
数据仓库、数据湖、流批一体,终于有大神讲清楚了!

导读:数据仓库,数据湖,包括Flink社区提的流批一体,它们到底能解决什么问题?今天将由阿里云研究员从解决业务问题出发,将问题抽丝剥茧,从技术维度娓娓道来:为什么你需要数据湖或者数据仓库解决方案?它的核心难点与核心问题在哪?如果想稳定落地,系统设计该怎么做?
作者:
蒋晓伟(量仔) 阿里云研究员
金晓军(仙隐) 阿里云高级技术专家
来源:过往记忆大数据(ID:iteblog_hadoop)

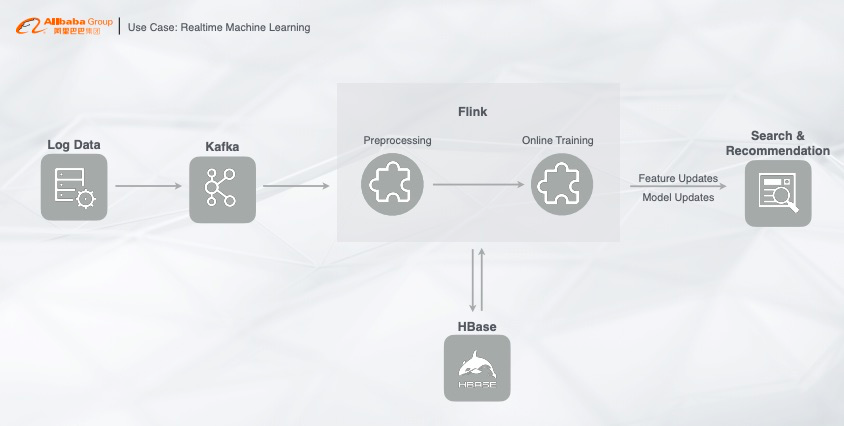
01 业务背景
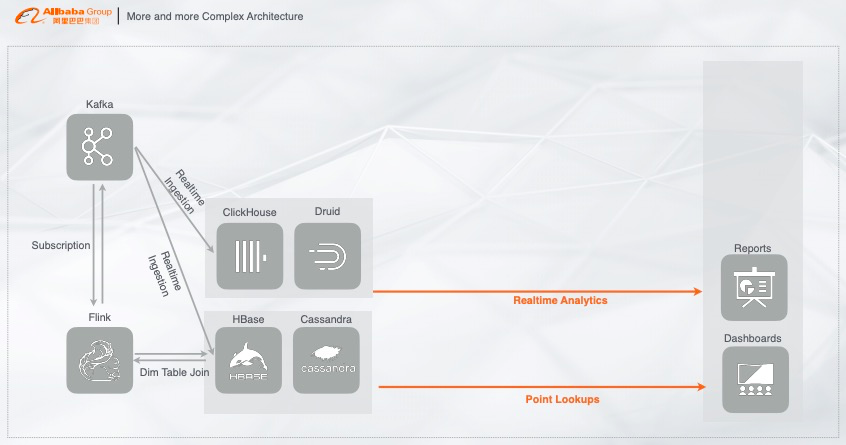
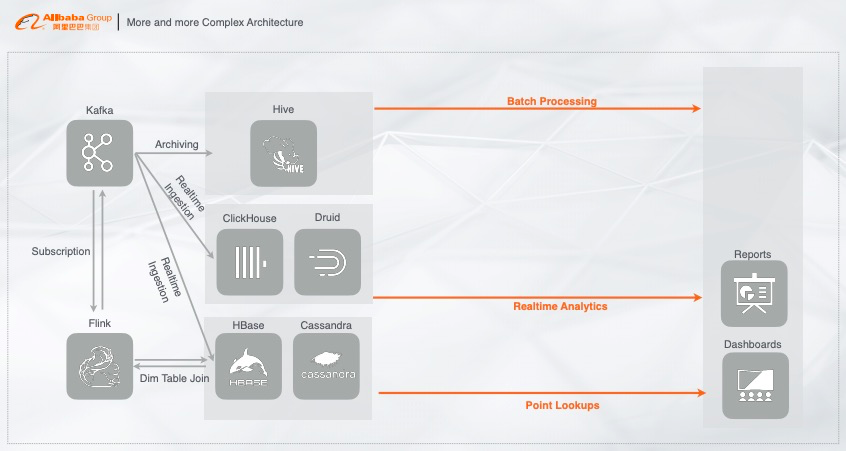
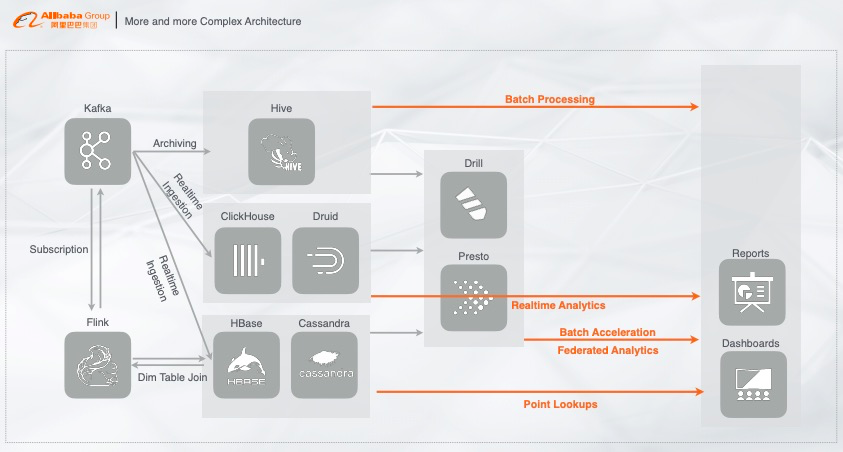
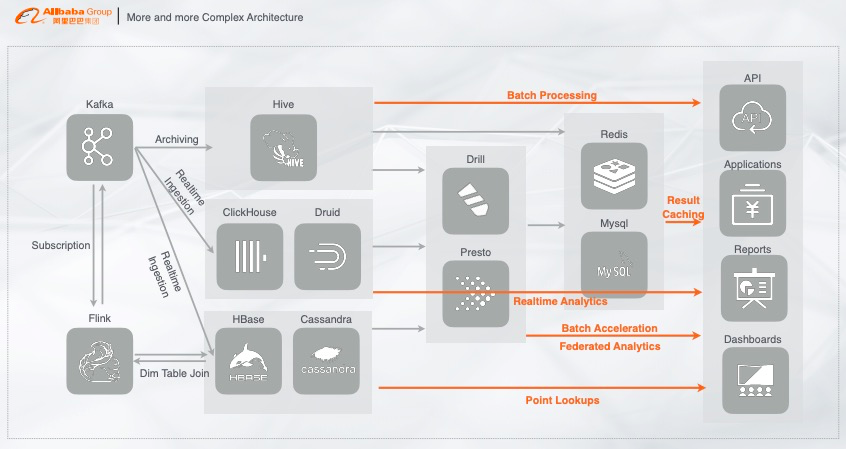
2. 越来越复杂的架构

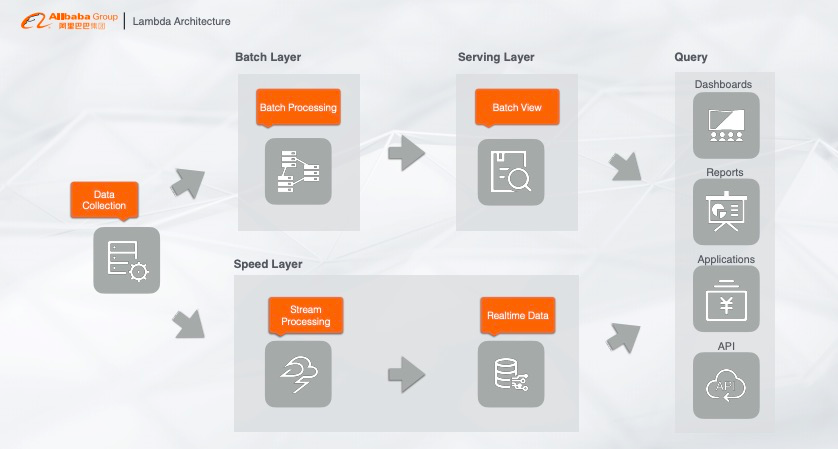
3. 典型的大数据Lambda架构
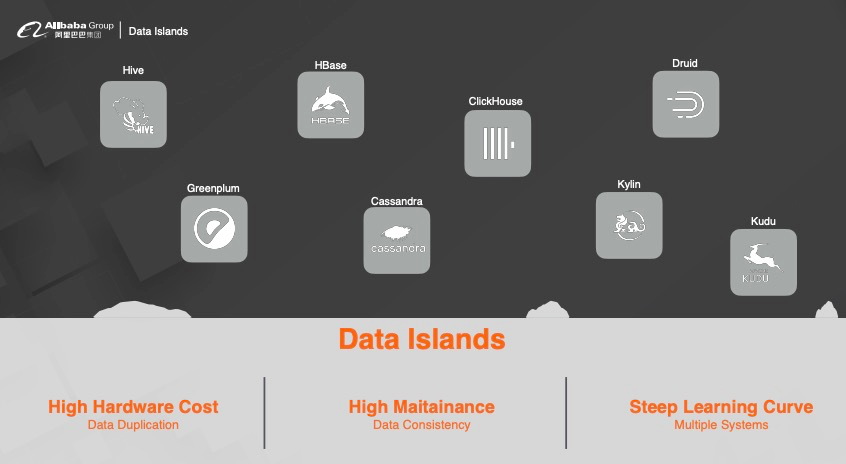
4. 典型大数据架构的痛点
冗余存储:数据将会存储在多个系统中,增加冗余存粗。
高维护成本:每个系统的数据格式不一致,数据需要做转换,增加维护成本,尤其是当业务到达一定量级时,维护成本剧增。 高学习成本:多个系统之前需要完全打通,不同的产品有不同的开发方式,尤其是针对新人来说,需要投入更多的精力去学习多种系统,增加学习成本。
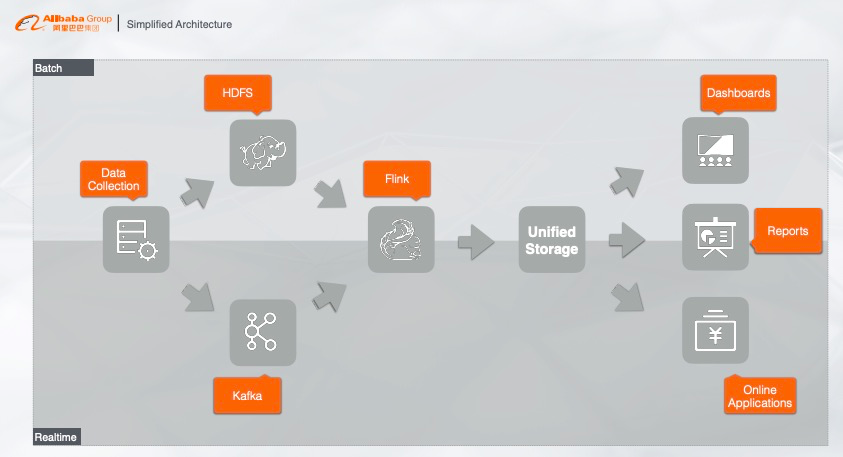
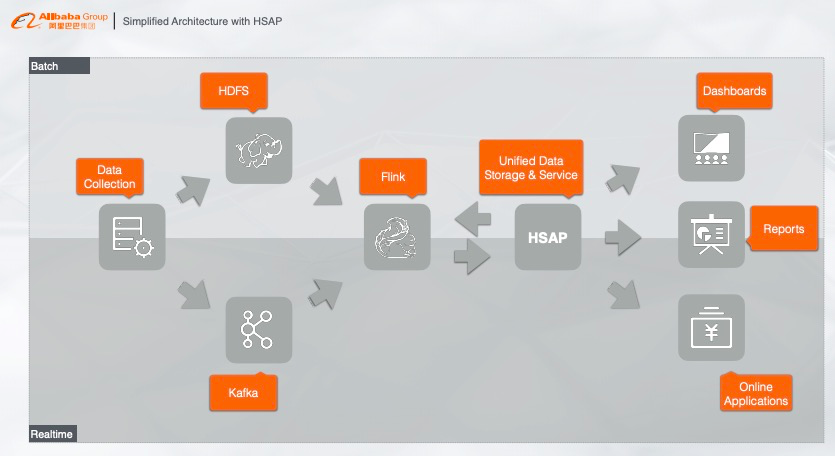
5. 简化的大数据架构
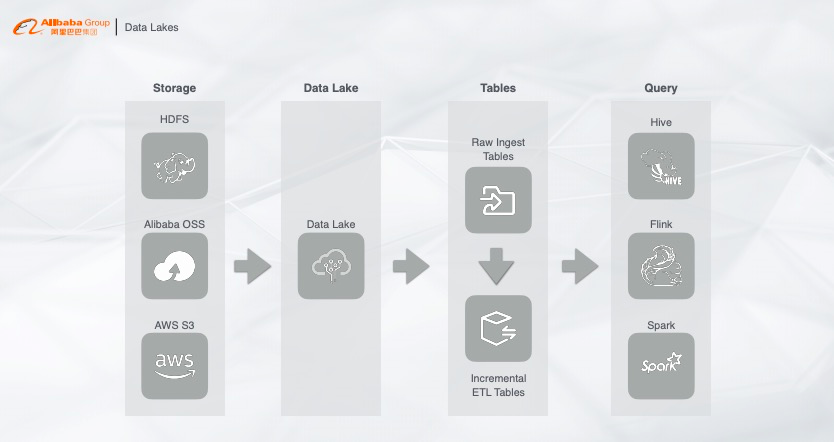
02 看起来很完美的Data Lakes
数据增量写入不满足实时性:开源的实时写入并不是实时写入,而是增量写入。实时和增量的区别在于,实时写一条数据就能立马查询可见,但是增量为了提高吞吐会将数据一批一批的写入。那么这套方案就不能完全满足数据实时性的要求。 查询的QPS:我们希望这个架构既能做实时分析,又能做流计算的维表查询,存储里面的数据能否通过Flink做一个高并发的查询,例如每秒钟支持上千万上亿QPS的查询? 查询的并发度:整个方案本质都是离线计算引擎,只能支持较低的并发,如果要支持每秒钟上千的并发,需要耗费大量的资源,增加成本。
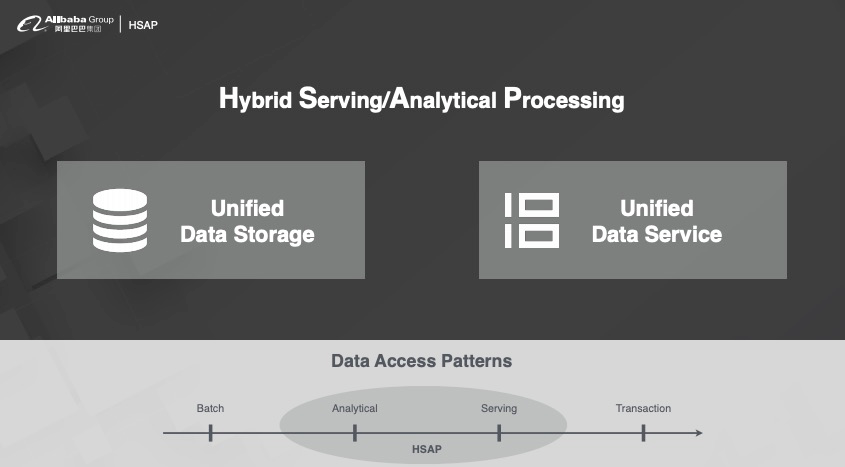
03 HSAP之我见
Batch:离线计算 Analytical:交互式分析 Servering:高QPS的在线服务 Transaction:与钱相关的传统数据库(绝大多数业务并不需要)
丰富的工具对接:PostgreSQL具有非常完备的工具对接,不管是开发工具还是BI分析工具,都有着丰富的支撑能力。 详尽的文档支撑:通常来讲写文档需要耗费大量的时间,PostgreSQL有着非常详尽的文档,如果能够直接复用PostgreSQL的文档,将会减少工作量。同时开发者们只需要根据postgreSQL文档来开发,减少学习成本。 多元化的扩展:PostgreSQL有着非常多元化的扩展,例如地理信息的PostGis,Matlab等,开发者们可以根据业务需求选择对应的扩展。

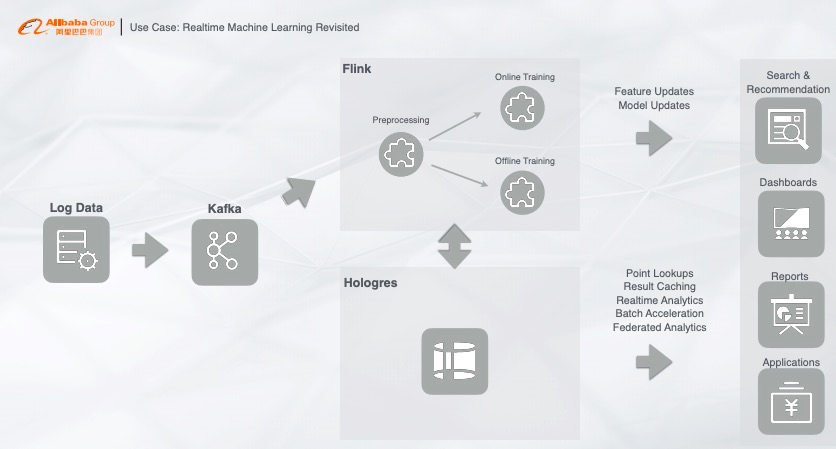
04 新一代的实时交互式引擎--Hologres

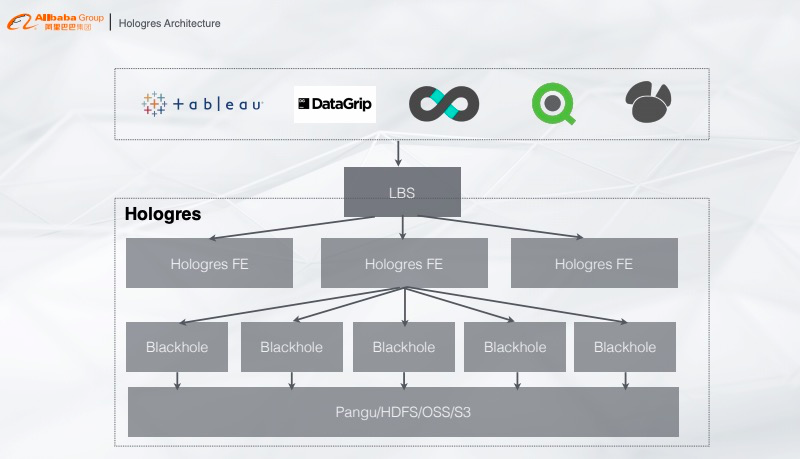
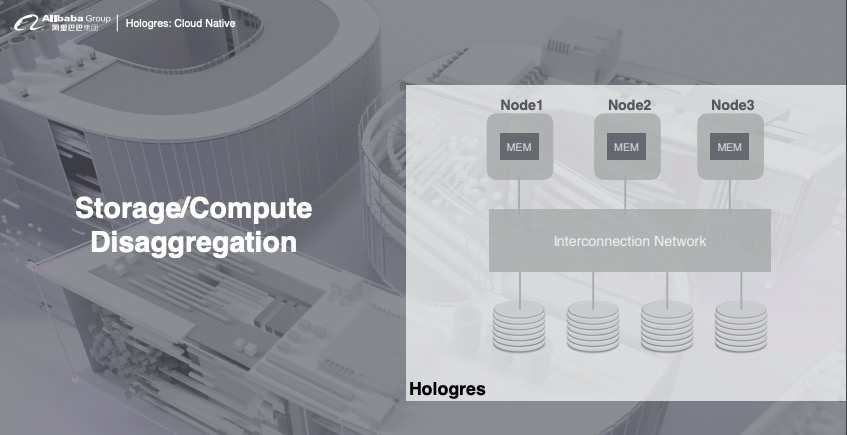
全异步:支持高并发写入,能够将CPU最大化利用; 无锁:写入能力随资源线性扩展,直到将CPU全部写满; 内存管理:提供数据cache,支持高并发查询。

高性能混合负载:慢查询和快查询混合一起跑,通过内部的调度系统,避免慢查询影响快查询; 向量化计算:列式数据通过向量化计算达到查询加速的能力; 存储优化:能够定制查询引擎,但是对存储在Hologres数据查询性能会更优。



评论