
导语 | Elasticsearch于7.10版本推出可搜索快照功能,但是7.10版本的可搜索快照技术还不够成熟,随着7.14版本的发布,可搜索快照技术才真正能够大规模用于生产实践中。本文将基于ES 7.14.2版本,继续从原理和实践两个角度向大家介绍可搜索快照技术。
可搜索快照特性向我们展现一种能够直接搜索快照中数据的魔力,通常我们会将快照备份到非常廉价的存储介质中,如腾讯云对象存储COS中。这样我们就可以将集群的使用成本降到最低。
(一)DataTier模型
要了解可搜索快照的工作机制,首先我们需要了解从7.10版本开始ES对节点的分层规划,即DataTier概念。
(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/data-tiers.html#frozen-tier)
ES对不同的节点类型做了如下分层,分别是Content tier、Hot tier、Warm tier、Cold tier和Frozen tier。
(二)节点属性优化
另外7.10版本之后的集群不再通过node.master,node.data来区分是何种角色的节点,而是通过node.roles数组来定义一个节点的角色。如我们的测试集群中,Hot tier节点的node.roles如下:
node.roles: ["data_hot", "data_content", "ingest", "ml", "remote_cluster_client", "transform"]
专用主节点的node.roles则是:
如果集群中有Frozen tier的节点,我们通过是将该节点设置为专用Frozen节点,不和任何角色混用,如设置node.roles如下:
node.roles: ["data_frozen"]
除了对节点角色的优化,还对索引的allocation做了优化,原先我们是通过include.{attribute}、require.{attribute}、exclude.{attribute}来设置索引的allocation settings;而升级到DataTier模式后,则是通过index.routing.allocation.include._tier_preference
(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/data-tier-shard-filtering.html#tier-preference-allocation-filter)属性决定索引分片应该分配在哪一Tier节点上。
index.routing.allocation.include._tier_preference的属性值是一个字符串,多个tier_preference之间通过逗号“,”隔开,分片分配的优先级是从前往后依次降低。例如集群中的系统索引.kibana_7.14.2_001在创建时,其index.routing.allocation.include._tier_preference属性值为:“data_hot,data_warm,data_cold”,如下图1所示:
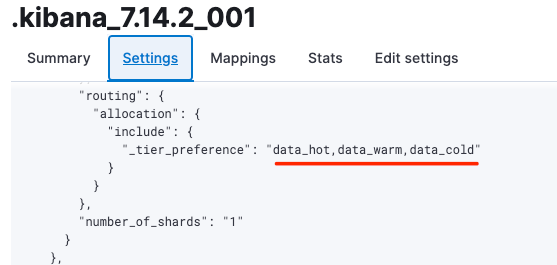
图1 索引创建时的_tier_preference属性
该属性的具体分配逻辑为:当集群中有data_hot节点时,则直接将分片分配在data_hot节点上,当没有data_hot节点时,则检查是否有data_warm节点,如果有,则在data_warm节点上分配,没有则在data_cold节点上分配。因此如果我们希望对集群中的数据进行降冷时,只需要将待降冷的索引settings设置为如下即可:
PUT {index_name}/_settings{ "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_warm,data_cold,data_hot" } } } }}
(三)工作原理
上面我们介绍了下7.10版本中引入的DataTier和_tier_preference概念,之所以先了解DataTier,是因为可搜索快照有两种挂载模式,分别对应的是两类不同的节点角色,即我们通过使用Cold或者Frozen数据节点来挂载可搜索快照数据,从而大大降低我们的集群成本。
若要对快照中数据进行查询,首先我们需要将快照中的数据Mount(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/searchable-snapshots-api-mount-snapshot.html)到集群中,而不是直接通过API去Search快照中的数据。
全量挂载的意思就是将快照中索引的数据在ES集群节点上全量保留一份,当搜索全量挂载的可搜索快照索引时,搜索原理和性能和普通索引相差不大。相比普通索引的优势在于,当其中一个分片出现损坏时,可搜索快照索引会自动从快照中拉取数据在其他节点上进行恢复,尤其是在集群中没有副本的情况下,普通模式是集群直接red,如果需要恢复,则必须手动从快照中进行恢复,在恢复前还需要先将该red的索引删除,而通过mount挂载下来的索引,则自动从快照中恢复损坏的分片。
部分挂载的意思就是并不将快照中的索引数据mount到集群节点上,而是只将索引的元数据信息保存以索引和分片的形式保留在节点上。部分挂载的分片只会分配在Frozen层。因此集群中Frozen层节点不存储快照数据,只存储索引分片的元数据信息,原始数据存储在COS的快照仓库中。如下API样例所示,其中storage就是索引的挂载类型:full_copy是全量挂载,而shared_cache则为部分挂载。
POST /_snapshot/default_searchable_snapshot_repository/my_cos_snapshot/_mount?wait_for_completion=true&storage=shared_cache{ "index": "wurong-test-2021.11.26-000001", "renamed_index": "wurong-test-2021.11.26-000001_from_cos", "index_settings": { "index.number_of_replicas": 0 }, "ignore_index_settings": [ "index.refresh_interval" ] }
当查询部分挂载的可搜索快照索引时,会从快照中进行拉取并加载在Frozen层节点本地缓存中,下次查询类似数据时则可以直接从本地进行返回,另外ES也有缓存淘汰策略,会定期清理不再经常查询的缓存数据以释放空间。通常需要配置一个或多个专用Frozen节点,这些专用Frozen节点之间共享缓存。如果集群中没有配置专用Frozen节点,则必须在节点的配置文件中配置如下参数xpack.searchable.snapshot.shared_cache.size来设置每个节点中需要为共享缓存保留的存储空间。因为部分挂载的可搜索快照索引只会在分配在具有共享缓存的节点上。
另外由于Frozen节点上存储的是索引的元数据信息,以及查询的缓存数据。因此在配置Frozen节点时,需要给共享缓存预留一定的硬盘空间,默认需要保留至少90%的磁盘总容量,如图2所示,通过xpack.searchable.snapshot.shared_cache.size参数进行调整。
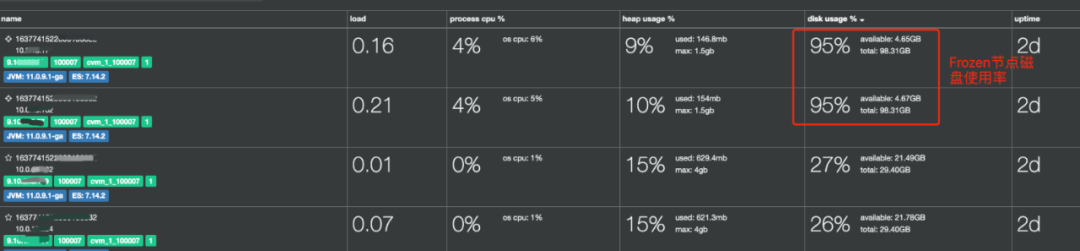
由于该参数是一个static类型,因此当我们给Frozen节点的硬盘进行扩容时,如采用腾讯云CBS的弹性拉伸时扩容时,则需要重启Frozen节点才能使得xpack.searchable.snapshot.shared_cache.size参数生效。
查询Frozen节点上的数据需要先将索引数据下拉到本地节点上才开始执行Search查询。因此查询时间上必然是比全量挂载或者查询普通的索引慢很多的,为了解决这个问题,ES提供了一种Async Search(https://www.elastic.co/guide/en/elasticsearch/reference/7.15/async-search.html)异步搜索的API。当执行该API时候,并不会立即获取到查询结果,而是返回一个requestId,随后异步准备数据,当数据准备好后,只需要通过该requestId即可获取到想要的数据了(以下样例来源官网)。
POST /sale*/_async_search?size=0{ "sort": [ { "date": { "order": "asc" } } ], "aggs": { "sale_date": { "date_histogram": { "field": "date", "calendar_interval": "1d" } } }}
由此我们可以看出Frozen层的部分挂载模式才是可搜索快照技术的真正亮点,因为它只需要Frozen节点很少的硬盘空间,即可Search过去无限规模的数据。达到了真正降低成本的目的。
下面我们基于腾讯云COS来逐步演示如何一步步搭建可搜索快照集群,我们要实现的效果是通过压测程序持续向集群中写入数据,索引在10分钟或者达到10mb后开始滚动,滚动完成后1小时开始迁移到冷节点上,并且执行COS备份,备份完成后全量挂载到集群中,删除集群中原来的索引数据,2小时后将索引部分挂载到集群中,此时索引分片分配在冻结层。其数据流转架构如下图3所示:
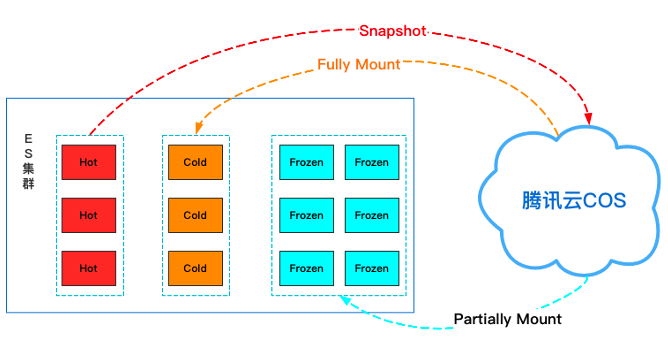
(一)集群环境准备
我们搭建的集群是7.14.2版本,由于可搜索快照技术只能在企业版本使用,因此我们在创建出7.14集群后需要手动调下如下API来免费试用企业版:
POST /_license/start_trial?acknowledge=true
调用API后如图4所示,说明当前集群已经是企业版集群了。

(二)创建快照仓库
本文测试集群使用的是腾讯云COS,因此我们需要在集群中创建一个COS仓库,用于可搜索快照的存放,仓库名称为default_searchable_snapshot_repository。
PUT _snapshot/default_searchable_snapshot_repository{ "type": "cos", "settings": { "app_id": "1254139681", "access_key_id": "xxxx", "access_key_secret": "xxxx", "bucket": "wurong-es-snapshpt", "region": “ap-guangzhou", "compress": true, "chunk_size": "500mb", "base_path": "/searchable-snapshot" }}
(三)配置索引生命周期管理
首先我们在Kibana上配置索引生命周期管理的Policy,路径为:Management-Stack Management-Data-Index Lifecycle Polices。主要是设置ILM的策略名称,每个Phase的触发Condition。
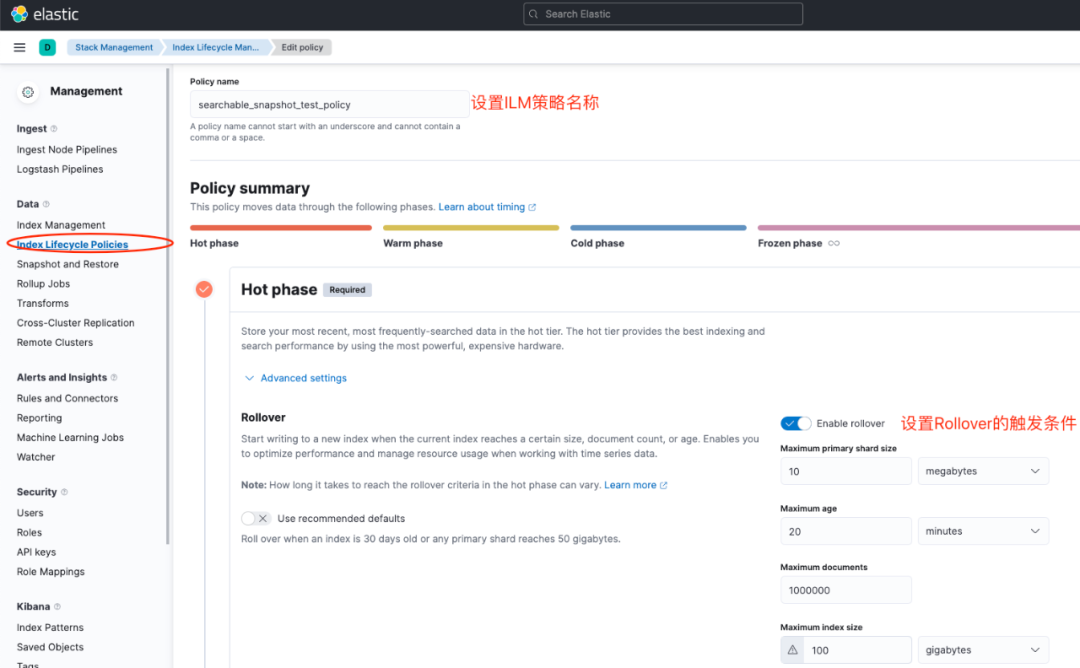
图5 配置ILM的Policy-Hot phase
上面我们设置好了Hot phase,主要是设置Rollover的触发条件,我们希望索引在创建后20分钟,或者主分片容量达到10mb后触发滚动,写入下一个索引。
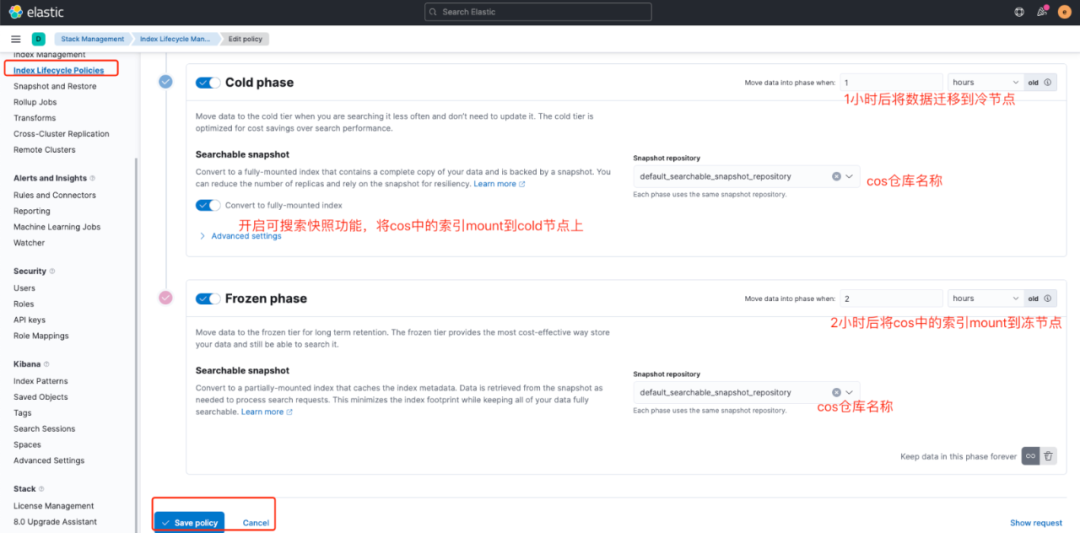
图6 配置ILM的Policy-Cold/Frozen phase
图6我们配置了Cold/Frozen phase的信息。我们想要达到的效果是索引在触发Rollover后的1小时开始降冷,将数据迁移到Cold tier上来,并且将数据备份到COS仓库,然后再全量Mount到集群中,在然后2小时后将cos中的索引部分mount到集群中。
上面我们是通过Kibana进行配置的,我们也可以直接通过API进行配置,效果是一样的:
PUT _ilm/policy/searchable_snapshot_test_policy { "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max_size": "100mb", "max_primary_shard_size": "10mb", "max_age": "20m", "max_docs": 1000000 }, "set_priority": { "priority": 100 } } }, "cold": { "min_age": "1h", "actions": { "searchable_snapshot": { "snapshot_repository": "default_searchable_snapshot_repository", "force_merge_index": true }, "set_priority": { "priority": 0 }, "allocate": { "number_of_replicas": 0 } } }, "frozen": { "min_age": "2h", "actions": { "searchable_snapshot": { "snapshot_repository": "default_searchable_snapshot_repository", "force_merge_index": true } } } } }}
在索引模版中指定创建的ILM policy和Rollover别名,模版名称为searchable_snapshot_test_template,policy名称为searchable_snapshot_test_policy,别名为wurong-test,_tier_preference为“data_hot,data_warm,data_cold”。
PUT _template/searchable_snapshot_test_template{ "order": 100, "index_patterns": [ "wurong-test*" ], "settings": { "index": { "lifecycle": { "name": "searchable_snapshot_test_policy", "rollover_alias": "wurong-test" }, "routing": { "allocation": { "include": { "_tier_preference": "data_hot,data_warm,data_cold" } } }, "refresh_interval": "30s", "number_of_shards": "5", "translog": { "sync_interval": "5s", "durability": "async" }, "max_result_window": "65536", "unassigned": { "node_left": { "delayed_timeout": "5m" } }, "number_of_replicas": "1" } }}
我们期望在索引名称上加上日期,因此使用如下的方式进行创建。
PUT %3Cwurong-test-%7Bnow%2Fd%7D-000001%3E{"aliases": { "wurong-test":{ "is_write_index": true } }}
创建完成后可以看出索引名称上包含了当前的日期,且后缀从000001开始。
然后通过压测程序开始向集群中写入数据,并且通过别名进行写入。
当我们持续往集群中写入半天的数据后,可以看到部分名称是restored-*开头的索引,这些索引就是从COS快照中Mount到本地的,如图8所示。
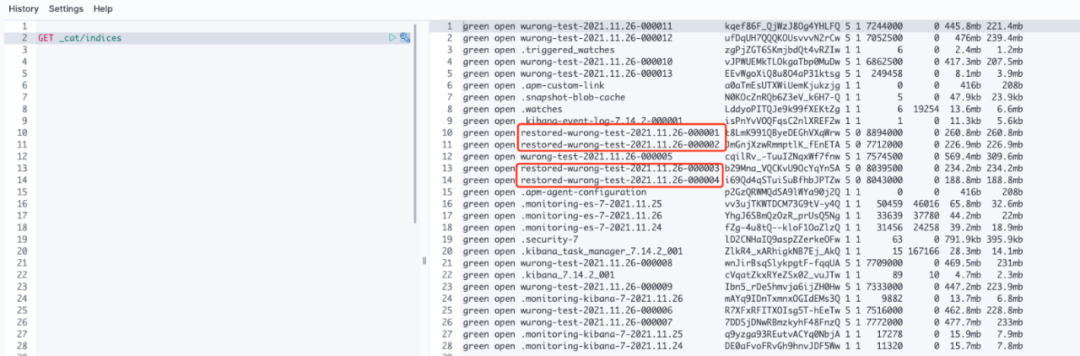
我们以restored-wurong-test-2021.11.26-000001为例子,查看该索引的settings信息,如下图9所示:
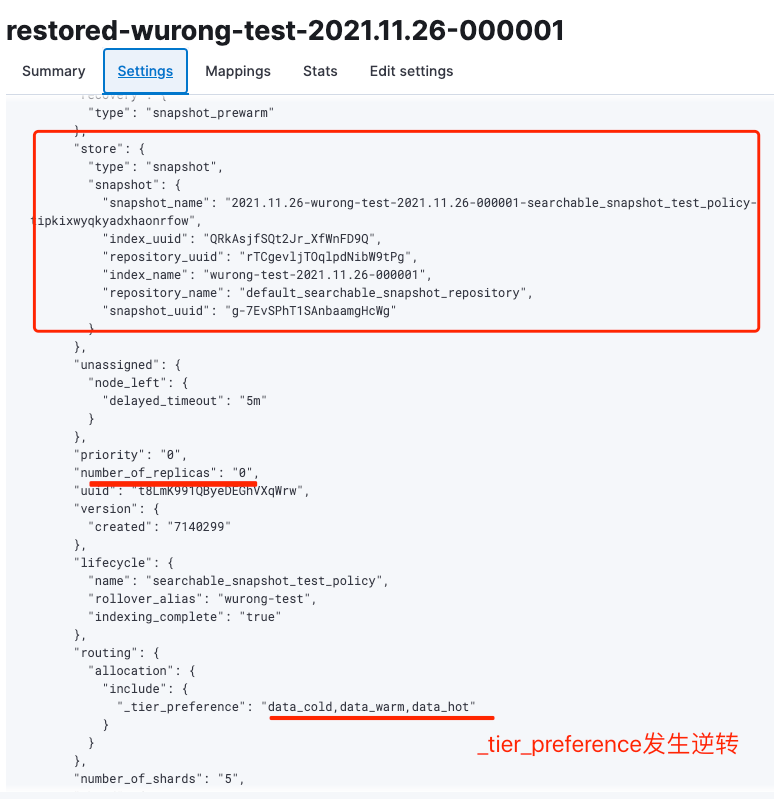
从restored-wurong-test-2021.11.26-000001索引的settings信息中可以看出分片副本被设置为了0,_tier_preference也从原先的“_tier_preference”:“data_hot,data_warm,data_cold”,调整成了“_tier_preference”:“data_cold,data_warm,data_hot”,由此也可以看出这个索引是通过全量挂载模式mount到集群中的。并且在store对象中详细列出了mount快照的信息,如仓库名称,快照名称,快照Id和索引Id等。
当触发了Frozen phase的条件后,索引分片会被分配到Frozen tier节点上,且该索引是按照我们在ILM policy中定义的那样,通过部分挂载,即Partially mount模式挂载在Frozen tier节点上的。从Kibana上我们可以看到,该类索引名称是以partial-*开头,其Docs数量是7413000,但是Storage size大小为0,这说明该索引在集群上是不占用存储空间的,只有索引的元数据信息。如图10所示:
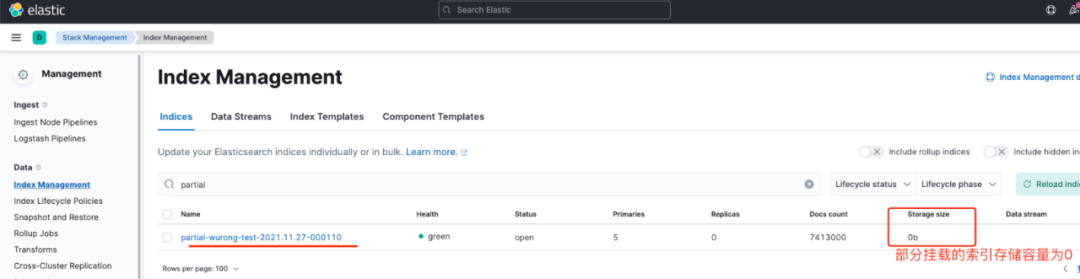
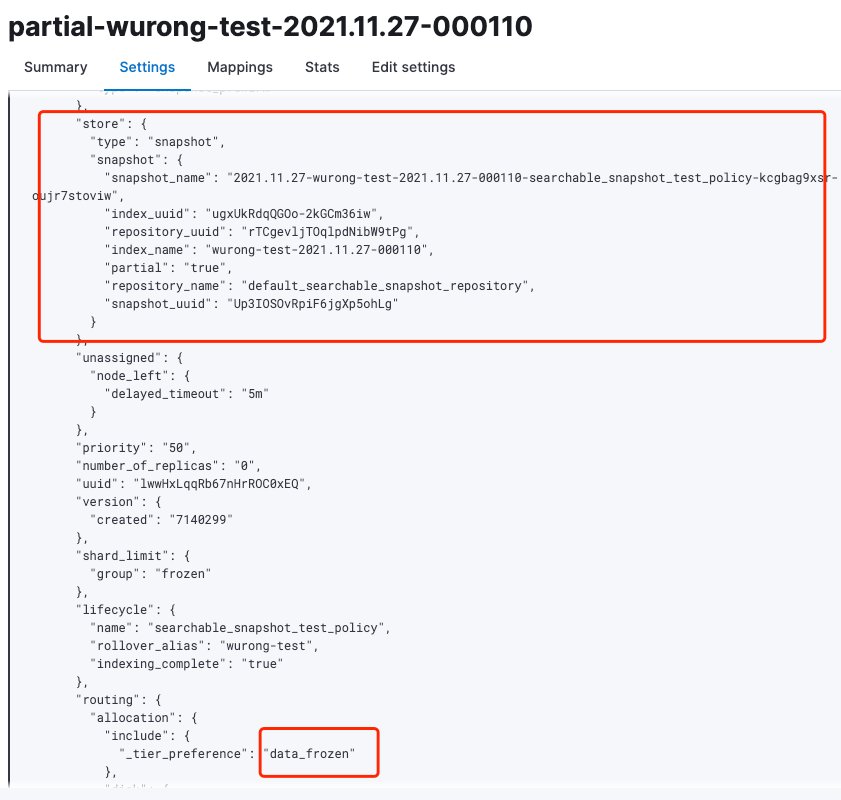
查看该索引的settings信息,可以看到_tier_preference被设置为了:data_frozen。
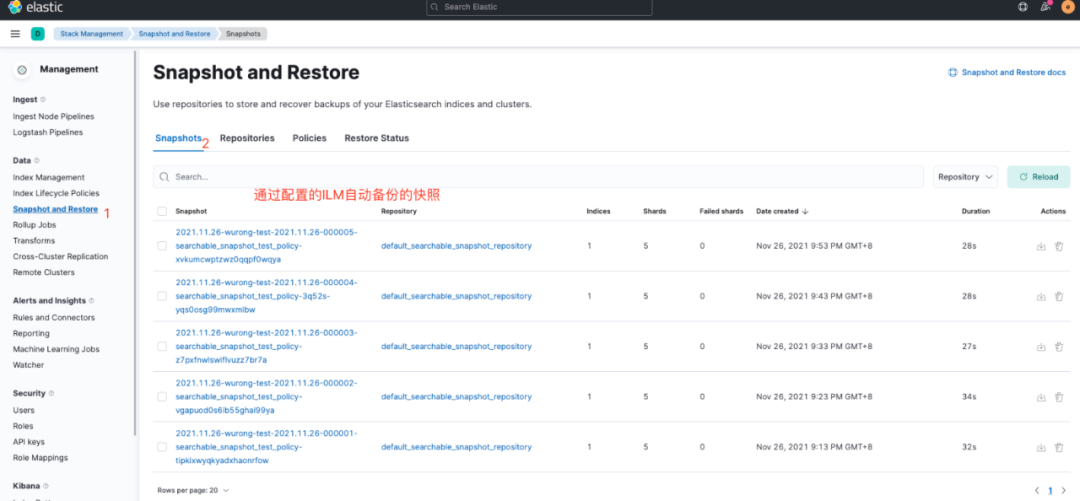
另外ILM自动备份的快照信息也可以直接在Kibana上查看,路径为:Management-Stack Management-Data-Snapshot and Restore,如图12所示。
本文介绍了可搜索快照的技术原理,以及基于腾讯云COS对象存储完整演示了可搜索快照的配置过程和可搜索快照的转换流程。希望对大家有所帮助,也让我们共同期待腾讯云ES的可搜索快照方案的发布。
(作者:吴容——腾讯云Elasticsearch高级开发工程师)

👇戳「阅读原文」一键了解腾讯云Elasticsearch Service更多信息~
