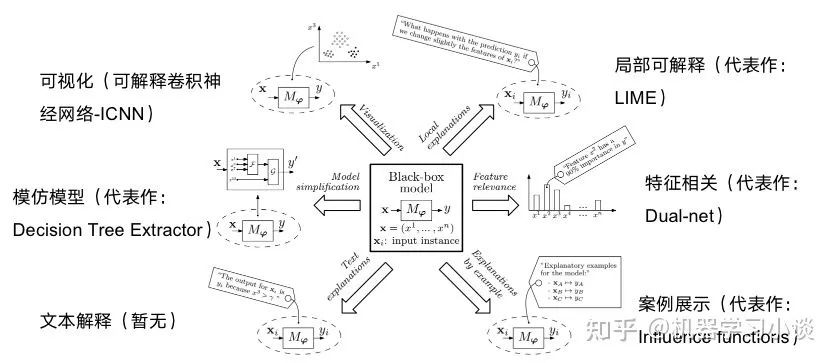
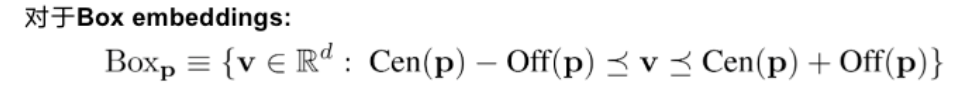1.1 什么是可解释性? 首先,什么是可解释性。由于可解释性人工智能、机器学习、神经网络等方兴未艾,可解释性的定义依旧没有准确的确定。目前较为受到认可的解释应该论文[1]提供解释Interpretability as the ability to explain or to present in understandable terms to a human,翻译过来的意识就是:可解释性是一种以人类认识的语言(术语)给人类提供解释的能力。 当然实际上人类也是高度进化的生物,不需要完整的解释,人类可以根据现有的知识自动进行脑补。所以这里引入可解释的边界。例如:为什么你这么聪明?因为我喜欢吃鱼。为什么吃鱼会聪明?因为鱼类富含DHA。为什么DHA聪明?因为 ...我们不可能无穷无尽地解释下去。根据不同的人群,我们的可解释的工作也不一样。例如给大众解释吃鱼能够聪明就行了,因为吃鱼能够聪明我们很多人已经从小到大耳熟能详了。如果我们给专业人士解释DHA为什么会是大脑聪明,我们身边很多人也答不出来,这可能就需要外部知识去解决了(例如知识图谱)。当然,可解释的这种边界越深,这个模型的能力也越强。 1.2 当前可解释性方法 XAI总结了一些可解释性的方法。例如比较著名的可视化[2]方法,这种方法在计算机视觉上使用较多。又例如模仿模型[3],这种方法比较简单,例如用一些可解释性的模型去模仿深层黑盒模型,从模仿者的结构来来研究可解释性。有例如特征相关,这些是研究显著性特征的方向,区分特征的重要性来提供可解释性,但是这种解释一般比较弱。还有很多的方法,我在上一篇文章的神经网络的可解释性综述讨论比较多,欢迎大家可以参考我的这篇文章或者其他的资料。 经典可解释性方法分类 1.3 知识图谱对比其他知识表示的优势 2012年,Google推出了一款从Metaweb中衍生而来的产品,名字叫做Knowledge Graph(知识图谱),彼时其功能在于,搜索内容时提供附加的衍生结果。随着人工智能的发展,知识图谱开始应用于更多的场景,关注度不断攀升,成为认知智能领域的核心技术之一。最重要的是,知识图谱逐渐成为人工智能应用的强大助力。
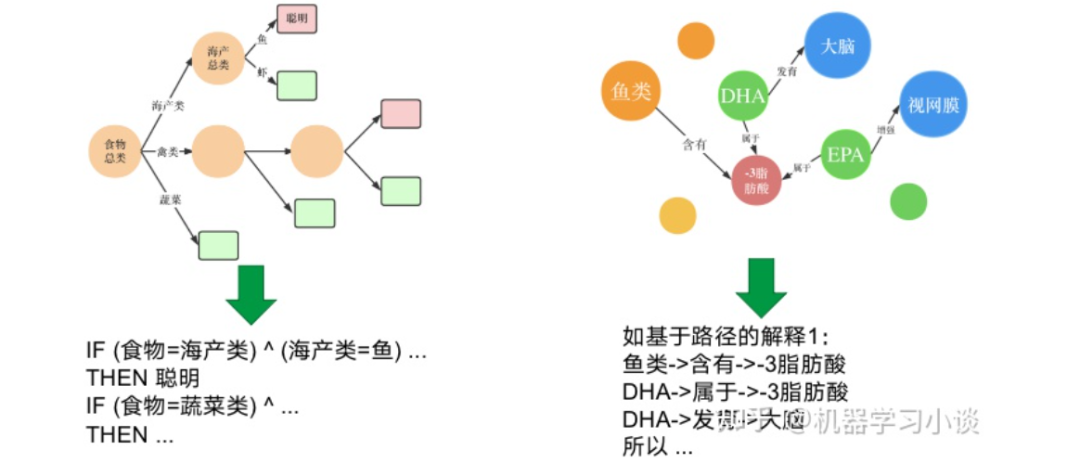
知识图谱的优势 1.4 决策树模型 vs 基于知识图谱的解释 在可解释性角度看来,由于知识图谱大多数属于异构图结构,对比其他的数据结构有更强的表达能力以及对应的更多用途的图算法。基于知识图谱的可解释性通常比之前的解释方法更有深度更容易让人类理解。如左图,是决策树中抽出的规则,总结食物的健康原因。对比右图,人工智能模型借助医疗生物领域知识图谱,例如基于路径得出的解释,显然比左图更容易理解、更有说服力。 决策树解释vs知识图谱解释 对于知识图谱在可解释人工智能上带来的优势,以及它们当前方法理论、限制以及机遇,Freddy Lecue博士在2020年的论文On the role of knowledge graphs in explainable AI[4]。给我们从人工智能的Machine Learning、Knowledge Representation and Reasoning(KRR)、Game Theory、Uncertainty in AI(UAI)、Robotics、Computer Vision 和 Natural Language Processing等分支分析了研究方法、可解释性面对的挑战、限制以及机遇。而本文主要从两个方法-基于路径的方法以及基于嵌入的方法对知识图谱在人工智能中的研究进行一个概述。 02
基于路径的方法
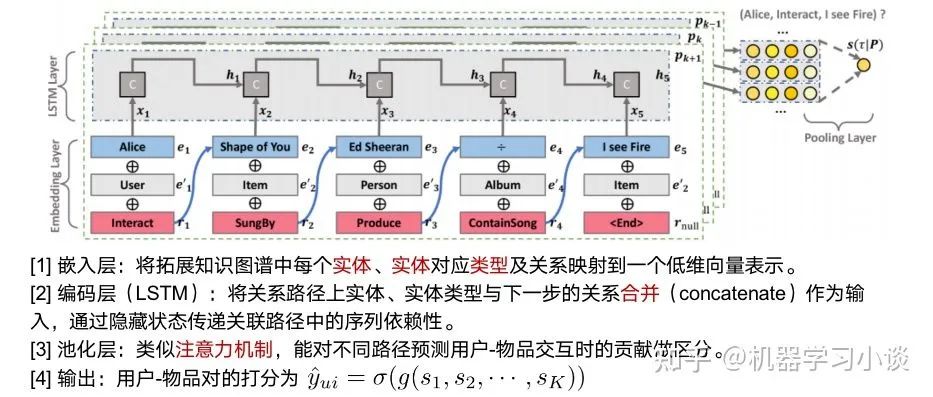
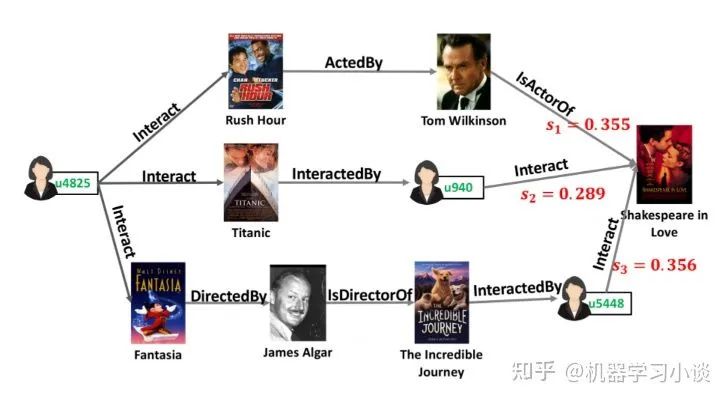
基于路径的解释方法主要应用在推荐系统上较多。下面主要介绍一个KPRN-基于知识图谱路径推理的可解释性推荐方法。这是我们在做综述的时候注意到的一篇论文Explainable Reasoning over Knowledge Graphs for Recommendation[5],在2019年发表于AAAI。 通过用户-物品的异构知识图谱,可以通过找到的关联路径作解释。这类关联路径不仅表述了知识图谱中实体和关系的语义,还能够帮助我们理解用户的兴趣偏好,赋予推荐系统推理能力和可解释性。 该论文提出了一种基于循环神经网络的方法KPRN,建模用户和物品对在知识图谱中存在的关联路径,按照路径的解释分数对路径进行排序后输出。它的训练数据主要来源于用户的历史记录CTR,其标签是用户最后对该项目(音乐歌曲)的评分或者是其他评价方式。例如有数据记录用户最终点击了Castle on the hill之前有哪些操作以及用户对该歌曲的最终评分。 Explainable Reasoning over Knowledge Graphs for Recommendation 我们先看一下模型,模型分为三层:嵌入层,将知识图谱的实体以及对应的关系映射到一个向量作为输入。再上一层是解码层,这里用了LSTM单元,这一步的作用主要是根据这些路径对下游任务进行解码,学习这些路径的时序依赖。最后经过池化层的处理后,根据不同的路径分数对物品进行一个打分。 KPRN训练 当这种模型训练好之后,我们可以使用这种模型对用户进行物品推荐的同时,追溯推荐的原因。例如这里路径S3最高分。 这条路径得出的一个解释是,“有很多观看该电影的用户,都喜欢The Incredible Journey;而这部电影刚好也是由你喜欢的电影Fantasia的导演Jams Algar指导的;不妨你可以试试。”当然这个解释可以用生成模型生成。 我们甚至还能从其他的高分路径得到这个用户感兴趣的导演James等。 KPRN的一个解释案例 除了KPRN之中方法之外,我们统计到了不少其他方法,例如这是一篇同一年发表在ACM的论文Reinforcement knowledge graph reasoning for explainable recommendation[6],它的思路用强化学习的方法去代替有监督学习,通过一个智能体自动在图上探索解释的路径,使得这种方法得到的解释更加灵活。具体细节大家可以自行去看这一篇论文。 关于KPRN收到的一个主要问题:关于刚刚基于路径的算法,在预测的时候,是怎样挑选路径的。一个点到另外一个点的路径数量随着长度限制应该是指数级别的,这篇文章是如何解决这种问题的呢?同时,我也注意到,它的训练数据是用户的CTR,模型学习这种CTR路径来为用户提供可解释性,你觉得真的有那么高的解释性吗?也许用户的一次点击是随心所欲的呢? 答复:这个问题问的很细节。我也曾经好奇过,但是我发现,作者挑选路径仅仅基于路径的长度来筛选,譬如筛选路径长度少于6跳的。但是我同时也会疑问,解释一定就跟长度有关吗?难道长路径的解释就一定比短路径要差?我发现很多读者也提出不同的想法,例如用随机游走之类的算法,收敛的时候对路径的概率进行排序,最后选择topk之类,这些也我们可以深挖的方向。 关于第二个问题,其实我也觉得单单依据用户CTR历史信息,作为可解释性的一种训练,也是不靠谱的。因为用户点击或者进行其他行为例如评论或者收藏之类的,不一定是有意的,有时候就是随心所欲。我认为这里确实可以过滤的,就是过滤掉一些可能是用户随心所欲的行为,例如看点击的时间频率之类的,或者甚至人工打标记来训练一个过滤器之类的。不过我认为作者的初心只是想提出有这样的一种基于路径的方向,后面的例如强化学习的方法,要比种方法强不少,我觉得读者有兴趣可以探究一下。 03
基于嵌入的方法
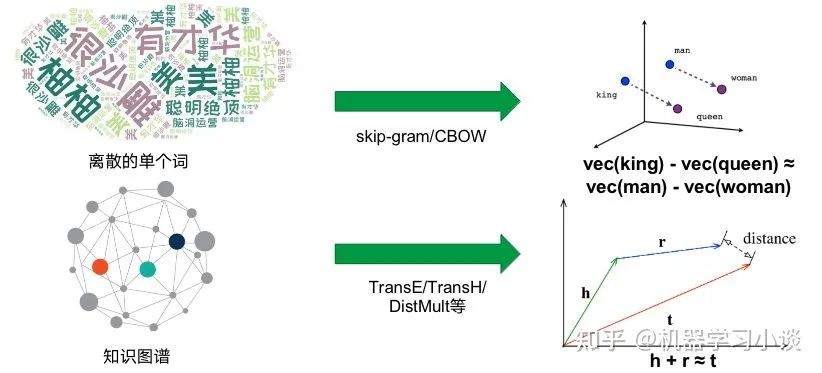
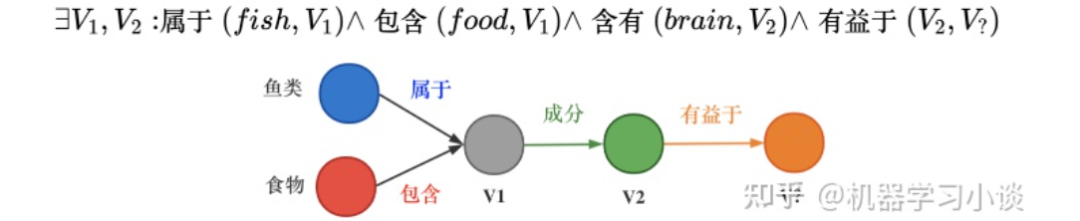
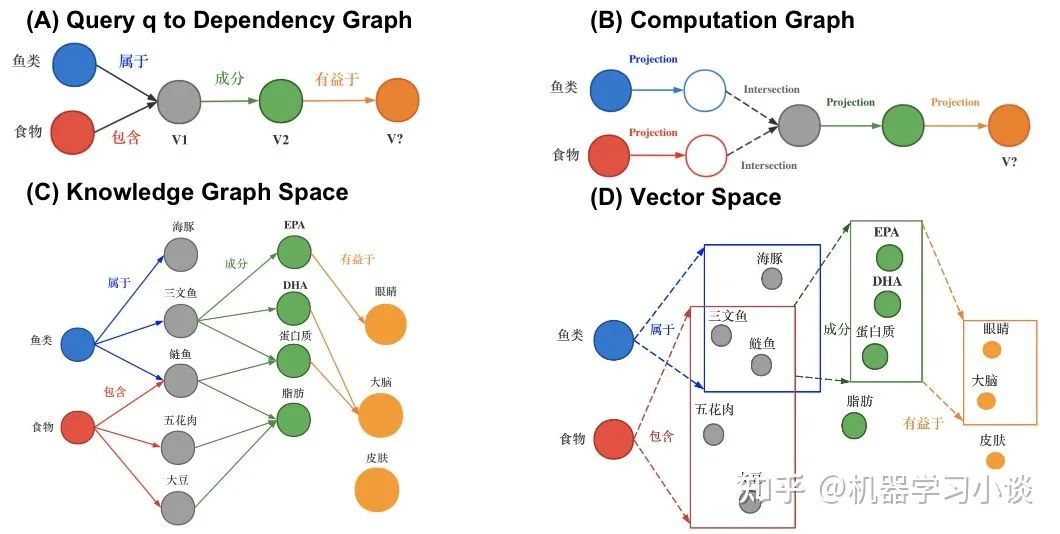
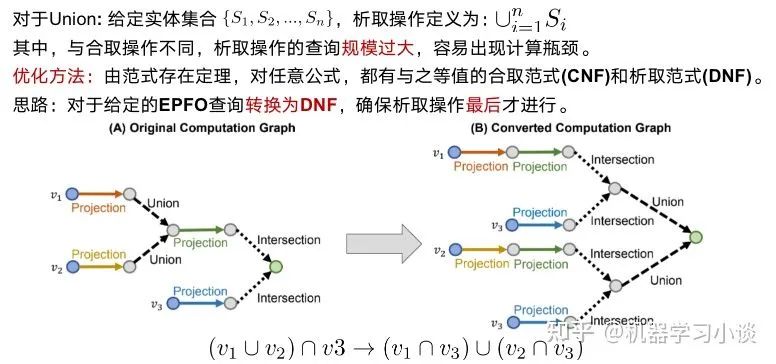
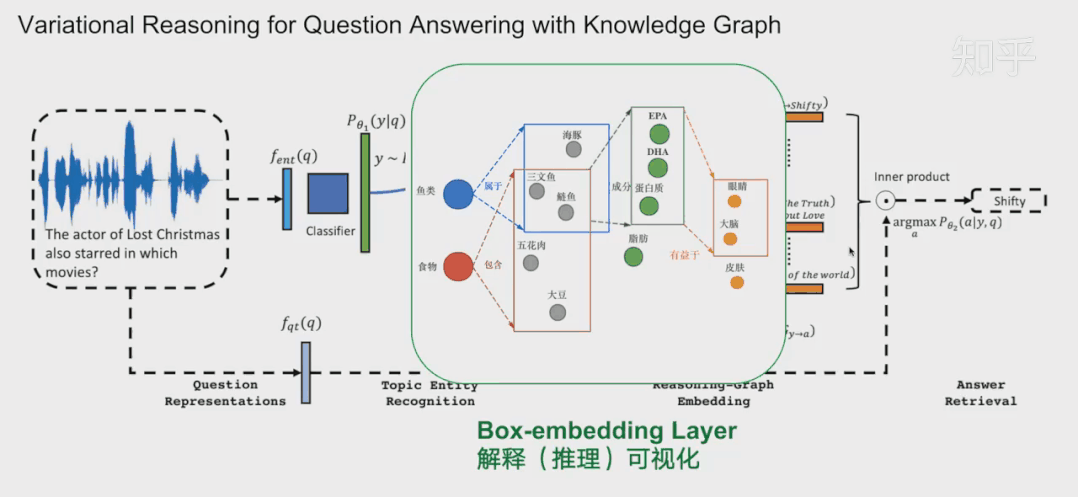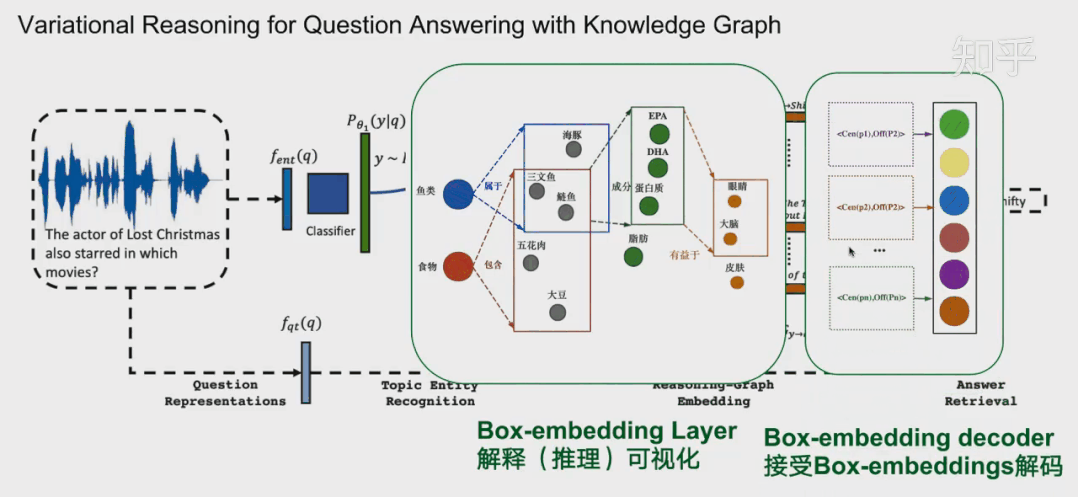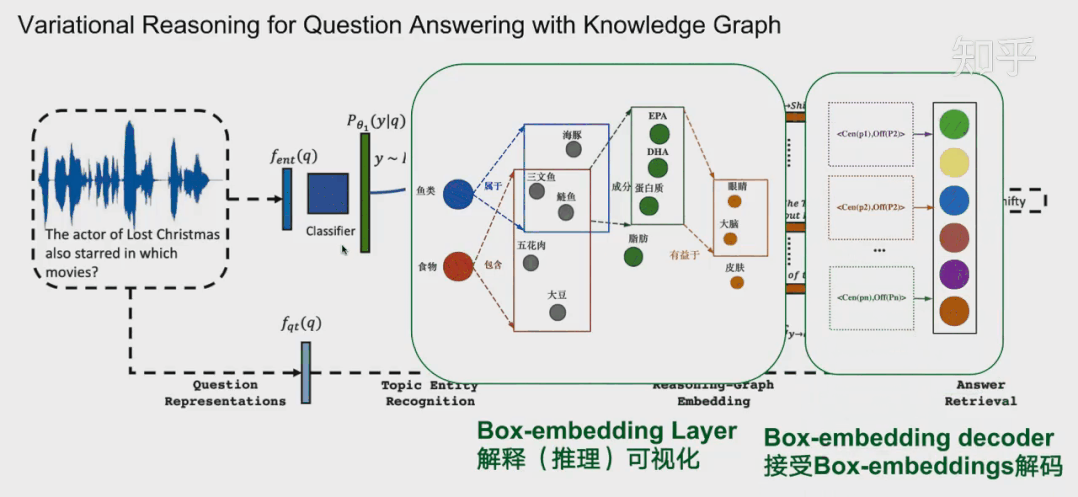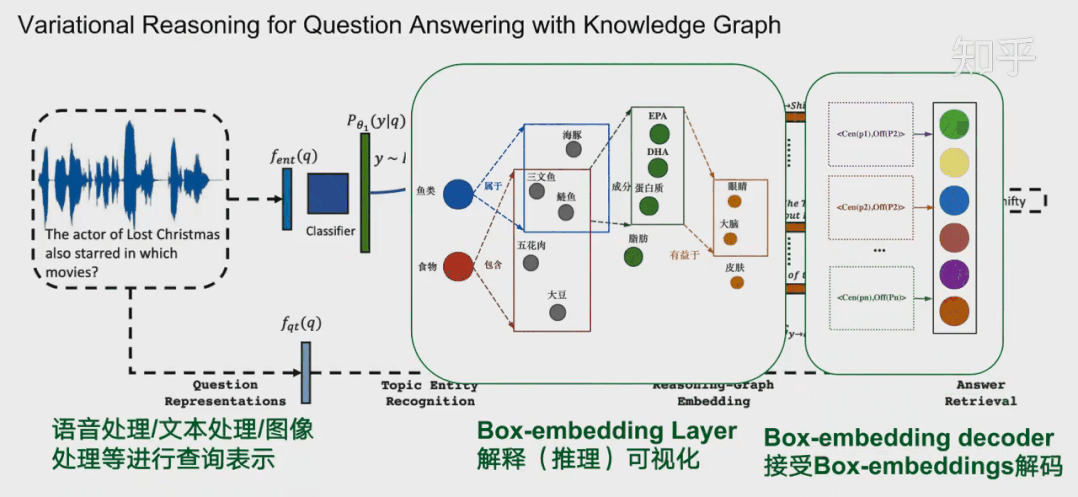
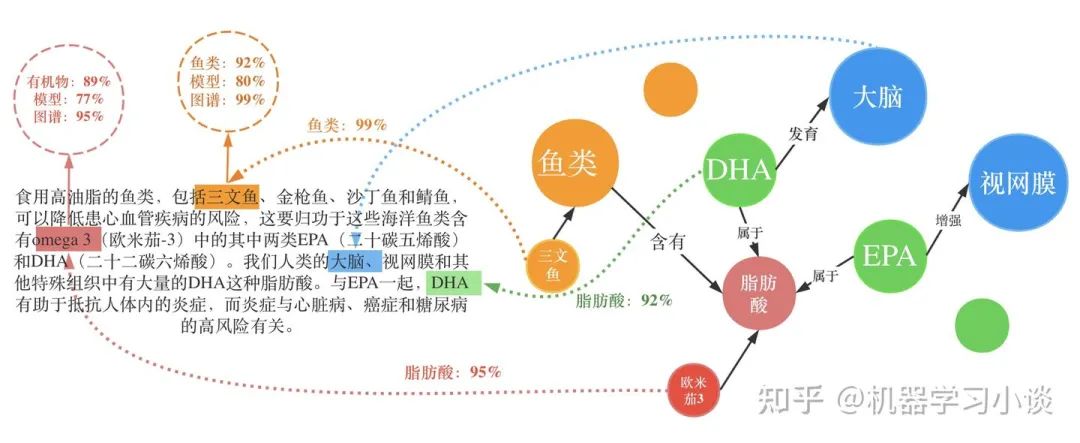
下面我再给大家分享另一种方法-基于嵌入的方法,以QUERY2BOX为例。首先简单介绍一下嵌入-embedding。知识图谱的表示学习受自然语言处理关于词向量研究的启发,因为在word2vec的结果中发现了一些词向量具有空间平移性,如图: embedding vec(king)−vec(queen)≈vec(man)−vec(woman) 同理,我们是否可以参考word2vec,将知识图谱中包括实体和关系的元素映射到一个连续的向量空间中,为每个元素学习在向量空间中表示,向量空间中的表示可以是一个或多个向量或矩阵。这些方法有很多,之前也有很多文章提过,大家可以参考参考。 而当前的一些嵌入,也就是用把实体映射成向量或者高维度空间中的一个点,有不少缺点:例如对于人工智能系统其中的对话机器人,面对复杂的问题:例如有鱼类食物富含的物质对身体哪些部位有好处?这种带有更深的逻辑推理问题,往往都有不止一个的答案,蕴含很多集合与集合之间的操作,因此用单个点或者向量是难以表示的。同时这些单点进行(合取/析取)也就是并集和交集操作也是不自然的。 “鱼类食物富含的物质对身体哪些部位有好处?”逻辑依赖图 所以小结当前方法:将复杂问题建模成向量空间的一个点。其普遍缺点是: 1.一个复杂的问题可能代表着一个很大的答案实体集合,用一个点(类比一个典型实体)表示是不合理的;2.向量空间中定义两个点的逻辑操作符(合取/析取)也是不合理的。 QUERY2BOX:Reasoning over Knowledge Graphs in Vector Space using Box Embeddings[7]发表在2020年的ICLR会议上。那么QUERY2BOX是思路是什么呢?大家也可以从主题猜到,QUERY2BOX是用“箱子”不再是一个点来进行嵌入。它的目标是想融入一阶逻辑推理EPFO能力到这些嵌入之中。大家可以看到右图,这些一个一个的box嵌入,看起来是适合集合之间的操作的,而且这些操作都是产生一个个新的box,因此它的操作也是封闭,一种闭包。从论文的总结看,box-embeddings有以下优势: 1.Box-embeddings更适合复杂而且答案多组合的推理问题;2.Box之间依然可以进行一阶逻辑操作EPFO(Existenial Positive First-order);3.Box操作的结果是产生新的box,因此操作符是封闭的。 那么QUERY2BOX是如何实现这种box-embedings?还是刚刚那个问题“鱼类食物富含的物质对身体哪些部位有好处?“。我们看一下具体的细节。图A,我们首先将复杂的抽象问题分解为依赖图,这是一种DAG。如果直接回答这些逻辑问题对于人工智能来说非常吃力,那么这种依赖分解对于人工智能则轻松得多,因此将查询转换为DAG依赖图是容易实现的一个环节。从人类的角度看,我们分析了问题的逻辑后,我们就可以借助外部知识(知识图谱)寻找答案。 对于下图C,我们可以找到鱼类和食物的交集“三文鱼和鲢鱼”,从该交集,我们可以继续找到其成分EPA、DHA等,从而可以继续找到对身体有益部分(橙色的实体)。从计算机的角度,根据DAG,可以编译为计算机理解的运算-计算图(如图B)。计算机可以根据这些操作,图C,例如对鱼类进行Projection得到新的box,与食物的box进行交集(Intersection)就得到了鱼类食物,诸如此类地一步一步推导出答案,橙色的箱子。 QUERY2BOX 关于箱子的定义,这里箱子是一个虚拟的中心点和偏移定义的,p是箱子里面的实体的坐标,off函数根据不同的实体计算一个偏移量。其中off函数,查看源代码,是一个神经网络实现的动态计算偏移量的函数,可以根据不同的实体p估计其偏移量。 而论文提出是这样训练的:训练的时候,有实体在箱子外面的,也有实体在箱子里面的,因此他们分为两个距离度量,dist-outside和dist-inside;dist-outside的在箱子外的实体距离有多远,目的是想把属于这个箱子的实体“拉扯”到箱子里面;而dist-inside是想让箱子内部的实体更加接近箱子的中心。 关于参数 ∈[0,1],如果 =0,意味着优化目标是把所有的答案实体控制在box内部即可。如果 =1,距离则变成原始L1距离,将会把所有实体向中心拉扯。 对于刚刚的计算图,Projection的定义是实体集合和他们对应的关系集合在集合层面上进行,投影操作,这一步跟TransE很相似。 Prohection定义 对于合取操作(Intersection),它们的设计会复杂一点。它们在交集时候,交集的箱子会分配不同的权重(类似注意力机制),并且交集后的箱子的大小也会由一个MLP进行大小调整,这里用了sigmoid这里对箱子进行一定大小衰减。 Intersection定义 对于析取操作(就是并集),大家可以想到,并集后的元素或者空间一般都是越来越大的。这样的话,如果后面再有其他的操作,计算成本就会更很多。而他们想出了一种优化方法。根据逻辑命题的范式存在定理,其实对应任何的公式,都能够找到等值的CNF和DNF。这里转换为DNF,也就是说所有的析取操作(并集操作将推到最后才进行)。如下图,这里就进行DNF转换,让并集操作在最后计算。 Union定义 通常在模型中,这一层会放在中间作为可解释层展示给用户。在18年提出的VRN网络,用于语音识别,就是这种架构。不过当时box-embedding还没有提出来,它们这一层使用一种基于路径的方式进行推理。可能有同学就想到了,这一层换成Box-embedding,后面编码器改成box-embedings的编码器,那不就是可以采用这个最新的技术呢?这个也是我们的一个机会。
1. Towards a rigorous science of interpretable machine learning F Doshi-Velez, B Kim - arXiv preprint arXiv:1702.08608, 2017 - arxiv.org https://arxiv.org/abs/1702.086082. K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” arXiv preprint arXiv:1312.6034, 2013. https://arxiv.org/abs/1312.60343“Extracting Decision Trees From Trained Neural Networks”. SIGKDD. July 23-26,2002 https://www.sciencedirect.com/science/article/pii/S00313203980018124. On the role of knowledge graphs in explainable AI F Lecue - Semantic Web, 2020 - content.iospress.com https://content.iospress.com/articles/semantic-web/sw1903745. Explainable reasoning over knowledge graphs for recommendation X Wang, D Wang, C Xu, X He, Y Cao… - Proceedings of the AAAI …, 2019 - ojs.aaai.org https://ojs.aaai.org/index.php/AAAI/article/view/44706. Since 2021 Since 2020 Since 2017 Custom range... Sort by relevance Sort by date [PDF] arxiv.org Reinforcement knowledge graph reasoning for explainable recommendation Y Xian, Z Fu, S Muthukrishnan, G De Melo… - Proceedings of the 42nd …, 2019 - dl.acm.org https://dl.acm.org/doi/abs/10.1145/3331184.33312037. Query2box: Reasoning over knowledge graphs in vector space using box embeddings H Ren, W Hu, J Leskovec - arXiv preprint arXiv:2002.05969, 2020 - arxiv.org https://arxiv.org/abs/2002.059698. hete-cf: social-based collaborative filtering recommendation using heterogeneous relations c luo, w pang, z wang, c lin - 2014 ieee international …, 2014 - ieeexplore.ieee.org https://arxiv.org/pdf/1412.7610.pdf9. Luciano Serafini and Artur d’Avila Garcez. Logic tensor networks: Deep learning and logical reasoning from data and knowledge. arXiv preprint arXiv:1606.04422, 2016. https://arxiv.org/abs/1606.0442210. Tim Rocktaschel and Sebastian Riedel. End-to-end differentiable proving. In ¨ NIPS, pages 3788–3800, 2017. https://arxiv.org/pdf/1705.11040 版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!