
分布式任务调度:你知道和不知道的事


导语
对于定时任务大家应该都不会陌生,从骨灰级别的Crontab到Spring Task,从QuartZ到xxl-job,随着业务场景越来越多样复杂,定时任务框架也在不断的升级进化。
那么今天就来跟大家从以下三个方面聊一聊分布式任务调度:从单机定时任务到分布式任务调度平台的演进过程、腾讯云分布式任务调度平台TCT是如何应运而生的、TCT具体落地案例情况和解决了哪些核心问题。
作者简介
崔凯
腾讯云 CSIG 微服务产品中心产品架构师
多年分布式、高并发电子商务系统的研发、系统架构设计经验,擅长主流微服务架构技术平台的落地和实施。
目前专注于微服务架构相关中间件的研究推广和最佳实践的沉淀,致力于帮助企业完成数字化转型。

场景类型
定时任务的场景千千万,但它的本质模型是个啥,怎么来理解定时任务呢,此处好有一比。
定时任务其实就是老师给学生布置作业,比如:
每天晚上7点准时开始写作业,写完了让家长检查签字。
“每天晚上7点准时”是对时间精度和周期性的要求,是7点不是8点,是每天不是每周;“写作业”是对任务执行内容的明确,是写作业不是看奥特曼;“写完了让家长检查签字”使得“写作业”和“家长检查签字”可以解耦为两个逻辑动作,在孩子写作业的时候家长还能看个看书啥的。
言归正传,定时任务的典型落地场景在各行业中非常普遍:电商中定时开启促销活动入口、15天未确认收货则自动确认收货、定点扫描未付款订单进行短信提醒等;金融保险行业中也有营销人员佣金计算、终端营销报表制作、组织关系定时同步、日清月清结算等场景。总结下来,笔者按照“时间驱动、批量处理、异步解耦”三个维度来划分定时任务的场景类型。
时间驱动型
以电商场景中定时开启活动入口为例,一般情况会在后台配置好活动需要的各种参数,同时将活动状态的动态配置设置为关闭,当到达执行时间后定时任务自动触发后开启促销活动。
可见,在时间驱动型场景中,相比执行内容而言,业务更关注的是任务是定时执行还是周期执行、执行具体时间点准确性、周期频率的长短等时间因素。
批量处理型
批量处理型任务的特点在于需要`同时对大量`积累的业务对象进行处理。此时,可能有的朋友会问,为什么不使用消息队列处理?原因是某些特定的场景下,消息队列并不能够进行简单替代,因为消息队列更多的是通过每个消息进行事件驱动,偏向更实时的处理。
以保险中佣金结算业务说明,比如营销人员的佣金计算。营销人员会从投保人缴纳的保费中获得一定比例的提成,并且这个比例会根据投保年限、险种的不同而变化,另外可能还会叠加公司的一些佣金激励政策等。这样的场景就需要积累一定量的数据之后,定时的进行批量计算,而不能每个事件都进行计算。
异步解耦型

说到系统的异步解耦一定又会想到消息队列,但消息队列并不能适用某些外部系统数据的获取,比如证券行业中股票软件公司对于交易所股票价格的抓取,由于股票价格对于股票软件公司是外部数据,使用消息队列是很难进行内外部系统间异步通讯的。所以,一般情况会通过批处理任务定时抓取数据并存储,然后后端系统再对数据进行分析整理,使得外部数据获取和内部数据分析处理两部分逻辑解耦。
前世今生
单机定时任务
单机定时任务是最常见的,也是比较传统的任务执行方式,比如linux内置的Crontab。其通过cron表达式中分、时、日、月、周五种时间维度,实现单机定时任务的执行。
# 每晚的21:30重启smb30 21 * * * /etc/init.d/smb restart
另外,在java中也有内置的定时任务,比如java.util.Timer类和它的升级版ScheduledThreadPoolExecutor,另外在Spring体系中也提供了Spring Task这种通过注解快速实现支持cron表达式的单机定时任务框架。
public class ScheduledConsumerDemo {private String echoUrl;/*** 间隔1秒请求provider的echo接口** @throws InterruptedException*/public void callProviderPer1Sec() throws InterruptedException {String response = restTemplate.getForObject(echoUrl, String.class);}}
显而易见的,单机定时任务在应对简单的业务场景是很方便的,但在分布式架构已然成为趋势的现在,单机定时任务并不能满足企业级生产以及工业化场景的诉求,主要体现在集群任务配置统一管理、单点故障及单点性能、节点间任务的通讯及协调、任务执行数据汇总等方面。为了满足企业级生产的诉求,各类任务调度平台逐步兴起。
中心化调度
典型的中心化调度框架quartz,其作为任务调度界的前辈和带头大哥,通过优秀的调度能力、丰富的API接口、Spring集成性好等优点,使其一度成为任务调度的代名词。
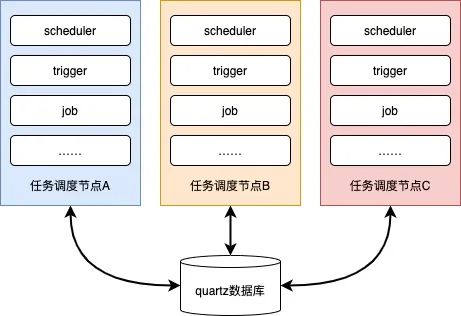
quartz架构中使用数据库锁保障多节点任务执行时的唯一性,解决了单点故障的问题。但数据库锁的集中性也产生了严重的性能问题,比如大批量任务场景下,数据库成为了业务整体调度的性能瓶颈,同时在应用侧还会造成部分资源的等待闲置,另外还做不到任务的并行分片。
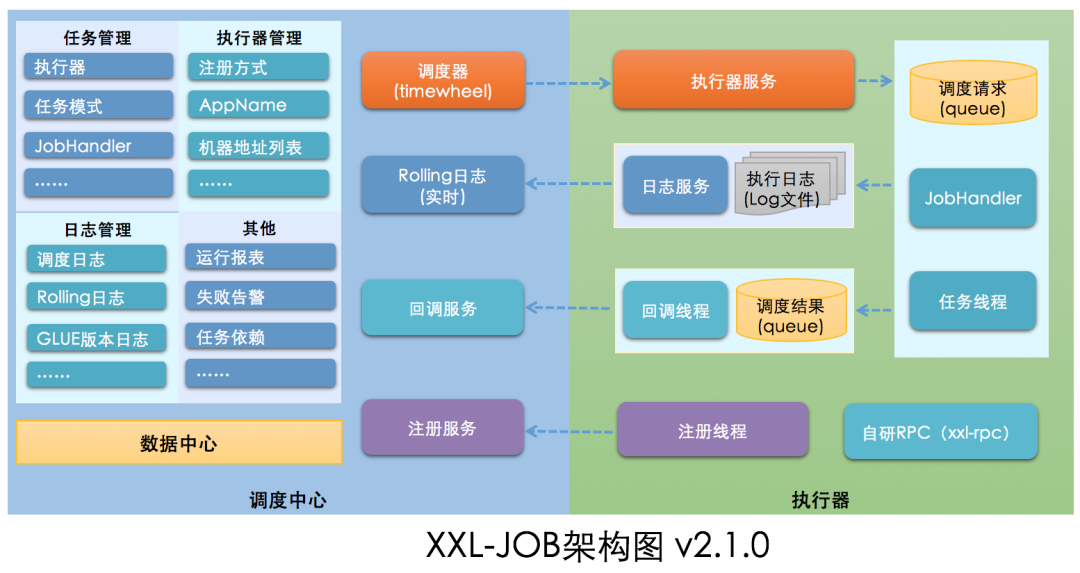
另一款出自大众点评的框架xxl-job,主要特点在于简单、易集成、有可视化控制台,相比quartz主要差异在于:
自研调度模块:xxl-job将调度模块和任务模块解耦的异步化设计,解决了调度任务逻辑偏重时,调度系统性能大大降低的问题。其中,调度模块主要负责任务参数的解析及调用发起,任务模块则负责任务内容的执行,同时异步调度队列和异步执行队列的优化,使得有限的线程资源也可支撑一定量的job并发。
调度优化:通过调度线程池、并行调度的方式,极大减小了调度阻塞的概率,同时提高了调度系统的承载量。
高可用保障:调度中心的数据库中会保存任务信息、调度历史、调度日志、节点注册信息等,通过MySQL保证数据的持久化和高可用。任务节点的故障转移(failover)模式和心跳检测,也会动态感知每个执行节点的状态。
但由于xxl-job使用了跟quartz类似的数据库锁机制,所以同样不能避免数据库成为性能瓶颈以及中心化带来的其它问题。
去中心化调度
为了解决中心化调度存在的各种问题,国内开源框架也是八仙过海、尽显神通,比如口碑还不错的powerjob、当当的elastic-job、唯品会的saturn。saturn整体上是基于开源的elastic-job进行改进优化的,所以本文只针对powerjob和elastic-job做简要介绍。
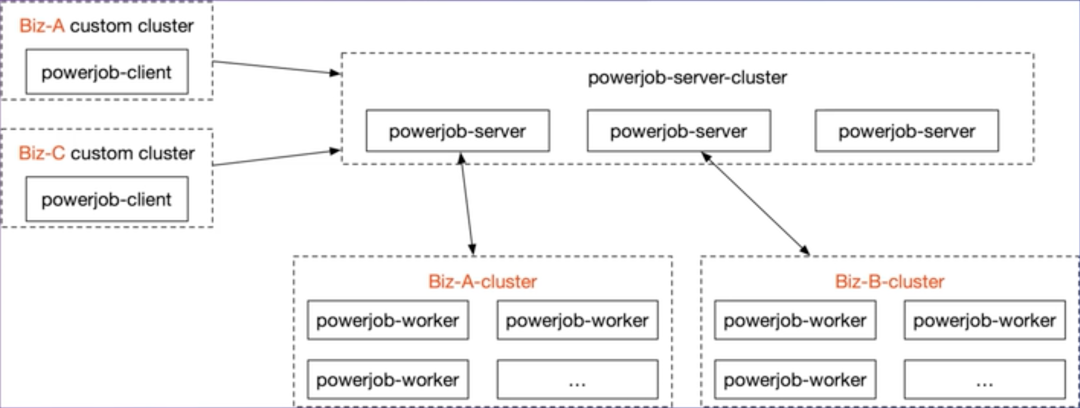
powerjob诞生于2020年4月,其中包含了一些比较新的思路和元素,比如支持基于MapReduce的分布式计算、动态热加载Spring容器等。在功能上,多任务工作流编排、MapReduce执行模式、延迟执行是亮点,同时宣称所有组件都支持水平扩展,其核心组件说明如下:
powerjob-server:调度中心,统一部署,负责任务调度和管理;
powerjob-worker:执行器,提供单机执行、广播执行和分布式计算;
powerjob-client:可选组件,OpenAPI客户端。
powerjob在解决中心化调度时的无锁调度设计思路值得借鉴,核心逻辑是通过appName作为业务应用分组的key,将powerjob-server和powerjob-worker以分组key进行逻辑绑定,即确保每个powerjob-worker集群在运行时只会连接到一台powerjob-server,这样就不需要锁机制来防止任务被多台server同时拿到,从而造成重复执行的问题。
虽然powerjob在各方面分析下来相对优秀,但毕竟产品迭代周期比较短,仍需要通过市场大规模应用来不断打磨产品细节,以验证产品的性能、易用性和稳定性。
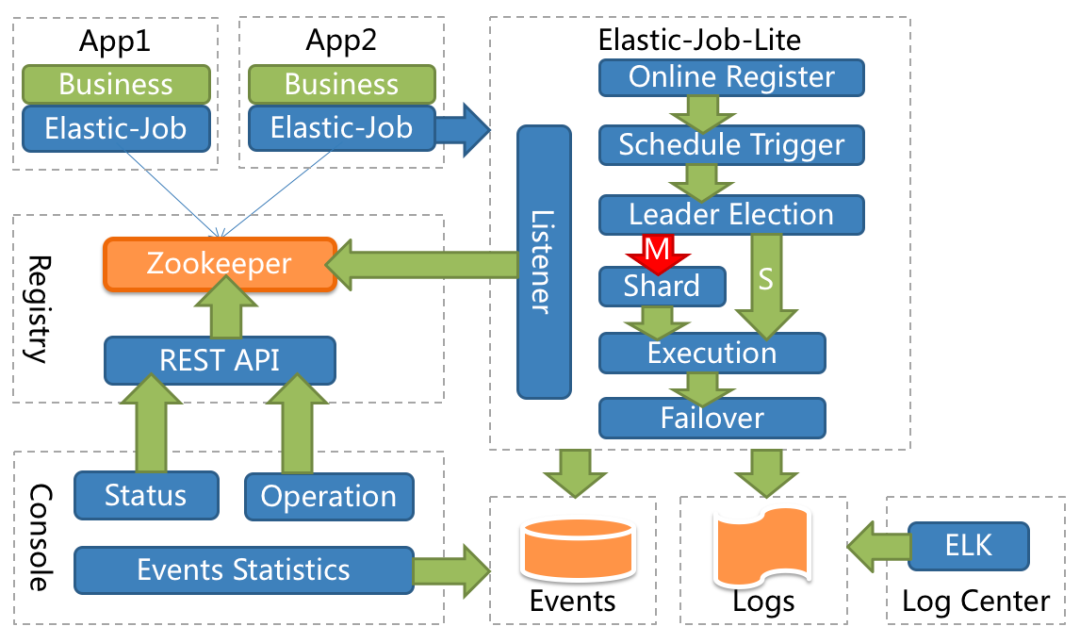
elasticjob包含elasticjob-lite和elasticjob-cloud两个独立子项目,本文主要以elasticjob-lite为例展开。
elasticjob-lite定位为轻量级无中心化解决方案,在继承quartz的基础上,同时使用了zookeeper作为注册中心。在产品设计层面上,个人理解elasticjob相比其他分布式任务调度框架,更加侧重数据处理和计算,主要体现在如下两方面:
elasticjob-lite的无中心化:
没有调度中心的设计,在业务程序引入elasticjob的jar包后,由jar包进行任务的调度、状态通讯、日志落盘等操作。
每个任务节点间都是对等的,会在zookeeper中注册任务相关的信息(任务名称、对等实例列表、执行策略等),同时依赖zookeeper的选举机制进行执行实例的选举。
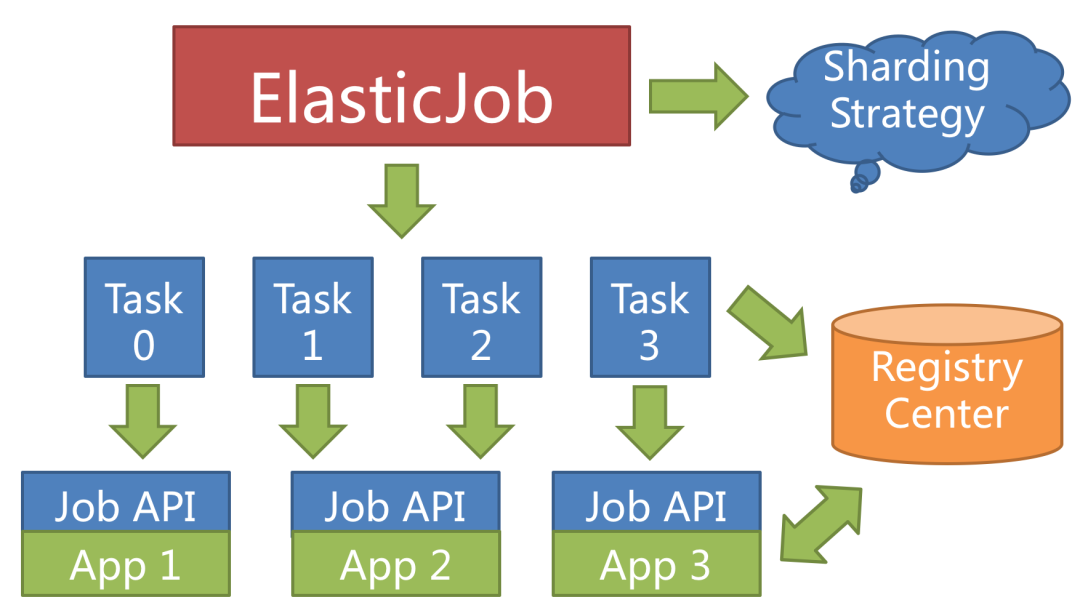
elasticjob-lite的弹性分片:
基于zookeeper,任务执行实例之间可以近乎实时的感知到对方的上下线状态,使得任务分片的分配可以随着任务实例数量的调整而调整,并且保证负载相对均匀。
在任务实例上下线时,并不会影响当前的任务,会在下次任务调度的时候重新分片,以避免任务的重复执行。
通过上述分析,elasticjob更多的是针对分布式任务计算场景设计,更适合做大量数据的分片计算或处理,尤其对资源利用率有要求的场景下更有优势。
演进过程
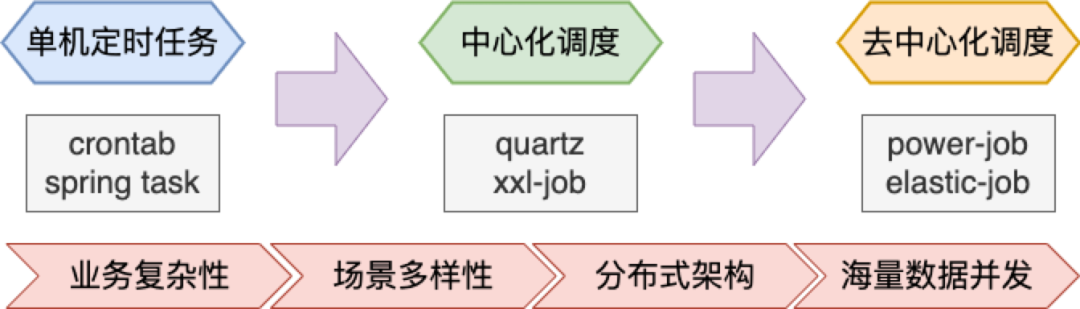
在粗略的介绍了各个主流的分布式任务调度框架后,一个问题出现了:是哪些主要因素推动了框架一步步发展演进?笔者简要概括为如下4个因素:
业务复杂性:原先的业务复杂性低,2、3行代码就可以搞定;随着业务复杂性提高,任务的组织形态和执行内容都发生了很大变化,逐步衍生出任务编排、框架生态融合、多语言及多终端支持等诉求。
场景多样性:不再仅仅是简单的定时任务执行,类似批量计算、业务解耦等场景的问题,也逐步开始使用分布式任务调度框架解决。对框架能力的要求在于,更丰富的任务执行策略、动态分片计算的支持、丰富的任务治理能力等方面上。
分布式架构:分布式架构趋势的全面到来,是最重要的推进因素。框架的整体设计须以分布式架构为前提,在任务节点及调度中心间的通讯、调度平台的高可用、任务节点的故障处理及恢复、任务调度可视化运维等方面,都是全新的挑战。
海量数据并发:当海量的业务数据及并发调用成为常态,就使得分布式任务调度平台需要在执行器性能、执行时间精准度、任务的并行及异步处理、节点资源弹性管控等方面推进优化,以帮助提升平台整体的吞吐量。
分布式任务调度框架的演进,是业务系统从单体架构向分布式架构演进的一个分支。分布式任务调度平台能力的不断完善,与业务架构的微服务化演进不可分割。
同理,目前各行业的业务系统逐步迁移上云,企业数字化转型趋势明显,未来分布式任务调度平台的演进过程同样离不开云原生产业环境,平台的整体架构需要深度融合云原生体系,才能满足未来多方面不断变化的产业诉求。
“云上”的TCT
分布式任务调度服务(Tencent Cloud Task)是腾讯云自主研发的一款轻量级、高可靠的分布式任务调度平台。通过指定时间规则,严格触发调度任务,保障调度任务的可靠、有序执行。该服务支持国际通用的时间表达式、执行生命周期管理,解决传统定时调度任务的单点故障及可视化程度低等问题。同时,支持任务分片、工作流编排等复杂调度任务处理能力,覆盖广泛的任务调度应用场景,如数据备份、日志切分、运维监控、金融日切等。
功能介绍
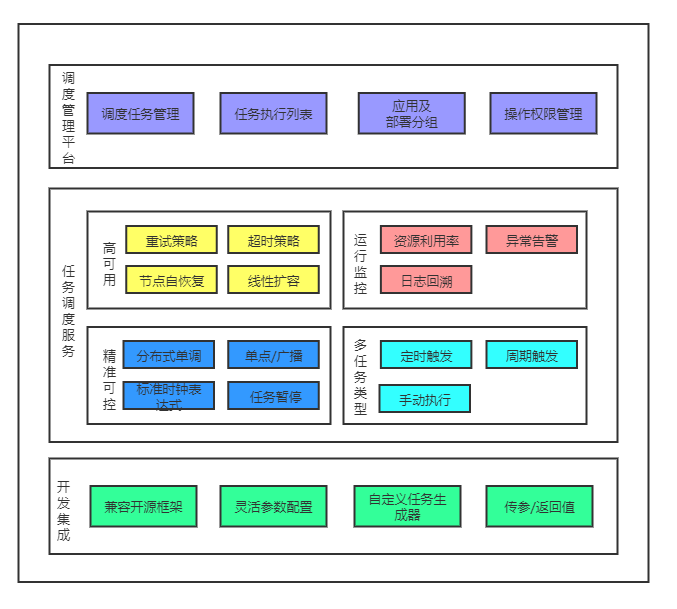
TCT在功能方面主要分为三个部分:调度管理平台、任务调度服务、开发集成(SDK)。调度管理平台提供优雅的可视化界面交互,任务调度服务实现分布式场景下的任务调度,开发集成深度融合开源框架,其中详细功能特点说明如下
丰富的任务配置
多种执行方式:支持随机节点、广播、分片执行方式,满足不同应用场景。
多种触发策略:支持定时触发、周期触发、工作流触发、人工手动触发策略。
完善的容错机制:支持异常重试、超时中断、手动停止等多种任务容错保护机制。
可视化的任务管理
任务管理视图:展示任务的执行状态,提供新增任务、编辑任务、删除任务、手动执行、启动/停用任务等操作能力。
执行记录视图:展示所有常规任务、工作流任务的执行批次详情列表,支持依据所属任务、部署组为查询过滤条件。
执行列表视图:展示选定任务的执行批次详情列表,支持针对任务批次的停止、重新执行操作。
执行详情视图:展示任务执行批次的执行实例列表,支持针对执行实例的停止、重新执行、日志查询操作。
工作流管理视图:展示工作流任务的执行状态,提供工作流任务新建、可视化流程编排、启动/停用工作流任务等操作能力。
完善的任务运行监控告警
立体化监控:提供任务运行状态、任务执行批次状态、执行实例运行状态的立体化监控,支持针对执行实例的线上日志查看能力。
灵活告警策略:集成云监控能力提供任务执行批次、执行实例异常告警,工作流任务执行批次、批次任务、执行实例异常告警能力,支持灵活的指标告警及事件告警配置。
架构原理
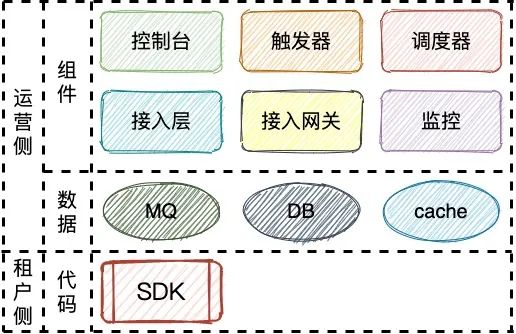
TCT各组件简介如下:
触发器:解析任务的触发规则
调度器:派发需要执行的任务、管理任务状态等
监控:任务执行相关的监控数据上报
控制台:管理员的控制台界面
接入层:任务下发、状态上报等消息的信道管理器
接入网关:统一对接接入层及SDK的网关
SDK:和业务进程运行在一起,负责执行任务中定义的一段具体代码逻辑
首先,由触发器解析用户在控制台配置并存入DB的任务信息,并将解析后的执行信息投入到MQ中。其次,由调度器消费执行信息并通过接入层下发到具体的执行器节点上(接入层中有具体的节点注册信息,包括IP地址等)。最后,当SDK所在节点完成任务的执行后(成功、失败、未响应等),会将执行结果通过TCP长连接传回给调度器,然后调度器会跟DB进行交互完成任务状态的变更,同时上报任务执行情况到监控模块。
通过功能简介可以发现TCT基本涵盖了常见的任务调度场景中所需功能,尤其在可视化视图方面做了大量的工作,同时依托腾讯云完备的基础设施建设,在高可用保障和减少运维成本方面也提供了极大保障。此外,TCT源于TSF技术平台,对TSF应用天然集成,支撑组件可以很方便的获取TSF应用的相关信息,如TSF部署组ID、节点IP、应用ID等,因此在任务执行效率上也会更高。
不过,由整体架构图发现TCT采用中心化调度方案,调度器、触发器及控制台组件无状态,支持水平扩展,组件及SDK间通过TCP长连接通讯;而数据流依赖DB及MQ,在任务数量大、执行频率高的大规模落地场景下,DB和MQ的吞吐量就会成为性能卡点,即使可以优化也会有明显上限。所以根据目前TCT的产品形态,其更多的适用于轻量级任务调度场景。
分片执行案例
背景概述
分片执行模式是大批量数据处理场景下经常用到的执行方式,本案例以保险行业中子公司每天向总公司汇总当天营销数据的业务场景为例进行说明。

从上图可见,汇总营销数据的服务(后文称summarydata)每天凌晨2:00定时调用34个子公司提供的营销数据查询API。之所以使用分片执行方式,是因为汇总营销数据的操作需要在同一时间触发,且整体汇总时间越短越准确。此外,各公司的营销数据量并不相同,而且即使是相同的子公司每天产生的营销数据量也不相同。
配置步骤
根据如上业务背景描述,同时基于现有资源情况,整体配置思路为:
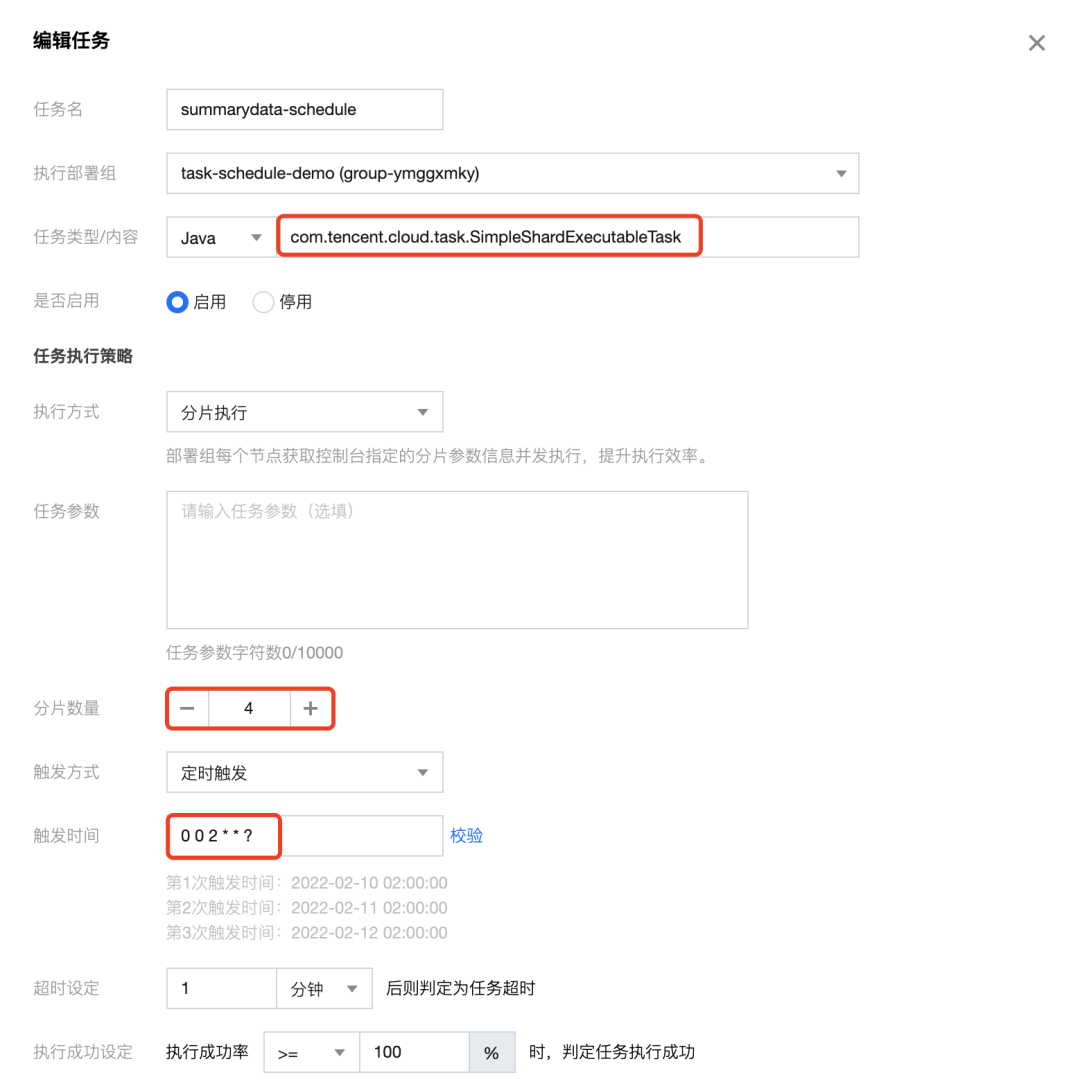
创建一个summarydata部署组,其中新建4个实例,单个实例线程池数量为3;
应用代码中将34个子公司一一对应到1~34的公司ID上;
根据大致地域和日均产生的数据量,将34家公司划分到NORTH、SOUTH、EAST、WEST四个区域;
分片数量为4,每个分片对应到1个实例,即1个实例至少计算1个区域的数据;
每个区域key对应的子公司ID列表可通过代码配置进行半自动调整,防止某个子公司数据量陡增情况;
为防止统计重复,不配置任务自动重试,采用手动补偿。
步骤一:触发类代码编写并打包
javapublic class SimpleShardExecutableTask implements ExecutableTask {private final static Logger LOG = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Overridepublic ProcessResult execute(ExecutableTaskData executableTaskData) {// 输出任务执行元数据TaskExecuteMeta executeMeta = executableTaskData.getTaskMeta();LOG.info("executeMetaJson:{}",executeMeta.toString());// 输出分配给本实例的分片参数ShardingArgs shardingArgs = executableTaskData.getShardingArgs();LOG.info("ShardCount: {}", shardingArgs.getShardCount());Integer shardingKey = shardingArgs.getShardKey();LOG.info("shardingKey: {}", shardingKey);String shardingValue = shardingArgs.getShardValue();LOG.info("shardingValue: {}", shardingValue);// 模拟任务执行try {this.doProcess(shardingValue);} catch (Exception e) {e.printStackTrace();}return ProcessResult.newSuccessResult();}public void doProcess(String shardingValue) throws Exception {if (shardingValue.equals(CompanyMap.NORTH.area)){Arrays.stream(CompanyMap.NORTH.companyIds).forEach(companyId->LOG.info("calling north subsidiary_{} api.....",companyId));} else if(shardingValue.equals(CompanyMap.SOUTH.area)){Arrays.stream(CompanyMap.SOUTH.companyIds).forEach(companyId->LOG.info("calling south subsidiary_{} api.....",companyId));} else if(shardingValue.equals(CompanyMap.EAST.area)){Arrays.stream(CompanyMap.EAST.companyIds).forEach(companyId->LOG.info("calling east subsidiary_{} api.....",companyId));} else if(shardingValue.equals(CompanyMap.WEST.area)){Arrays.stream(CompanyMap.WEST.companyIds).forEach(companyId->LOG.info("calling west subsidiary_{} api.....",companyId));} else {throw new Exception("input shardingValue error!");}ThreadUtils.waitMs(3000L);}enum CompanyMap{NORTH("NORTH", new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9}),SOUTH("SOUTH",new int[]{10,11,12,13,14,15,16,17,18,19}),EAST("EAST",new int[]{20,21,22,23,24,25,26,27,28}),WEST("WEST",new int[]{29,30,31,32,33,34});private String area;private int[] companyIds;CompanyMap(String key,int[] values){this.area = key;this.companyIds = values;}public String getArea() { return area; }public void setArea(String area) { this.area = area; }public int[] getCompanyIds() { return companyIds; }public void setCompanyIds(int[] companyIds) { this.companyIds = companyIds; }}}
步骤二:创建应用及部署组,并完成部署
步骤三:创建TCT任务

步骤四:手动启动任务测试

测试效果
通过控制台查看实例执行情况,同时可通过分片参数按钮,查询某个实例执行批次内的分片参数。
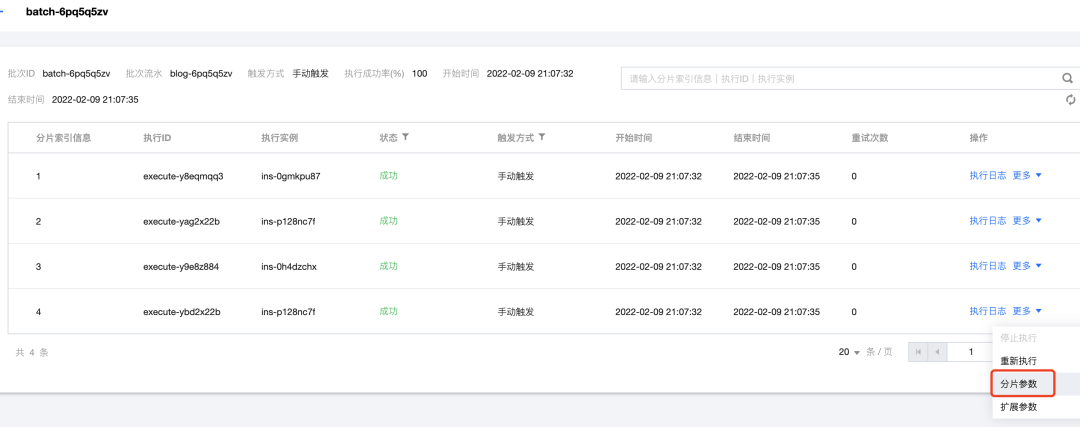
通过应用日志查看结果,可发现有1个实例运行了2个分片任务,是由于TCT对实例负载情况进行了判断,选择了相对空闲的实例。
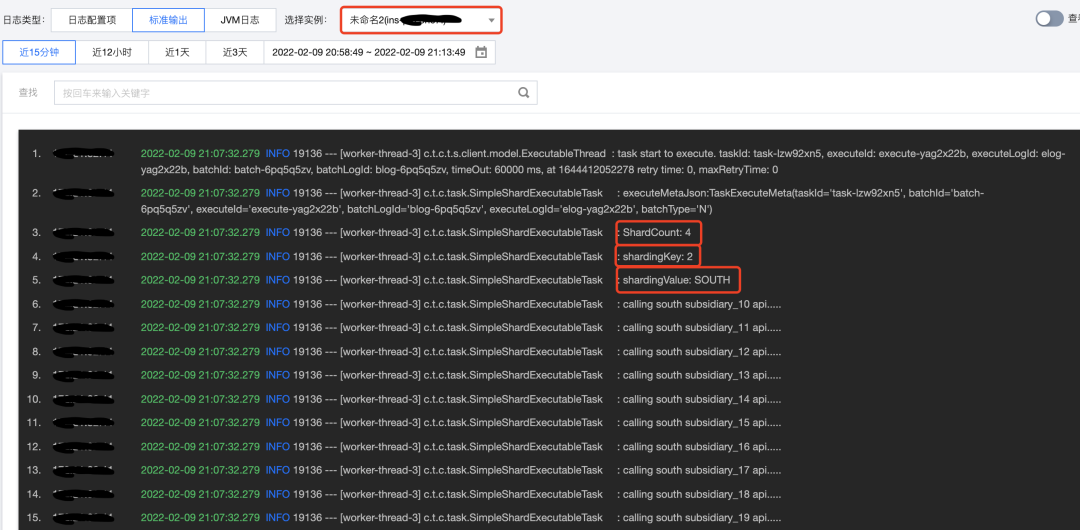
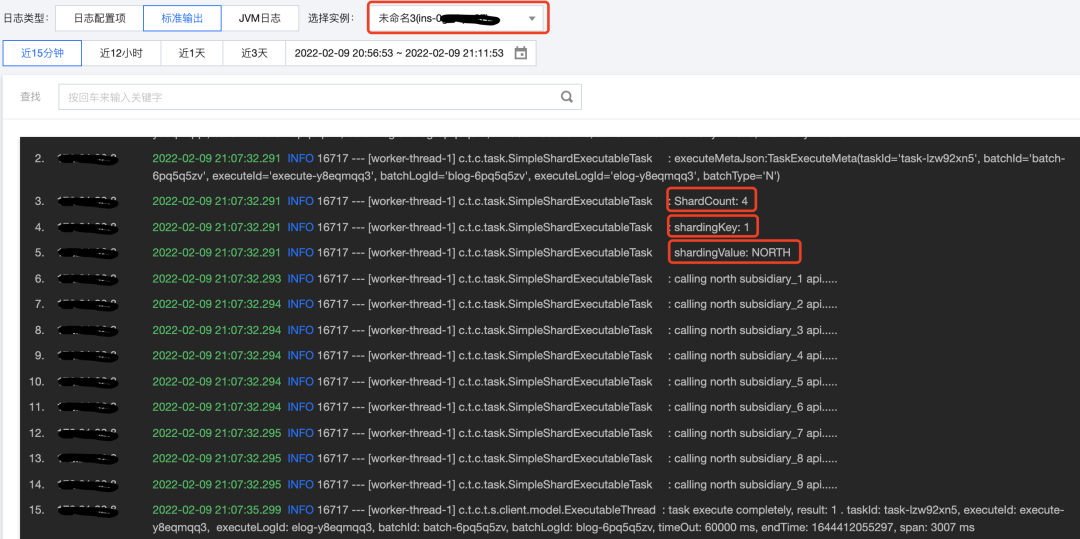
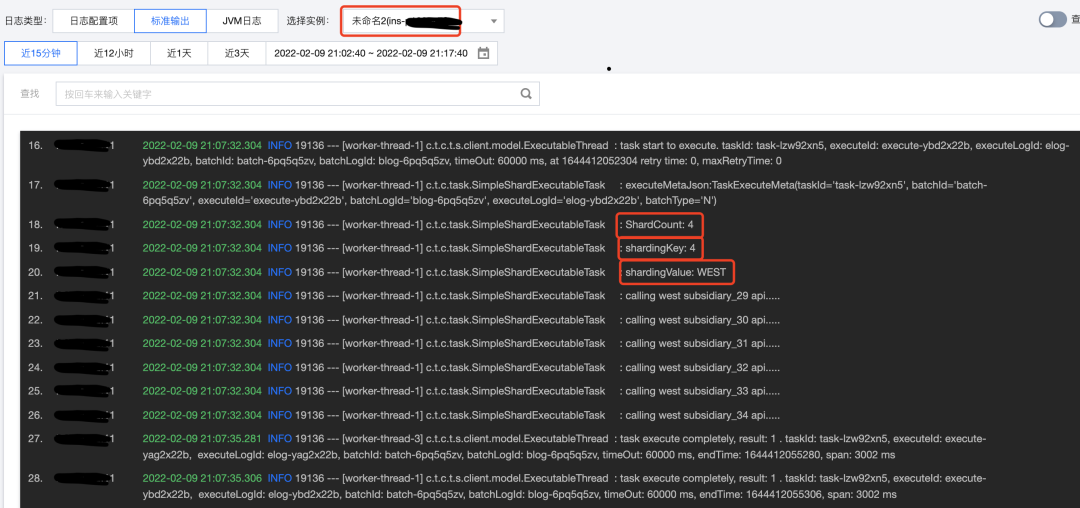
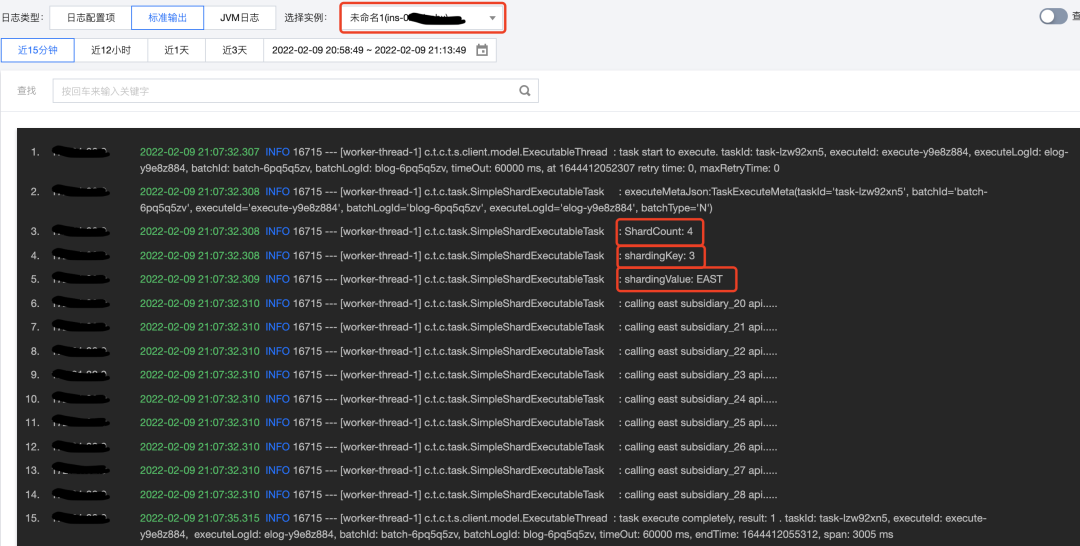
此外还进行了服务内实例异常的测试,即当summarydata服务中4个实例仅余1个实例正常时任务的执行情况(由于日志较长,笔者节选了重要部分)。可以看到前3个分片任务是同时且使用不同线程执行的,第4个分片任务是在前3个任务执行完成后再执行的,符合预期。

未来方向
分布式任务调度平台框架间的竞争过程漫长而胶着,各家厂商都在寻求产品价值上的突破口,TCT也仍有很多不足,需要从市场需求和技术趋势的角度持续深度思考。针对分布式任务调度市场,笔者粗略总结了如下几点未来产品可能的优化方向:
1.去中心化
中心化的分布式任务调度平台缺点明显,难以支撑企业大规模落地场景。同时,市场中的产品及技术演进趋势逐渐向去中心化发展,原因在于去中心化的分布式任务调度平台才具有大规模商业化落地的可能,成功的商业化落地案例也是产品走向成熟的标志。
2. 容器化
分布式任务调度平台组件及组件间通讯目前多为传统虚机方式,如果能同时实现支撑组件的容器化部署,就可以更好的发挥容器平台快速启停、资源调度、水平扩展等方面的优势,以提高支撑侧整体可用性,减少扩缩容时的运维成本,有效提升平台整体的吞吐量,而高可用、弹性扩缩、高性能是大型企业数字化转型云原生的重要考量因素。
3. 可编程
越来越多的分布式任务场景需要针对多个任务做复杂的任务编排,目前主流的编排仍局限于任务间串行、并行、与或等简单的逻辑处理。未来更多的需要一种通用的、可编程的模板语言,用于描述任务参数及内容、DAGS(有向无环图)、操作符、触发动作等,标准化各家厂商对于任务编排的定义方式。
4. 容错补偿
在任务及工作流执行异常时的处理策略也有很多方面需要完善,比如由于实例夯死导致的过时触发问题、任务追赶和任务堆积问题、工作流场景下任务异常后是整体重试还是断点续传重试等。
5. 场景升级
目前各家产品在常见的定时任务场景中,功能同质化程度比较高。但随着云原生、大数据等相关领域的快速发展,分布式任务调度平台也逐渐产生了新的应用场景,如大数据场景下的分布式计算及计算汇总、调度平台对接serverless应用等,这都对产品的场景和功能提出更高的要求。
尾声
通过对定时任务的场景、演进历史、各平台框架的介绍以及腾讯云自研分布式任务调度框架TCT的实践案例描述,笔者继前人的基础上对分布式任务调度框架的应用现状和未来发展进行了简要分析,之前知道的和不知道的现在读者朋友应该都知道了。谨希望本文能在技术选型及开源建设方面提供些许思路和视角,供企业和开源社区参考。
往期
推荐
《云原生时代的Java应用优化实践》
《全面兼容Eureka:PolarisMesh(北极星)发布1.5.0版本》
《全面拥抱Go社区:PolarisMesh全功能对接gRPC-Go | PolarisMesh12月月报》
《SpringBoot应用优雅接入北极星PolarisMesh》
《Serverless可观测性的价值》
《RoP重磅发布0.2.0版本:架构全新升级,消息准确性达100%》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!


点个在看你最好看