
Redis 实战篇:Geo 算法教你邂逅附近女神
码老湿,阅读了你的巧用数据类型实现亿级数据统计之后,我学会了如何游刃有余的使用不同的数据类型(String、Hash、List、Set、Sorted Set、HyperLogLog、Bitmap)去解决不同场景的统计问题。
产品经理说他有一个 idea,为广大少男少女提供一个连接彼此的机会。
让处于这最美的年龄的少男少女能在每一个十二时辰里能邂逅到那个 Ta。
所以就想开发一款 App,用户登陆后能发现附近的那个 Ta,连接彼此。
我该如何实现发现附近的人?我也希望通过这个 App邂逅女神……
记忆中,一个下班的夜晚,她从人群中轻盈的移动着,那高挑苗条的身材像漂浮在空间中的一个飘逸的音符。她的眼睛充满清澈的阳光和活力,她的双眸中印着银河系的星光。
开篇寄语
“多锻炼自己的表达能力,特别是在工作中。很多人说「干活的不如那些做 PPT 的」,实际上老板都不傻,为何他们会更认可那些做 PPT 的?
因为他们从老板的角度考虑问题,对他而言,需要的是一个「解决方案」。多从一个创造者的视角去考虑问题,而不是局限在用程序员的视角考虑问题;
多想一下这个东西到底给人提供什么价值,而不是「我要怎么实现它」。当然,怎么实现是必须的,但通常不是最重要的。
”
什么是面向 LBS 应用
经纬度是经度与纬度的合称组成一个坐标系统。又称为地理坐标系统,它是一种利用三度空间的球面来定义地球上的空间的球面坐标系统,能够标示地球上的任何一个位置(小数点后7位,精度可以到1厘米)。
经度的范围在 (-180, 180],纬度的范围 在(-90, 90],纬度正负以赤道为界,北正南负,经度正负以本初子午线 (英国格林尼治天文台) 为界,东正西负。
附近的人 也就是常说的 LBS (Location Based Services,基于位置服务),它围绕用户当前地理位置数据而展开的服务,为用户提供精准的邂逅服务。
附近的人核心思想如下:
以 “我” 为中心,搜索附近的 Ta; 以 “我” 当前的地理位置为准,计算出别人和 “我” 之间的距离; 按 “我” 与别人距离的远近排序,筛选出离我最近的用户。
MySQL 实现
“计算「附近的人」,通过一个坐标计算这个坐标附近的其他数据,按照距离排序,如何下手呢?
”
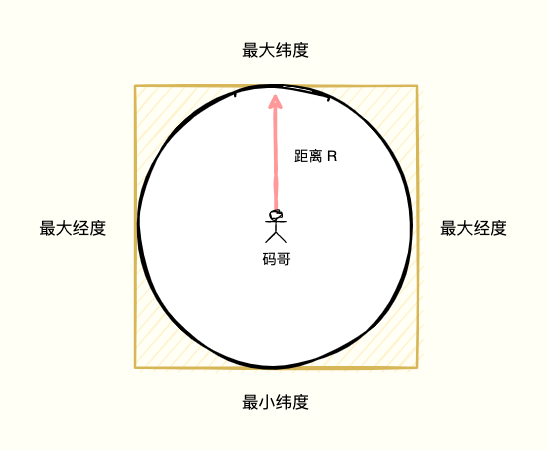
以用户为中心,给定一个 1000 米作为半径画圆,那么圆形区域内的用户就是我们想要邂逅的「附近的人」。
将经纬度存储到 MySQL:
CREATE TABLE `nearby_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL COMMENT '名称',
`longitude` double DEFAULT NULL COMMENT '经度',
`latitude` double DEFAULT NULL COMMENT '纬度',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
“可是总不能遍历所有的「女神」经纬度与自己的经纬度数据计算在根据距离排序,这个计算量也太大了。
”
我们可以通过区域来过滤出有限「女神」坐标数据,再对矩形区域内的数据进行全量距离计算再排序,这样计算量明显降低。
“如何划分矩形区域呢?
”
在圆形外套上一个正方形,根据用户经、纬度的最大最小值(经、纬度 + 距离),作为筛选条件过滤数据,就很容易将正方形内的「女神」信息搜索出来。
“多出来的一些区域咋办?
”
多出来的这部分区域内的用户,到圆点的距离一定比圆的半径要大,那么我们就计算用户中心点与正方形内所有用户的距离,筛选出所有距离小于等于半径的用户,圆形区域内的所用户即符合要求的附近的人。
为了满足高性能的矩形区域算法,数据表需要在经纬度坐标加上复合索引 (longitude, latitude),这样可以最大优化查询性能。
实战
根据经纬度和距离获取外接矩形最大、最小经纬度以及根据经纬度计算距离使用了一个第三方类库:
<dependency>
<groupId>com.spatial4j</groupId>
<artifactId>spatial4j</artifactId>
<version>0.5</version>
</dependency>
获取到外接矩形后,以矩形的最大最小经、纬度值搜索正方形区域内的用户,再剔除超过指定距离的用户,就是最终的附近的人。
/**
* 获取附近 x 米的人
*
* @param distance 搜索距离范围 单位km
* @param userLng 当前用户的经度
* @param userLat 当前用户的纬度
*/
public String nearBySearch(double distance, double userLng, double userLat) {
//1.获取外接正方形
Rectangle rectangle = getRectangle(distance, userLng, userLat);
//2.获取位置在正方形内的所有用户
List<User> users = userMapper.selectUser(rectangle.getMinX(), rectangle.getMaxX(), rectangle.getMinY(), rectangle.getMaxY());
//3.剔除半径超过指定距离的多余用户
users = users.stream()
.filter(a -> getDistance(a.getLongitude(), a.getLatitude(), userLng, userLat) <= distance)
.collect(Collectors.toList());
return JSON.toJSONString(users);
}
// 获取外接矩形
private Rectangle getRectangle(double distance, double userLng, double userLat) {
return spatialContext.getDistCalc()
.calcBoxByDistFromPt(spatialContext.makePoint(userLng, userLat),
distance * DistanceUtils.KM_TO_DEG, spatialContext, null);
}
/***
* 球面中,两点间的距离
* @param longitude 经度1
* @param latitude 纬度1
* @param userLng 经度2
* @param userLat 纬度2
* @return 返回距离,单位km
*/
private double getDistance(Double longitude, Double latitude, double userLng, double userLat) {
return spatialContext.calcDistance(spatialContext.makePoint(userLng, userLat),
spatialContext.makePoint(longitude, latitude)) * DistanceUtils.DEG_TO_KM;
}
由于用户间距离的排序是在业务代码中实现的,可以看到SQL语句也非常的简单。
SELECT * FROM nearby_user
WHERE 1=1
AND (longitude BETWEEN #{minlng} AND #{maxlng})
AND (latitude BETWEEN #{minlat} AND #{maxlat})
但是数据库查询性能毕竟有限,如果「附近的人」查询请求非常多,在高并发场合,这可能并不是一个很好的方案。
尝试 Redis Hash 未果
我们一起分析下 LBS 数据的特点:
每个「女神」都有一个 ID 编号,每个ID 对应着经纬度信息。 「宅男」登陆 app获取「心动女生」的时候,app根据「宅男」的经纬度查找附近的「女神」。获取到位置符合的「女神」ID 列表后,再从数据库获取 ID 对应的「女神」信息返回用户。
“数据特点就是一个女神(用户)对应着一组经纬度,让我想到了 Redis 的 Hash 结构。也就是一个 key(女神 ID) 对应着 一个 value(经纬度)。
”
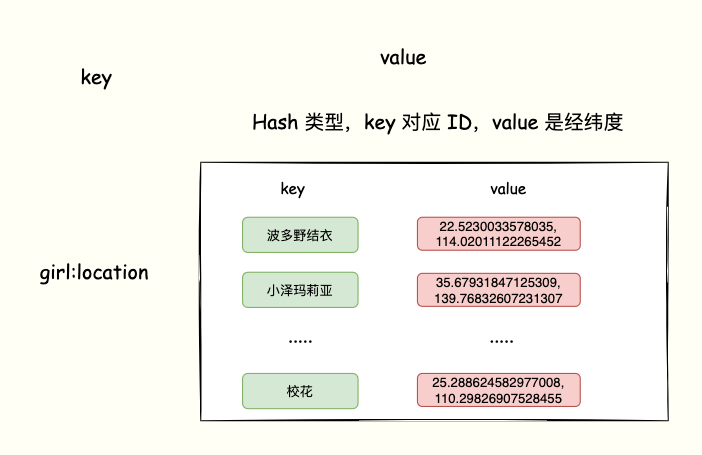
Hash看起来好像可以实现,但是 LBS 应用除了记录经纬度以外,还需要对 Hash 集合中的数据进行范围查询,根据经纬度换算成距离排序。
而 Hash 集合的数据是无序的,显然不可取。
Sorted Set 初见端倪
“Sorted Set 类型是是否合适呢?因为它可以排序。
”
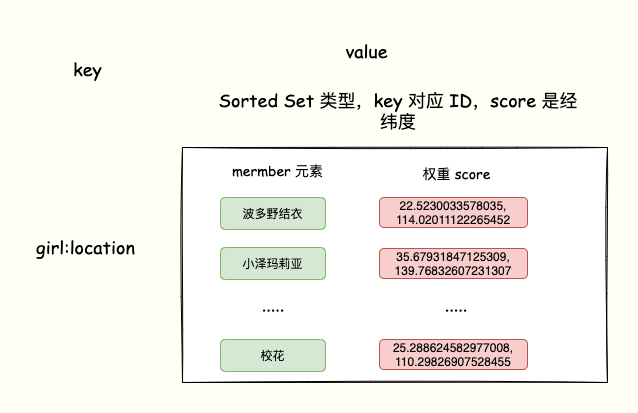
Sorted Set 类型也是一个 key对应一个 value,key元素内容,而value `就是该元素的权重分数。
Sorted Set可以根据元素的权重分数对元素排序,这样看起来就满足我们的需求了。
比如,Sorted Set 的元素是「女神ID」,元素对应的权重 score 是经纬度信息。
“问题来了,Sorted Set 元素的权重值是一个浮点数,经纬度是经度、纬度两个值,咋办呢?能不能将经纬度转换成一个浮点数呢?
”
思路对了,为了实现对经纬度比较,Redis 采用业界广泛使用的 GeoHash 编码,分别对经度和纬度编码,最后再把经纬度各自的编码组合成一个最终编码。
这样就实现了将经纬度转换成一个值,而 Redis 的 GEO 类型的底层数据结构用的就是 Sorted Set来实现。
我们来看下 GeoHash 如何将经纬度编码的。
GEOHash 编码
“关于 GeoHash 可参考 :https://en.wikipedia.org/wiki/Geohash
”
GeoHash算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。
当我们想要计算「附近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行了。
GeoHash 编码会把一个经度值编码成一个 N 位的二进制值,我们来对经度范围[-180,180]做 N 次的二分区操作,其中 N 可以自定义。
在进行第一次二分区时,经度范围[-180,180]会被分成两个子区间:[-180,0) 和[0,180](我称之为左、右分区)。
此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果是落在左分区,我们就用 0 表示;如果落在右分区,就用 1 表示。
这样一来,每做完一次二分区,我们就可以得到 1 位编码值(不是0 就是 1)。
再对经度值所属的分区再做一次二分区,同时再次查看经度值落在了二分区后的左分区还是右分区,按照刚才的规则再做 1 位编码。当做完 N 次的二分区后,经度值就可以用一个 N bit 的数来表示了。
所有的地图元素坐标都将放置于唯一的方格中。方格越小,坐标越精确。然后对这些方格进行整数编码,越是靠近的方格编码越是接近。
编码之后,每个地图元素的坐标都将变成一个整数,通过这个整数可以还原出元素的坐标,整数越长,还原出来的坐标值的损失程度就越小。对于「附近的人」这个功能而言,损失的一点精确度可以忽略不计。
比如对经度值等于 169.99 进行 4 位编码(N = 4,做 4 次分区),把经度区间[-180,180]分成了左分区[-180,0) 和右分区[0,180]。
169.99 属于右分区,使用 1表示第一次分区编码;再将 169.99 经过第一次划分所属的 [0, 180] 区间继续分成 [0, 90) 和 [90, 180],169.99 依然在右区间,编码 ‘1’。 将[90, 180] 分为[90, 135) 和 [135, 180],这次落在左分区,编码 ‘0’。
如此,最后我们就得到一个 4 位的编码。
而纬度的编码思路跟经度也是一样的,不再赘述。
合并经纬度编码
假如计算的经纬度编码分别是 11011 和00101`,目标编码第 0 位则从经度第 0 位的值 1 作为目标值,目标编码的第 1 位则从纬度第 0 位值 0 作为目标值,以此类推:
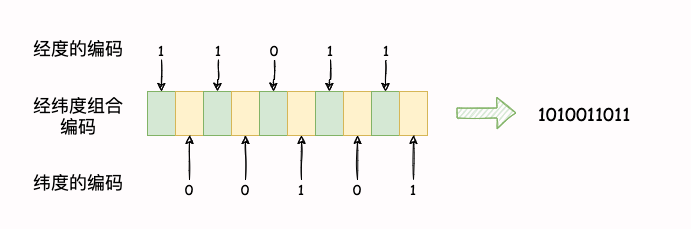
就这样,经纬度(35.679,114.020)就可以使用 1010011011 表示,而这个值就可以作为 SortedSet 的权重值实现排序。
Redis GEO 实现
“GEO 类型是将经纬度的经过 GeoHash 编码的合并值作为 Sorted Set 元素的 score 权重,Redis 的 GEO 有哪些指令呢?
”
我们需要把登陆 app 的女生 ID 和对应的经纬度存到 Sorted Set 里面。
更多 GEO 类型指令可参考:https://redis.io/commands#geo
GEOADD
Redis 提供了 GEOADD key longitude latitude member 命令,将一组经纬度信息和对应的「女神 ID」记录到 GEO 类型的集合中,如下:一次记录多个用户(苍井空、波多野结衣)的经纬度信息。
GEOADD girl:localtion 13.361389 38.115556 "苍井空" 15.087269 37.502669 "波多野结衣"
GEORADIUS
“我登陆了 app,获取自己的经纬度信息,如何查找以这个经纬度为中心的一定范围内的其他用用户呢?
”
Redis GEO类型提供了 GEORADIUS指令:会根据输入的经纬度位置,查找以这个经纬度为中心的一定范围内的其他元素。
假设自己的经纬度是(15.087269 37.502669),需要获取附近 10 km 的「女神」并返回给 LBS 应用:
GEORADIUS girl:locations 15.087269 37.502669 km ASC COUNT 10
ASC可以实现让「女神」信息按照这个距离自己的经纬度由近到远排序。
COUNT选项表示指定返回的「女神」数量,防止附近太多「女神」,节省带宽资源。
如果觉得自己需要更多女神,那么可以无限制,但是需要注意身体,多吃鸡蛋补一补。
“用户下线后,如删除下线的「女神」经纬度呢?
”
这个问题问得好,GEO 类型是基于 Sorted Set 实现的,所以可以借用 ZREM 命令实现对地理位置信息的删除。
比如删除「苍井空」的位置信息:
ZREM girl:localtion "苍井空"
小结
GEO 本身并没有设计新的底层数据结构,而是直接使用了 Sorted Set 集合类型。
GEO 类型使用 GeoHash 编码方法实现了经纬度到 Sorted Set 中元素权重分数的转换,这其中的两个关键机制就是对二维地图做区间划分,以及对区间进行编码。
一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为 Sorted Set 元素的权重分数。
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用 Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。
在 Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
所以,这里建议 Geo 的数据使用单独的 Redis 集群实例部署。
如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按区拆分。
这样就可以显著降低单个 zset 集合的大小。
我是小富~,如果对你有用在看、关注支持下,咱们下期见~
你的每个赞和在看,我都喜欢!
