
从V8引擎来看JS中这个"假数组"

作者:哈啰出行-共享团队-Allan
原文地址:https://juejin.cn/post/6847902222009925640
数组是前端日常开发中最常见的一种数据类型,但你真的了解数组吗?JS中的数组又是怎么实现的呢?通过本文,你将了解:
JS数组和传统数组的区别
V8引擎为“传统”数组做了哪些优化
快数组和慢数组
ArrayBuffer
什么是数组?
数组(Array)在维基百科上的解释是:
数组是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续内存来存储。
注意,这里有两个关键词:相同类型、连续内存,这是作为一个“真数组”的充分必要条件!好,重点来了:
let arr = [100, 'foo', 1.1, {a: 1}];
上面代码表示JS中的一个常规的数组,那么数组元素为啥可以是多种类型共存?这就有意思了,维基百科对于数组的描述应该是具有一定权威的,难道JS的数组不是真的“数组”?

这么来看,我们姑且推断一个小结论:
∵ 不同数据类型存储所需空间大小不同
∴ JS中用来存放数组的内存地址一定不是连续的(除非类型相同)
因此我们大胆猜测,JS中的数组实现一定不是基础的数据结构实现的!所以JS中原本没有“真正”的数组!这就引起了我的好奇心了,那么JS中是如何“实现”数组这个概念的呢? 我们来一探究竟!
数组中概念一:连续内存
在讲连续内存前,先来了解下什么是内存,知道的本节直接绕过。
1)什么是内存?
通俗理解,在计算机中,CPU用于数据的运算,而数据来源于硬盘,但考虑到CPU直接从硬盘读写数据效率低,所以内存在其中扮演了“搬运工”的角色。
内存是由DRAM(动态随机存储器)芯片组成的。DRAM的内部结构可以说是PC芯片中最简单的,是由许多重复的“单元”——cell组成,每一个cell由一个电容和一个晶体管(一般是N沟道MOSFET)构成,电容可储存1bit数据量,充放电后电荷的多少(电势高低)分别对应二进制数据0和1。
DRAM由于结构简单,可以做到面积很小,存储容量很大。用芯片短暂存储数据,读写的效率要远高于磁盘。所以内存的运行也决定了计算机的稳定运行。
2)内存和数组的故事
了解完什么是内存后,回过头再来看一下数组的概念:
数组是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续内存来存储。
那么数组中的连续内存说的是,通过在内存中划出一串连续且长度固定的空间,用来于存放一组有限且数据类型相同的数据结构。在C/C++、Java等编译型语言中数组的实现都是这个。C++数组声明示例代码如下:
// 数据类型 数组名[元素数量]
double balance[10];
上述代码中,需要指定元素类型和数量,这非常重要。细细品味其中的蕴含的内容,将其联系到内存以及计算机运行原理信息量很大!
数组中概念二:固定长度
从上面说的就很容易理解,计算机语言设计者为什么要让C/C++、Java这类编译型语言在数组的设计上要固定长度。因为数组空间数连续的,所以这就意味着内存中需要有一整块的空间用来存放数组。如果长度不固定,那么内存中位于数组之后的区域没法继续往下分配了!内存不知道当前数组还要不要继续存放,要多少空间了。毕竟数组后面的空间得要留出来给别人去用,不可能让你(数组)一直霸占着对吧。
数组中概念三:相同数据类型
为什么数组的定义需要每个元素数据类型相同呢。其实比较容易理解了,如果数组允许各种类型的数据,那么每存入一个元素都要进行装箱操作,每读取一个元素又要进行拆箱操作。统一数据类型就可以省略装箱和拆箱的步骤了,这样能提高存储和读取的效率。
V8引擎下数组的实现
写在前面
首先,我们要了解JS代码是如何在计算机上被执行的。和Python一样,它作为一门解释型语言,需要宿主环境去对它进行“转换”,然后再由机器运行机器码,也就是二进制。我们平时对JS的讨论很多都是(默认)基于浏览器来讲的,当前大多主流浏览器底层都是基于C++开发的,并且Node底层也是基于Chrome V8引擎的JS运行环境,而V8底层也是基于C++来开发的。所以会有开发者以为JavaScript是用C++写的,这是不对的。
作为一门解释型语言,JS并非只有C++才能去解析JS,其实还有:
D:DMDScript
Java:Rhino、Nashorn、DynJS、Truffle/JS 等
C#:Managed JScript、SPUR 等等
还有最近热度不减的Rust:deno(也是基于V8)。所以,我们要来研究JS中数组的实现就要依赖“解释”他的JS引擎来讲了。鉴于此,本文用V8引擎来进行讲解有关JS中的数组。
V8源码中的JS数组
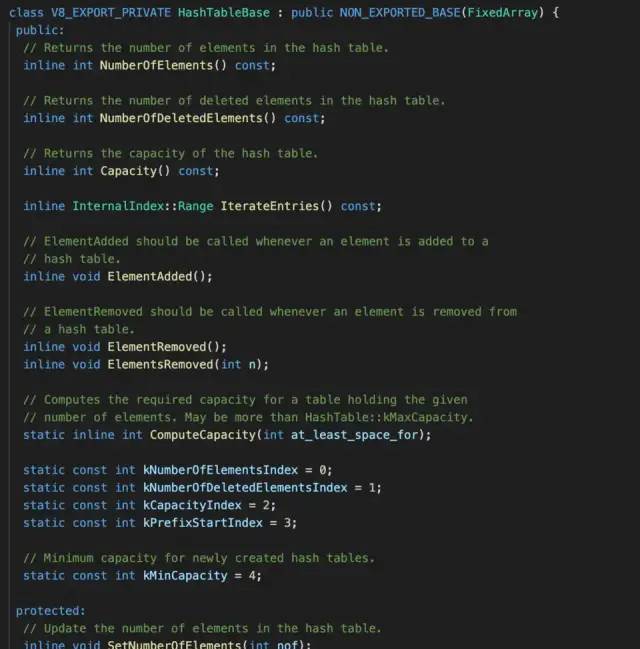
为了追踪JS到底是如何实现数组的,我们追踪到V8中看看它是如何去“解析”JS数组的。下面截图来自V8源码:
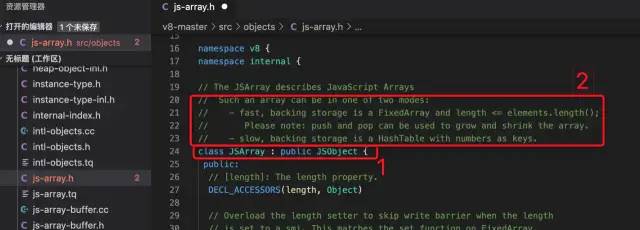
可以看到上面截图1中可以得到两个信息(V8源码注释写的还是比较详细的):
1、
JSArray数组继承于JSObject对象2、数组有快慢两种模式
下面我们来具体讲讲。
JS数组就是“对象”
如果说JS中的数组底层是一个对象,那么我们就可以解释为什么JS中数组可以放各种类型了。假设我们猜测是对的,那么如何来验证这一点呢?为此最近花了点时间探索了一番,在网上看了很多资料,也找了很多方法,最终锁定使用通过观察JS最终执行生产的字节码来看最终代码的转换。最后选用了GoogleChromeLabs的jsvu,他可以帮我们安装各种JS引擎,也可以将JS转为字节码。
测试代码:const arr = [1, true, 'foo'];复制代码
然后使用V8-debug引擎去debug打印他转译的字节码,如下图所示:
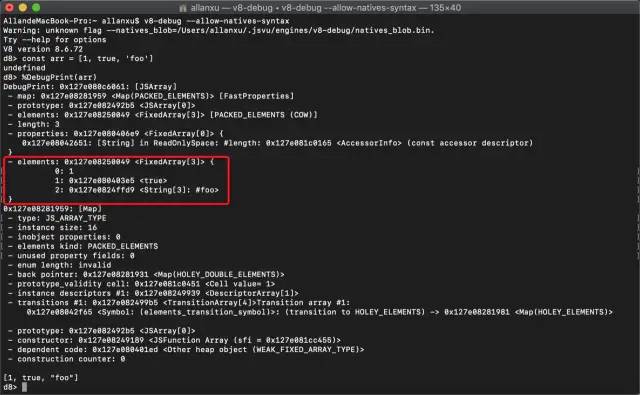
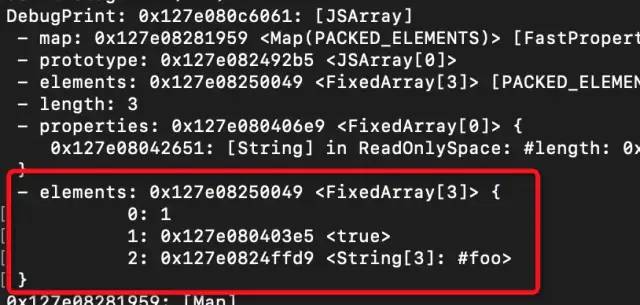
那么这就可以得出结论,其实arr就是一个map,它有key,有value,而key就是数组的索引,value就是数组中的元素。
快数组和慢数组
细心的同学可能发现了,前面截图的V8源码注释中有这样一段描述:
Such an array can be in one of two modes:- fast, backing storage is a FixedArray and length <= elements.length();- slow, backing storage is a HashTable with numbers as keys.
翻译一下,一个数组含有两种模式:
快(模式):后备存储是一个FixedArray,长度 <= elements.length
慢(模式):后备存储是一个以数字为键的HashTable
那么来思考下为什么要V8要将数组这样“设计”,动机是什么?无非就是为了提升性能,一说到性能,就不得不提内存,总之这一切无非就是:
牺牲性能节省内存,牺牲内存提高性能
这是时间换空间,空间换时间的博弈,最后看到底哪个“划算”(合理)。
快数组
先看快数组,快数组是一种线性存储,其长度是可变的,可以动态调整存储空间。其内部有扩容和收缩机制,来看一下V8中扩容的实现。源码(C++):
./src/objects/js-objects.h
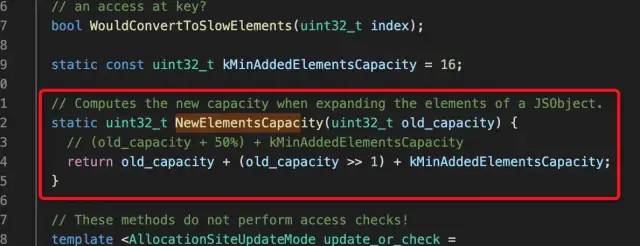
拓容时计算新容量是根据基于旧的容量来的:
新容量 = 旧容量 + 50% + 16
因为JS数组是动态可变的,所以这样安排的固定空间势必会造成内存空间的损耗。然后扩容后会将数组拷贝到新的内存空间:

收缩的实现源码(C++):

它的判断依据是:当前容量是否大于等于当前数组长度的2倍+16,此外的都填入Holes(空洞)对象。什么是Holes,简单理解就是数组分配了空间但没有存入元素,这里不展开。快数组就是空间换时间来提升JS数组在性能上的缺陷,也可以说这是参照编译型语言的设计的一种“数组”。
一句话总结:V8用快数组来实现内存空间的连续(增加内存来提升性能),但由于JS是弱类型语言,空间无法固定,所以使用数组的length来作为依据,在底层进行内存的重新分配。
慢数组
慢数组底层实现使用的是 HashTable 哈希表,相比于快数组,他不用开辟大块的连续空间,从而节省内存,但无疑执行效率是比快数组要低的(时间换空间)。相关代码(C++):
快慢数组之间的转换
JS中长度不固定,类型不固定,所以我们在适合的适合会做相应的转换,以期望它能以最适合当前数组的方式去提升性能。对应源码:
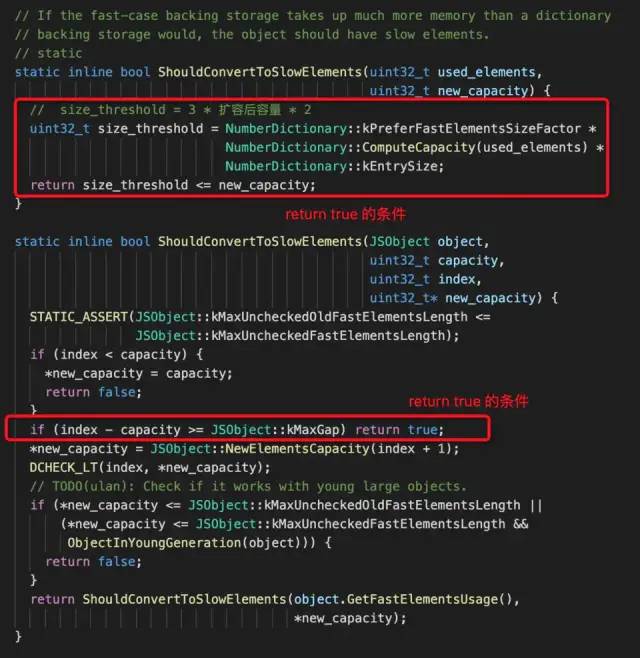
上面截图代码中,返回true就表示应该快数组转慢数组。第一个红框表示3*扩容后容量*2 <= 新容量这个对象就改为慢数组。kPreferFastElementsSizeFactor 源码中声明如下:
// 此处注释翻译:相比于快(模式)元素,如果字典元素能节省非常多的内存空间,那JSObjects更倾向于字典`dictionary`。static const uint32_t kPreferFastElementsSizeFactor = 3;
第二个红框表示索引-当前容量 >= 1024(kMaxGap的值)时,也会从快数组转为慢数组。其中 kMaxGap 是一个用于控制快慢数组转换的试探性常量,源码中声明如下:
// 此处注释翻译:kMaxGap 是“试探法”常量,用于控制快慢数组的转换
static const uint32_t kMaxGap = 1024;也就是说当前数组在重新赋值要远超其所需的容量+1024的时候,就会造成内从的浪费,于是改为慢数组。我们来验证下:
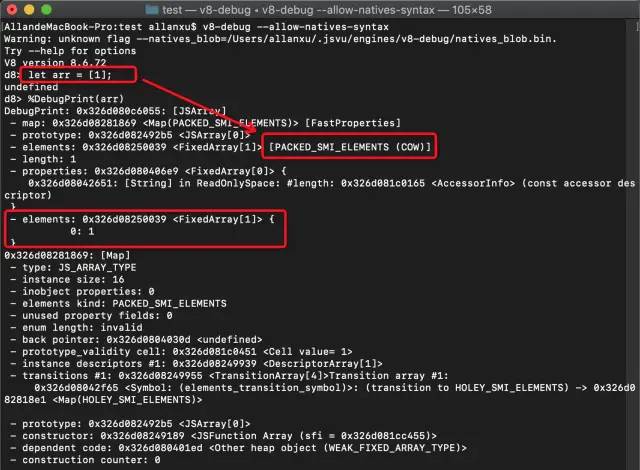
示例代码一:
let arr = [1];复制代码
%DebugPrint(arr) 后截图如下:
然后将arr数组重新赋值:
arr[1024] = 2;复制代码
%DebugPrint(arr) 后截图如下:
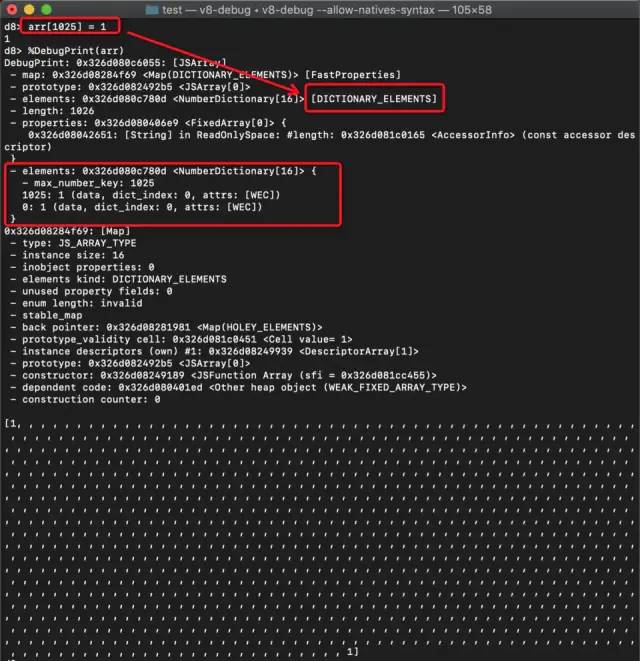
ok,验证成功。接下来我们来看如何从慢数组到快数组。

从上面源码注释可以知道,快数组到慢数组的条件就是:快数组节省仅为50%的空间时,就采用慢数组(Dictionary)。我们继续来验证:
let arr = [1];arr[1025] = 1;复制代码
上面代码声明的数组使用的是慢数组(Dictionary),截图如下
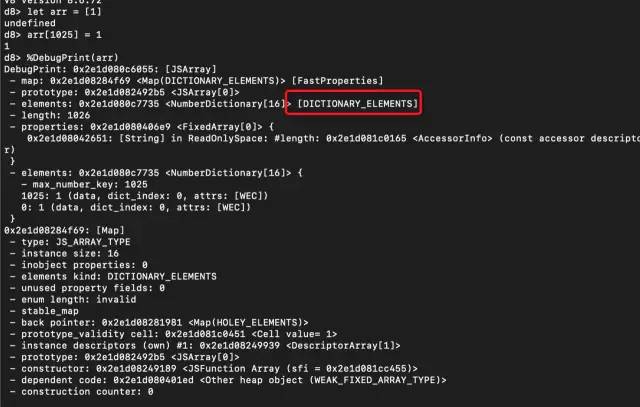
接下来让索引从500开始填充数字1,让其满足快数组节省空间小于50%:
for(let i=500;i<1024;i++){arr[i]=1;}复制代码
得到结果如下:
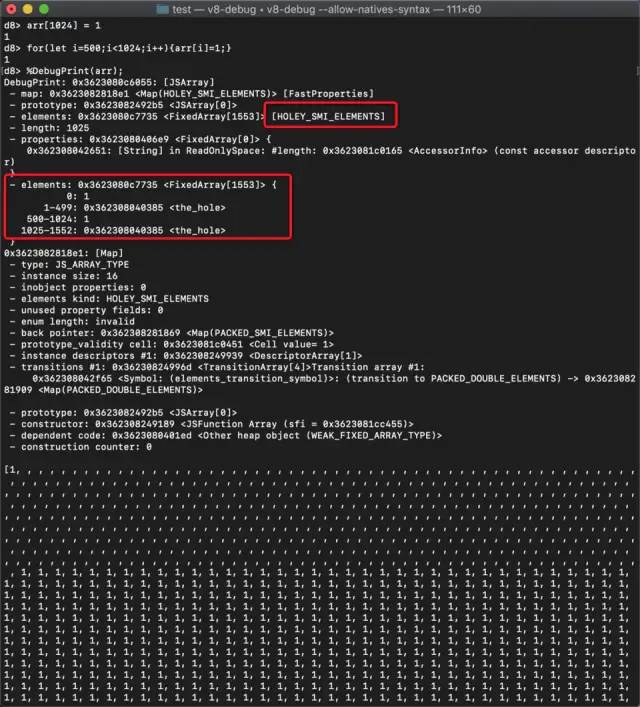
最终我们得到结果,让arr数组从慢数组(Dictionary)转为了快数组(HOLEY_SMI_ELEMENTS就是Fast Holey Elements)。以上就是快慢数组的相互转换,核心还是本着合理用内存来决定到底用哪种数组。
new ArrayBuffer
讲了真么多,无非就是在说JS中由于语言“特色”而在数组的实现上有一些性能问题,那么为了解决这个问题V8引擎中引入了连续数组的概念,这是在JS代码转译层做的优化,那么还有其他方式吗?
当然有,那就是ES6中ArrayBuffer。ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区,它是一个字节数组。使用ArrayBuffer能在操作系统内存中得到一块连续的二进制区域。然后这块区域供JS去使用。
// create an ArrayBuffer with a size in bytesconst buffer = new ArrayBuffer(8); // 入参8为lengthconsole.log(buffer.byteLength);
但需要注意的是ArrayBuffer本身不具备操作字节能力,需要通过视图去操作。比如:
let buffer = new ArrayBuffer(3);let view = new DataView(buffer);view.setInt8(0, 8)
更多细节本文不再展开,请读者自行探索。
❤️爱心三连击 1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我创作的动力。
2.关注公众号
程序员成长指北,回复「1」加入高级前端交流群!「在这里有好多 前端 开发者,会讨论 前端 Node 知识,互相学习」!3.也可添加微信【ikoala520】,一起成长。
“在看转发”是最大的支持