
Linux文件系统基础知识补充

linux文件管理简介
一个文件系统的功能是什么?
1、 创建、删除、打开、读取、写入等文件操作
2、 文件要以一定的方式进行组织管理,比如目录结构等形式
文件系统的底层依托 是 可以存储东西的存储器,比如内存、硬盘等存储器。
常见的文件系统
- 1、ext3 硬盘文件系统
- 2、ext4 硬盘文件系统
- 3、tmpfs 内存文件系统
ext3和ext4
block
硬盘被分为若干个block,一个block的大小为 4KB。
通过block位图来标记一个block是否空闲,也就是一个block ,4K, 有4 * 1024 * 8 个bit ,可以表示 128M 的空间。
每次分配的时候,从位图中找到一个 位图中为0的对应的block,并将其位图中的bit置为1
每次回收的时候,将位图中对应的bit置为0,
inode
一个文件和文件夹都是对应着一个inode。
每个Inode都有一个唯一的ID。
inode中记录了文件对应的详细信息,比如id,更改时间、所属用户、所属组等信息,以及对应的存储的block信息。
文件的具体内容和属性是分开存放的,属性存放在inode中,具体的内容可以通过inode中的指针进行读取。
inode中通过inode位图来标识一个inode是否空闲。
位图存在一个block中,也就是说一个block可以记录410248个inode的状态
块组
block位图 + inode位图 + 对应的inode列表 + 对应的block 称为 一个 块组
块组描述符表
一个硬盘可以分为 多个 块组,通过块组描述符表来记录对应的块组信息。
读取 一个块组描述符 可以快速得出对应的块组的inode和block的信息,比如空闲block的个数、空闲inode的个数。block位图的地址范围、inode位图地址的范围等信息。
超级块
超级块中记录了整个文件系统中的信息,比如block的大小,inode的大小,文件系统中可用的inode个数、文件系统中可用的block的个数。块组描述符列表的地址范围。
文件系统结构图
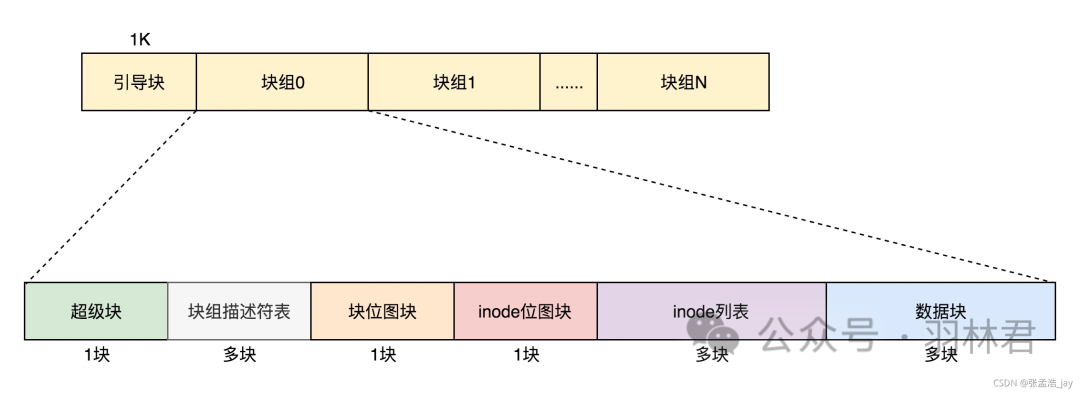
ext3和ext4中文件具体信息存放的方式不一样。
ext3架构图
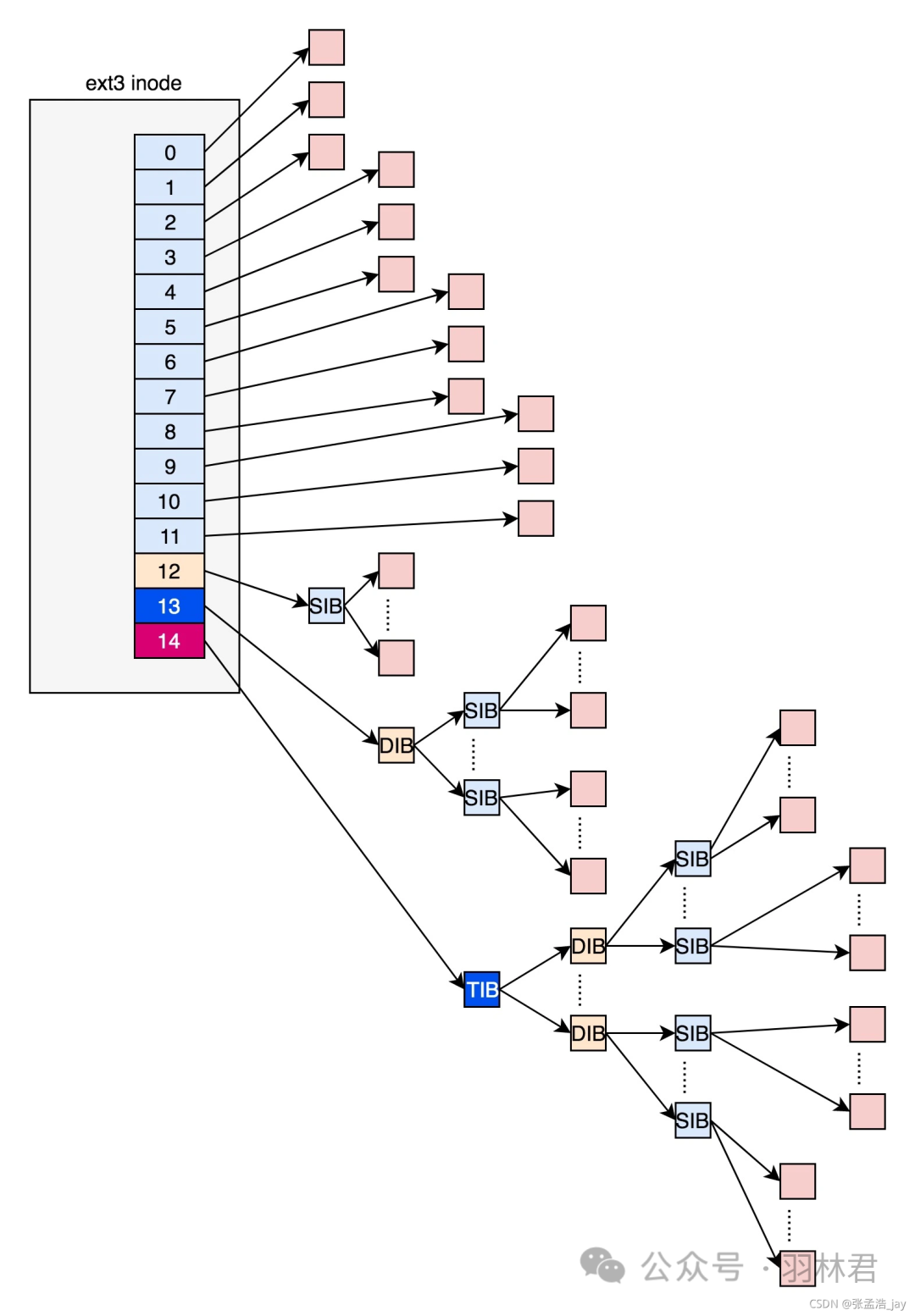
ext3中,每个innode对应着block数组,前12个为直接映射,后3个为间接映射。
ext4的架构图
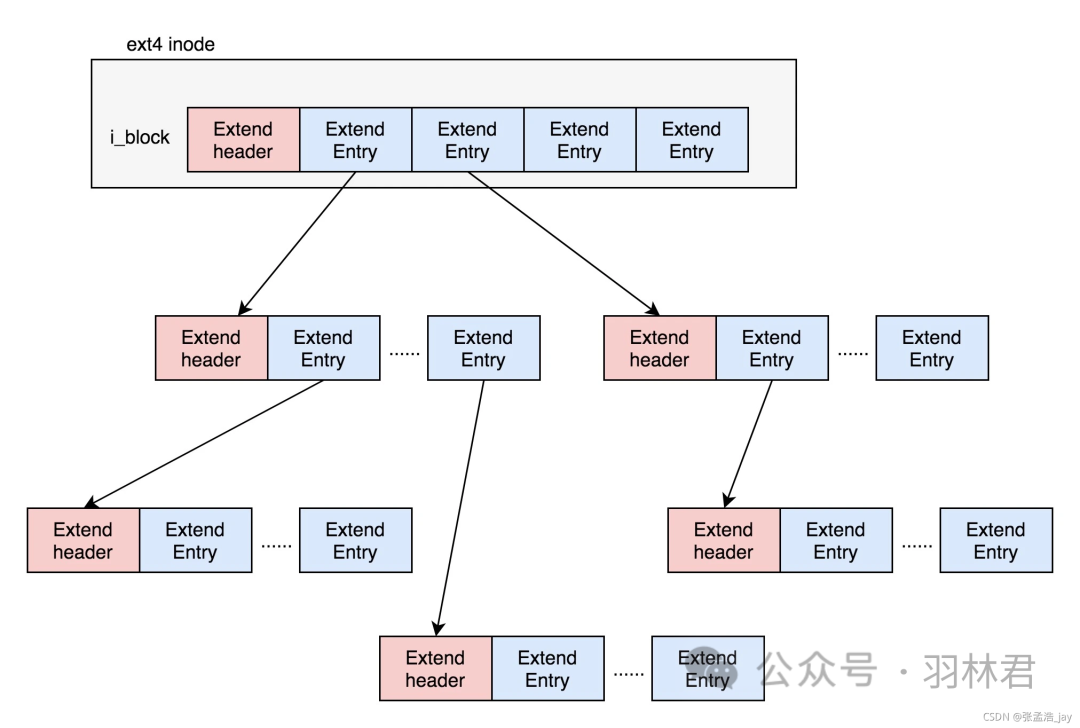
ext3有一个缺点:当组织大文件的时候,每个block都用一个记录项来记录,会导致索引项增多,索引项会额外浪费空间,而且会降低大文件的读取效率。
ext4通过一个多叉树来组织大文件,分为叶子节点和非叶子节点,非叶子节点用来记录索引信息,而叶子节点用来记录实际的block信息,不会挨个记录,而是通过start 和 end 开始和结束地址来记录若干个block,提高大文件的读取效率。
目录
一个操作系统中存在很多个文件,怎么有效的管理文件呢?
Linux采用的树状结构,也就是目录结构,通过目录来管理文件
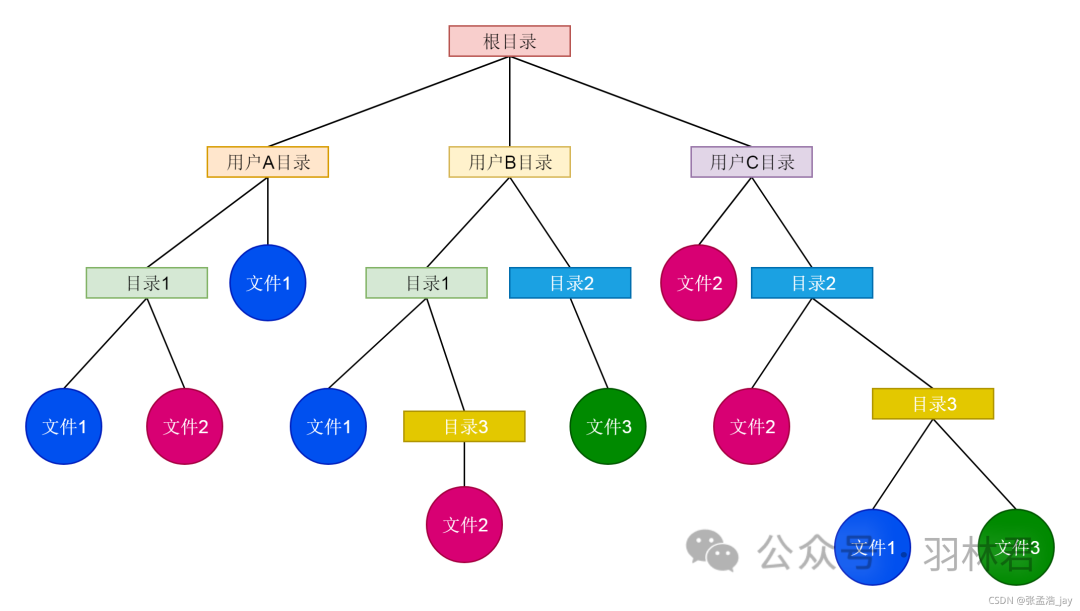
这里面有一个非常关键的问题,目录怎么存储。
在Linux中,目录也被当作一个文件,也有对应的inode,只不过目录文件中存储的是目录下的文件和目录信息。
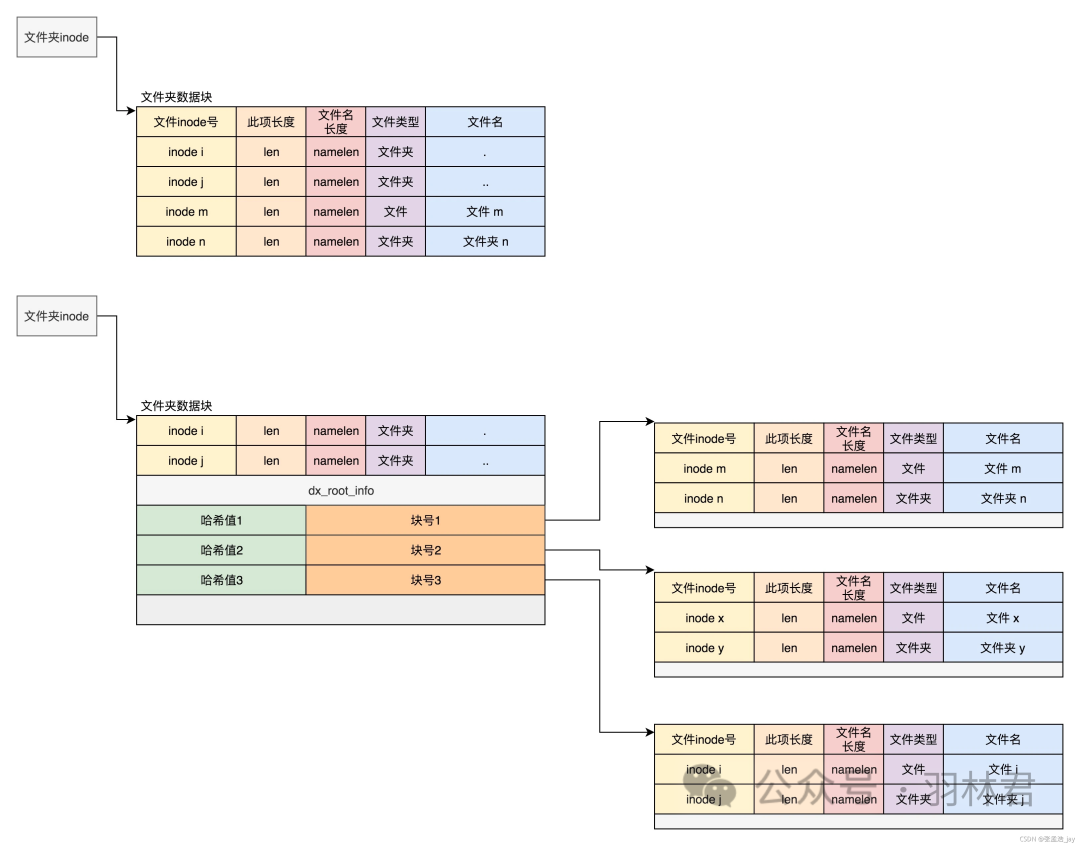
为了快速的在目录文件中检索对应的文件或者目录,引入了 哈希索引,通过对文件或者目录名字来进行哈希,每个哈希值对应的有一个块号,对应的块中存储的有对应的文件信息和目录信息。
通过对文件名字进行哈希值可以快速找到对应的块号。
硬链接和软链接
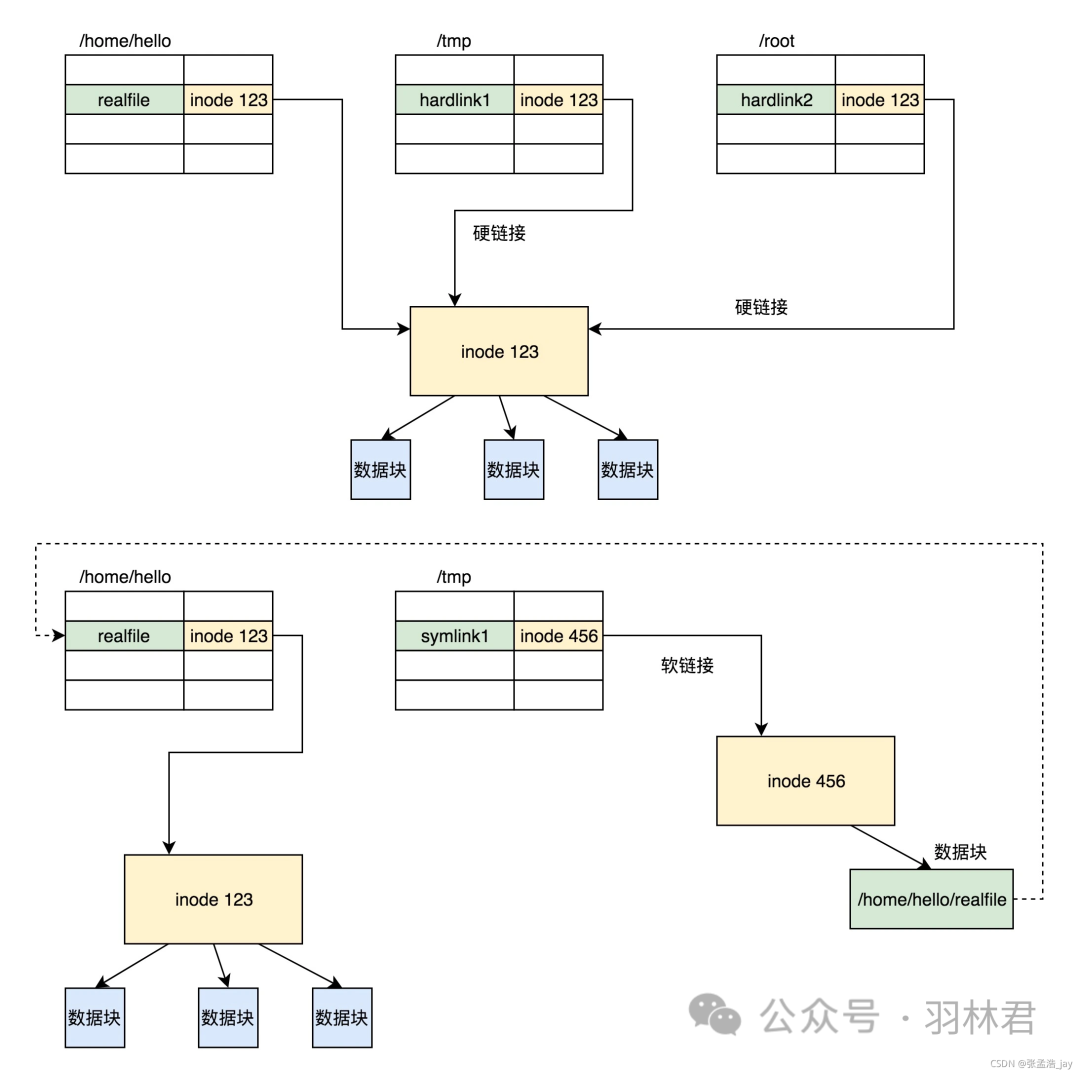
-
硬链接:新建文件和原始文件共用一个Inode节点,当所有文件都删除的时候,才会彻底删除对应的文件。不可以跨文件系统建立链接。
-
软链接:文件新建一个Inode节点,文件中存储的是对应的链接,指向原始文件。可以跨文件系统建立链接。
虚拟文件系统 VFS
Linux中一切皆文件,无论是块设备、共享内存、socket、字符设备、进程信息都可以通过操作文件的的统一接口来访问对应的资源,比如open()、read()、write()。这就依靠于Linux的虚拟文件系统 VFS
挂载 mount
块设备、内存、字符设备等要想被使用,都要有一定的文件系统,然后将其挂载到Linux中的目录中。
这个目录可以是根目录,也可以是其他文件系统下的目录。
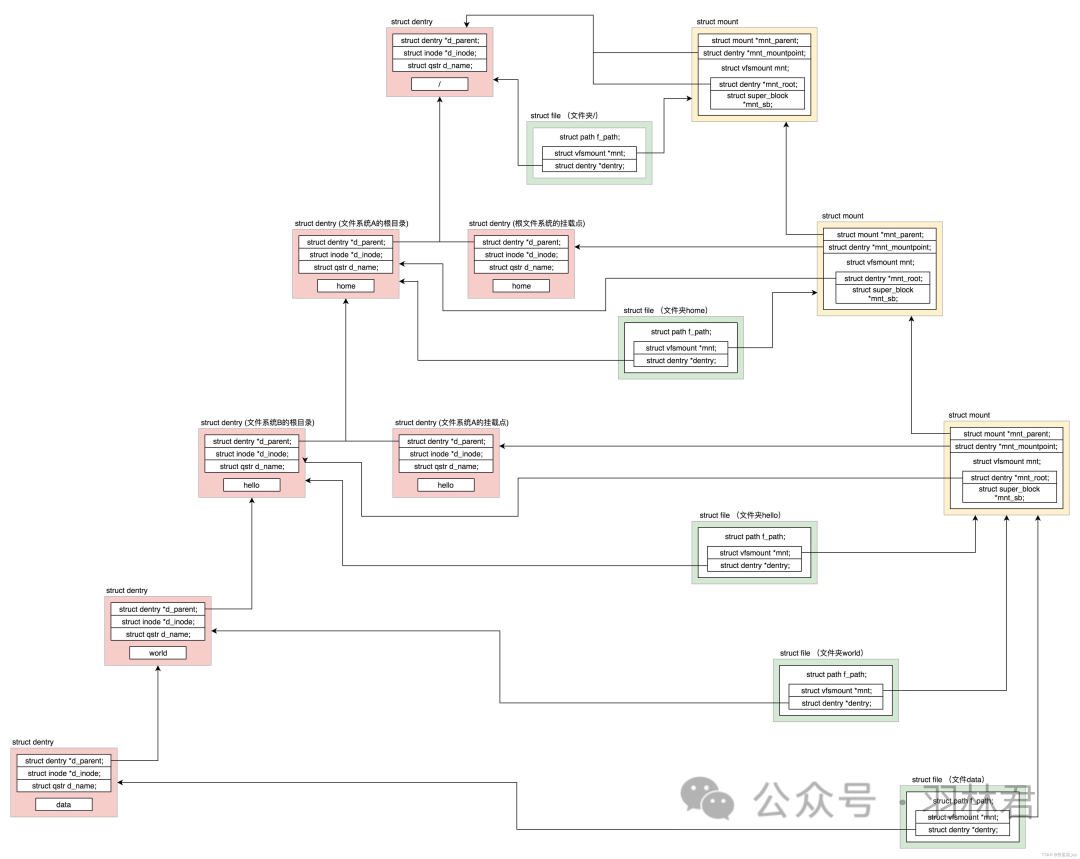
这些挂载信息被保存在根分区中,在Linux初始化的时候被取出,加载到内存中。
根分区是用来引导Linux加载的,是必须的,根分区会挂载到根目录 /。
挂载信息中记录了对应的文件系统的超级块信息、以及对应的挂载目录信息。
内存中会维护一个目录树,最一开始之后只有根目录,通过挂载信息中的文件系统超级块信息和挂载目录信息,就可以逐渐的扩展目录树。
访问文件
Linux需要通过 一个文件路径 来 访问对应的文件。
- 1、首先要open(),也就是打开文件。
首先获取根目录对应的inode,然后通过根目录的inode获取对应的目录信息和文件信息, 通过遍历根目录中的目录来找到二级目录对应的inode,就这样不断的向下寻找就可以找到对应的文件的inode了。
-
2、内核会维护一个file struct列表,file中会加入文件对应的inode节点,并且为inode加入对应的块设备编号和驱动程序。
-
3、内核会返回一个fd给用户进程,fd就是文件描述符。用户进程会维护一个文件描述符表,fd会对应一个指向内核中file的指针,在之后的访问文件就可以直接通过fd来找到对应的file了。
FD就是进程的文件描述符表的对应的文件记录的索引下标,是一个非负的整数
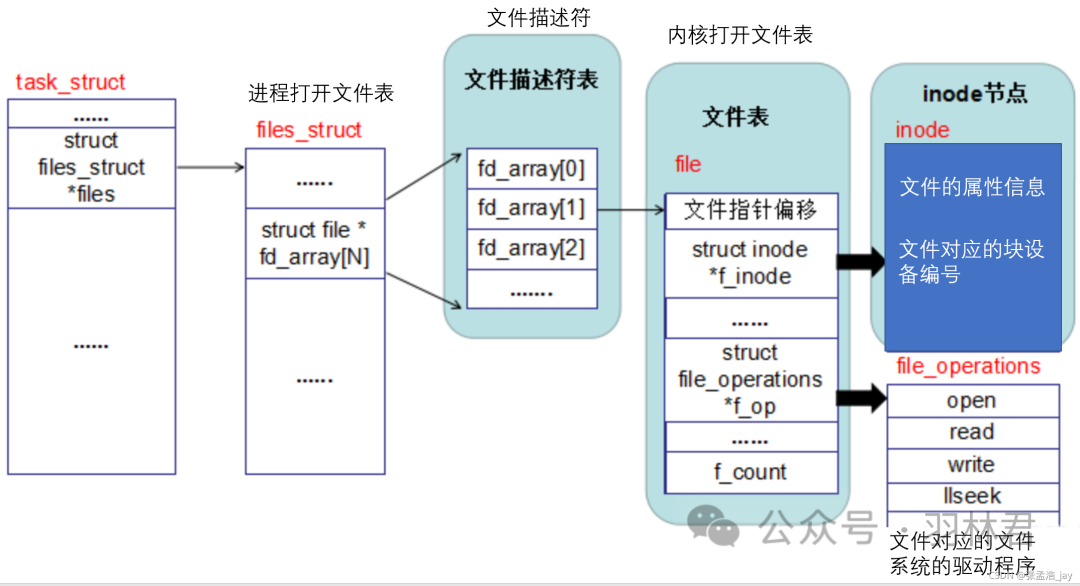
通过inode中的设备编号和对应的驱动程序,就可以通过驱动程序+inode的文件信息,就可以对文件进行操作了。
这样就实现了VFS的功能了,虚拟文件管理。进程只需要通过open()、read()和fd就可以操作对应的文件了。
值得注意的是,当读取文件的时候,有以下两个步骤:
- 1、将数据从 磁盘 拷贝到 内核空间中
- 2、将数据 从内核空间 拷贝到 用户空间中。
文件缓存
内存和磁盘都是分页来进行管理的,也就是4K,写入磁盘或者读取文件的时候,也是按照 页 来读取。
为了减少访问磁盘的次数,Linux在内核空间开启了一片内存作为缓存,然后将读取的文件按照page放入到缓存中,当再次需要该文件对应的page的时候,会先查看缓存中是否存在对应的page,如果存在,直接从缓存拷贝到用户态。如果不存在,才会访问磁盘。
当写对应的page的时候,先将其写入到缓存中,等待系统或者用户调用sync(),才将文件写入到磁盘上。当文件写入到缓存中后,对应的缓存就为脏页了,在内存紧张的时候,或者刷盘的时候,会将其写入到磁盘中。
缓存中的page是通过inode和对应的偏移offset来唯一标识的
来源:https://blog.csdn.net/qq_40276626/article/details/120478538
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
推荐阅读
【3】CPU中的程序是怎么运行起来的 必读
本公众号全部原创干货已整理成一个目录,回复[ 资源 ]即可获得。