端才会有 TIME_WAIT 状态,这是不对的。TCP 是全双工协议,哪一方都可以先关闭连接,所以哪一方都可能会有 TIME_WAIT 状态。
总之记住,谁先关闭连接的,它就是主动关闭方,那么 TIME_WAIT 就会出现在主动关闭方。
什么场景下服务端会主动断开连接呢?
如果服务端出现大量的 TIME_WAIT 状态的 TCP 连接,就是说明服务端主动断开了很多 TCP 连接。
问题来了,什么场景下服务端会主动断开连接呢?
第一个场景:HTTP 没有使用长连接 第二个场景:HTTP 长连接超时 第三个场景:HTTP 长连接的请求数量达到上限
接下来,分别介绍下。
第一个场景:HTTP 没有使用长连接
我们先来看看 HTTP 长连接(Keep-Alive)机制是怎么开启的。
在 HTTP/1.0 中默认是关闭的,如果浏览器要开启 Keep-Alive,它必须在请求的 header 中添加:
Connection: Keep-Alive
然后当服务器收到请求,作出回应的时候,它也被添加到响应中 header 里:
Connection: Keep-Alive
这样做,TCP 连接就不会中断,而是保持连接。当客户端发送另一个请求时,它会使用同一个 TCP 连接。这一直继续到客户端或服务器端提出断开连接。
从 HTTP/1.1 开始, 就默认是开启了 Keep-Alive,现在大多数浏览器都默认是使用 HTTP/1.1,所以 Keep-Alive 都是默认打开的。一旦客户端和服务端达成协议,那么长连接就建立好了。
如果要关闭 HTTP Keep-Alive,需要在 HTTP 请求或者响应的 header 里添加 Connection:close 信息,也就是说,只要客户端和服务端任意一方的 HTTP header 中有 Connection:close 信息,那么就无法使用 HTTP 长连接的机制。
关闭 HTTP 长连接机制后,每次请求都要经历这样的过程:建立 TCP -> 请求资源 -> 响应资源 -> 释放连接,那么此方式就是 HTTP 短连接,如下图:
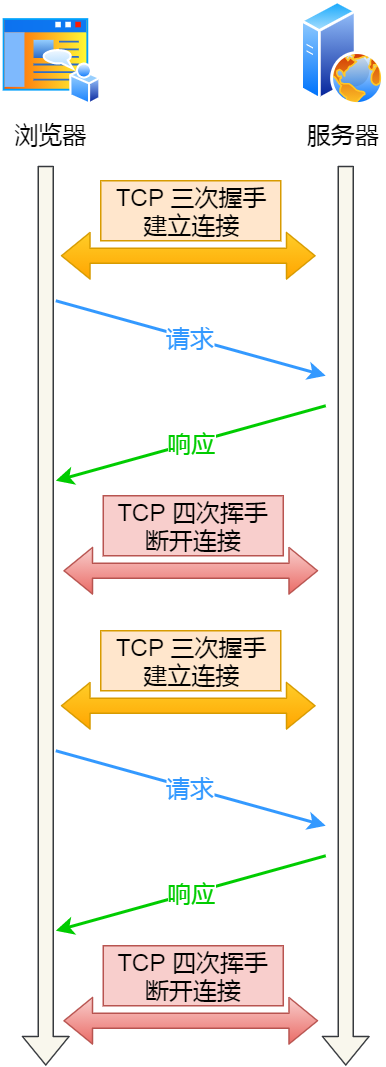
在前面我们知道,只要任意一方的 HTTP header 中有 Connection:close 信息,就无法使用 HTTP 长连接机制,这样在完成一次 HTTP 请求/处理后,就会关闭连接。
问题来了,这时候是客户端还是服务端主动关闭连接呢?
在 RFC 文档中,并没有明确由谁来关闭连接,请求和响应的双方都可以主动关闭 TCP 连接。
不过,根据大多数 Web 服务的实现,不管哪一方禁用了 HTTP Keep-Alive,都是由服务端主动关闭连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
客户端禁用了 HTTP Keep-Alive,服务端开启 HTTP Keep-Alive,谁是主动关闭方?
当客户端禁用了 HTTP Keep-Alive,这时候 HTTP 请求的 header 就会有 Connection:close 信息,这时服务端在发完 HTTP 响应后,就会主动关闭连接。
为什么要这么设计呢?HTTP 是请求-响应模型,发起方一直是客户端,HTTP Keep-Alive 的初衷是为客户端后续的请求重用连接,如果我们在某次 HTTP 请求-响应模型中,请求的 header 定义了 connection:close 信息,那不再重用这个连接的时机就只有在服务端了,所以我们在 HTTP 请求-响应这个周期的「末端」关闭连接是合理的。
客户端开启了 HTTP Keep-Alive,服务端禁用了 HTTP Keep-Alive,谁是主动关闭方?
当客户端开启了 HTTP Keep-Alive,而服务端禁用了 HTTP Keep-Alive,这时服务端在发完 HTTP 响应后,服务端也会主动关闭连接。
为什么要这么设计呢?在服务端主动关闭连接的情况下,只要调用一次 close() 就可以释放连接,剩下的工作由内核 TCP 栈直接进行了处理,整个过程只有一次 syscall;如果是要求 客户端关闭,则服务端在写完最后一个 response 之后需要把这个 socket 放入 readable 队列,调用 select / epoll 去等待事件;然后调用一次 read() 才能知道连接已经被关闭,这其中是两次 syscall,多一次用户态程序被激活执行,而且 socket 保持时间也会更长。
因此,当服务端出现大量的 TIME_WAIT 状态连接的时候,可以排查下是否客户端和服务端都开启了 HTTP Keep-Alive,因为任意一方没有开启 HTTP Keep-Alive,都会导致服务端在处理完一个 HTTP 请求后,就主动关闭连接,此时服务端上就会出现大量的 TIME_WAIT 状态的连接。
针对这个场景下,解决的方式也很简单,让客户端和服务端都开启 HTTP Keep-Alive 机制。
第二个场景:HTTP 长连接超时
HTTP 长连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
HTTP 长连接可以在同一个 TCP 连接上接收和发送多个 HTTP 请求/应答,避免了连接建立和释放的开销。
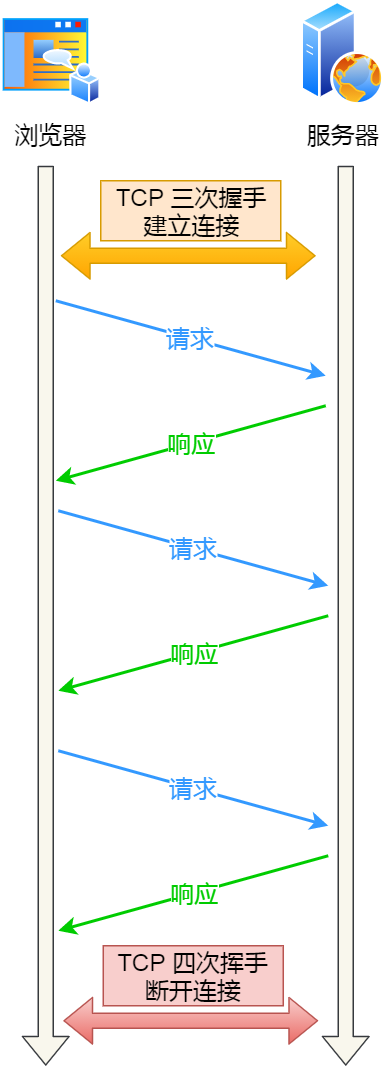
可能有的同学会问,如果使用了 HTTP 长连接,如果客户端完成一个 HTTP 请求后,就不再发起新的请求,此时这个 TCP 连接一直占用着不是挺浪费资源的吗?
对没错,所以为了避免资源浪费的情况,web 服务软件一般都会提供一个参数,用来指定 HTTP 长连接的超时时间,比如 nginx 提供的 keepalive_timeout 参数。
假设设置了 HTTP 长连接的超时时间是 60 秒,nginx 就会启动一个「定时器」,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,nginx 就会触发回调函数来关闭该连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
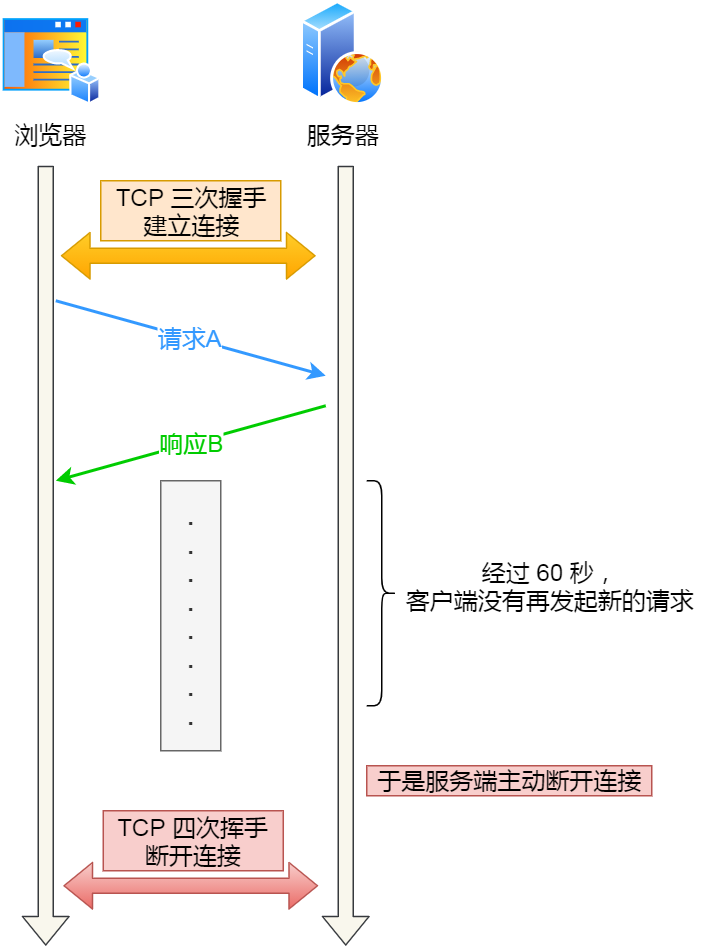
当服务端出现大量 TIME_WAIT 状态的连接时,如果现象是有大量的客户端建立完 TCP 连接后,很长一段时间没有发送数据,那么大概率就是因为 HTTP 长连接超时,导致服务端主动关闭连接,产生大量处于 TIME_WAIT 状态的连接。
可以往网络问题的方向排查,比如是否是因为网络问题,导致客户端发送的数据一直没有被服务端接收到,以至于 HTTP 长连接超时。
第三个场景:HTTP 长连接的请求数量达到上限
Web 服务端通常会有个参数,来定义一条 HTTP 长连接上最大能处理的请求数量,当超过最大限制时,就会主动关闭连接。
比如 nginx 的 keepalive_requests 这个参数,这个参数是指一个 HTTP 长连接建立之后,nginx 就会为这个连接设置一个计数器,记录这个 HTTP 长连接上已经接收并处理的客户端请求的数量。如果达到这个参数设置的最大值时,则 nginx 会主动关闭这个长连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
keepalive_requests 参数的默认值是 100 ,意味着每个 HTTP 长连接最多只能跑 100 次请求,这个参数往往被大多数人忽略,因为当 QPS (每秒请求数) 不是很高时,默认值 100 凑合够用。
但是,对于一些 QPS 比较高的场景,比如超过 10000 QPS,甚至达到 30000 , 50000 甚至更高,如果 keepalive_requests 参数值是 100,这时候就 nginx 就会很频繁地关闭连接,那么此时服务端上就会出大量的 TIME_WAIT 状态。
针对这个场景下,解决的方式也很简单,调大 nginx 的 keepalive_requests 参数就行。
TIME_WAIT 状态过多有什么危害?
过多的 TIME-WAIT 状态主要的危害有两种:
第一是占用系统资源,比如文件描述符、内存资源、CPU 资源等; 第二是占用端口资源,端口资源也是有限的,一般可以开启的端口为 32768~61000,也可以通过net.ipv4.ip_local_port_range参数指定范围。
客户端和服务端 TIME_WAIT 过多,造成的影响是不同的。
如果客户端(主动发起关闭连接方)的 TIME_WAIT 状态过多,占满了所有端口资源,那么就无法对「目的 IP+ 目的 PORT」都一样的服务端发起连接了,但是被使用的端口,还是可以继续对另外一个服务端发起连接的。具体可以看我这篇文章:客户端的端口可以重复使用吗?
因此,客户端(发起连接方)都是和「目的 IP+ 目的 PORT 」都一样的服务端建立连接的话,当客户端的 TIME_WAIT 状态连接过多的话,就会受端口资源限制,如果占满了所有端口资源,那么就无法再跟「目的 IP+ 目的 PORT」都一样的服务端建立连接了。
不过,即使是在这种场景下,只要连接的是不同的服务端,端口是可以重复使用的,所以客户端还是可以向其他服务端发起连接的,这是因为内核在定位一个连接的时候,是通过四元组(源IP、源端口、目的IP、目的端口)信息来定位的,并不会因为客户端的端口一样,而导致连接冲突。
如果服务端(主动发起关闭连接方)的 TIME_WAIT 状态过多,并不会导致端口资源受限,因为服务端只监听一个端口,而且由于一个四元组唯一确定一个 TCP 连接,因此理论上服务端可以建立很多连接,但是 TCP 连接过多,会占用系统资源,比如文件描述符、内存资源、CPU 资源等。
如何优化 TIME_WAIT 状态?
这里给出优化 TIME-WAIT 的几个方式,都是有利有弊:
打开 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_timestamps 选项; net.ipv4.tcp_max_tw_buckets 程序中使用 SO_LINGER ,应用强制使用 RST 关闭。
方式一:net.ipv4.tcp_tw_reuse 和 tcp_timestamps
开启 tcp_tw_reuse,则可以复用处于 TIME_WAIT 的 socket 为新的连接所用。
有一点需要注意的是,tcp_tw_reuse 功能只能用客户端(连接发起方),因为开启了该功能,在调用 connect() 函数时,内核会随机找一个 time_wait 状态超过 1 秒的连接给新的连接复用。
net.ipv4.tcp_tw_reuse = 1
使用这个选项,还有一个前提,需要打开对 TCP 时间戳的支持,即
net.ipv4.tcp_timestamps=1(默认即为 1)
这个时间戳的字段是在 TCP 头部的「选项」里,它由一共 8 个字节表示时间戳,其中第一个 4 字节字段用来保存发送该数据包的时间,第二个 4 字节字段用来保存最近一次接收对方发送到达数据的时间。
由于引入了时间戳,可以使得重复的数据包会因为时间戳过期被自然丢弃,因此 TIME_WAIT 状态才可以被复用。
方式二:net.ipv4.tcp_max_tw_buckets
这个值默认为 18000,当系统中处于 TIME_WAIT 的连接一旦超过这个值时,系统就会将后面的 TIME_WAIT 连接状态重置,这个方法比较暴力。
net.ipv4.tcp_max_tw_buckets = 18000
方式三:程序中使用 SO_LINGER
我们可以通过设置 socket 选项,来设置调用 close 关闭连接行为。
struct linger so_linger;
so_linger.l_onoff = 1;
so_linger.l_linger = 0;
setsockopt(s, SOL_SOCKET, SO_LINGER, &so_linger,sizeof(so_linger));
如果l_onoff为非 0, 且l_linger值为 0,那么调用close后,会立该发送一个RST标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了TIME_WAIT状态,直接关闭。
但这为跨越TIME_WAIT状态提供了一个可能,不过是一个非常危险的行为,不值得提倡。
前面介绍的方法都是试图越过 TIME_WAIT状态的,这样其实不太好。虽然 TIME_WAIT 状态持续的时间是有一点长,显得很不友好,但是它被设计来就是用来避免发生乱七八糟的事情。
《UNIX网络编程》一书中却说道:TIME_WAIT 是我们的朋友,它是有助于我们的,不要试图避免这个状态,而是应该弄清楚它。
如果服务端要避免过多的 TIME_WAIT 状态的连接,就永远不要主动断开连接,让客户端去断开,由分布在各处的客户端去承受 TIME_WAIT。
服务端出现大量 CLOSE_WAIT 状态的原因有哪些?
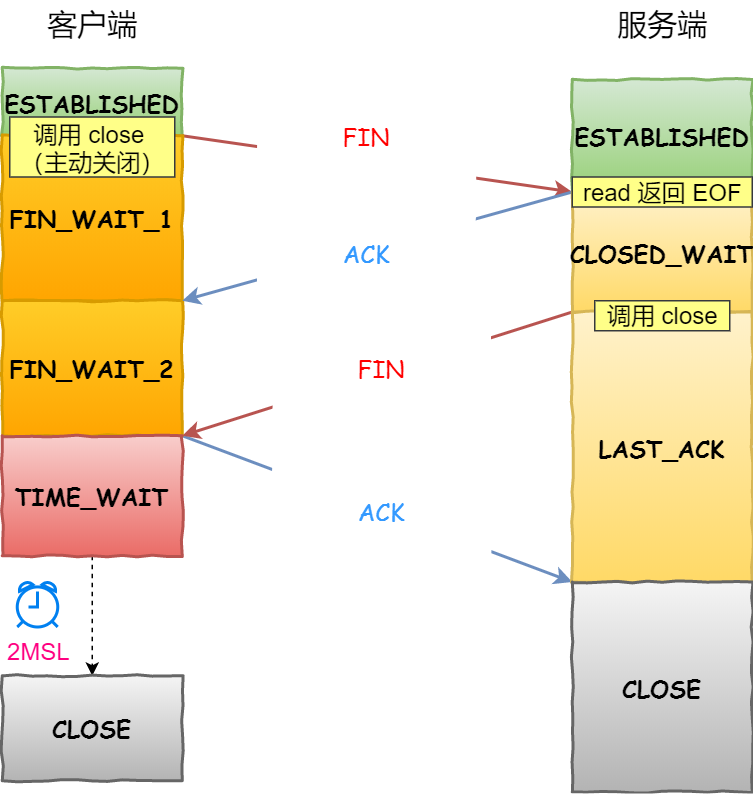
还是拿这张图:
从上面这张图我们可以得知,CLOSE_WAIT 状态是「被动关闭方」才会有的状态,而且如果「被动关闭方」没有调用 close 函数关闭连接,那么就无法发出 FIN 报文,从而无法使得 CLOSE_WAIT 状态的连接转变为 LAST_ACK 状态。
所以,当服务端出现大量 CLOSE_WAIT 状态的连接的时候,说明服务端的程序没有调用 close 函数关闭连接。
那什么情况会导致服务端的程序没有调用 close 函数关闭连接?这时候通常需要排查代码。
我们先来分析一个普通的 TCP 服务端的流程:
创建服务端 socket,bind 绑定端口、listen 监听端口 将服务端 socket 注册到 epoll epoll_wait 等待连接到来,连接到来时,调用 accpet 获取已连接的 socket 将已连接的 socket 注册到 epoll epoll_wait 等待事件发生 对方连接关闭时,我方调用 close
可能导致服务端没有调用 close 函数的原因,如下。
第一个原因:第 2 步没有做,没有将服务端 socket 注册到 epoll,这样有新连接到来时,服务端没办法感知这个事件,也就无法获取到已连接的 socket,那服务端自然就没机会对 socket 调用 close 函数了。
不过这种原因发生的概率比较小,这种属于明显的代码逻辑 bug,在前期 read view 阶段就能发现的了。
第二个原因:第 3 步没有做,有新连接到来时没有调用 accpet 获取该连接的 socket,导致当有大量的客户端主动断开了连接,而服务端没机会对这些 socket 调用 close 函数,从而导致服务端出现大量 CLOSE_WAIT 状态的连接。
发生这种情况可能是因为服务端在执行 accpet 函数之前,代码卡在某一个逻辑或者提前抛出了异常。
第三个原因:第 4 步没有做,通过 accpet 获取已连接的 socket 后,没有将其注册到 epoll,导致后续收到 FIN 报文的时候,服务端没办法感知这个事件,那服务端就没机会调用 close 函数了。
发生这种情况可能是因为服务端在将已连接的 socket 注册到 epoll 之前,代码卡在某一个逻辑或者提前抛出了异常。之前看到过别人解决 close_wait 问题的实践文章,感兴趣的可以看看:一次 Netty 代码不健壮导致的大量 CLOSE_WAIT 连接原因分析
第四个原因:第 6 步没有做,当发现客户端关闭连接后,服务端没有执行 close 函数,可能是因为代码漏处理,或者是在执行 close 函数之前,代码卡在某一个逻辑,比如发生死锁等等。
可以发现,当服务端出现大量 CLOSE_WAIT 状态的连接的时候,通常都是代码的问题,这时候我们需要针对具体的代码一步一步的进行排查和定位,主要分析的方向就是服务端为什么没有调用 close。
▲ 点击上方卡片关注K8s技术圈,掌握前沿云原生技术