
SVO: 视觉SLAM中特征点法与直接法结合
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
前面的话
VSLAM 是利用多视图几何理论,根据相机拍摄的图像信息对相机进行定位并同时构建周围环境地图。VSLAM 前端为视觉里程计和回环检测,相当于是对图像数据进行关联;后端是对前端输出的结果进行优化,利用滤波或非线性优化理论,得到最优的位姿估计和全局一致性地图。
特征点法精度高,直接法速度快,两者是否可以结合呢?
SVO(Semi-Direct Monocular Visual Odometry)是苏黎世大学 Scaramuzza 教授的实验室,在 2014 年发表的一种视觉里程计算法,它的名称是半直接法视觉里程计,通俗点说,就是结合了特征点法和直接法的视觉里程计。
目前该算法已经在 github 上面 开 源 (https://github.com/uzh-rpg/rpg_svo )。 贺 一 家 在 它 的 开 源 版 本 上 面 进 行 改 进 , 形 成了 SVO_Edgelet(https://github.com/HeYijia/svo_edgelet)。相比原版, SVO_Edgelet 增加了一些功能,比如结合本质矩阵和单应矩阵来初始化,把边缘特征点加入跟踪等,对 SVO 的鲁棒性有较大的改善。
SVO 面向无人机航拍场合,将特征点法与直接法结合,跟踪关键点,不计算描述子,根据关键点周围的小图像块的信息估计相机的运动。主要分运动估计线程和地图构建线程两个线程。
其中运动估计分为如下三步:
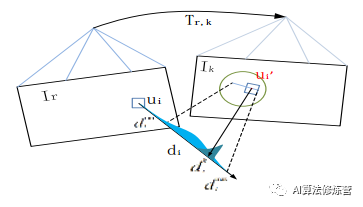
1)图像对齐。如图所示,通过当前帧和参考帧中的特征点对的 patch(特征点周围 4*4 区域)的灰度差异,构建光度误差的优化函数
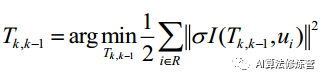
其中,
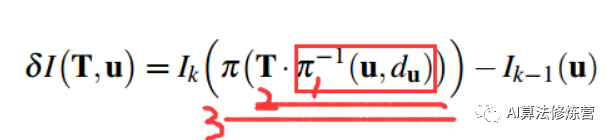
公式中第一步为根据图像位置和深度逆投影到三维空间,第二步将三维坐标点旋转平移到当前帧坐标系下,第三步再将三维坐标点投影回当前帧图像坐标。当然在优化过程中,残差的计算方式不止这一种形式:有前向(forwards),逆向(inverse)之分,并且还有叠加式(additive)和构造式(compositional)之分。
优化变量为相机的变换矩阵 T,采用高斯牛顿迭代求解,然后寻找更多的地图点到当前帧图像的对应关系。
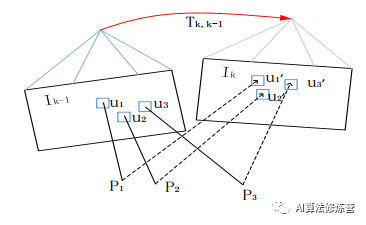
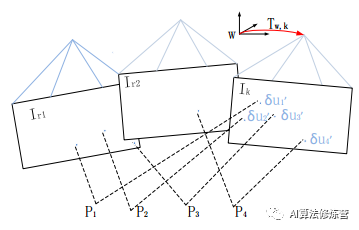
2)特征对齐。如图,由于深度估计和相机位姿的不准导致预测的特征块位置不准,通过光流跟踪对特征点位置进行优化,具体为:对每个当前帧能观察到的地图点 p(深度已收敛),找到观察 p 角度最小的关键帧 r 上的对应点 ui,得到 p 在当前帧上的投影。优化的目标函数是特征块(8*8的 patch ) 及 其 在 仿 射 变 换 下 的 灰 度 差
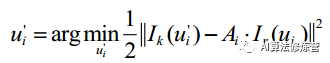
其中:Ai 表示仿射变换; 优化变量为特征点位置 ui’。
3)位姿结构优化。 如图所示,像素位置优化后,利用建立的对应关系对空间三维点和相机位置进行分别优化,构 建 像 素 重 投 影 误 差 的 优 化 函 数
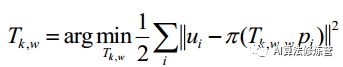
优化变量为相机的变换矩阵 T或空间三维点 P。
地图构建主要是深度估计。如图所示,它采用概率模型, 高斯分布加上一个设定在最小与最大 深 度 之 间 的 均 匀 分 布 :
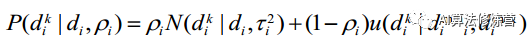
并推导了均匀—高斯混合分布的深度滤波器,采用逆深度作为参数化形式。当出现新的关键帧时,选取若干种子点,每个种子点根据变换矩阵得到对应的极线,在极线上找到特征点的对应点,通过三角测量计算深度和不确定性;然后不断更新其估计, 直到深度估计收敛到一定程度,将该三维坐标加入地图。
SVO算法流程
主要流程图为:
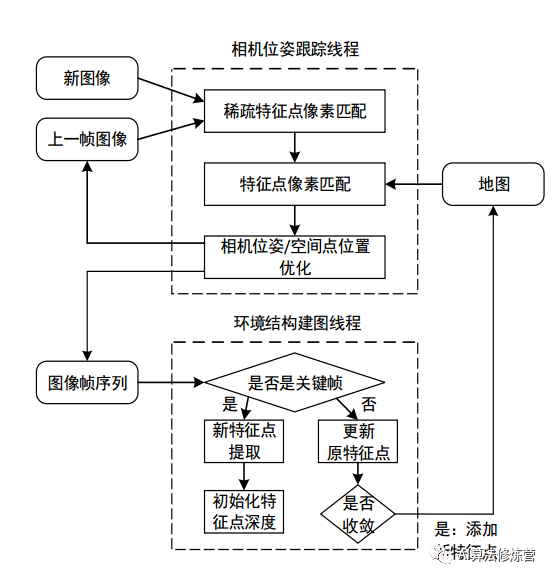
下面,结合代码进行算法流程的详细分析:
1.跟踪
其实, SVO 的跟踪部分的本质是跟 ORBSLAM 一样的,只是匹配的方法从特征点法改成了灰度值匹配法。
但是,随后,与 ORBSLAM 有不同的地方, SVO 在优化出相机位姿之后,还有可选项,可以再优化地图点,还可以再把地图点和相机位姿一起优化。
1.1 初始化
图像刚进来的时候,就获取它的金字塔图像, 5 层,比例为 2。
然后处理第一张图像, processFirstFrame()。先检测 FAST 特征点和边缘特征。如果图像中间的特征点数量超过 50 个,就把这张图像作为第一个关键帧。
然后处理第一张之后的连续图像, processSecondFrame(), 用于跟第一张进行三角初始化。从第一张图像开始,就用光流法持续跟踪特征点, 把特征像素点转换成在相机坐标系下的深度归一化的点,并进行畸变校正,再让模变成 1,映射到单位球面上面。
如果匹配点的数量大于阈值,并且视差的中位数大于阈值。如果视差的方差大的话,选择计算 E 矩阵,如果视差的方差小的话,选择计算 H 矩阵。如果计算完 H 或 E 后,还有足够的内点,就认为这帧是合适的用来三角化的帧。根据 H 或 E 恢复出来的位姿和地图点,进行尺度变换,把深度的中值调为 1。
然后把这一帧,作为关键帧,送入到深度滤波器中。(就是送到的深度滤波器的 updateSeedsLoop()线程中。 深度滤波器来给种子点在极线上搜索匹配点,更新种子点,种子点收敛出新的候选地图点。如果是关键帧的话,就初始化出新的种子点, 在这帧图像里面每层的每个 25x25 大小的网格里,取一个最大的 fast 点。在第 0 层图像上,找出 canny 边缘点。)
之后就是正常的跟踪 processFrame()。
1.2 基于稀疏点亮度的位姿预估
把上一帧的位姿作为当前帧的初始位姿。把上一帧作为参考帧。
先创建 n 行 16 列的矩阵 ref_patch_cache_, n 表示参考帧上面的特征点的个数, 16 代表要取的图块的像素数量。
再创建 6 行 n*16 列的矩阵 jacobian_cache_。 代表图块上的每个像素点误差对相机位姿的雅克比。
要优化的是参考帧相对于当前帧的位姿。
把参考帧上的所有图块结合地图点,往当前帧图像的金字塔图像上投影。在当前帧的金字塔图像上,从最高层开始,一层层往低层算。每次继承前一次的优化结果。如果前一次的误差相比前前次没有减小的话,就继承前前次的优化后的位姿。 每层的优化,迭代 30 次。
要优化的残差是, 参考帧 k-1上的特征点的图块与投影到当前帧 k上的位置上的图块的亮度残差。 投影位置是,参考帧中的特征点延伸到三维空间中到与对应的地图点深度一样的位置,然后投影到当前帧。
这是 SVO 的一个创新点,直接由图像上的特征点延伸出来,而不是地图点(因为地图点与特征点之间也存在投影误差),这样子就保证了要投影的图块的准确性。延伸出来的空间点肯定也与特征点以及光心在一条直线上。这样子的针孔模型很漂亮。
SVO 的另外一个创新点是,以当前帧上的投影点的像素值为基准,通过优化调整参考帧投影过来的像素点的位置,以此来优化这两者像素值残差。 这样子,投影过来的图块patch上的像素值关于像素点位置的雅克比,就可以提前计算并且固定了。(而以前普通的方法是,以参考帧投影过去的像素值为基准,通过优化投影点的位置,来优化这两者的残差。)
采用近似的思想。首先, 认为空间点 p 固定不动, 只调整参考帧k-1的位姿,所以残差的扰动不影响在当前帧上的投影点的位置,只会影响图块patch的内容。然后,参考帧在新的位姿上重新生成新的空间点,再迭代下去。虽然只是近似优化,
但每次迭代的方向都是对的, 假设步长也差不多, 所以最终也可以优化成功。
1.3 基于图块的特征点匹配
因为当前帧有了 1.1 的预估的位姿。对于关键帧链表里面的那些关键帧,把它们图像上的分散的 5 点往当前帧上投影,看是否能投影成功,如果能投影成功,就认为共视。再把所有的共视关键帧,按照与当前帧的距离远近来排序。然后,按照关键帧距离从近到远的顺序,依次把这些关键帧上面的特征点对应的地图点都往当前帧上面投影,同一个地图点只被投影一次。如果地图点在当前帧上的投影位置,能取到 8x8 的图块,就把这个地图点存入到当前帧投影位置的网格中。
再把候选地图点都往当前帧上投影,如果在当前帧上的投影位置,能取到 8x8 的图块,就把这个候选地图点存入到当前帧投影位置的网格中。如果一个候选点有 10 帧投影不成功,就把这个候选点删除掉。
然后,对于每一个网格, 把其中对应的地图点,按照地图点的质量进行排序(TYPE_GOOD> TYPE_UNKNOWN> TYPE_CANDIDATE>TYPE_DELETED)。如果是 TYPE_DELETED,则在网格中把它删除掉。
遍历网格中的每个地图点,找到这个地图点被观察到的所有的关键帧。获取那些关键帧光心与这个地图点连线,与地图点与当前帧光心连线的夹角。选出夹角最小的那个关键帧作为参考帧,以及对应的特征点。(注意,这里的这种选夹角的情况,
是只适合无人机那样的视角一直朝下的情况的,应该改成 ORBSLAM 那样,还要再把视角转换到对应的相机坐标系下,再筛选一遍)。这个对应的特征点,必须要在它自己的对应的层数上, 能获取 10x10 的图块。
然后,计算仿射矩阵。首先,获取地图点在参考帧上的与光心连线的模。然后它的对应的特征点,在它对应的层数上,取右边的第 5 个像素位置和下边的第 5 个像素位置,再映射到第 0 层。再转换到单位球上,再映射到三维空间中,直到与地图点的模一样的长度。把对应的特征点也映射到三维空间中,直到与地图点的模一样的长度。然后,再把这 3 个点映射到当前帧的(有畸变的) 图像上。根据它们与中心投影点的位置变换, 算出了仿射矩阵 A_cur_ref。A_cur_ref.col(0) = (px_du-px_cur)/halfpatch_size; A_cur_ref.col(1) = (px_dv - px_cur)/halfpatch_size;。
仿射矩阵 A,就是把参考帧上的图块在它自己对应的层数上, 转换到当前帧的第 0 层上。(这种把比例变换转换成矩阵表示的方法,很好)。
然后, 计算在当前帧的目标搜索层数。通过计算仿射矩阵 A_cur_ref 的行列式,其实就是面积放大率。如果面积放大率超过3,就往上一层,面积放大率变为原来的四分之一。知道面积放大率不再大于 3,或者到最高层。就得到了目标要搜索的层数。
然后,计算仿射矩阵的逆仿射矩阵 A_ref_cur。然后,这样子,如果以投影点为中心(5,5),取 10x10 的图块,则图块上每个像素点的(相对中心点的) 位置,都可以通过逆仿射矩阵,得到对应的参考帧上的对应层数图像上的(相对中心点的) 像素位置。进行像素插值。就是,把参考帧上的特征点附近取一些像素点过来,可以组成, 映射到当前帧上的对应层数的投影点位置的附近,这些映射到的位置刚好组成 10x10 的图块。
然后, 从映射过来的 10x10 的图块中取出 8x8 的图块,作为参考图块。对这个图块的位置进行优化调整,使得它与目标位置的图块匹配。
在这里, SVO 有两个创新点。
第一个创新的地方是。因为一般情况下,是基于自己图块不变,通过优化u'使得投影位置的图块跟自己最接近。而 SVO 是投影位置的图块不变, 通过优化u使得自己图块与投影位置的图块最接近。这样的话,就可以避免重复计算投影位置图块像素关于位置的雅克比了。因为自己图块是固定的,所以雅克比是固定的,所以只需要计算一次。其实,这个创新点与 1.2 中的反向创新点一样,都是用近似优化的方法来。因为,如果是一般的方法的话,计算目标投影位置的图块的雅克比,是知道自己参考图块重新移动后,会遇到怎样的目标图块。而这个反向的方法,并不知道重新移动后会遇到怎样的图块,只知道移动后,对当前的目标图块可以匹配得更好。也是一种迭代,近似优化的方法,但速度可以块很多,避免了重复计算雅克比。
第二个创新的地方是。一般情况下,两图块的均值差m,都是直接把两个图块的均值相减的。但是,这样子的话,可能容易受某些极端噪声的影响。所以, SVO 中,直接把m也作为优化变量了。
1.4 进一步优化位姿和地图点
针对每个地图点, 优化地图点的三维位置, 使得它在它被观察到的每个关键帧上的重投影误差最小。 每个地图点优化 5 次。
如果这次优化的误差平方和小于上次优化的误差平方和,就接受这次的优化结果。(注意,这里的平方和也是在优化之前算的,其实应该在优化之后算)。如果是边缘点的话,则把重投影误差映射到梯度方向上,成为梯度方向上的模,就是与梯度方向进行点积。相应的,雅克比也左乘对应的梯度方向。相当于是,优化重投影误差在梯度方向上的映射。
2.创建地图点
特征点提取的方法,放在了地图线程里。因为与 ORBSLAM 不同的是,它跟踪的时候,不需要找特征点再匹配,而是直接根据图块亮度差匹配的。而如果是 vins 的话,也可以参考这个方法,把特征点提取放到地图线程里,连续帧之间的特征点用光流匹配。但光流要求帧与帧之间不能差别太大。
而在 SVO 中,后端的特征点是只在关键帧上提取的,用 FAST 加金字塔。而上一个关键帧的特征点在这一个关键帧上找匹配点的方法,是用极线搜索,寻找亮度差最小的点。最后再用 depthfilter 深度滤波器把这个地图点准确地滤出来。
选取 30 个地图点,如果这 30 个地图点在当前帧和最近一个关键帧的视差的中位数大于 40, 或者与窗口中的关键帧的距离大于一定阈值, 就认为需要一个新的关键帧。然后把当前帧设置为关键帧,对当前帧进行操作。
SVO 中重定位,实现很简单,就是在跟丢之后,仍然假设当前帧的位姿和前一帧一样,往这个位姿上投地图点,用第 1 部分中的方法去优化计算,如果优化成功,就重定位回来,如果优化不成功,就继续下一帧。所以,在跟丢后,只能再回到跟丢时的位置,才能重定位回来。
SVO 在运动估计中的思路很新颖,运行速度非常快,由于不用计算描述子,也不用处理过多的地图点云,在普通 PC上也能达到 100 Frame /S 以上。
但是正因为它的目标应用平台是无人机,所以它在其他的场合应用是不适合的,至少是需要修改的。例如在单目初始化时,是采用分解 H,这需要假设前两个关键帧的特征点位于一个平面上。再者,在关键帧的选取策略上,采用的是平移量,没有考虑旋转。而且它是一个轻量级的相机运动估计,没有闭环功能,没有重定位,建图功能也基本没有,即使如此,它也不失为一个优秀的SLAM-DEMO。
2016 年, Forster 等人对 SVO 进行改进,形成 SVO2.0 版本,新的版本作出了很大的改进,增加了边缘的跟踪,并且考虑了 IMU 的运动先验信息,支持大视场角相机(如鱼眼相机和全景相机)和多相机系统。
值得一提的是, Foster 对 VIO 的理论也进行了详细的推导, 尤其是关于预积分的论文成为后续 VSLAM 系统融合 IMU 的理论指导。
SVO 的定位很好,抖动很小。尤其在重复纹理的环境中,表现得比基于特征点法的 ORBSLAM2 要出色。将来可以在上面增加更鲁棒的重定位,回环闭环,全局地图的功能,来满足更多的实际应用场景,比如室内机器人、无人机、无人车。
参考:
1. Forster C, Pizzoli M, Scaramuzza D. SVO: Fast semi-direct monocular visual odometry[C]// IEEE International Conference on Robotics and Automation.
IEEE, 2014:15-22.
2. https://blog.csdn.net/heyijia0327/article/details/51083398
3. https://www.cnblogs.com/luyb/p/5773691.html
4. 《视觉SLAM十四讲:从理论到实践 第2版》高翔等人
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~