
Go:最简单的服务响应时长优化方法,没有之一
序言 - From 万俊峰Kevin
我们能把服务做到平均延迟基本在30ms左右,其中非常大的一个前提是我们大量使用了 MapReduce 技术,让我们的服务即使调用很多个服务,很多时候也只取决于最慢的那一个请求的时长。
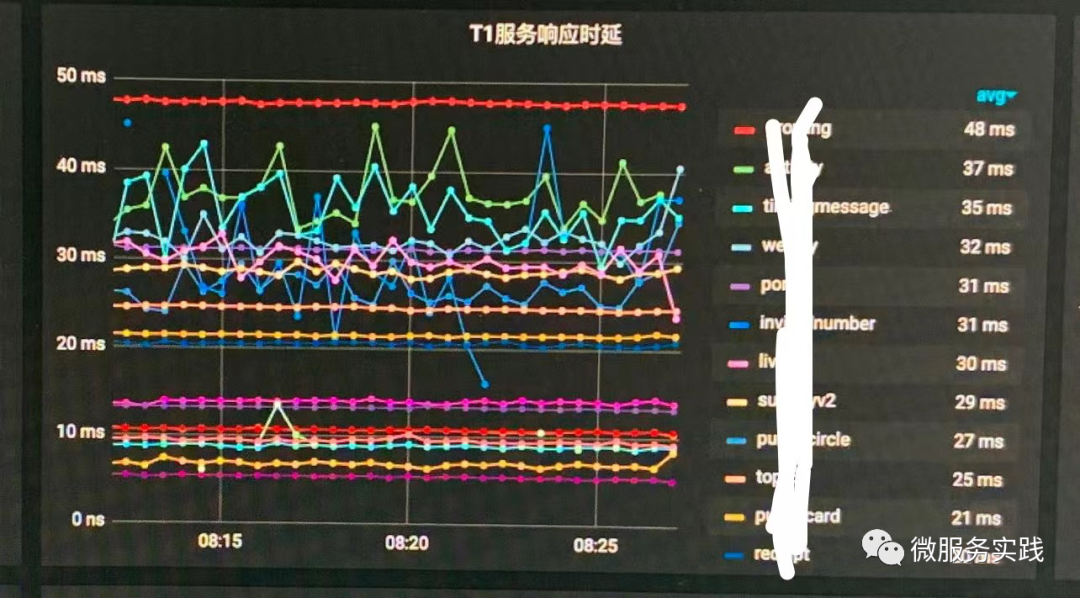
对你现有的服务,不需要优化 DB 操作,不需要优化缓存,不需要重写业务逻辑,只需要通过 MapReduce 把正交(不相关)的请求并行化,你就可以大幅降低服务响应时长。
本文欧阳安就给大家仔细分析一下 MapReduce 的实现细节。
为什么需要 MapReduce
在实际的业务场景中我们常常需要从不同的 rpc 服务中获取相应属性来组装成复杂对象。
比如要查询商品详情:
商品服务-查询商品属性 库存服务-查询库存属性 价格服务-查询价格属性 营销服务-查询营销属性
如果是串行调用的话响应时间会随着 rpc 调用次数呈线性增长,所以我们要优化性能一般会将串行改并行。
简单的场景下使用 waitGroup 也能够满足需求,但是如果我们需要对 rpc 调用返回的数据进行校验、数据加工转换、数据汇总呢?继续使用 waitGroup 就有点力不从心了,go 的官方库中并没有这种工具(java 中提供了 CompleteFuture),go-zero 作者依据 mapReduce 架构思想实现了进程内的数据批处理 mapReduce 并发工具类。
设计思路
我们尝试把自己代入到作者的角色梳理一下并发工具可能的业务场景:
查询商品详情:支持并发调用多个服务来组合产品属性,支持调用错误可以立即结束。 商品详情页自动推荐用户卡券:支持并发校验卡券,校验失败自动剔除,返回全部卡券。
以上实际都是在进行对输入数据进行处理最后输出清洗后的数据,针对数据处理有个非常经典的异步模式:生产者消费者模式。于是我们可以抽象一下数据批处理的生命周期,大致可以分为三个阶段:
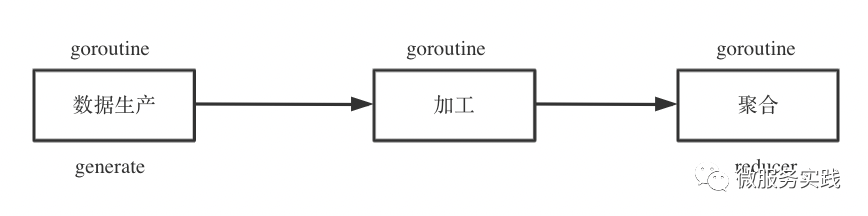
数据生产 generate 数据加工 mapper 数据聚合 reducer
其中数据生产是不可或缺的阶段,数据加工、数据聚合是可选阶段,数据生产与加工支持并发调用,数据聚合基本属于纯内存操作单协程即可。
再来思考一下不同阶段之间数据应该如何流转,既然不同阶段的数据处理都是由不同 goroutine 执行的,那么很自然的可以考虑采用 channel 来实现 goroutine 之间的通信。
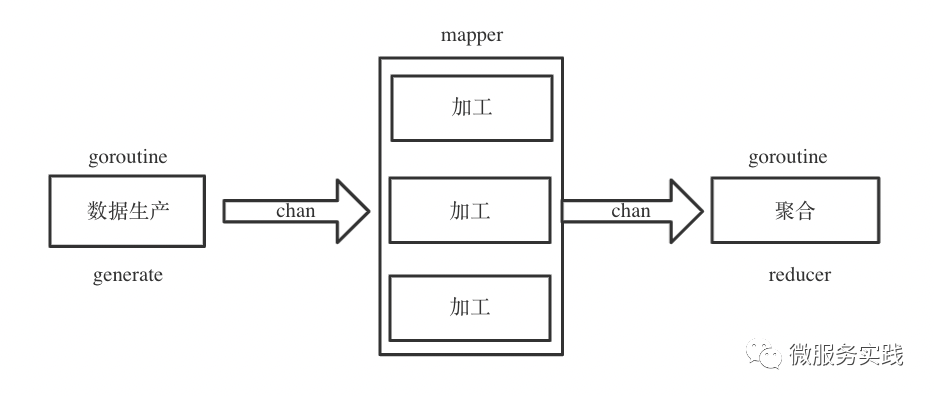
如何实现随时终止流程呢?
很简单,goroutine 中监听一个全局的结束 channel 就行。
go-zero 代码实现
core/mr/mapreduce.go
详细源码可查看 https://github.com/Ouyangan/go-zero-annotation/blob/24a5753f19a6a18fc05615cb019ad809aab54232/core/mr/mapreduce.go
前置知识 - channel 基本用法
因为 MapReduce 源码中大量使用 channel 进行通信,大概提一下 channel 基本用法:
channel 写结束后记得关闭
ch := make(chan interface{})
// 写入完毕需要主动关闭channel
defer func() {
close(ch)
}()
go func() {
// v,ok模式 读取channel
for {
v, ok := <-ch
if !ok {
return
}
t.Log(v)
}
// for range模式读取channel,channel关闭循环自动退出
for i := range ch {
t.Log(i)
}
// 清空channel,channel关闭循环自动退出
for range ch {
}
}()
for i := 0; i < 10; i++ {
ch <- i
time.Sleep(time.Second)
}
已关闭的 channel 依然支持读取 限定 channel 读写权限
// 只读channel
func readChan(rch <-chan interface{}) {
for i := range rch {
log.Println(i)
}
}
// 只写channel
func writeChan(wch chan<- interface{}) {
wch <- 1
}
接口定义
先来看最核心的三个函数定义:
数据生产 数据加工 数据聚合
// 数据生产func
// source - 数据被生产后写入source
GenerateFunc func(source chan<- interface{})
// 数据加工func
// item - 生产出来的数据
// writer - 调用writer.Write()可以将加工后的向后传递至reducer
// cancel - 终止流程func
MapperFunc func(item interface{}, writer Writer, cancel func(error))
// 数据聚合func
// pipe - 加工出来的数据
// writer - 调用writer.Write()可以将聚合后的数据返回给用户
// cancel - 终止流程func
ReducerFunc func(pipe <-chan interface{}, writer Writer, cancel func(error))
面向用户的方法定义
使用方法可以查看官方文档,这里不做赘述
面向用户的方法比较多,方法主要分为两大类:
无返回 执行过程发生错误立即终止 执行过程不关注错误 有返回值 手动写入 source,手动读取聚合数据 channel 手动写入 source,自动读取聚合数据 channel 外部传入 source,自动读取聚合数据 channel
// 并发执行func,发生任何错误将会立即终止流程
func Finish(fns ...func() error) error
// 并发执行func,即使发生错误也不会终止流程
func FinishVoid(fns ...func())
// 需要用户手动将生产数据写入 source,加工数据后返回一个channel供读取
// opts - 可选参数,目前包含:数据加工阶段协程数量
func Map(generate GenerateFunc, mapper MapFunc, opts ...Option)
// 无返回值,不关注错误
func MapVoid(generate GenerateFunc, mapper VoidMapFunc, opts ...Option)
// 无返回值,关注错误
func MapReduceVoid(generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, opts ...Option)
// 需要用户手动将生产数据写入 source ,并返回聚合后的数据
// generate 生产
// mapper 加工
// reducer 聚合
// opts - 可选参数,目前包含:数据加工阶段协程数量
func MapReduce(generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface{}, error)
// 支持传入数据源channel,并返回聚合后的数据
// source - 数据源channel
// mapper - 读取source内容并处理
// reducer - 数据处理完毕发送至reducer聚合
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error)
核心方法是 MapReduceWithSource 和 Map,其他方法都在内部调用她俩。弄清楚了 MapReduceWithSource 方法 Map 也不在话下。
MapReduceWithSource 源码实现
一切都在这张图里面了
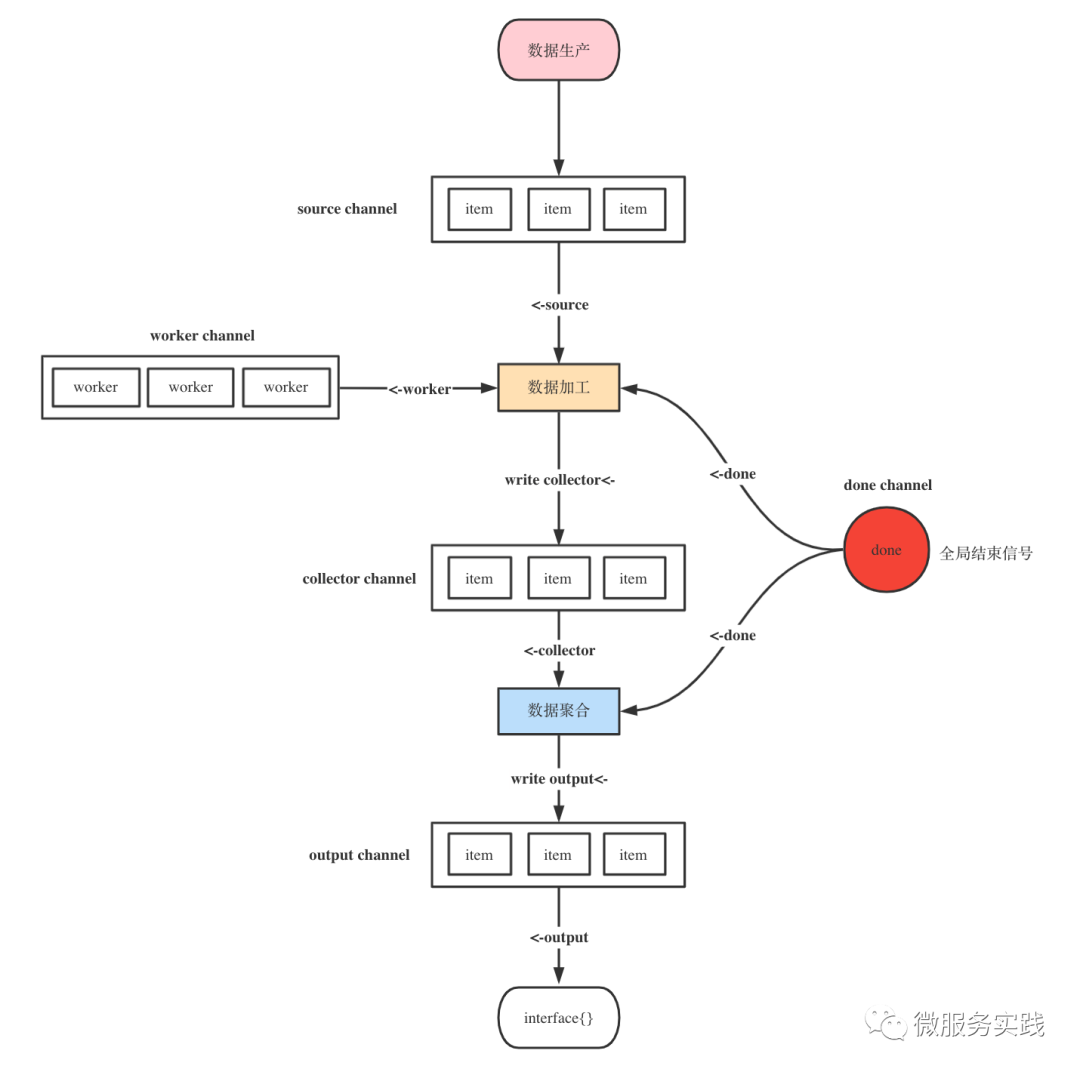
// 支持传入数据源channel,并返回聚合后的数据
// source - 数据源channel
// mapper - 读取source内容并处理
// reducer - 数据处理完毕发送至reducer聚合
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error) {
// 可选参数设置
options := buildOptions(opts...)
// 聚合数据channel,需要手动调用write方法写入到output中
output := make(chan interface{})
// output最后只会被读取一次
defer func() {
// 如果有多次写入的话则会造成阻塞从而导致协程泄漏
// 这里用 for range检测是否可以读出数据,读出数据说明多次写入了
// 为什么这里使用panic呢?显示的提醒用户用法错了会比自动修复掉好一些
for range output {
panic("more than one element written in reducer")
}
}()
// 创建有缓冲的chan,容量为workers
// 意味着最多允许 workers 个协程同时处理数据
collector := make(chan interface{}, options.workers)
// 数据聚合任务完成标志
done := syncx.NewDoneChan()
// 支持阻塞写入chan的writer
writer := newGuardedWriter(output, done.Done())
// 单例关闭
var closeOnce sync.Once
var retErr errorx.AtomicError
// 数据聚合任务已结束,发送完成标志
finish := func() {
// 只能关闭一次
closeOnce.Do(func() {
// 发送聚合任务完成信号,close函数将会向chan写入一个零值
done.Close()
// 关闭数据聚合chan
close(output)
})
}
// 取消操作
cancel := once(func(err error) {
// 设置error
if err != nil {
retErr.Set(err)
} else {
retErr.Set(ErrCancelWithNil)
}
// 清空source channel
drain(source)
// 调用完成方法
finish()
})
go func() {
defer func() {
// 清空聚合任务channel
drain(collector)
// 捕获panic
if r := recover(); r != nil {
// 调用cancel方法,立即结束
cancel(fmt.Errorf("%v", r))
} else {
// 正常结束
finish()
}
}()
// 执行数据加工
// 注意writer.write将加工后数据写入了output
reducer(collector, writer, cancel)
}()
// 异步执行数据加工
// source - 数据生产
// collector - 数据收集
// done - 结束标志
// workers - 并发数
go executeMappers(func(item interface{}, w Writer) {
mapper(item, w, cancel)
}, source, collector, done.Done(), options.workers)
// reducer将加工后的数据写入了output,
// 需要数据返回时读取output即可
// 假如output被写入了超过两次
// 则开始的defer func那里将还可以读到数据
// 由此可以检测到用户调用了多次write方法
value, ok := <-output
if err := retErr.Load(); err != nil {
return nil, err
} else if ok {
return value, nil
} else {
return nil, ErrReduceNoOutput
}
}
// 数据加工
func executeMappers(mapper MapFunc, input <-chan interface{}, collector chan<- interface{},
done <-chan lang.PlaceholderType, workers int) {
// goroutine协调同步信号量
var wg sync.WaitGroup
defer func() {
// 等待数据加工任务完成
// 防止数据加工的协程还未处理完数据就直接退出了
wg.Wait()
// 关闭数据加工channel
close(collector)
}()
// 带缓冲区的channel,缓冲区大小为workers
// 控制数据加工的协程数量
pool := make(chan lang.PlaceholderType, workers)
// 数据加工writer
writer := newGuardedWriter(collector, done)
for {
select {
// 监听到外部结束信号,直接结束
case <-done:
return
// 控制数据加工协程数量
// 缓冲区容量-1
// 无容量时将会被阻塞,等待释放容量
case pool <- lang.Placeholder:
// 阻塞等待生产数据channel
item, ok := <-input
// 如果ok为false则说明input已被关闭或者清空
// 数据加工完成,执行退出
if !ok {
// 缓冲区容量+1
<-pool
// 结束本次循环
return
}
// wg同步信号量+1
wg.Add(1)
// better to safely run caller defined method
// 异步执行数据加工,防止panic错误
threading.GoSafe(func() {
defer func() {
// wg同步信号量-1
wg.Done()
// 缓冲区容量+1
<-pool
}()
mapper(item, writer)
})
}
}
}
总结
mapReduce 的源码我大概看了两个晚上,整体看下来比较累。一方面是我自身 go 语言并不是很熟练尤其是 channel 的用法,导致我需要频繁停下来查询相关文档理解作者的写法,另一方面是多个 goroutine 之间通过 channel 进行通信实现协作真的蛮烧脑(佩服作者的思维能力)。
其次看源码时第一遍看起来肯定会比较懵的,其实没关系找到程序的入口(公共基础组件一般是面向的方法)先沿着主线一路看下去把每一句代码都看懂加上注释,再看支线代码。
如果有实在看不懂的地方就查查这段代码的提交记录非常有可能是解决某个bug改动的,比如下面这段代码我死活看了好多遍都不理解。
// 聚合数据channel,需要手动调用write方法写入到output中
output := make(chan interface{})
// output最后只会被读取一次
defer func() {
// 如果有多次写入的话则会造成阻塞从而导致协程泄漏
// 这里用 for range检测是否可以读出数据,读出数据说明多次写入了
// 为什么这里使用panic呢?显示的提醒用户用法错了会比自动修复掉好一些
for range output {
panic("more than one element written in reducer")
}
}()
最后画出流程图基本就能把源码看懂了,对于我而言这方法比较笨但有效。
资料
Go Channel 详解: https://colobu.com/2016/04/14/Golang-Channels/
go-zero MapReduce文档: https://go-zero.dev/cn/mapreduce.html
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
我是 polarisxu,北大硕士毕业,曾在 360 等知名互联网公司工作,10多年技术研发与架构经验!2012 年接触 Go 语言并创建了 Go 语言中文网!著有《Go语言编程之旅》、开源图书《Go语言标准库》等。
坚持输出技术(包括 Go、Rust 等技术)、职场心得和创业感悟!欢迎关注「polarisxu」一起成长!也欢迎加我微信好友交流:gopherstudio