
Flume+Kafka双剑合璧玩转大数据平台日志采集
大数据平台每天会产生大量的日志,处理这些日志需要特定的日志系统。
一般而言,这些系统需要具有以下特征:
构建应用系统和分析系统的桥梁,并将它们之间的关联解耦
支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统
具有高可扩展性。即:当数据量增加时,可以通过增加节点进行水平扩展
为此建议将日志采集分析系统分为如下几个模块:
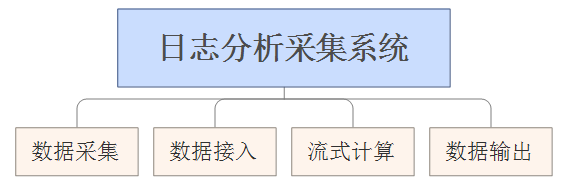
数据采集模块:负责从各节点上实时采集数据,建议选用Flume-NG来实现。
数据接入模块:由于采集数据的速度和数据处理的速度不一定同步,因此添加一个消息中间件来作为缓冲,建议选用Kafka来实现。
流式计算模块:对采集到的数据进行实时分析,建议选用Storm来实现。
数据输出模块:对分析后的结果持久化,可以使用HDFS、MySQL等。

大数据平台每天会产生大量的日志,处理这些日志需要特定的日志系统。目前常用的开源日志系统有 Flume 和Kafka两种, 都是非常优秀的日志系统,且各有特点。下面我们来逐一认识一下。
Flume是一个分布式、可靠、高可用的海量日志采集、聚合和传输的日志收集系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
可靠性
Flume的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据。Flume 使用事务性的方式保证传送Event整个过程的可靠性。
可扩展性
Flume中只有一个角色Agent,其中包含Source、Sink、Channel三种组件。一个Agent的Sink可以输出到另一个Agent的Source。这样通过配置可以实现多个层次的流配置。
功能可扩展性
Flume自带丰富的Source、Sink、Channel实现。用户也可以根据需要添加自定义的组件实现, 并在配置中使用起来。
Flume的基本架构是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是 Source、Channel、Sink。数据以Event为基本单位经过Source、Channel、Sink,从外部数据源来,向外部的目的地去。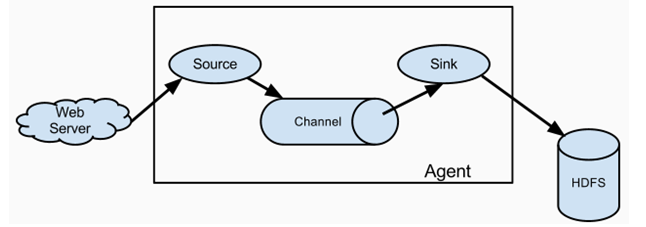
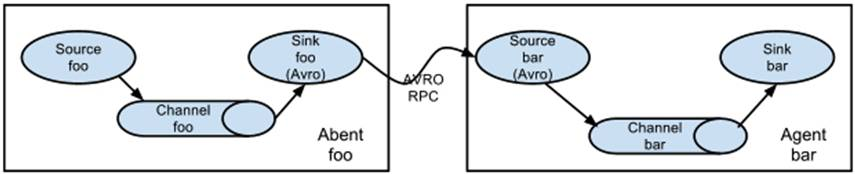
除了单Agent的架构外,还可以将多个Agent组合起来形成多层的数据流架构:
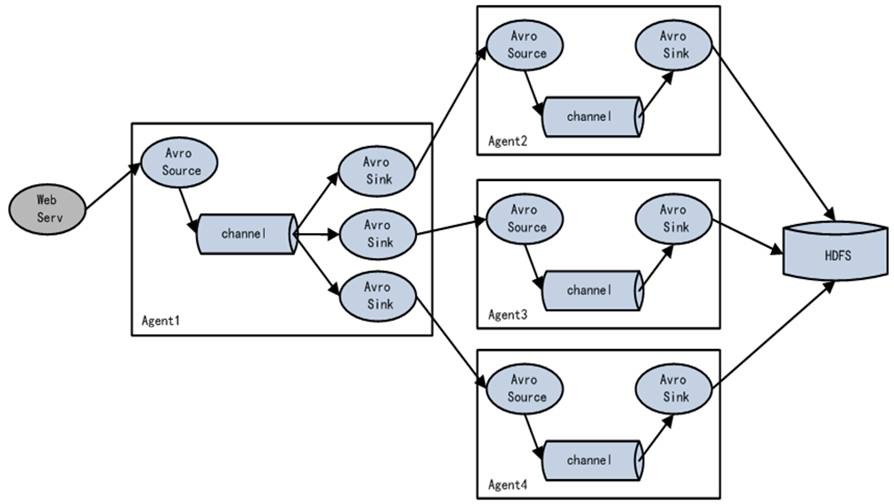
多个Agent顺序连接:将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑Failover的话,出现故障将影响整个Flow上的Agent收集服务。
多个Agent的数据汇聚到同一个Agent:这种情况应用的场景比较多,适用于数据源分散的分布式系统中数据流汇总。
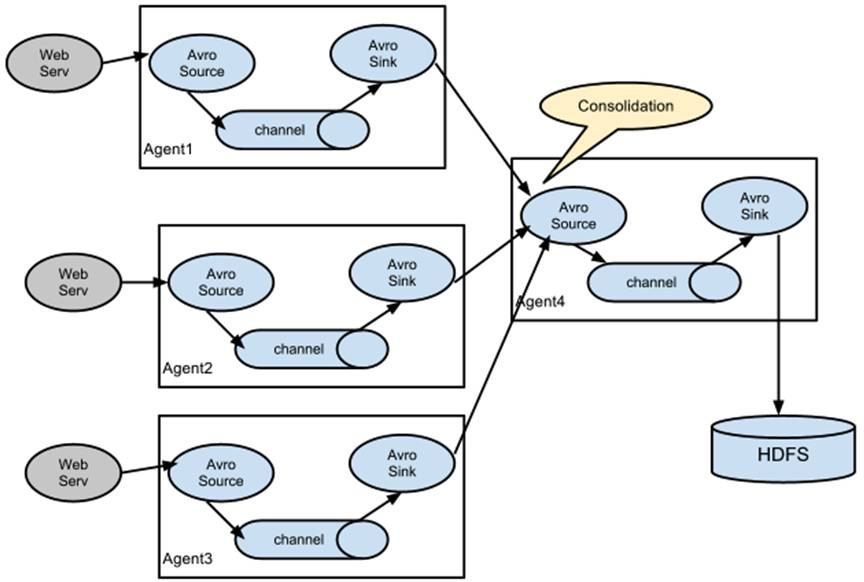
多路(Multiplexing)Agent:多路模式一般有两种实现方式,一种是用来复制,另一种是用来分流。复制方式可以将最前端的数据源复制多份,分别传递到多个Channel中,每个Channel接收到的数据都是相同的。分流方式,Selector可以根据Header的值来确定数据传递到哪一个Channel。
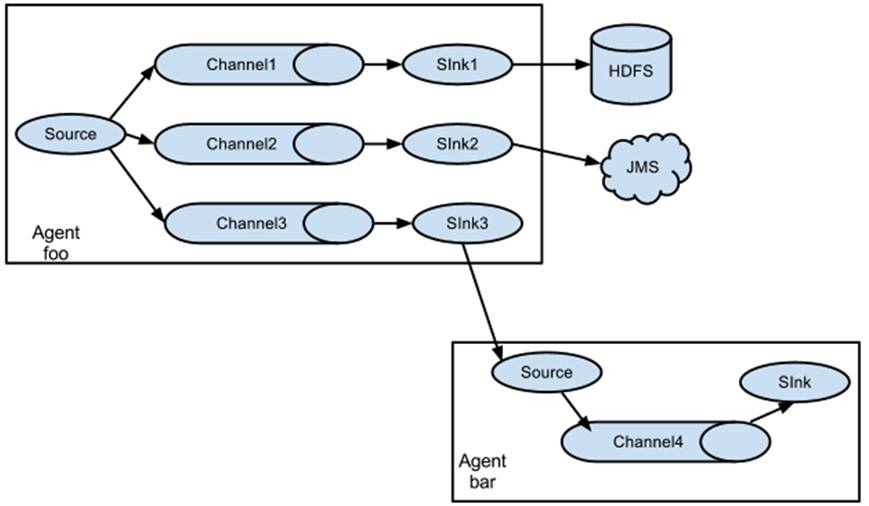
实现Load Balance功能:Channel中Event可以均衡到对应的多个Sink组件上,而每个Sink组件再分别连接到一个独立的Agent上,这样可以实现负载均衡。
kafka实际上是一个消息发布订阅系统。Producer向某个Topic发布消息,而Consumer订阅某个Topic的消息。一旦有新的关于某个Topic的消息,Broker会传递给订阅它的所有Consumer。
数据在磁盘上的存取代价为O(1)
Kafka以Topic来进行消息管理,每个Topic包含多个Partition,每个Partition对应一个逻辑log,由多个Segment组成。每个Segment中存储多条消息。消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
为发布和订阅提供高吞吐量
Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
分布式系统,易于向外扩展
所有的Producer、Broker和Consumer都会有多个,均为分布式的。无需停机即可扩展机器。
Kafka是一个分布式的、可分区的、可复制的消息系统,维护消息队列。
Kafka的整体架构非常简单,是显式分布式架构,Producer、Broker和Consumer都可以有多个。Producer,consumer实现Kafka注册的接口,数据从Producer发送到Broker,Broker承担一个中间缓存和分发的作用。Broker分发注册到系统中的Consumer。Broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单、高性能、且与编程语言无关的TCP协议。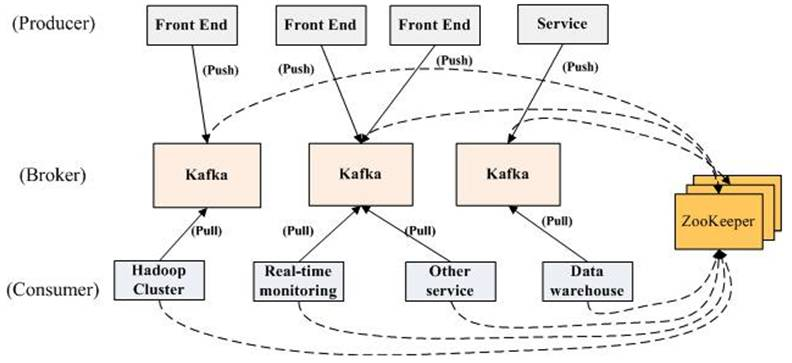
Flume和Kafka都是优秀的日志系统,其都能实现数据采集、数据传输、负载均衡、容错等一系列的需求, 但是两者之间还是有着一定的差别。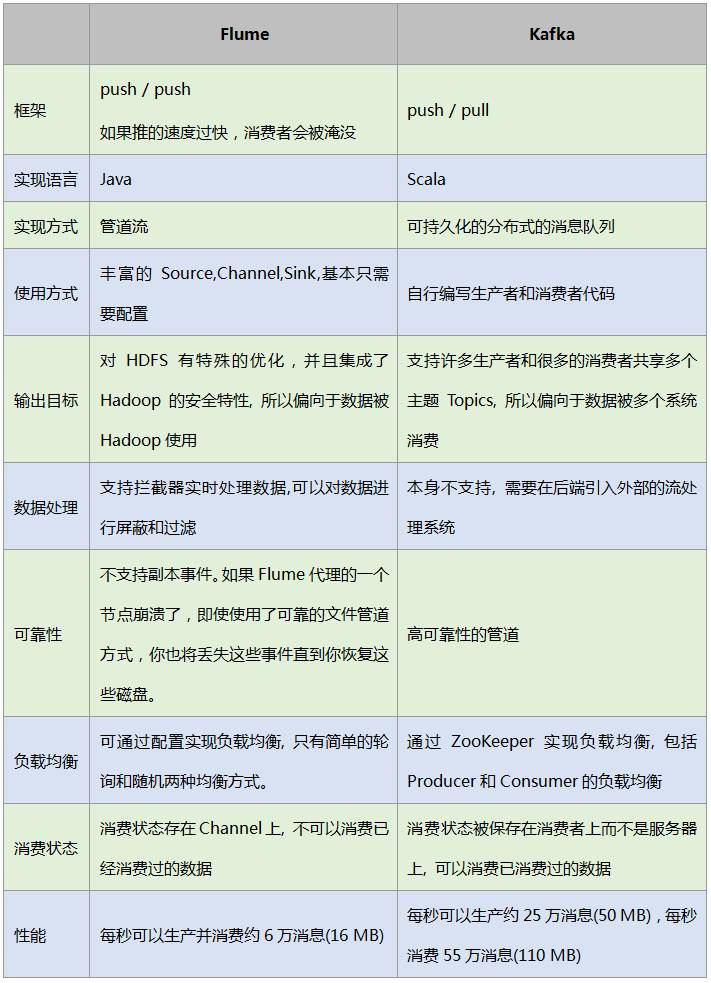
由此可见Flume和Kafka还是各有特点的:
Flume 适用于没有编程的配置解决方案,由于提供了丰富的source、channel、sink实现,各种数据源的引入只是配置变更就可实现。
Kafka 适用于对数据管道的吞吐量、可用性要求都很高的解决方案,基本需要编程实现数据的生产和消费。
建议采用Flume作为数据的生产者,这样可以不用编程就实现数据源的引入,并采用Kafka Sink作为数据的消费者,这样可以得到较高的吞吐量和可靠性。如果对数据的可靠性要求高的话,可以采用Kafka Channel来作为Flume的Channel使用。
Flume作为消息的生产者,将生产的消息数据(日志数据、业务请求数据等)通过Kafka Sink发布到Kafka中。
假设现有Flume实时读取/data1/logs/component_role.log的数据并导入到Kafka的mytopic主题中。环境预设为:
Zookeeper 的地址为 zdh100:2181 zdh101:2181 zdh102:2181 Kafka broker的地址为 zdh100:9092 zdh101:9092 zdh102:9093
配置Flume agent,如下修改Flume配置:
gent1.sources = logsrc
agent1.channels = memcnl
agent1.sinks = kafkasink
#source section
agent1.sources.logsrc.type = exec
agent1.sources.logsrc.command = tail -F /data1/logs/component_role.log
agent1.sources.logsrc.shell = /bin/sh -c
agent1.sources.logsrc.batchSize = 50
agent1.sources.logsrc.channels = memcnl
# Each sink's type must be defined
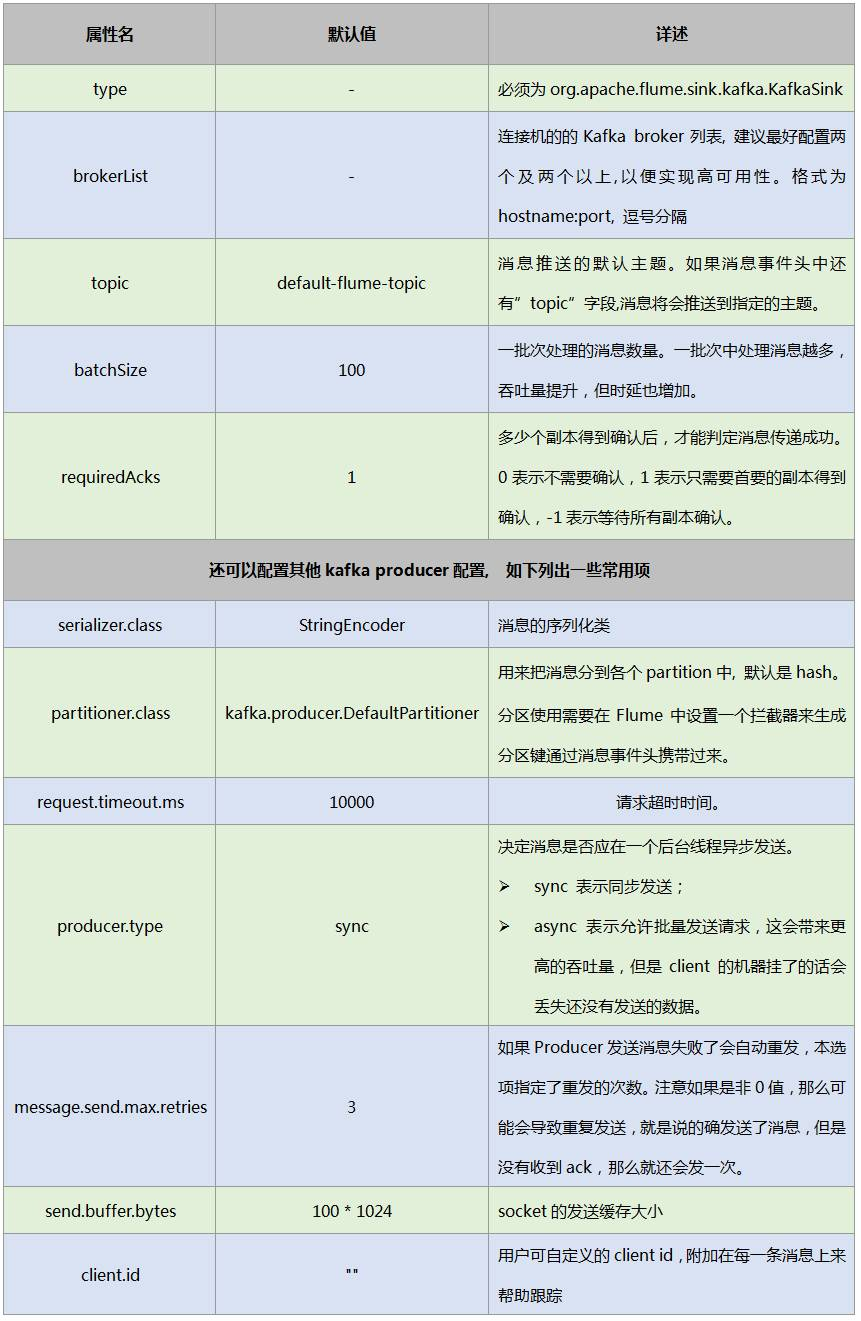
agent1.sinks.kafkasink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafkasink.brokerList=zdh100:9092, zdh101:9092,zdh102:9092
agent1.sinks.kafkasink.topic=mytopic
agent1.sinks.kafkasink.requiredAcks = 1
agent1.sinks.kafkasink.batchSize = 20
agent1.sinks.kafkasink.channel = memcnl
# Each channel's type is defined.
agent1.channels.memcnl.type = memory
agent1.channels.memcnl.capacity = 1000启动该Flume节点:
/home/mr/flume/bin/flume-ng agent -c
/home/mr/flume/conf -f /home/mr/flume/conf/flume-conf.properties -n agent1 -Dflume.monitoring.type=http -Dflume.monitoring.port=10100动态追加日志数据,执行命令向 /data1/logs/component_role.log 添加数据:
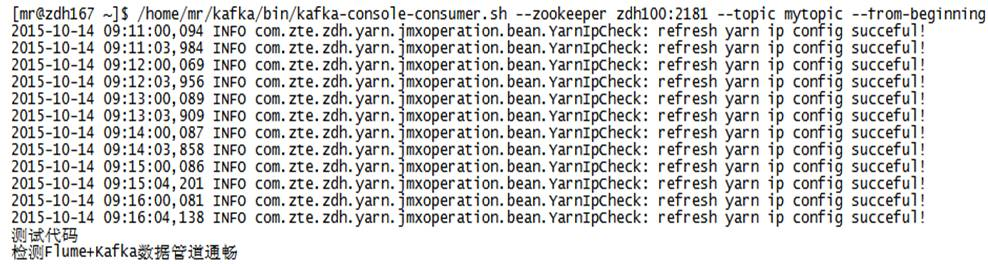
echo "测试代码" >> /data1/logs/component_role.log
echo "检测Flume+Kafka数据管道通畅" >> /data1/logs/component_role.log验证Kafka数据接收结果,执行命令检查Kafka收到的数据是否正确,应该可以呈现刚才追加的数据:
/home/mr/kafka/bin/kafka-console-consumer.sh --zookeeper zdh100:2181 --topic mytopic --from-beginning输出结果如下:
此文章来源网络,因未找到来源,如有侵权,请联系浪尖微信(langjianliaodashuju)删除。