
【学术前沿】基于三维地面激光扫描数据的常用建筑材料自动分类
点击上方“公众号”可订阅哦!
声明:本文只是针对个人学习记录,侵权可删。本人自觉遵守《中华人民共和国著作权法》和《伯尔尼公约》等法律,其他个人或组织等转载请保留此声明,并自负法律责任。论文版权与著作权等全归原作者所有。

01
文章摘要
建筑材料自动分类在建筑施工管理和设施管理中具有重要的应用价值,是近几十年来建筑材料自动分类研究的热点。目前提出的材料自动分类方法主要是利用建筑材料的视觉特征,基于二维图像进行分类。带有内置摄像头的地面激光扫描仪(TLS)可以生成一组包含建筑材料表面几何形状的彩色激光扫描数据。激光扫描数据不仅包括建筑材料的视觉特征,还包括材料反射率和表面粗糙度等其他属性。通过提供更多的属性,激光扫描数据有可能提高建筑材料分类的准确性。因此,本研究旨在利用机器学习技术开发一种基于TLS数据的常见建筑材料分类方法。该技术利用材料反射率、HSV颜色值和表面粗糙度作为材料分类的特征。建立了10种常用建筑材料的激光扫描数据数据库,并利用机器学习技术进行模型训练和验证。通过对不同机器学习算法的比较,最佳算法的平均分类准确率为96.7%,验证了所提出方法的可行性。
02
文章导读
地面激光扫描技术为建筑材料的自动分类提供了一个新的前景。带有内置摄像头的TLS不仅可以捕捉视觉特征,还可以捕捉建筑材料的内在属性,如材料反射率。因此,考虑到所提供的信息类型更多,且对变化的光照条件具有更高的鲁棒性,TLS在实现更精确的材料分类方面具有很大潜力。此外,TLS由于其高测量精度和速度,已被广泛用于构建代表建筑现状的bim。因此,使用TLS数据进行建筑材料分类不需要额外的数据收集,如果TLS数据已经为构建现有bim收集。尽管TLS具有诸多优势,但采用TLS数据进行建筑材料分类的研究较少。
03
实验设计
本研究需要确定一套常见的建筑材料作为目标材料。已经建立了一些建筑材料库,用于基于图像的材料分类。因此,我们以现有的建筑材料库为参考,创建了一个通用的建筑材料集。
主要图表:
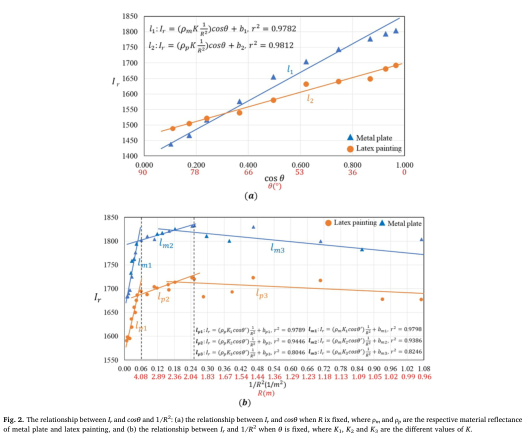
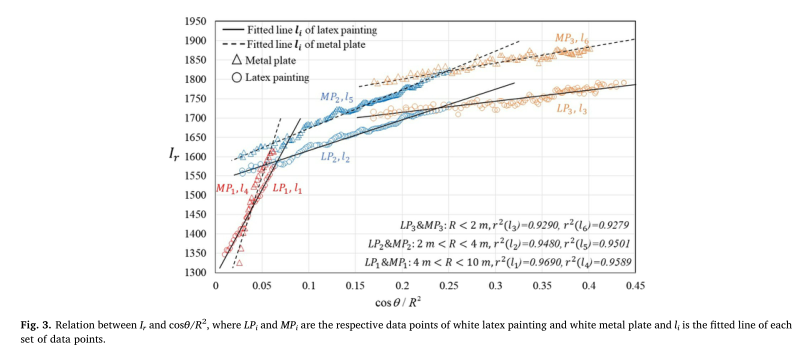
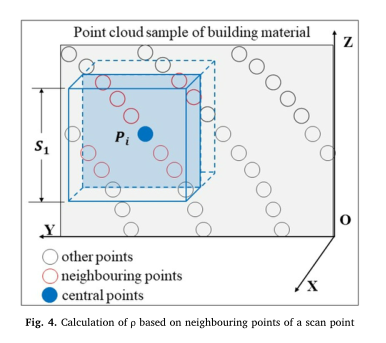
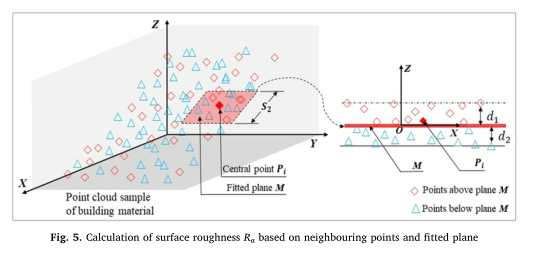
04
实验


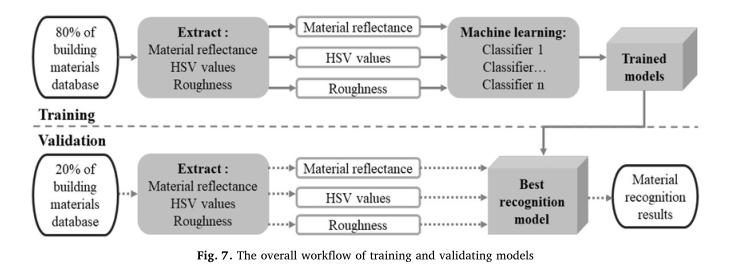
05
实验结果
特征和分类器的比较
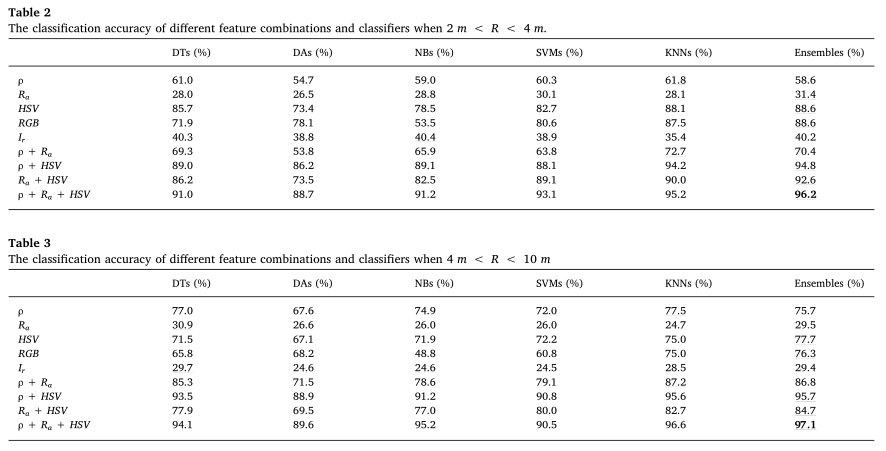
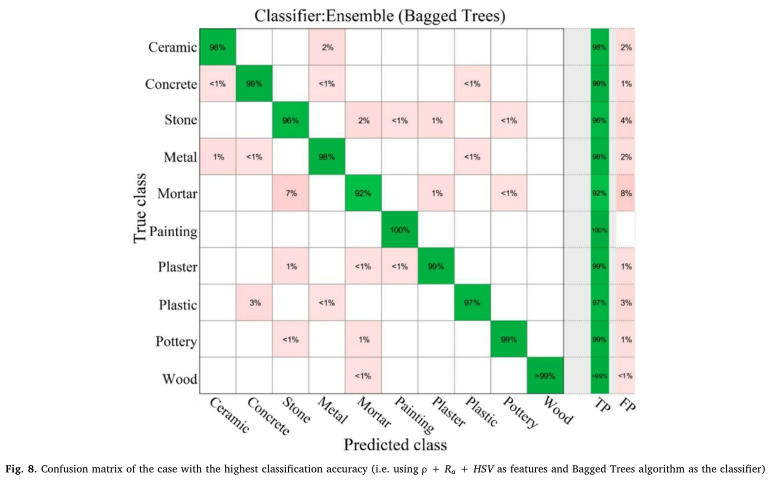
每种建筑材料的精度分析
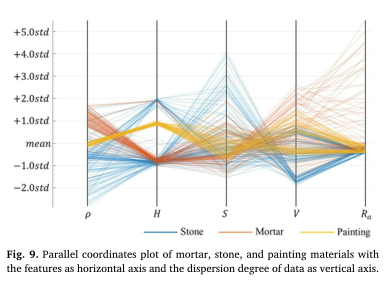
06
结论
为了找到最佳的特征组合,对不同的特征组合进行了测试。此外,还探讨了不同的监督学习分类器,包括决策树(DTs)、判别分析(DAs)、朴素贝叶斯(NBs)、支持向量机(SVMs)、最近邻(KNNs)和集成。实验结果表明,使用ρ、HSV、Raas特征和集成作为分类器,实现了最高的分类准确率96.7%。实验结果也证实了ρ色在材料分类方面比Ir色有更好的效果,HSV色优于RGB色。
为了进一步测试一种建筑材料的识别精度,我们还采用了一类分类方法对分类模型进行了训练和验证。本文采用OC-SVM和SVDD,这两种分类器在以往的研究中都被证实是处理一类分类问题的最佳分类器。实验结果表明,OC-SVM和SVDD的平均准确率分别为85.5%和86.5%,进一步证明了该方法的可行性。
END

深度学习入门笔记
微信号:sdxx_rmbj
日常更新学习笔记、论文简述