
基于Flink打造实时计算平台为企业赋能
点击上方蓝色字体,选择“设为星标”




随着互联网技术的广泛使用,信息的实时性对业务的开展越来越重要,特别是业务的异常信息,没滞后一点带来的就是直接的经济损失。所以实时信息处理能力,越来越成为企业的重要竞争力之一。Flink作为业内公认的性能最好的实时计算引擎,以席卷之势被各大公司用来进处理实时数据。然而Flink任务开发成本高,运维工作量大,面对瞬息万变得业务需求,工程师往往是应接不暇。如果能有一套实时计算平台,让工程师或者业务分析人员通过简单的SQL或者拖拽式操作就可以创建Flink任务,无疑可以快速提升业务的迭代能力。
1. 方法论—Lambda架构
如何设计大数据处理平台呢?目前业界基本都是采用了Lambda架构(Lambda Architecture),该架构是由工程师南森·马茨(Nathan Marz)在BackType和Twitter的大数据处理实践中总结出的,示意图如下。
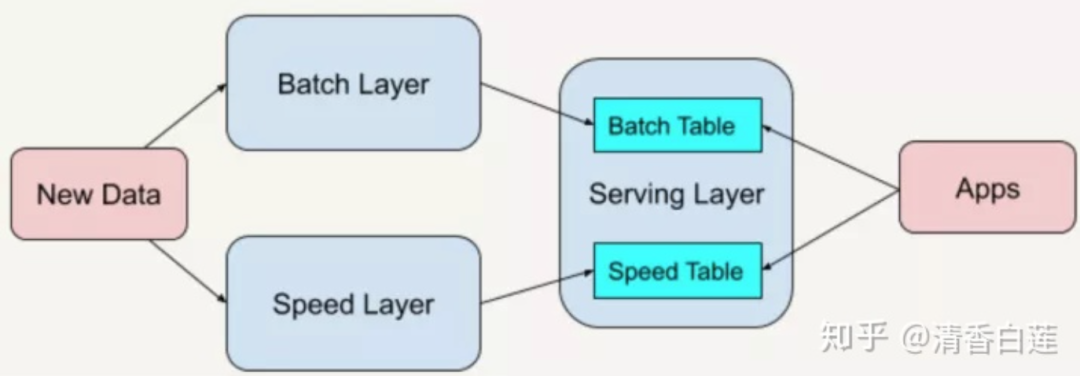
Lambda 共分为三层,分别是批处理层(Batch Layer),速度处理层(Speed Layer),以及服务层(Serving Layer),用途分别如下:
批处理层(Batch Layer),存储管理主数据集和预先批处理计算好的视图。这部分数据对及时性要求不高,但对准确性要求较高,会以批处理的方式同步到主库中,处理过程通常以定时任务的形式存在。
速度处理层(Speed Layer),负责处理实时数据。这部分数据需要实时的计算出结果,支持随时供用户查看,通常对准确性要求不高,主要通过流式计算引擎计算出结果。通常这些数据最终还是会通过批处理层入库,并针对部分计算结果进行校验。
服务层(Serving Layer),数据进入到平台以后,会进行存储、同步、计算、分析等一系列分析计算过程。但是,最终都是需要提供给用户使用的。针对业务需求的差异性,会有一个服务层将提炼出的数据以报表、仪表盘、API 接口等形式提供给用户。
具体如何落实,主要有两种方式,业务场景和通用组件来进行。
自底向上:从业务场景需求出发,先做苦逼的数据搬运工,再从中总结出重复与最耗时的工作进行平台化组件化,一步步堆砖头添瓦,建立大数据平台。这种方式可以让数据针对具体的业务发挥作用,一开始效率非常低,需要大量的人肉工作,复杂的业务需求甚至需要资深的大数据开发工程师花费多个人日才能处理。在平台建设的过程中,平台也可能会面临不断重构的风险。工程团队与业务部门工作耦合度太高,消耗太多沟通成本。
自顶向下:先磨刀再砍柴,将大数据平台中和具体的业务实现无关的通用功能组件抽离出来,做成简单易用的数据产品,常见的需求可以通过SQL或者简单的拖拽操作就能完成。这种方式处理需求效率高,门槛低,平台做的好业务部们都可以自己分析数据,而且工程师与业务部门工作耦合度低,可以花更多时间再平台建设上。但前期投入成本大,对产品经理/架构师的经验要求非常高,要能使开发的产品再未来很好的业务使用需求,否则很可能变成造轮子。
这两种方式各有优缺点,具体采用哪种方式,可实际根据业务的特点来选择,但更多的是两种方式穿插采用。
2. 功能设计
Flink提供了多层的API,越上层的API使用起来越简单,但灵活性受限。越底层的API功能越强大,但对开发能力要求越高。

2.1 SQL定义任务
根据Uber的使用经验,70%的流处理任务都可以用SQL实现,再结合UDF,基本上一般需求都能解决,业内的大数据处理平台上任务大部分都是也是以SQL+UDF的方式实现的,比如Hive,Dataworks,EasyCount与SparkSQL等。所以平台开发语言以SQL为主,可以让没有大数据开发能力的业务分析人员就可以使用。通过SQL定义Flink任务的设计如下:
用DDL创建源表、(维表)、结果表;
用DML定义计算任务。
定义任务参数,如计算资源、最大并行度、udf的jar包位置等。
示例如下:

目前(Flink 1.10)已经实现了很多外部数据connector的DDL支持,对于不支持的数据源也可以通过扩展Calcite语法,自己解析DDL,将source或sink的目标对象映射成关系表。
Flink SQL得解析能力较弱,嵌套太多与太过复杂的SQL可能会解析失败,所以INSERT语句不宜太复杂,可以添加对创建视图的DDL的支持,简化对SQL子查询的多次嵌套引用。这项功能在未来的Flink中会得到支持,具体详见FLIP-71。目前可以通过在TableEnvironment API中将SELECT语句的执行结果注册为Table对象来实现。
Table table = tableEnvironment.sqlQuery("SELECT user_id, user_name, login_time FROM user_login_log");
tableEnvironment.registerTable("table_name", table);此外为了方便debug,可以实现对select语句的支持,直接打印处理结果,而不是sink到外部存储。
然而SQL并非是图灵完备语言,对于部分复杂的功能需求,可能很难甚至无法用SQL实现。这时候平台需要支持让用户将自几开发的Jar包上传到平台去运行。
有了这两项功能基本上已经可以满足所有的使用需求了,产品在此基础上可以做得更加傻瓜化,也就是通过拖拽式操作来定义流失计算任务。
2.2 用户自定义Jar
对于某些计算任务可能通过SQL定义的话执行效率不高,通过Java或者Scala调用Flink更底层的API会更好,这时候我们希望平台支持运行用户自定义Jar。实现方案如下:
要求用户将Jar上传到HDFS或者其他文件系统,并在任务配置里面指定Jar的位置与执行命令;
任务提交时,平台会解析任务配置,从文件系统下载用户Jar包,并执行任务的启动命令。
2.3 拖拽式操作
为了进一步降低使用门槛或者提升开发效率,可以实现通过拖拽式操作来定义任务。其原理时将数据处理常见的SELECT、JOIN、Filter、INSERT操作以及Sink、Source Table和各种UDF等定义成流程图中的节点,用户定义完流程图后,平台将流程图转化成SQL或者直接转化成Flink代码去执行。
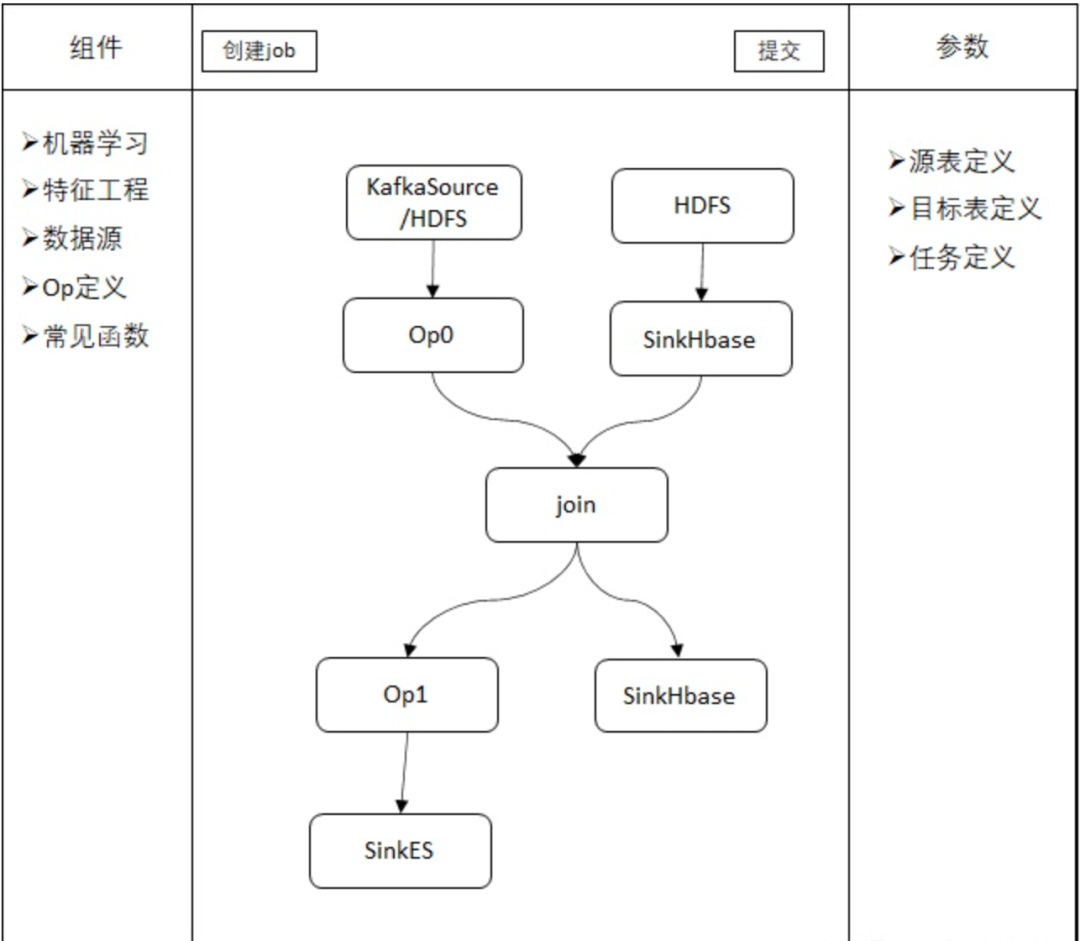
3. 平台架构设计
Flink通过对数据抽象成流表,实现了批流一体化的任务设计,即同一套代码即可以用于批处理也可以用于处理流失数据,只需要修改数据源即可,处理逻辑完全不需要变。这就对实现Lamda架构具备了天然优势,不再需要专门的批处理引擎。整个平台的架构设计如下
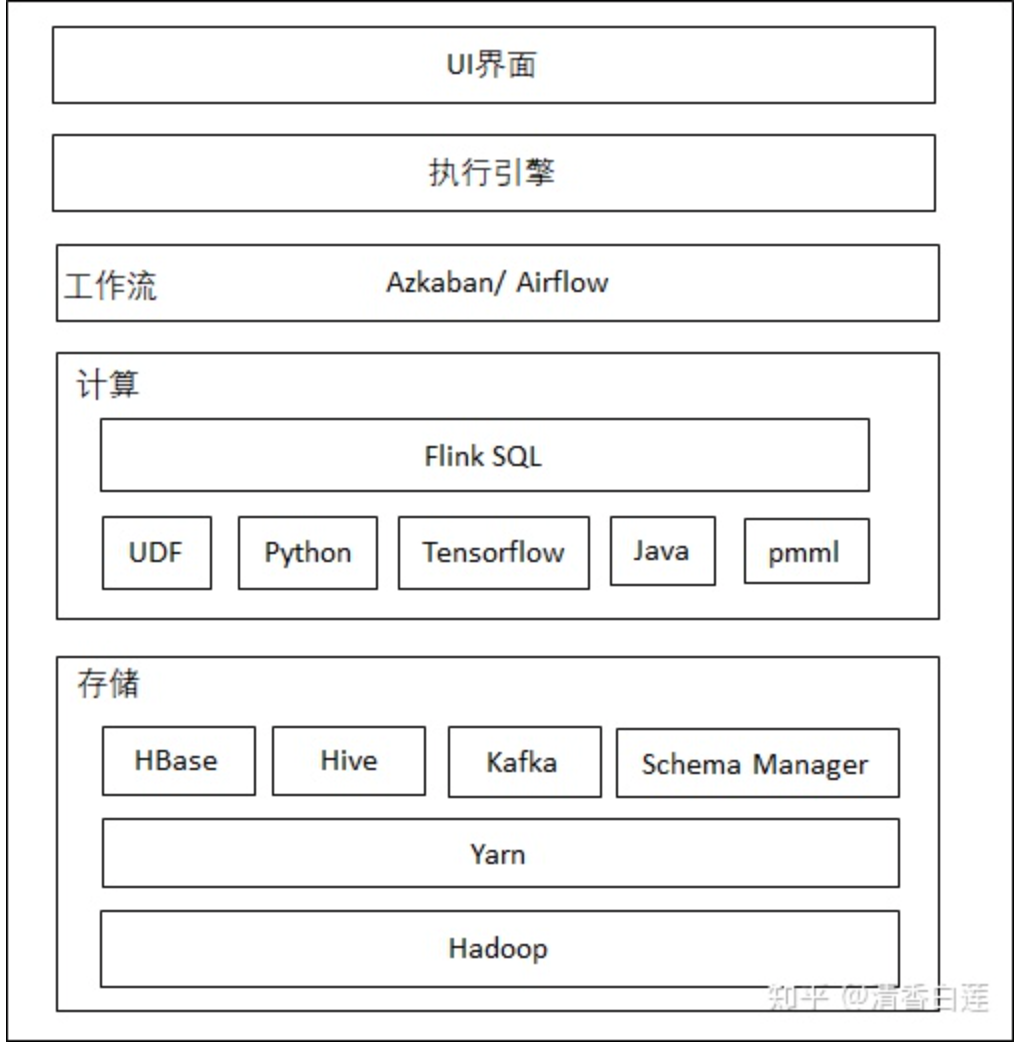
最上层为UI界面,常见任务有相应的Op实现,自定义任务采用Flink SQL与UDF或者用户Jar。
执行引擎将前端定义的业务流程通过Flink SQL API翻译成Flink Job。
通过workflow对任务进行调度。
在下面是负责执行计算的flink,以及它可能会调用的其他框架,如机器学习、NLP等任务会调用tensorflow,stanford cornlp等。
最底层是物理集群,除了Flink任务外,外部数据存储系统如HDFS、Hbase、Kafka等也可以跑在这个公共集群上。集群的管理通过Yarn或者K8S实现。
4. 集群资源管理
目前Flink已经实现了在Yarn集群上的稳定运行,只要在Flink客户端有Hadoop配置文件,就可以在客户端通过Bash命令直接向Yarn集群提交Flink任务,业内主要也是用Yarn来管理运行Flink任务的集群资源的,如Uber的AthenaX。Flink on Yarn提供了两种运行模式:
Session模式:先启动一个Flink集群,然后像该集群提交任务,不同任务共用一个JobManager,即便没有提交任务。由于需要预先启动一个Flink集群,即便没有任务运行,这部分物理集群资源也不能被回收;
Per-Job模式:为每个任务单独启动一个集群,每个任务独立运行,物理集群资源可以根据任务数量按需申请。
这两种方式各有优缺点,一般而言,如果式以频繁提交的短期任务,如批处理为主,则适合Session模式,如果以长期运行的流式任务为主,则适合用Per-Job模式。
K8S提供了更强大的集群资源管理工具,具有更好的用户体验,已经发展为云服务厂商首选的资源管理与任务调度工具。Flink on K8S也是未来的发展趋势,Flink社区也提供了相应的docker image与K8S资源配置文件,用于在K8S集群中启动Flink集群运行Flink任务。在Flink 1.11中将支持直接从Flink客户端提交任务到K8S集群的功能。
5. 任务提交
有两种模式可以将Flink任务提交到集群去执行,即Client模式与Application模式,其中Application模式尚且不成熟,目前主要采用Client模式。
5.1 Client模式
在Client模式中,任务的提交需要有一个Flink Client,将任务需要的相关jar或者UDF都下载到本地,然后通过flink command编译出任务的JobGraph,再将JobGraph与相关依赖提交给集群去执行。目前业内主要有两者实现方式,个人推荐第二种方式:
启动一个client,所有作业都通过这个client去提交的,因为用的是同一个进程,所以不能加载 过多的jar包,还要注意不同任务之间UDF的冲突。
为每一个任务单独启动一个client进程(容器),在这个进程内下载需要的jar包,编译出任务的JobGraph,并提交任务。这样可以做到每个用户用到的jar包或UDF不会冲突。

5.2 Application模式
在Client模式的缺点很显著,如果请求量大的话,同一时刻Client需要下载大量jar包,并消耗大量CPU资源去编译JobGraph,无论是网络还是CPU都很容易成为系统瓶颈。
针对Client模式的确定,社区提出了Application模式,只需要将任务所需要地资源文件上传到集群,在集群中完成Flink JobGraph的编译与任务地执行。Application模式社区也提出了两种提交方式。
Flink-as-a-library
顾名思义,把flink本身作为需要本地化的依赖,用户程序的main函数就是一个自足的应用,因此可以直接用yarn命令来提交任务。
yarn jar MY_FLINK_JOB.jar myMainClass args...但如果集群是HA部署的话,同一时刻会有多个竞争者执行用户程序的main函数,但最后被选中的leader只有一个,其他进程需要自己退出main函数。这种打断进程的操作需要抛异常来实现,这点在编程上很不优雅。并且用户对Flink集群的生命周期管理受限于execute()的时间窗口。
所以社区最终采纳的是下面的ClusterEntrypoint模式。
ClusterEntrypoint
实现一个新的ClusterEntrypoint 即 ApplicationClusterEntryPoint ,其生命周期与用户任务的main函数一致。它主要做以下这些事情
下载用户jar与相关依赖资源;
选举leader去执行用户程序的main函数;
当用户的main函数执行结束后终止该Flink集群;
确保集群的HA与容错性。
所以这种模式整个Flink集群的生命周期由ApplicationClusterEntryPoint,拥有更大的灵活性。目前该功能尚且处于开发阶段,预计会在Flink 1.11中发布,具体进展详见FLIP-85。
此外如果采用的是Session模式在跑Flink on Yarn的话,还可以通过Web API来提交任务。
6. 任务编排
对于单个任务或者流式任务的编排,主要就是每个任务的优先级问题,一般直接使用Yarn的调度功能就够了。Yarn内置了三种调度器,并且支持优先级分数的设置与优先级ACL,一般需求都能满足。
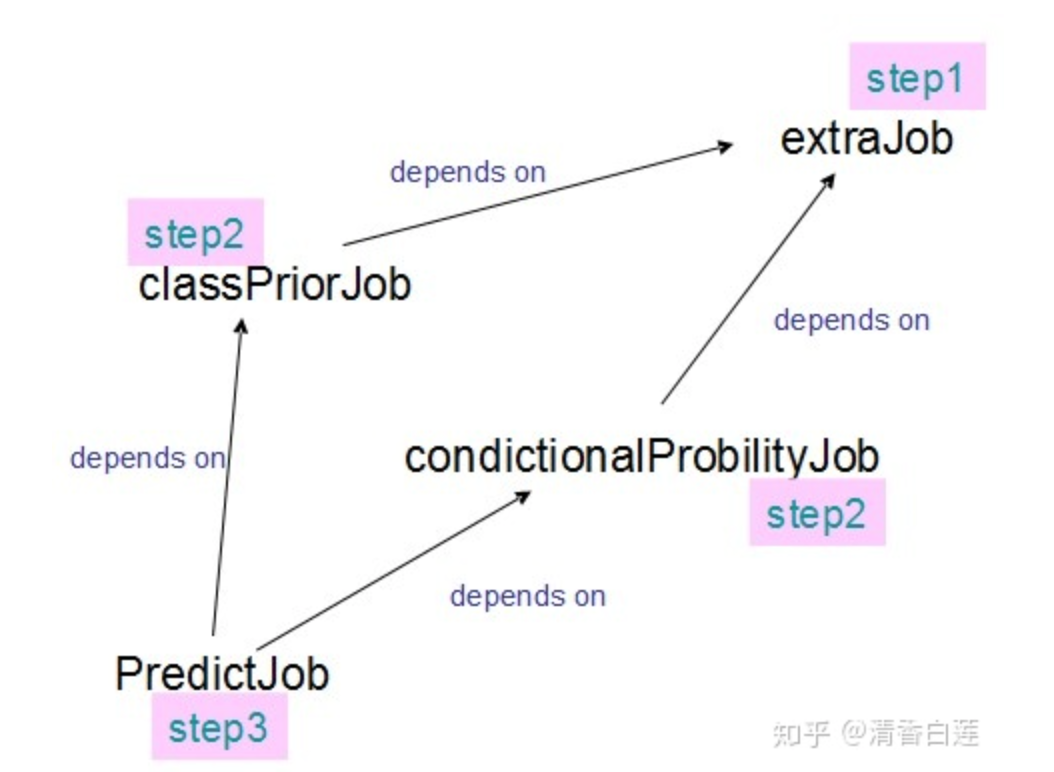
对于批处理任务,整个pipeline中一般存在多个子任务,不同子任务的执行次序存在依赖关系。这时候一般采用专业的workflow框架去编排这些子任务,workflow框架会对这些子任务进行拓扑排序,再去调度执行。常见的workflow有Airflow、Azkaban、Oozie、Conductor等,其中Airflow最为流行,但是它是个python项目,workflow也是用python定义的,Azkaban社区也较为活跃,原生支持Hadoop生态的任务,用户体验也较好。
7. 权限管理
平台的建立最终是为用户服务的,这就需要考虑用户的多样性,可能是企业内部客户、合作伙伴还有终端用户。平台需要根据不同用户的不i同权限,提供不同的服务。在平台建设过程中通常需要考虑:
用户的权限和角色管理。
业务分组功能,针对业务分类、子分类对用户进行划分。
根据数据功能进行不同的安全等级管理,包括流程管理、血缘关系的管理等。
支持对元数据的检索和浏览。
对于权限管理问题,Hadoop采用了Kerberos模块来实现客户端的身份认证与ACL,在Flink on Yarn布署中,目前已经支持在flink客户端实现Kerberos认证。
Kerberos只能提供服务器之间的认证,企业需要更加精细化的权限控制,还需要更加复杂的ACL模块,甚至是企业自己实现的ACL模块。在Flink 1.11中安全访问控制模块将被实现为可插拔的而模块,任何第三方的ACL模块都可以轻松的集成进来。
8. 元数据管理
元数据的管理是数仓建设必不可少的部分,可以让用户知道平台中存在哪些数据,他们的结构是什么样子,以及他们之间的关系。这样一来,很多业务需求可以在已有的数据源的基础上做些简单的计算就可以满足,减少了大量的重复计算工作。
8.1 表管理
Hive提供了丰富的元数据存储查询功能,Flink可以通过HiveCatalog来使用Hive的元存储功能来实现跨session管理自己的元数据。用户可以在某个任务里面将它的Kafka或者ElasticSerach表的Schema存入Hive的元数据库,然后在另一个任务中通过HiveCatalog直接获取并使用这些表。
此外Flink还可以直接读写Hive表。
8.2 血缘关系管理
可以通过解析每个flink sql任务的source、sink表以及维表,这样就可以建立这些表之间的血缘关系。
9. 日志收集
日志可以帮助我们观察整个作业运行的情况,尤其是在job出问题之后,可以帮助我们复现问题现场,分析原因。对于本地无法debug的代码,也可以通过运行日志来辅助debug。所以收集任务的运行日志,对平台的建设是必不可少的。
由于flink任务的运行过程是先在客户端编译成JobGraph,再提交到Flink集群运行,所以每个任务的日志包括客户端的提交日志与任务在集群上的运行日志。
9.1 client日志
Flink客户端默认使用的日志框架是log4j,可以通过修改conf/log4j-cli.properties文件对客户端日志的输出进行设置。如进行如下设置可以将flink客户端INFO级别的日志输出到控制台与文件中。
log4j.rootLogger=INFO, file, console可以将通过配置输出到邮件、消息队列或者数据库等,也可以通过自定义的Appender或者公司统一的日服API上报到公司统一的日志采集系统(如Flume、fluentd或者kafka等)。实际可根据平台的架构与用户量将客户端日志输出到合适的位置供用户查看。
9.2 cluster日志
如果Flink是运行在 YARN 上,YARN 会帮我们做这件事,例如在 Container 运行完成时,YARN 会把日志收集起来传到 HDFS,可以用命令 yarn logs -applicationId
当然实际应用中不大可能让用户这样查看日志,一般还是要将日志上报到专业的日志服务框架如EFK中,用户通过报表(如Kibana)或者API来查看,甚至配置邮件短信报警等。我们利用基于Flume的Log4j Appender 定制了自己的日志收集器,从服务器异步发送日志到Kafka中,再通过Kafka将日志传到日服的数据库中(一般是Elasticsearch)。这样可以尽可能地降低日志采集对运行作业的影响。
如果Flink是运行再K8S 上,K8S本身并没有提供日志收集功能,目前一般是使用 fluentd来收集日志。
fluentd是一个CNCF项目,它通过配置一些规则,比如正则匹配,就可以将logs目录下的*.log 、*.out 及 *.gc日志定期的上传到 HDF 或者通过kafa写入Elasticsearch 集群,以此来解决我们的日志收集功能。这也意味着在Flink集群的POD里面,除了运行TM或JM容器之外,我们需要再启动一个运行着fluentd进程的容器(sidecar)。
10. 监控报警
在job出问题后,虽然日志可以帮助我复现问题现场,分析原因。但最好还是可以实时监控任务的运行状况,出现问题能及时报警,好做出应急措施,防止发生生产事故。目前业界已经有很多种监控系统解决方案,比如在阿里内部使用比较多的 Druid、开源InfluxDB 或者商用集群版 InfluxDB、CNCF的 Prometheus 或者 Uber 开源的 M3 等等。
10.1 Prometheus
Prometheus是一个开源的,基于metrics(度量)的一个开源监控系统,诞生于2012年,主要是使用go语言开发的,并于2016年成为成为CNCF第二个成员,现已被大量的组织使用于工业生产环境中。

Prometheus在指标采集领域具备先天优势,它提供了强大的数据模型和查询语言,不仅可以很方便的查看系统的性能指标,还可以结合mtail从日志中提取Metric指标,如Error出现次数,发送到时间序列数据库,实现日志告警。
对于Flink任务平台需要支持监控以下指标
Flink本身的metric,可以将精确到每个subtask的operator,主要通过promethues push gateway上报。
Flink Cluster、task/operator IO、JVM 、Source、Sink、维表IO等。
任务延迟,重启次数等。
自定义Metric,一般针对具体任务。
10.2 Grafana
有了Prometheus来监控任务后,还需要有一个可视化工具来展示Prometheus收集的指标。Grafana是Prometheus的最佳搭档,它是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能,并且自带权限管理功能。
Grafana支持的可视化方式有很多种,不过Graph、Table、Pie chart 这三种基本就已经满足数据展现要求了。

使用起来也很简单,跟商业的BI报表工具类似,先选择图表类型

然后选择数据库,写好sql,就可以制定一个报表。

11. 总结
流失计算是在内存中事实进行的,数据很多时候也是直接来自生产环境,无论是框架还是业务逻辑都比批处理复杂多了。对平台的建设也提出了严峻的挑战,Flink作为新一代的流失计算引擎,功能还在不断完善中,刚开始使用必然会踩很多坑。当然踩坑的过程也是学习的过程,为了趟过坑,你必然要做很多的技术调研,对平台与很多组件的认知也会不断加深。


版权声明:
文章不错?点个【在看】吧! ?