
LightGBM——提升机器算法(图解+理论+安装方法+python代码)
https://blog.csdn.net/huacha__/article/details/81057150
前言
LightGBM是个快速的,分布式的,高性能的基于决策树算法的梯度提升框架。可用于排序,分类,回归以及很多其他的机器学习任务中。
在竞赛题中,我们知道XGBoost算法非常热门,它是一种优秀的拉动框架,但是在使用过程中,其训练耗时很长,内存占用比较大。在2017年年1月微软在GitHub的上开源了一个新的升压工具--LightGBM。在不降低准确率的前提下,速度提升了10倍左右,占用内存下降了3倍左右。因为他是基于决策树算法的,它采用最优的叶明智策略分裂叶子节点,然而其它的提升算法分裂树一般采用的是深度方向或者水平明智而不是叶,明智的。因此,在LightGBM算法中,当增长到相同的叶子节点,叶明智算法比水平-wise算法减少更多的损失。因此导致更高的精度,而其他的任何已存在的提升算法都不能够达。与此同时,它的速度也让人感到震惊,这就是该算法名字 灯 的原因。
-
2014年3月,XGBOOST最早作为研究项目,由陈天奇提出 (XGBOOST的部分在我的另一篇博客里: -
2017年1月,微软发布首个稳定版LightGBM 在微软亚洲研究院AI头条分享中的「LightGBM简介」中,机器学习组的主管研究员王太峰提到:微软DMTK团队在github上开源了性能超越其它推动决策树工具LightGBM后,三天之内星了1000+次,叉了超过200次。知乎上有近千人关注“如何看待微软开源的LightGBM?”问题,被评价为“速度惊人”,“非常有启发”,“支持分布式” “代码清晰易懂”,“占用内存小”等。以下是微软官方提到的LightGBM的各种优点,以及该项目的开源地址。

**科普链接:**如何玩转LightGBM https://v.qq.com/x/page/k0362z6lqix.html
目录
一、"What We Do in LightGBM?"
下面这个表格给出了XGBoost和LightGBM之间更加细致的性能对比,包括了树的生长方式,LightGBM是直接去选择获得最大收益的结点来展开,而XGBoost是通过按层增长的方式来做,这样呢LightGBM能够在更小的计算代价上建立我们需要的决策树。当然在这样的算法中我们也需要控制树的深度和每个叶子结点的最小数据量,从而减少过拟合。
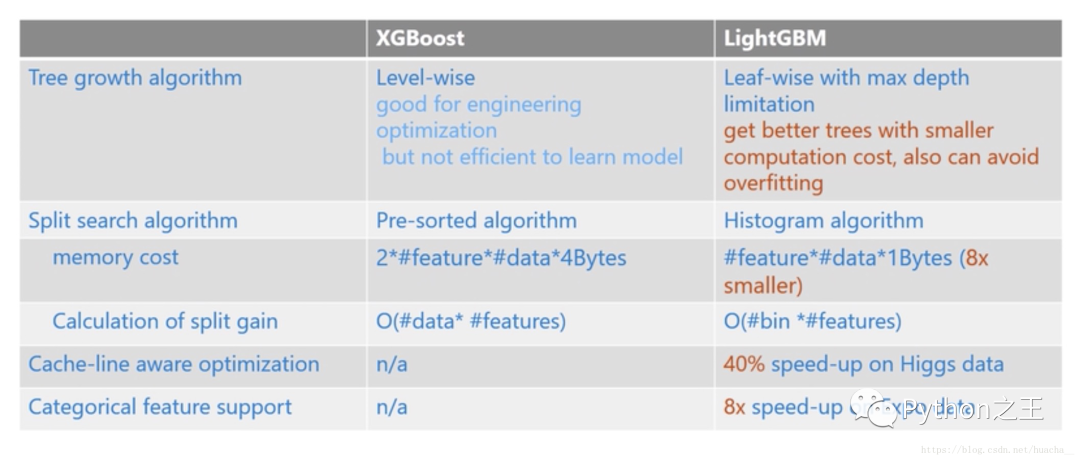
小小翻译一下,有问题还望指出
**XGBoost****LightGBM** 树木生长算法 **按层生长的方式** 有利于工程优化,但对学习模型效率不高 直接**选择最大收益的节点**来展开,在更小的计算代价上去选择我们需要的决策树 控制树的深度和每个叶子节点的数据量,能减少过拟合有利于工程优化,但对学习模型效率不高
控制树的深度和每个叶子节点的数据量,能减少过拟合
划分点搜索算 法对特征预排序的方法直方图算法:将特征值分成许多小筒,进而在筒上搜索分裂点,减少了计算代价和存储代价,得到更好的性能。另外数据结构的变化使得在细节处的变化理上效率会不同 内存开销8个字节1个字节 划分的计算增益数据特征容器特征 高速缓存优化无在Higgs数据集上加速40% 类别特征处理无在Expo数据集上速度快了8倍二、在不同数据集上的对比
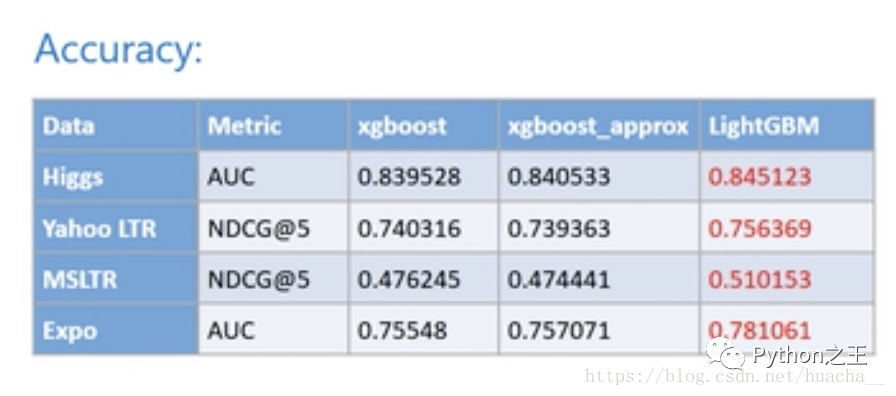
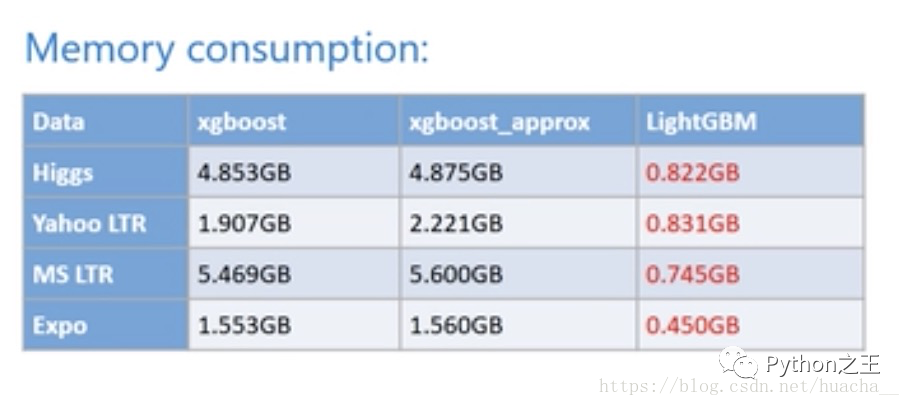
higgs和expo都是分类数据,yahoo ltr和msltr都是排序数据,在这些数据中,LightGBM都有更好的准确率和更强的内存使用量。
准确率
内存使用情况
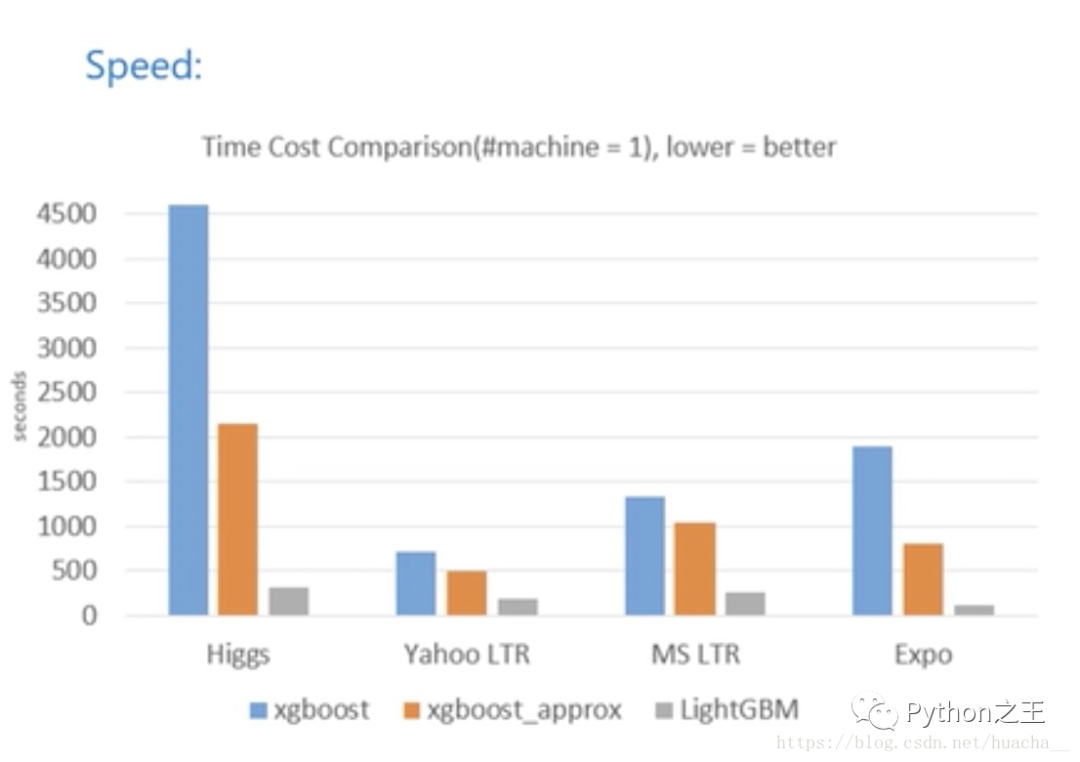
计算速度的对比,完成相同的训练量XGBoost通常耗费的时间是LightGBM的数倍之上,在higgs数据集上,它们的差距更是达到了15倍以上。
三、LightGBM的细节技术
1、直方图优化
XGBoost中采用预排序的方法,计算过程当中是按照value的排序,逐个数据样本来计算划分收益,这样的算法能够精确的找到最佳划分值,但是代价比较大同时也没有较好的推广性。
在LightGBM中没有使用传统的预排序的思路,而是将这些精确的连续的每一个value划分到一系列离散的域中,也就是筒子里。以浮点型数据来举例,一个区间的值会被作为一个筒,然后以这些筒为精度单位的直方图来做。这样一来,数据的表达变得更加简化,减少了内存的使用,而且直方图带来了一定的正则化的效果,能够使我们做出来的模型避免过拟合且具有更好的推广性。
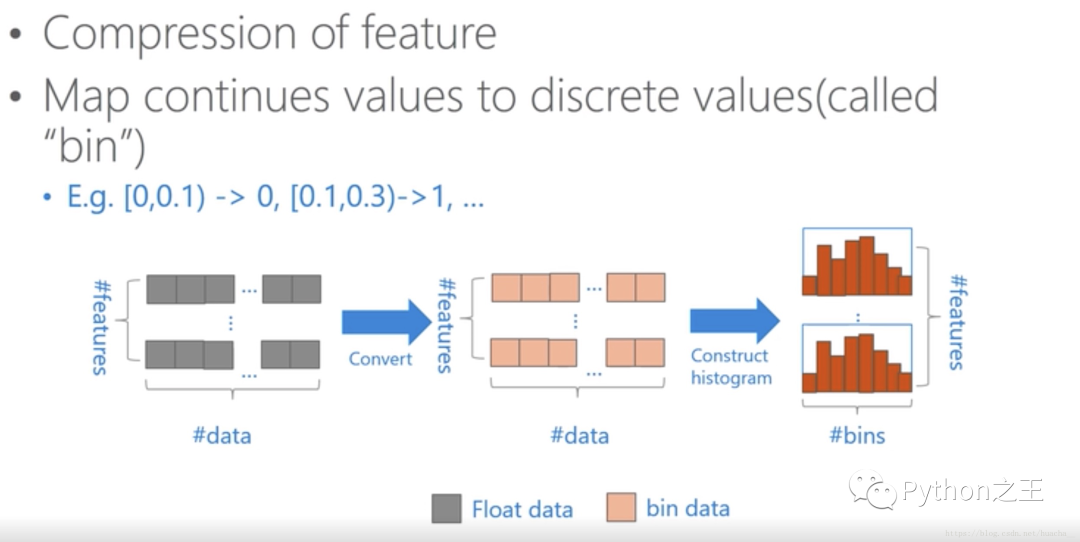
看下直方图优化的细节处理

可以看到,这是按照bin来索引“直方图”,所以不用按照每个“特征”来排序,也不用一一去对比不同“特征”的值,大大的减少了运算量。
2、存储记忆优化
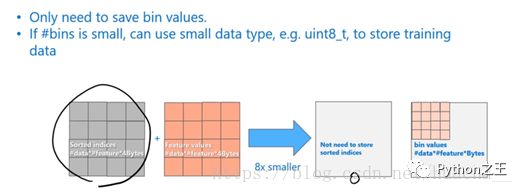
当我们用数据的bin描述数据特征的时候带来的变化:首先是不需要像预排序算法那样去存储每一个排序后数据的序列,也就是下图灰色的表,在LightGBM中,这部分的计算代价是0;第二个,一般bin会控制在一个比较小的范围,所以我们可以用更小的内存来存储
3、深度限制的节点展开方法
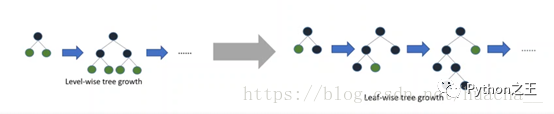
LightGBM使用了带有深度限制的节点展开方法(Leaf-wise)来提高模型精度,这是比XGBoost中Level-wise更高效的方法。它可以降低训练误差得到更好的精度。但是单纯的使用Leaf-wise可能会生长出比较深的树,在小数据集上可能会造成过拟合,因此在Leaf-wise之上多加一个深度限制
4、直方图做差优化
直方图做差优化可以达到两倍的加速,可以观察到一个叶子节点上的直方图,可以由它的父亲节点直方图减去它兄弟节点的直方图来得到。根据这一点我们可以构造出来数据量比较小的叶子节点上的直方图,然后用直方图做差来得到数据量比较大的叶子节点上的直方图,从而达到加速的效果。

5、顺序访问梯度
预排序算法中有两个频繁的操作会导致cache-miss,也就是缓存消失(对速度的影响很大,特别是数据量很大的时候,顺序访问比随机访问的速度快4倍以上 )。
-
对梯度的访问:在计算增益的时候需要利用梯度,对于不同的特征,访问梯度的顺序是不一样的,并且是随机的- 对于索引表的访问:预排序算法使用了行号和叶子节点号的索引表,防止数据切分的时候对所有的特征进行切分。同访问梯度一样,所有的特征都要通过访问这个索引表来索引。这两个操作都是随机的访问,会给系统性能带来非常大的下降。
LightGBM使用的直方图算法能很好的解决这类问题。首先。对梯度的访问,因为不用对特征进行排序,同时,所有的特征都用同样的方式来访问,所以只需要对梯度访问的顺序进行重新排序,所有的特征都能连续的访问梯度。并且直方图算法不需要把数据id到叶子节点号上(不需要这个索引表,没有这个缓存消失问题)
6、支持类别特征
传统的机器学习一般不能支持直接输入类别特征,需要先转化成多维的0-1特征,这样无论在空间上还是时间上效率都不高。LightGBM通过更改决策树算法的决策规则,直接原生支持类别特征,不需要转化,提高了近8倍的速度。

7、支持并行学习
LightGBM原生支持并行学习,目前支持特征并行(Featrue Parallelization)和数据并行(Data Parallelization)两种,还有一种是基于投票的数据并行(Voting Parallelization)
-
特征并行的主要思想是在不同机器、在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。- 数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。LightGBM针对这两种并行方法都做了优化。 -
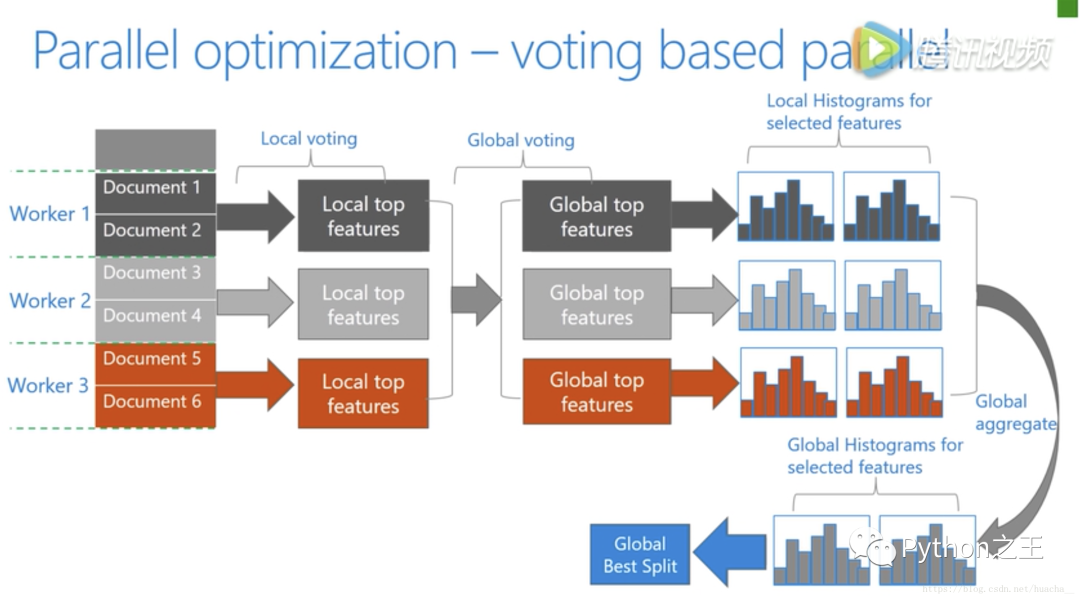
特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信。- 数据并行中使用分散规约 (Reduce scatter) 把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减少了一半的通信量。- **基于投票的数据并行(Voting Parallelization)**则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。下图更好的说明了以上这三种并行学习的整体流程:
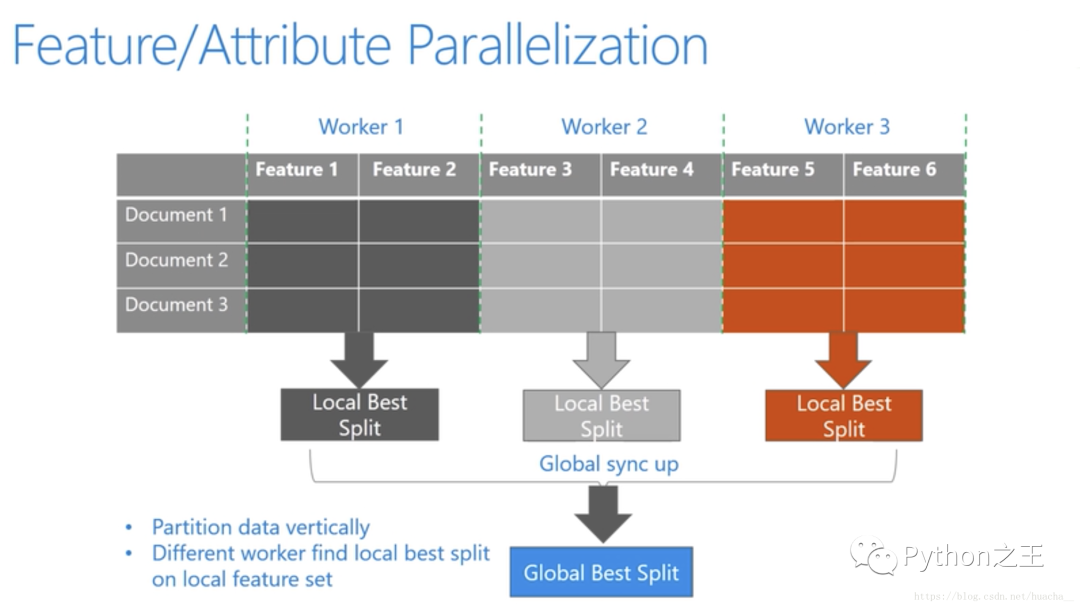
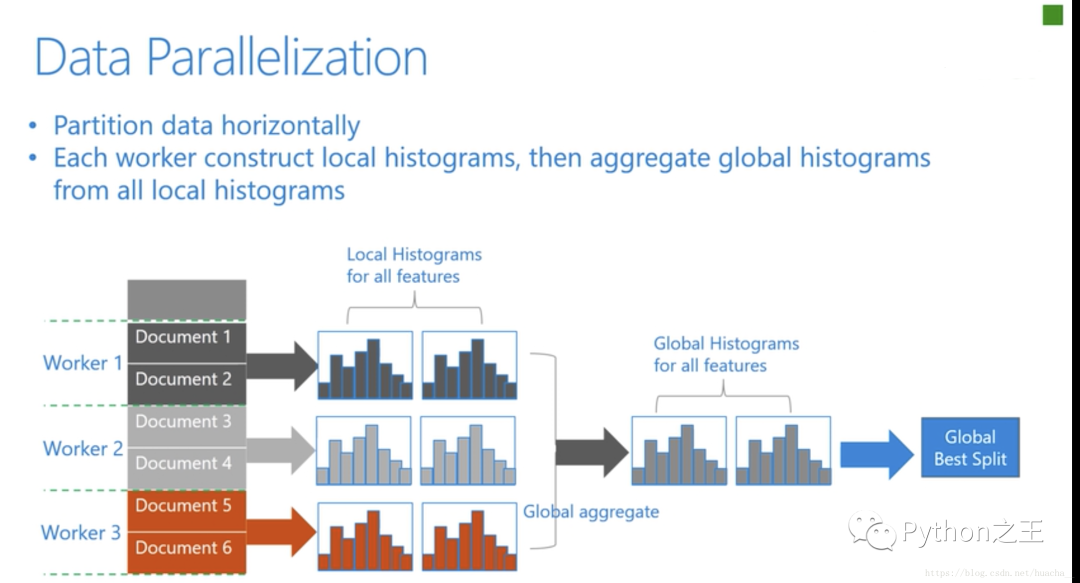
在直方图合并的时候,通信代价比较大,基于投票的数据并行能够很好的解决这一点。
四、MacOS安装LightGBM
#先安装cmake和gcc,安装过的直接跳过前两步
brew install cmake
brew install gcc
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
#在cmake之前有一步添加环境变量
export CXX=g++-7 CC=gcc-7
mkdir build ; cd build
cmake ..
make -j4
cd ../python-package
sudo python setup.py install
来测试一下:

大功告成!
值得注意的是:pip list里面没有lightgbm,以后使用lightgbm需要到特定的文件夹中运行。我的地址是:
/Users/ fengxianhe / LightGBM /python-package
五,用python实现LightGBM算法
为了演示LightGBM在蟒蛇中的用法,本代码以sklearn包中自带的鸢尾花数据集为例,用lightgbm算法实现鸢尾花种类的分类任务。
# coding: utf-8
# pylint: disable = invalid-name, C0111
# 函数的更多使用方法参见LightGBM官方文档:http://lightgbm.readthedocs.io/en/latest/Python-Intro.html
import json
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
iris = load_iris() # 载入鸢尾花数据集
data=iris.data
target = iris.target
X_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2)
# 加载你的数据
# print('Load data...')
# df_train = pd.read_csv('../regression/regression.train', header=None, sep='\t')
# df_test = pd.read_csv('../regression/regression.test', header=None, sep='\t')
#
# y_train = df_train[0].values
# y_test = df_test[0].values
# X_train = df_train.drop(0, axis=1).values
# X_test = df_test.drop(0, axis=1).values
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(X_train, y_train) # 将数据保存到LightGBM二进制文件将使加载更快
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train) # 创建验证数据
# 将参数写成字典下形式
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
print('Start training...')
# 训练 cv and train
gbm = lgb.train(params,lgb_train,num_boost_round=20,valid_sets=lgb_eval,early_stopping_rounds=5) # 训练数据需要参数列表和数据集
print('Save model...')
gbm.save_model('model.txt') # 训练后保存模型到文件
print('Start predicting...')
# 预测数据集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration) #如果在训练期间启用了早期停止,可以通过best_iteration方式从最佳迭代中获得预测
# 评估模型
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5) # 计算真实值和预测值之间的均方根误差
输出结果:
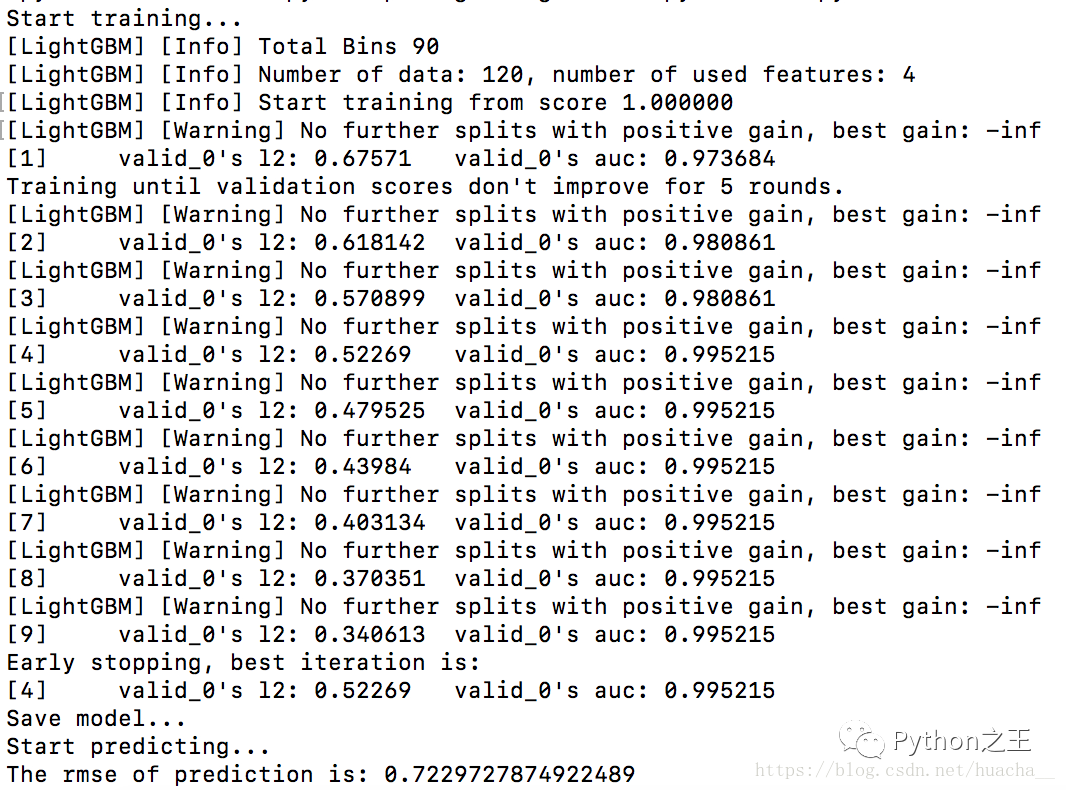
可以看到预测值和真实值之间的均方根误差为0.722972。


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。