
数据中台:基于标签体系的360°用户画像

导读:通过标签体系,建立数据中台,打通用户数据。

实物标签是用于标明物品的品名、重量、体积、用途等信息的简要标牌,例如:商品标签、图书标签、车检标签、文件标签、服装吊牌、车票、登机牌都是实物标签。 网络标签(Tag)是一种互联网内容组织方式,是相关性很强的关键字,它帮助人们轻松的描述和分类内容,以便于检索和分享,Tag是web 2.0的重要元素。 电子标签又称RFID射频标签,是一种识别效率高和准确性好的识别工具,通过射频信号自动识别目标对象并获取相关数据,识别工作无须人工干预,可工作于各种恶劣环境。


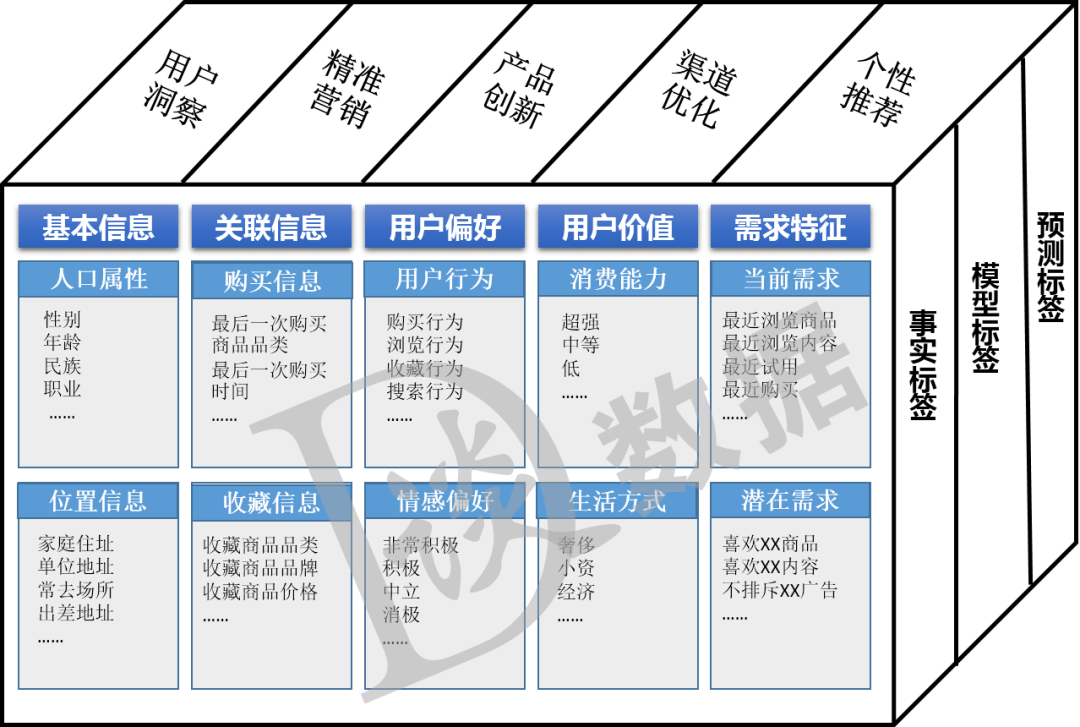
基础标签主要是指对用户基础特征的描述,比如:姓名、性别、年龄、身高、体重等。 业务标签是在基础标签之上依据相关业务的业务经验并结合统计方法生成的标签,比如:用户忠诚度、用户购买力等标签就是根据用户的登录次数、在线时间、单位时间活跃次数、购买次数、单次购买金额、总购买金额等指标计算出来的。业务标签可以将经营固化为知识,为更多的人使用。 智能标签是利用人工智能技术基于机器学习算法,通过大量的数据计算而实现的自动化、推荐式的进行打标签,比如今日头条的推荐引擎就是通过智能标签体系给用户推送其感兴趣的内容的。


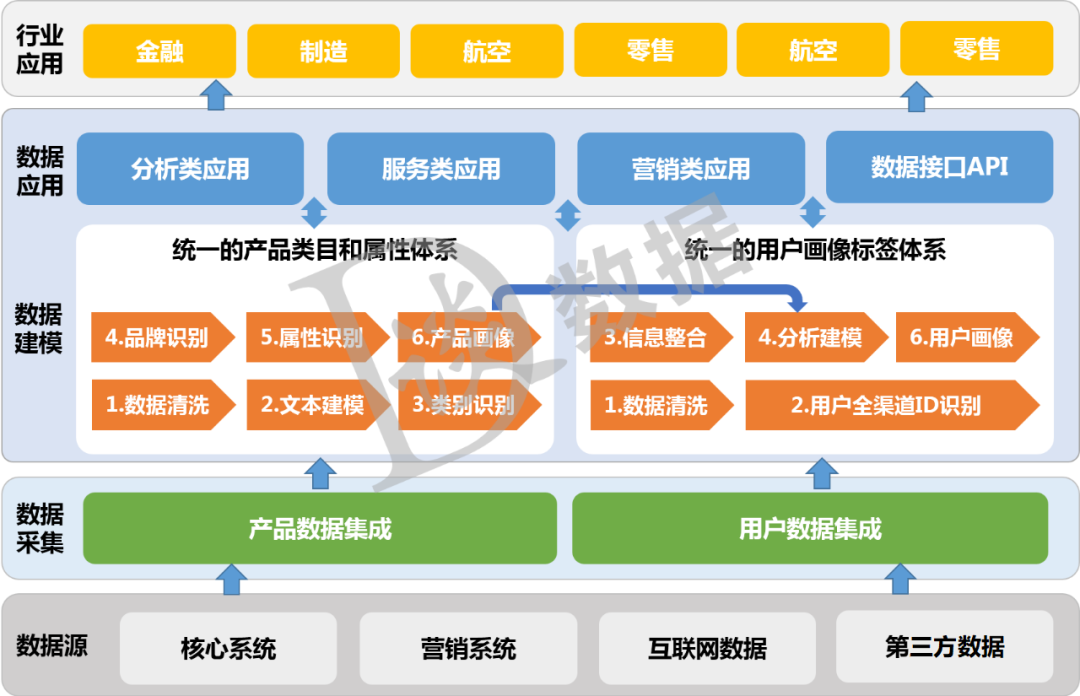

有线下采集的信息,比如通过访谈、调研等方式采集的数据; 有线上采集的信息,比如:消费记录、浏览日志、收藏记录等; 有从第三方接口接入的信息,比如微信接口可以获取用户微信的昵称、性别、地域,QQ接口可以获取用户QQ的昵称、性别、年龄、生日、星座、地域等信息; 还有通过爬虫获取的数据,比如微博、评论、论坛等社交媒体的内容; 通过机器学习来训练得到信息,比如通过预置机器学习算法; 利用网络爬虫不断抓取数据进行大量计算得出来的数据,比如情感偏好、购物偏好等。
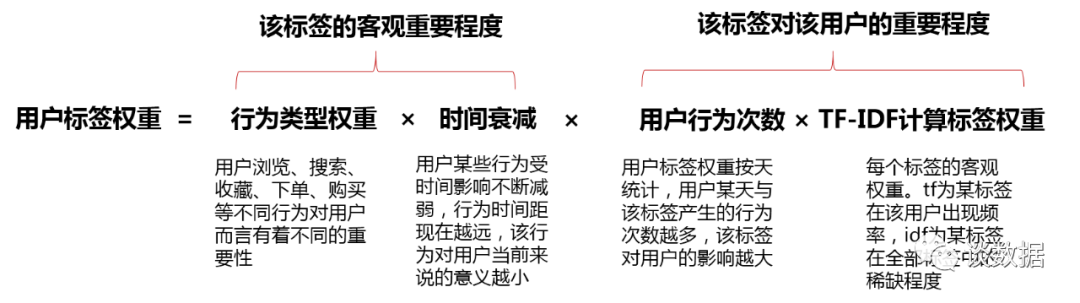
行为类型权重:用户浏览、搜索、收藏、下单、购买等不同行为对用户而言有着不同的重要性(偏序关系),该权重值一般由运营人员或业务来决定; 时间衰减:用户某些行为受时间影响不断减弱,行为时间距现在越远,该行为对用户当前来说的意义越小,采用牛顿冷却定律; 行为次数:用户标签权重按天统计,用户某天与该标签产生的行为次数越多,该标签对用户的影响越大。
基于规则定义的标签生产方式,即根据固定的规则,通过数据查询的结果生产标签,重点在于如何制定规则。 基于主题模型的标签生产方式,主题模型最开始运用于内容领域,目的是找到用户的偏好,在用户标签中我们可以参照分类算法将用户进行分类、聚类,使用关键词的算法挖掘用户的偏好,从而生产标签。


评论