
终于有人把Spark大数据分析与挖掘讲明白了
当我们每天面对扑面而来的海量数据时,是战斗还是退却,是去挖掘其中蕴含的无限资源,还是让它们自生自灭?我们的答案是:“一切都取决于你自己”。对于海量而庞大的数据来说,在不同人眼里,既可以是一座亟待销毁的垃圾场,也可以是一个埋藏有无限珍宝的金银岛,这一切都取决于操控者的眼界与能力。本书的目的就是希望所有的大数据技术人员都有这种挖掘金矿的能力!
大数据时代
什么是“大数据”?一篇名为 “互联网上一天”的文章告诉我们:
一天之中,互联网上产生的全部内容可以刻满 1.68 亿张 DVD,发出的邮件有2940 亿封之多(相当于美国两年的纸质信件数量),发出的社区帖子达200万个(相当于《时代》杂志770 年的文字量),卖出的手机数量为 37.8万台,比全球每天出生的婴儿数量高出 37.1万。
正如人们常说的一句话:“冰山只露出它的一角”。大数据也是如此,“人们看到的只是其露出水面的那一部分,而更多的则是隐藏在水面下”。随着时代的飞速发展,信息传播的速度越来越快,手段也日益繁多,数据的种类和格式趋于复杂和丰富,并且在存储上已经突破了传统的结构化存储形式,向着非结构存储飞速发展。大数据科学家 JohnRauser 提到一个简单的定义:“大数据就是任何超过了一台计算机处理能力的庞大数据量”。亚马逊网络服务 CAWS)研发小组对大数据的定义:“大数据是最大的宣传技术,也是最时髦的技术,当这种现象出现时,定义就变得很混乱。” Kely 说:“大数据可能不包含所有的信息,但是我觉得大部分是正确的。对大数据的一部分认知在于它是如此之大,分析它需要多个工作负载,这是AWS 的定义。当你的技术达到极限时也就是数据的极限”
飞速产生的数据构建了大数据,海量数据的时代称为大数据时代。但是,简单地认为那些掌握了海量存储数据资料的人是大数据强者显然是不对的。真正的强者是那些能够挖掘出隐藏在海量数据背后获取其中所包含的巨量数据信息与内容的人,是那些掌握专门技能懂得怎样对数据进行有目的、有方向处理的人。只有那些人,才能够挖掘出真正隐藏的宝库,拾取金山中的珍宝,从而实现数据的增值,让大数据“为我所用”。
大数据分析的要素
可以说,大数据时代最重要的技能是掌握对大数据的分析能力。只有通过对大数据的分析,提炼出其中所包含的有价值的内容才能够真正做到 “为我所用”。换言之,如果把大数据比作一块洪土,那么只有强化对土地的“耕耘”能力才能通过 “加工” 实现数据的 “增值” 一般来说,大数据分析涉及 5个要素。
1. 有效的数据质量
任何数据分析都来自于真实的数据基础,而一个真实数据是采用标准化的流程和工具对数据进行处理得到的,可以保证一个预先定义好的高质量的分析结果。
2.优秀的分析引擎
对于大数据来说,数据的来源多种多样,特别是非结构化数据,其来源的多样性给大数据分析带来了新的挑战。因此,我们需要一系列的工具去解析、提取、分析数据。大数据分析引擎用手从数据中提取我们所需要的信息。
3. 合适的分析算法
采用合适的大数据分析算法,能让我们深入数据内部挖掘价值。在算法的具体选择上,不仅要考虑能够处理的大数据数量,还要考虑对大数据处理的速度。
4. 对未来的合理预测
数据分析的目的是对已有数据体现出来的规律进行总结,并且将现象与其他情况紧密连接在一起,从而获得对未来发展趋势的预测。大数据分析也是如此。不同的是,在大数据分析中,数据来源的基础更为广泛,需要处理的方面更多。
5. 数据结果的可视化
大数据的分析结果更多的是为决策者和普通用户提供决策支持和意见提示,其对较为深奥的数学含义不会太了解。因此,必然要求数据的可视化能够直观地反映出经过分析后得到的信息与内容,能够较为容易地被使用者所理解和接受。
可以说大数据分析是数据分析最前沿的技术。这种新的数据分析是目标导向的,不用关心数据的来源和具体格式,能够根据我们的需求去处理各种结构化、半结构化和非结构化的数据,配合使用合适的分析引擎,能够输出有效结果,提供一定的对未来趋势的预测分析服务,能够面向更广泛的用户快速部署数据分析应用。
简单、优雅、有效的Spark
Apache Spark 是加州大学伯克利分校的 AMPLabs 开发的开源分布式轻量级通用计算框架。与传统的数据分析框架相比,Spark 在设计之初就是基于内存而设计的,因此比一般的数据分析框架具有更高的处理性能,并且对多种编程语言(例如 Java、Scala 及Python 等)提供编译支持,使得用户使用传统的编程语言即可进行程序设计,从而使得用户的快速学习和代码维护能力大大提高。
简单、优雅、有效——这就是 Spark!
Spark 是一个简单的大数据处理框架,它可以帮助程序设计人员和数据分析人员在不了解分布式底层细节的情况下,编写一个简单的数据处理程序就可以对大数据进行分析计算。
Spark 是一个优雅的数据处理程序,借助于 Scala 函数式编程语言,以前往往几百上千行的程序,这里只需短短十行即可完成。Spark 创新了数据获取和处理的理念,简化了编程过程,不再需要建立索引来对数据进行分类,通过相应的表链接即可将需要的数据匹配成我们需要的格式。Spark 没有臃肿,只有优雅。
Spark 是一款有效的数据处理工具程序,充分利用集群的能力对数据进行处理,其核心就是Mapeduoe数据处理。通过对数据的输入、分拆与组合,可以有效地提高数据管理的安全性,同时能够很好地访问管理的数据。
Spark 是建立在 JVM 上的开源数据处理框架,开创性地使用了一种从最底层结构上就与现有技术完全不同,但足更加具有分进性的款搬行饰和必理技木,这样使用 Spark 时无需掌握系统的底层细节,更不诺要购买价格不菲的软硬件平合。它借助于架设在普通商用机上的HDES 存储系统,就可以无限制地在价格低廉的商用 PC 上搭建所需要规模的评选数据分析平台。即使从只有一台商用 PC 的集群平台开始,也可以在后期任意扩充其规模。
Spark 是基于 MapReduice 并行算法实现的分布式计算,其拥有 MapReduce 的优点,对数据分析细致而准确。更进一步,Spark 数据分析的结果可以保持在分布式框架的内存中,从而使得下一步的计算不再频繁地读写 HDFS,使得数据分析更加快速和方便。
提示:需要注意的是,Spark 并不是“仅”使用内存作为分析和处理的存储空间,而是和HDFS 交互使用,首先尽可能地采用内存空间,当内存使用达到一定阈值时,仍会将数据存储在 HDFS 上。
除此之外,Spark通过 HDFS 使用自带的和自定义的特定数据格式 (RDD、DataFrame ),基本上可以按照程序设计人员的要求处理任何数据(音乐、电影、文本文件、Log 记录等),而不论数据类型是什么样的。编写相应的 Spark 处理程序,可以帮助用户获得任何想要的答案。
有了Spark 后,再没有数据被认为是过于庞大而不好处理或不好存储的,从而解决了之前无法解决的、对海量数据进行分析的问题,便于发现海量数据中潜在的价值。
Spark 3.0 核心--ML
首先谈一下新旧版本MLlib 的区别ML和MLlib 都是 Spark 中的机器学习库,都能满足目前常用的机器学习功能需求:Spank 官方推荐使用 ML,因为它功能更全面、更灵活,未来会主要支持 ML, MLlib 很有可能会被废弃。
ML 主要操作的是 DataFrame,而 MLlib操作的是 RDD,也就是说二者面向的数据集不一样。相比于 MLlib在RDD提供的基本操作,ML 在 DataFrame 上的抽象级别更高,数据和操作耦合度更低。ML 中的操作可以使用 Pipeline, 跟 Sklearn一样,可以把很多操作(算法、特征提取、特征转换)以管道的形式串起来,然后让数据在这个管道中流动。ML 中无论是什么模型,都提供了统一的算法操作接口,比如模型训练都是fit。
如果将 Spark 比作一颗闪亮的星星,那么其中最明亮、最核心的部分就是 ML。ML是一个构建在 Spark 上、专门针对大数据处理的并发式高性能机器学习库,其特点是采用较为先进的选代式、内存存储的分析计算,使数据的计算处理速度大大高于普通的数据处理引擎。
ML 机器学习库还在不停地更新中,Apache 的相关研究人员仍在不停地为其中添加更名的机器学习算法。目前 ML 中已经有通用的学习算法和工具类,包括统计、分类、回归、聚类、降维等。
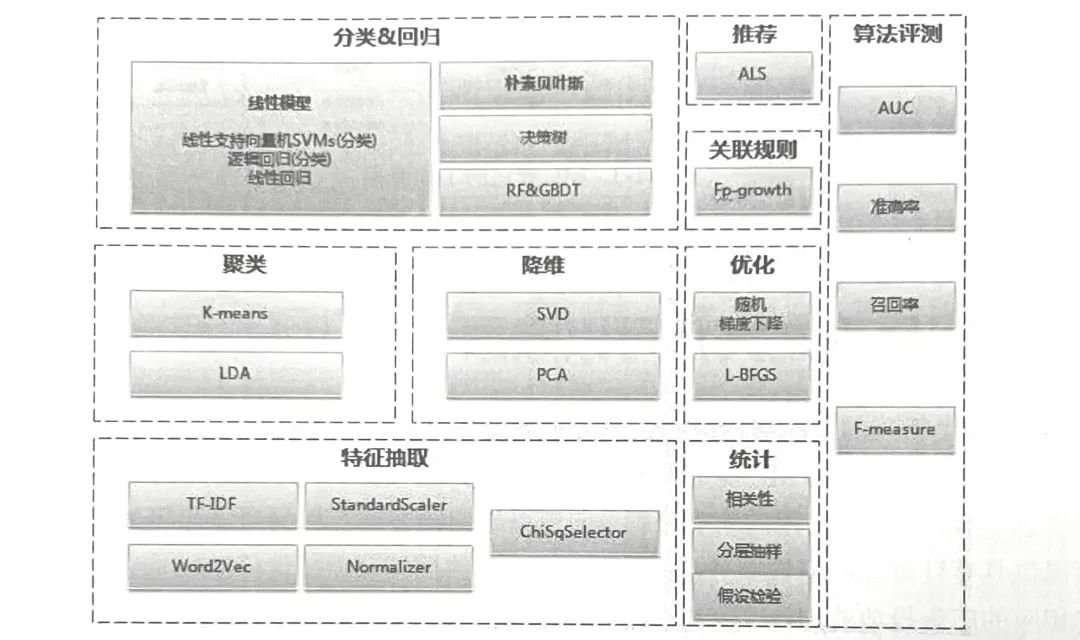
对预处理后的数据进行分析,从而获得包含着数据内容的结果。ML 作为 Spark 的核心处理引擎,在诞生之初就为处理大数据而采用了“分治式”的数据处理模式,将数据分散到各个节点中进行相应的处理。通过数据处理的“依赖” 关系,使处理过程层层递进。这个过程可以依据要求具体编写,好处是避免了大数据处理框架所要求进行的大规模数据传输,从而节省了时间、提高了处理效率。
ML 借助函数式程序设计思想,让程序设计人员在编写程序的过程中只需要关注其数据,而不必考虑函数调用顺序,不用谨慎地设置外部状态。所有要做的就是传递代表了边际情况的参数。
ML 采用 Scala 语言编写。Scala 语言是运行在JVM 上的一种函数式编程语言,特点是可移植性强,最重要的特点是“一次编写,到处运行”。借助于 RDD 或 DataFrame 数据统一输入格式,让用户可以在不同的 DDE 上编写数据处理程序,通过本地化测试后可以在略微修改运行参数后直接在集群上运行。对结果的获取更为可视化和直观,不会因为运行系统底层的不同而造成结果的差异与改变。
本文摘编自《Spark 3.0大数据分析与挖掘:基于机器学习》,经出版方授权发布。(ISBN:9787302598992)
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码