
综述:神经网络中 Normalization 的发展历程

极市导读
本篇文章用于总结近年来神经网络中 Normalization 操作的发展历程。其中,包括:Local Response Normalization, Batch Normalization, Weight Normalization, Layer Normalization, Instance Normalization, Consine Normalization, Group Normalization。>>明日直播!田值:实例分割创新式突破BoxInst,仅用Box标注,实现COCO 33.2AP!
Local Response Normalization
Batch Normalization
Weight Normalization
Layer Normalization
Instance Normalization
Consine Normalization
Group Normalization
1. Local Response Normalization
LRN 最早应该是出现在 2012 年的 AlexNet 中的,其主要思想是:借鉴“侧抑制”(Lateral Inhibitio)的思想实现局部神经元抑制,即使得局部的神经元产生竞争机制,使其中相应值较大的将变得更大,响应值较小的将变得更小。此外,作者在论文中指出使用 LRN 能减少其 AlexNet 在 ILSVRC-2012 上的 top-1 错误率 1.4% 和 top-5 错误率 1.2%,效果较为显著。
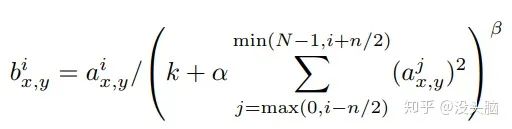
其中,  表示输入中第
表示输入中第  个 FeatureMap 中位于
个 FeatureMap 中位于  的响应值,
的响应值,  表示输出中第 个 FeatureMap 中位于 的响应值,
表示输出中第 个 FeatureMap 中位于 的响应值,  都是由验证集所决定的超参数 (Hyper-Parameter)。论文中的设定为:
都是由验证集所决定的超参数 (Hyper-Parameter)。论文中的设定为:  。
。
在 2015 年的 VGG 中,该论文指出 LRN 在 VGG 并无任何用处:

此后,随着 Batch Normalization 等不同 Normalization 的出现,LRN 也开始逐渐落寞。
2. Batch Normalization
BN 应该算是目前使用最多的 Normalization 操作了,现在甚至可以说是 CNN 网络的标配。自 2015 年 2 月的 Inception V2(https://arxiv.org/pdf/1502.03167.pdf) 提出之后,也引出了后续许多不同的 Normalization 的提出。
作者在论文中指出,提出 Batch Normalization 是目的为了解决 ‘internal covariate shift’ 现象(这个应该是属于机器学习的问题,我无法进行详细表达,建议查看其他文章),经过测试后,发现使用 BN 能加速神经网络的收敛速度,并使得神经网络对于初始化的敏感度下降。
在 深度学习中 Batch Normalization为什么效果好?(https://www.zhihu.com/question/38102762/answer/85238569)中,答者指出其实 BN 解决的是梯度消失问题(Gradient Vanishing Problem),我感觉其实有点道理的。)

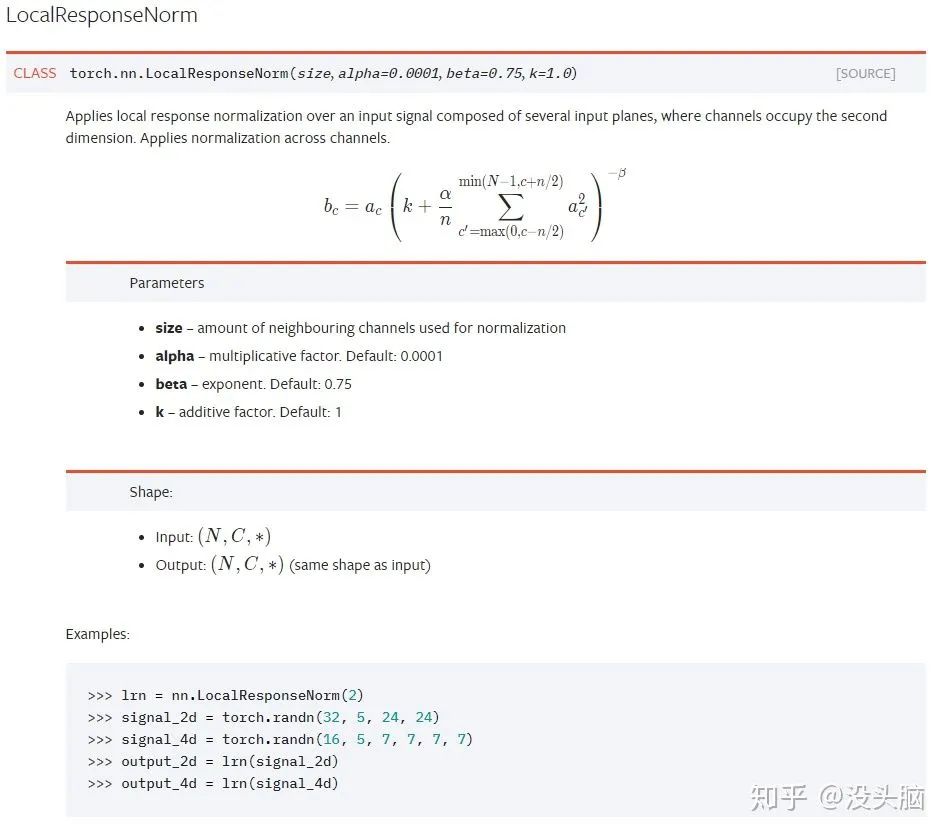
其中,  为输入数据,
为输入数据,  为数据平均值,
为数据平均值,  为数据方差,
为数据方差,  和
和  为学习参数。此外, 和 是统计量,随着 Batch 的迭代不断更新(一般实现都会对其做滑动平均,不然当 Batch Size 较小时,其统计值的波动会很大,导致网络无法收敛的)。
为学习参数。此外, 和 是统计量,随着 Batch 的迭代不断更新(一般实现都会对其做滑动平均,不然当 Batch Size 较小时,其统计值的波动会很大,导致网络无法收敛的)。
在 BN 中,作者之所以加上 和 这两个仿射参数(Affine Parameter),是为了使得经过 BN 处理后的数据仍可以恢复到之前的分布,从而提升了网络结构的 Capacity,即在做出一定的改变的同时,仍保留之前的能力。
此外,除了 BN 背后的原理这一话题外,大家对 Batch-normalized 应该放在非线性激活层的前面还是后面?这一话题的讨论也比较激烈,并没有达成统一的观点,只是大部分实验表明BN 放在非线性激活层后比较好,不过仍需要具体任务具体分析。

注意,在 PyTorch 中冻结 BN Layer,不仅需要对将其参数的 requires_grad 设为 False,还需要将该层的 training 设为 False,即调用 eval 函数;否则,将会导致统计量不断更新,而仿射参数却一直处于冻结状态。此外,一般都会设置 track_running_state 为 True,以减小 Batch Size 所造成的统计量波动。
3. Weight Normalization
在 2016 年 2 月的 Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks (https://arxiv.org/pdf/1602.07868.pdf)中,作者提出了与 BN 完全不同的 Normalization 操作:Weight Normalization,并指出:相较于 BN,WN 摆脱了对于 Batch 的依赖,这意味这 WN 完全可以用在 RNN 网络中(如:LSTM )以及对于噪声敏感的任务(如:强化学习、生成式模型)中;此外,WN 的计算成本低,可以减少模型的运行时间。
与 BN 不同的是, WN 并不是对输入的特征数据进行归一化操作,而是对神经网络中指定的层的参数做归一化操作。
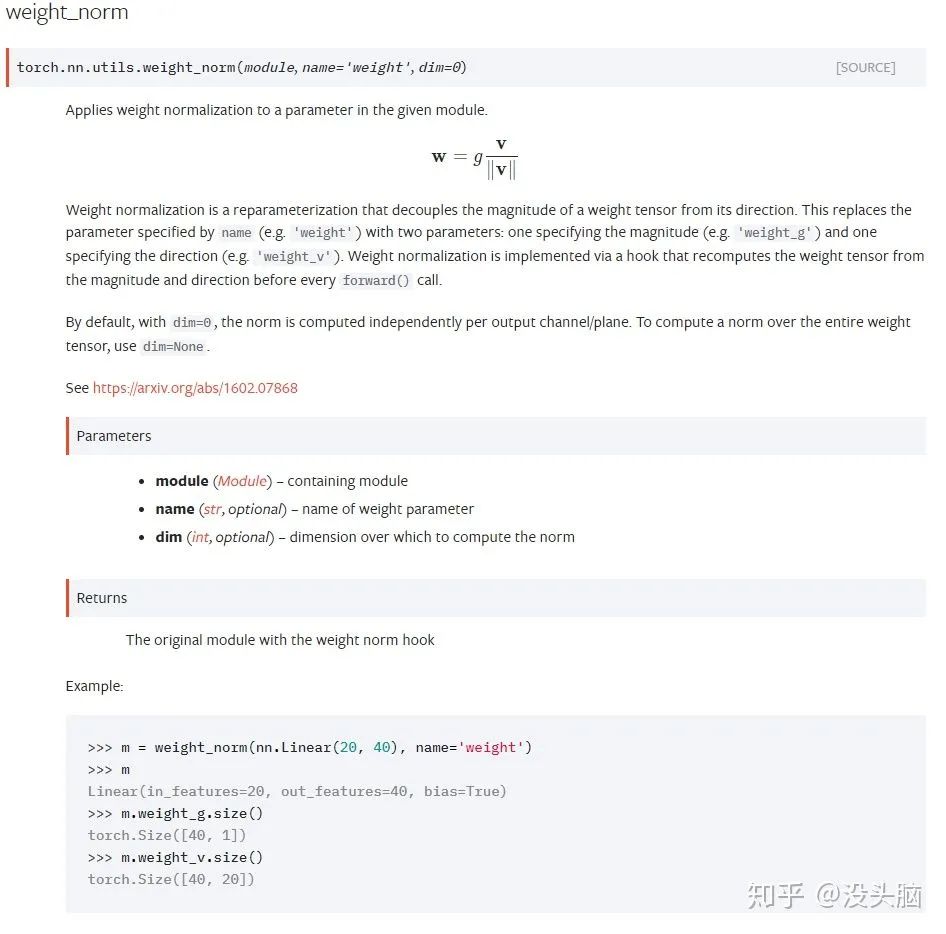
在论文中,作者将神经网络的层表示为  ,其中,
,其中,  为权重向量,
为权重向量,  为偏置参数,
为偏置参数,  为输入向量,
为输入向量,  为非线性激活函数。而 WN 就是对 做归一化,将 分解为
为非线性激活函数。而 WN 就是对 做归一化,将 分解为  。其中,
。其中,  为单位向量,代表 的方向,
为单位向量,代表 的方向,  为标量,代表 的长度,
为标量,代表 的长度,  为
为  的欧式范数。
的欧式范数。

在 详解深度学习中的Normalization,BN/LN/WN https://zhuanlan.zhihu.com/p/33173246中,作者指出:WN 与 BN 其实是相似的。


4. Layer Normalization
在 2016 年 7 月的 Layer Normalization (https://arxiv.org/pdf/1607.06450.pdf)中,作者提出了一种类似与 BN 的操作:Layer Normalization,提出 LN 的主要目的是为了解决 BN 对 Batch Size 和内存的依赖以及减少 Normalization 所需时间。
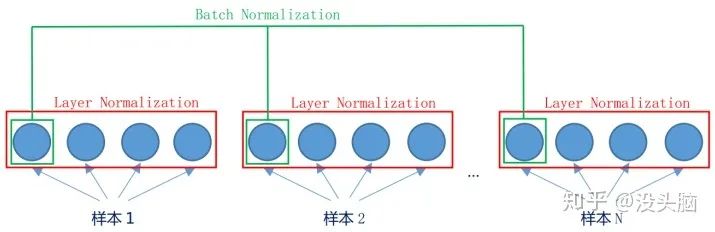
LN 与 BN 的不同之处在于:BN 是对一个 Batch 中的所有样本的不同维度做 Normalization,而 LN 是对单个样本中的所有维度做 Normalization。当然,两者的数学公式长得都一样,都是求平均值、方差,做归一化后在做仿射变换。

举例来说,对于  的数据,BN 计算得到的统计量的
的数据,BN 计算得到的统计量的  为
为  ,而 LN 计算得到的统计量的 为
,而 LN 计算得到的统计量的 为  。
。
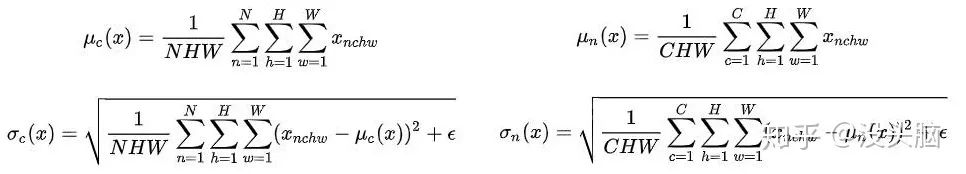
(左侧:Batch Normalization,右侧:Layer Normalization)

5. Instance Normalization
在 2016 年 7 月的 Instance Normalization: The Missing Ingredient for Fast Stylization (https://arxiv.org/pdf/1607.08022.pdf)中,作者提出与 LN 类似的操作:Instance Normalization。在论文中,作者指出在图像风格迁移任务中,生成式模型计算得到的 Feature Map 的各个 Channel 的均值与方差将影响到所生成图像的风格。故,作者提出了 IN,在 Channel 层面对输入数据进行归一化,再使用目标图像的 Channel 的均值与方差对结果进行 '去归一化'。
值得一提的是,IN 与LN 类似,仅对单个样本进行归一化,但是 IN 并不进行仿射变换。
举例来说,对于 的数据,IN 计算得到的统计量的 为  。
。
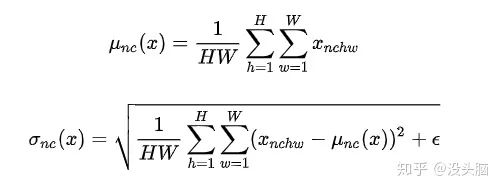

6. Cosine Normalization
在 2017 年 2 月的
Cosine Normalization: Using Cosine Similarity Instead of Dot Product in Neural Networks (https://arxiv.org/pdf/1702.05870.pdf)
中,作者提出了 Cosine Normalization,不对输入数据做归一化,也不对参数做归一化,而是对输入数据与参数的点乘做出改动,改为计算两者的余弦相似度  ,即
,即  变为
变为  。
。
CN 将模型的输出进行了归一化,使得输出有界,但是也因此丢弃了原本输出中所含的 Scale 信息,所以这个是否值得也有待进一步探讨。
7. Group Normalization
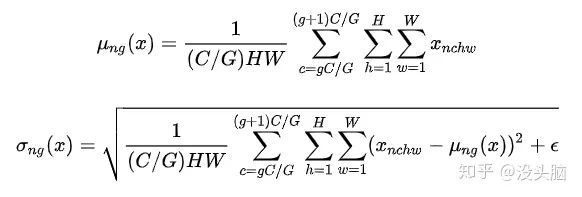
在 2018 年 3 月的 Group Normalization(https://arxiv.org/pdf/1803.08494.pdf)中,作者提出了 Group Normalization,与 BN 相比,GN 的改进有两点:不再依赖 Batch Size,计算成本可由超参数进行调节。
作者在论文中指出,BN 对于 Batch Size 的依赖使得其无法较好的运用在因内存限制而使用较小 Batch Size 的任务上(如:detection, segmentation, video),故作者令 GN 仅对单个样本进行 Normalization 操作。此外,GN 更像是 LN 与 IN 的一般形式,当  时,GN 等价于 LN;当
时,GN 等价于 LN;当  时,GN 等价于 IN。
时,GN 等价于 IN。
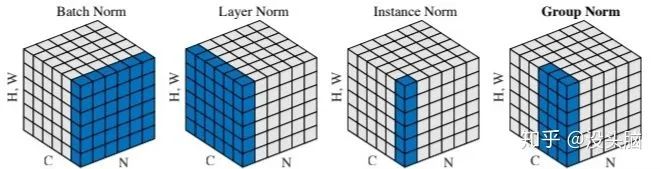
在 如何区分并记住常见的几种 Normalization 算法(https://zhuanlan.zhihu.com/p/69659844) 中,作者给出了一张图像,直观的给出了以上 Normalization 的不同之处:
举例来说,对于 的数据,GN 计算得到的统计量的 为  。
。

推荐阅读
