
跪了,米哈游是真的细节...
共 9869字,需浏览 20分钟
·
2024-04-10 16:03
大家好,我是小林。
今天分享米哈游的校招面经,虽然问的问题不算很多,但是主要是考虑的计算机基础的细节,游戏类的公司都会比较注重性能,所以对于计算机基础方面的内容会考察比较多。
米哈游面试输入URL过程用到哪些协议?
主要会涉及HTTP/HTTPS协议、DNS协议、TCP协议、ARP协议、OPSF协议。
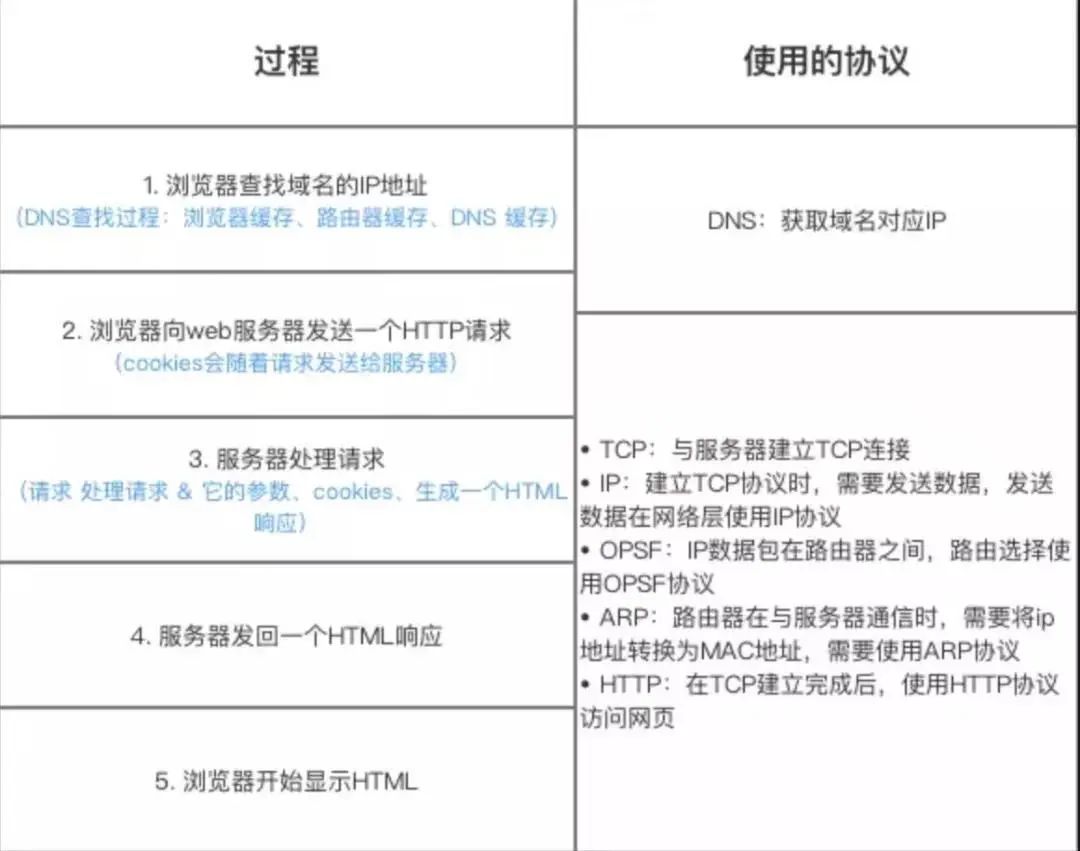
输入URL过程如下:
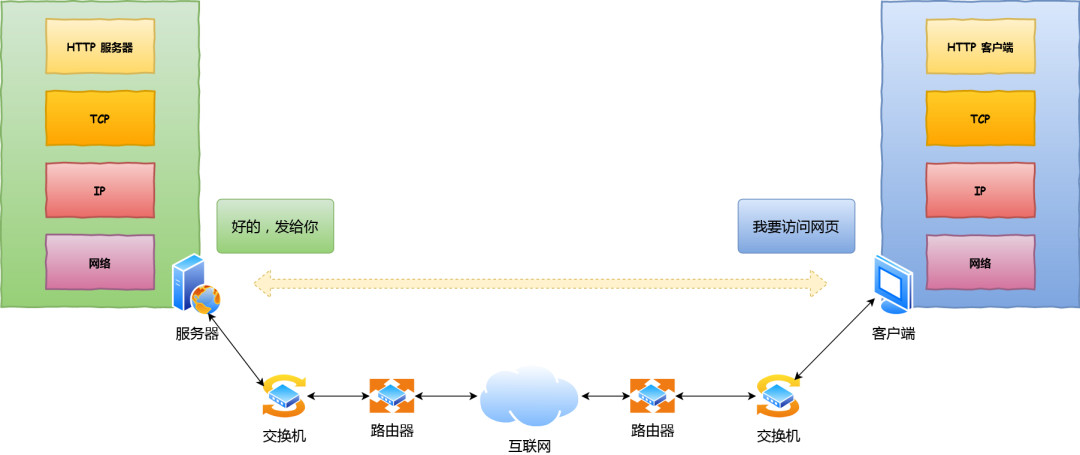
- DNS 解析:当用户输入一个网址并按下回车键的时候,浏览器获得一个域名,而在实际通信过程中,我们需要的是一个 IP 地址,因此我们需要先把域名转换成相应 IP 地址。
- TCP 连接:浏览器通过 DNS 获取到 Web 服务器真正的 IP 地址后,便向 Web 服务器发起 TCP 连接请求,通过 TCP 三次握手建立好连接。
- 建立TCP协议时,需要发送数据,发送数据在网络层使用IP协议, 通过IP协议将IP地址封装为IP数据报;然后此时会用到ARP协议,主机发送信息时将包含目标IP地址的ARP请求广播到网络上的所有主机,并接收返回消息,以此确定目标的物理地址,找到目的MAC地址;
- IP数据包在路由器之间,路由选择使用OPSF协议, 采用Dijkstra算法来计算最短路径树,抵达服务端。
- 发送 HTTP 请求:建立 TCP 连接之后,浏览器向 Web 服务器发起一个 HTTP 请求(如果是HTTPS协议,发送HTTP 请求之前还需要完成TLS四次握手);
- 处理请求并返回:服务器获取到客户端的 HTTP 请求后,会根据 HTTP 请求中的内容来决定如何获取相应的文件,并将文件发送给浏览器。
- 浏览器渲染:浏览器根据响应开始显示页面,首先解析 HTML 文件构建 DOM 树,然后解析 CSS 文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。
TCP中断了怎么办?发送方几个报文都没回复怎么办?
如果TCP意外断开,并没有正常关闭socket,双方并未按照协议上的四次挥手去断开连接。
那么这时候正在执行Recv或Send操作的一方就会因为没有任何连接中断的通知而一直等待下去,也就是会被长时间卡住。
像这种如果一方已经关闭或异常终止连接,而另一方却不知道,我们将这样的TCP连接称为半打开的。
解决意外中断办法都是利用保活机制。而保活机制分又可以让底层实现也可自己实现。
自己编写心跳包程序
在自己的程序中加入一条线程,定时向对端发送数据包,查看是否有ACK,如果有则连接正常,没有的话则连接断开。
比如,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。如果设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完成一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。
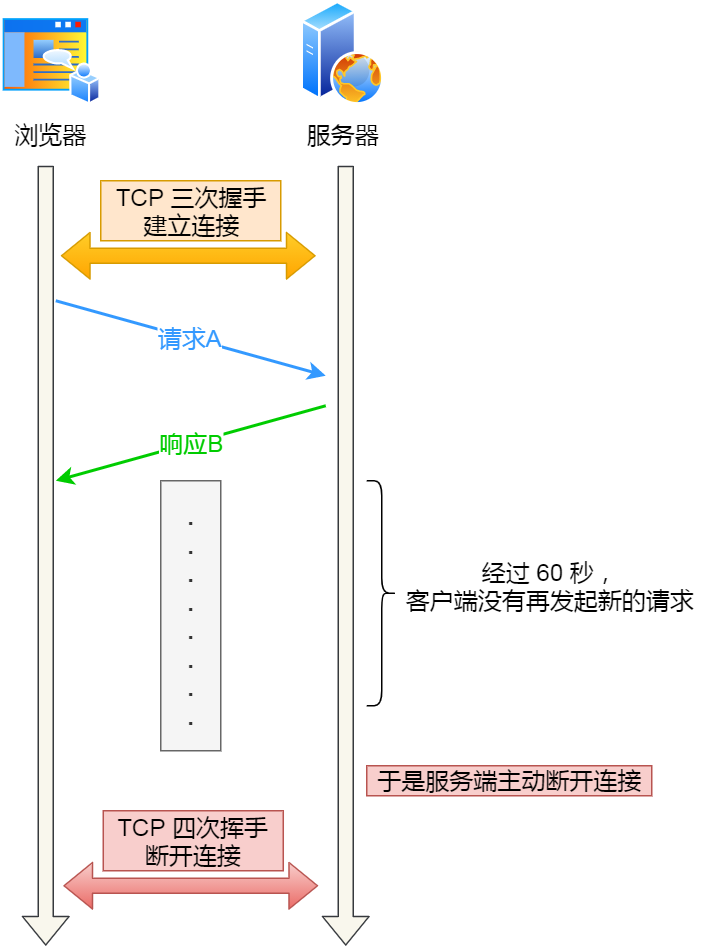 web 服务的 心跳机制
web 服务的 心跳机制
启动 TCP 的keepAlive机制
以服务器端为例,如果当前server端检测到超过一定时间没有数据传输,那么会向client端发送一个心跳探测报文,如果连续几个探测报文都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应用程序。
在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
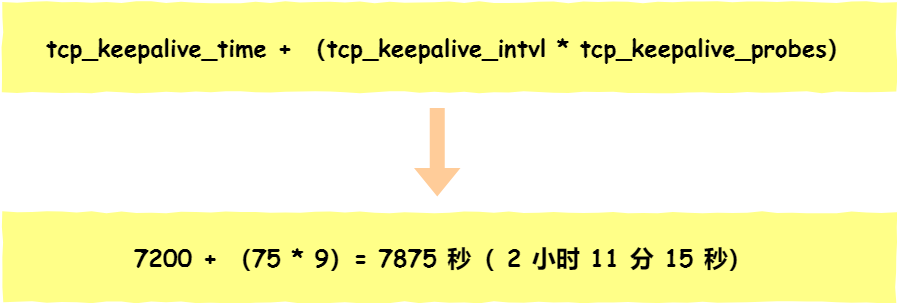
- tcp_keepalive_time=7200:表示保活时间是 7200 秒(2小时),也就 2 小时内如果没有任何连接相关的活动,则会启动保活机制
- tcp_keepalive_intvl=75:表示每次检测间隔 75 秒;
- tcp_keepalive_probes=9:表示检测 9 次无响应,认为对方是不可达的,从而中断本次的连接。
也就是说在 Linux 系统中,最少需要经过 2 小时 11 分 15 秒才可以发现一个「死亡」连接。
 img
img
注意,应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。
如果开启了 TCP 保活,需要考虑以下几种情况:
- 第一种,对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 第二种,对端主机宕机并重启。当 TCP 保活的探测报文发送给对端后,对端是可以响应的,但由于没有该连接的有效信息,会产生一个 RST 报文,这样很快就会发现 TCP 连接已经被重置。
- 第三种,是对端主机宕机(注意不是进程崩溃,进程崩溃后操作系统在回收进程资源的时候,会发送 FIN 报文,而主机宕机则是无法感知的,所以需要 TCP 保活机制来探测对方是不是发生了主机宕机),或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
锁有哪些?
Linux 提供的锁机制,主要有互斥锁、信号量、自旋锁、读写锁。
- 互斥锁(Mutex):也称为互斥量,用于保护共享资源,确保同一时间只有一个线程可以访问该资源。当一个线程获取到互斥锁后,其他线程需要等待锁释放才能继续访问。
- 信号量(Semaphore):用于控制对一组资源的访问。信号量可以允许多个线程同时访问资源,但是需要在访问前进行P操作(申请资源)和在访问结束后进行V操作(释放资源),以确保资源的正确使用。
- 自旋锁(Spinlock):是一种忙等待锁,在获取锁之前,线程会一直尝试获取锁,而不会进入睡眠状态。自旋锁适用于保护临界区较小、锁占用时间短暂的情况。
- 读写锁(ReadWrite Lock):也称为共享-独占锁,用于在读操作和写操作之间提供更好的并发性。读写锁允许多个线程同时读取共享资源,但是在写操作时需要独占访问,保证数据的一致性。
锁本身怎么保证线程安全?为什么一个线程拿到锁以后,另一个线程就无法获得锁?
所谓的锁,在计算机里本质上就是一块内存空间。当这个空间被赋值为1的时候表示加锁了,被赋值为0的时候表示解锁了,仅此而已。多个线程抢一个锁,就是抢着要把这块内存赋值为1。在一个多核环境里,内存空间是共享的。
CPU 通常会有多个CPU核心,每个核上各跑一个线程,那如何保证一次只有一个线程成功抢到锁呢?这必须要硬件的支持,譬如提供某种特殊指令。具体的实现如下。
硬件实现
CPU如果提供一些用来构建锁的原子性指令,比如x86的XCHG或CMPXCHG(加上LOCK prefix),能够完成原子性的compare-and-swap (CAS)机制,用这样的硬件指令就能实现自旋锁。
画外音:那么CAS是什么呢?
- CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。反正就是我知道你flag为0,我来了,诶?你的flag怎么是1?那我走了,再见。
LOCK前缀的作用是锁定系统总线(或者锁定某一块cache line)来实现原子性,简单来说就是,如果指令前加了LOCK前缀,就是告诉其他核,一旦我开始执行这个指令了,在我结束这个指令之前,谁也不许动,这样便实现了一次只能有一个核对同一个内存地址赋值。
操作系统实现
CPU提供了特殊硬件来保证内存操作的原子性的时候,再通过一种简单的逻辑,我们就可以构建出一个简单的自旋锁来了。
下面就可以利用CAS来实现自旋锁了:
// 1表示自旋锁已分配给某个线程,0表示自旋锁没有分配个任何线程,即处于释放状态
int owner = 0;
void spin_lock(int * owner ) {
while(!compare_and_set(owner, 0, 1) {
}
}//需要说明的一点是系统对comare_and_set的内核实现中包含对总线加锁
这个逻辑很简单,我们让多个线程持续地抢着将某块内存地址的值赋为1(原始为0),谁先抢到了谁就可以进入临界区,没抢到的线程继续在一个循环里面反复读取这块内存地址的值,看看自己的机会是不是到了。当抢到锁的线程在它的临界区结束以后,就可以把该内存地址的值赋为0,表示现在其他人可以抢锁了,用这种方式构建出来的锁也被称为自旋锁,自旋的意思就是没有拿到锁的线程就在那儿自己转儿。
接下来我们可以利用 CAS 原子操作实现互斥锁,我们可以通过操作系统的介入,来实现一个线程向操作系统申请把自己挂起,还是把自己挂起,将CPU让出来,这样或许其他的线程能做点更有用的事情。通过这样一种机制构建出来的锁,常常被称为mutex(互斥锁)。
lock:
movb $0, $al
xchgb $al, mutex
if(al 寄存器的内存 > 0) {
return0;
} else
{
挂起等待;
}
goto lock;
unlock
movb $1, mutex
唤醒等待 mutex 的线程;
return 0;
lock:这一步先将0赋值到寄存器al,再将mutex与al中的值交换(xchgb指令,CAS原子操作),再进行判断。当对某个线程进行lock操作时,即使在中间任意一步被切出去也没有问题。这样就保证了lock的操作也是原子的。
多线程一定好吗?怎么选用?
不一定的,线程越多,系统的运行速度不一定越快。
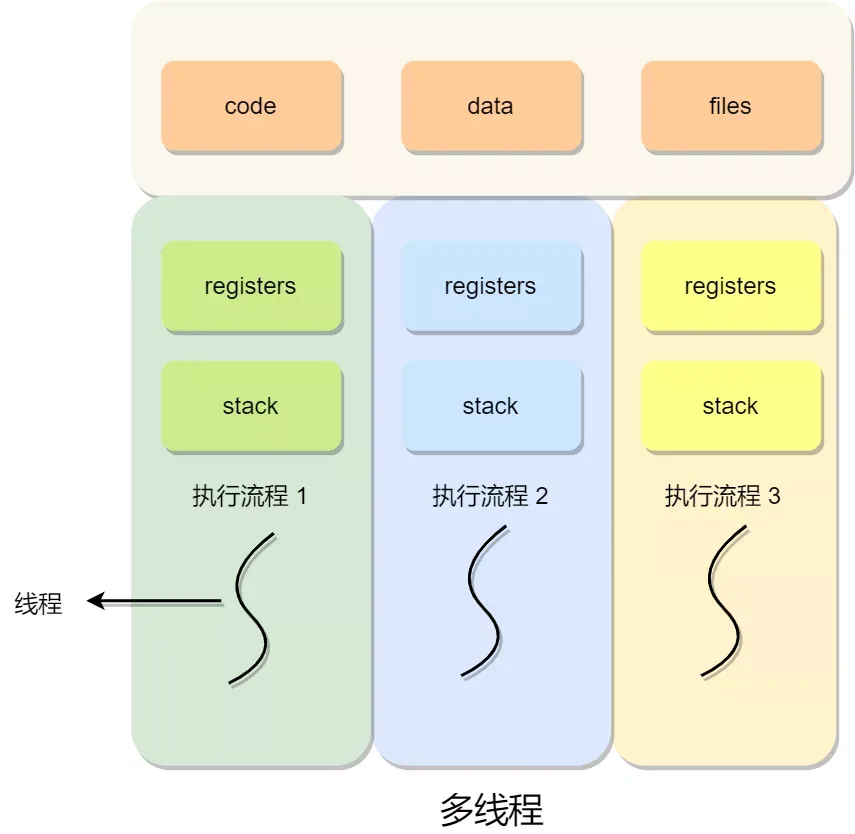
多线程的优点是提高程序的并发性,因为多线程可以同时执行多个任务,分利用多核处理器的性能,提高程序的处理能力和响应速度,所以如果任务可以进行有效的并行处理,并且对响应时间有较高的要求,多线程可以提升性能和用户体验。
而多线程的缺点主要是:
- 多线程编程复杂:多线程编程需要考虑线程同步、共享资源访问等问题,容易引发死锁、竞态条件等并发问题,增加了程序的复杂性和调试难度。
- 资源消耗:多线程需要占用额外的内存和CPU资源,线程的创建、销毁和切换都需要一定的开销,如果线程数量过多,会导致系统资源的浪费和性能下降。
线程切换详细过程是怎么样的?上下文保存在哪里?
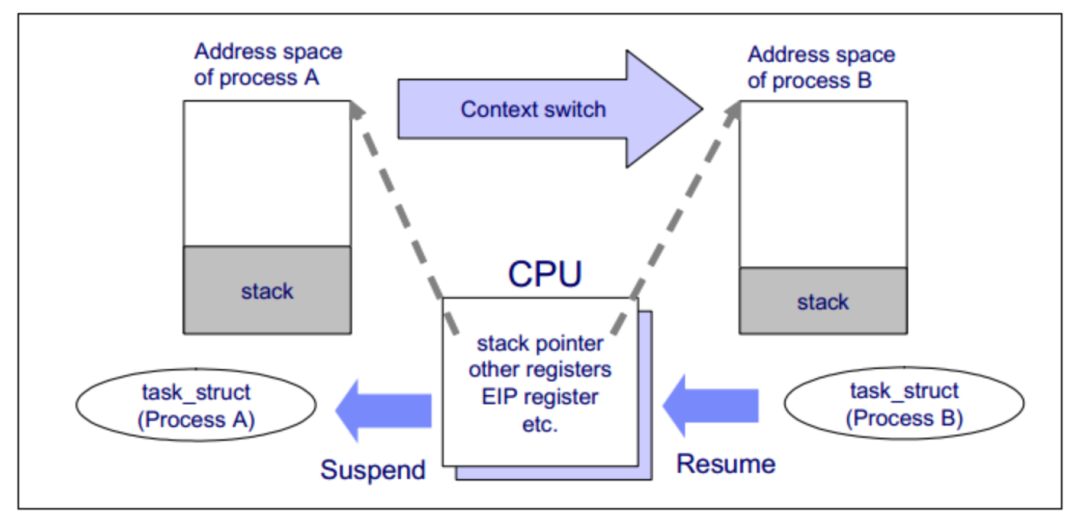
线程切换的详细过程可以分为以下几个步骤:
- 上下文保存:当操作系统决定切换到另一个线程时,它首先会保存当前线程的上下文信息。上下文信息包括寄存器状态、程序计数器、堆栈指针等,用于保存线程的执行状态。
- 切换到调度器:操作系统将执行权切换到调度器(Scheduler)。调度器负责选择下一个要执行的线程,并根据调度算法做出决策。
- 上下文恢复:调度器选择了下一个要执行的线程后,它会从该线程保存的上下文信息中恢复线程的执行状态。
- 切换到新线程:调度器将执行权切换到新线程,使其开始执行。
上下文信息的保存通常由操作系统负责管理,具体保存在哪里取决于操作系统的实现方式。一般情况下,上下文信息会保存在线程的控制块(Thread Control Block,TCB)中。
TCB是操作系统用于管理线程的数据结构,包含了线程的状态、寄存器的值、堆栈信息等。当发生线程切换时,操作系统会通过切换TCB来保存和恢复线程的上下文信息。
如果要对一个很大的数据集,进行排序,而没办法一次性在内存排序,这时候怎么办?
可以使用外部排序来解决,基本思路分为两个阶段。
部分排序阶段。
我们根据内存大小,将待排序的文件拆成多个部分,使得每个部分都是足以存入内存中的。然后选择合适的内排序算法,将多个文件部分排序,并输出到容量可以更大的外存临时文件中,每个临时文件都是有序排列的,我们将其称之为一个“顺段”。
在第一个阶段部分排序中,由于内存可以装下每个顺段的所有元素,可以使用快速排序,时间复杂度是O(nlogn)。
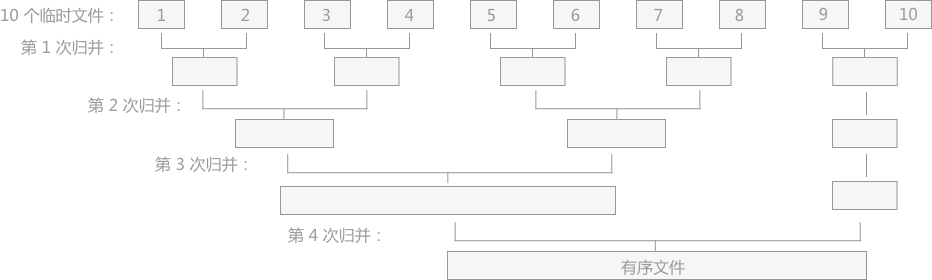
归并阶段
我们对前面的多个“顺段”进行合并,思想和归并排序其实是一样的。以 2 路归并为例,每次都将两个连续的顺段合并成一个更大的顺段。
因为内存限制,每次可能只能读入两个顺段的部分内容,所以我们需要一部分一部分读入,在内存里将可以确定顺序的部分排列,并输出到外存里的文件中,不断重复这个过程,直至两个顺段被完整遍历。这样经过多层的归并之后,最终会得到一个完整的顺序文件。
归并阶段有个非常大的时间消耗就是 IO,也就是输入输出。最好就是让归并的层数越低越好,为了降低降低归并层数,可以使用败者树。
败者树中的非终端结点中存储的是胜利(左右孩子相比较,谁最小即为胜者)的一方;而败者树中的非终端结点存储的是失败的一方。而在比较过程中,都是拿胜者去比较。
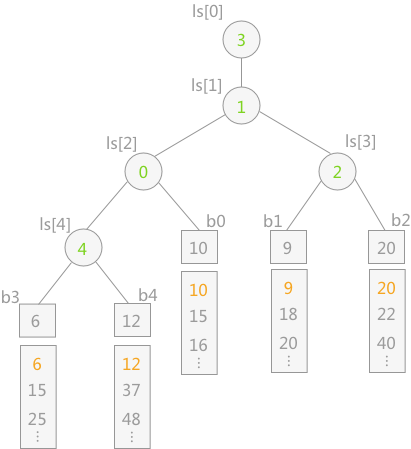
现在有了败者树的加持,多路归并排序就可以比较高效地解决外部排序的问题了。
大致思路就是:
- 先用内排序算法(比如快速排序),尽可能多的加载源文件,将其变成 n 个有序顺段。
- 在内存有限的前提下每 k 个文件为一组,每次流式地从各个文件中读取一个单词,借助败者树选出字典序最低的一个,输出到文件中,这样就可以将 k 个顺段合并到一个顺段中了;反复执行这样的操作,直至所有顺段被归并到同一个顺段。
算法
手撕LRU算法(思路:链表+哈希表)
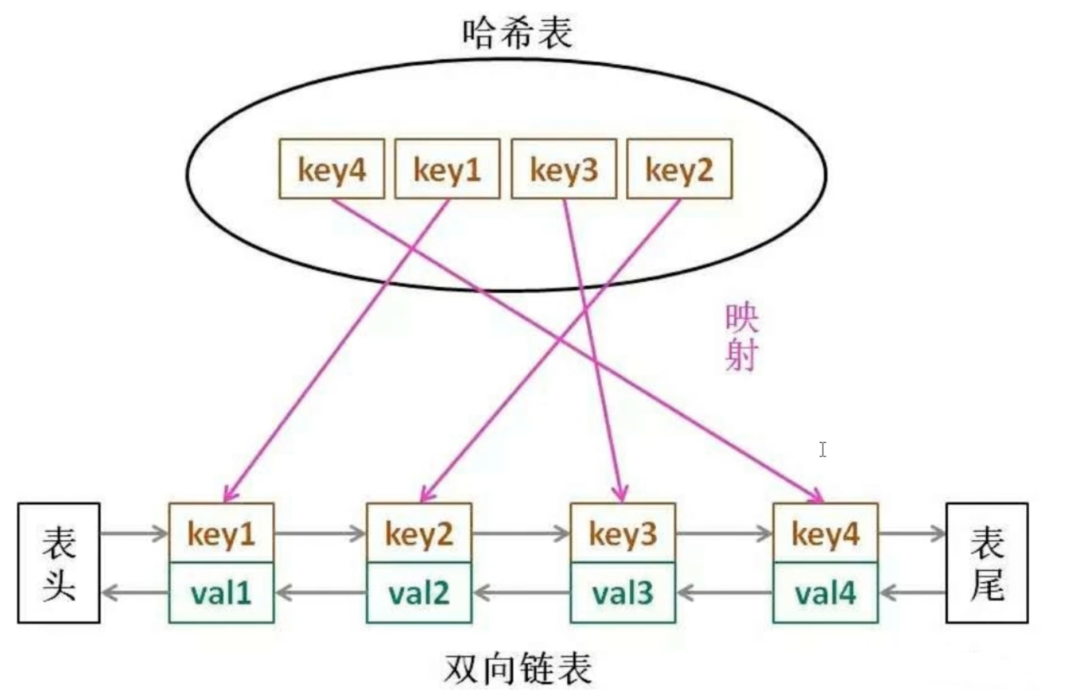
#include <iostream>
#include <unordered_map>
#include <list>
using namespace std;
class LRUCache {
private:
int capacity;
unordered_map<int, pair<int, list<int>::iterator>> cache;
list<int> lru;
public:
LRUCache(int cap) {
capacity = cap;
}
int get(int key) {
if (cache.find(key) != cache.end()) {
// 将访问的元素移到链表头部
lru.erase(cache[key].second);
lru.push_front(key);
cache[key].second = lru.begin();
return cache[key].first;
}
return -1;
}
void put(int key, int value) {
if (cache.find(key) != cache.end()) {
// 更新已存在的元素的值,并将其移到链表头部
lru.erase(cache[key].second);
}
else if (cache.size() >= capacity) {
// 删除最久未使用的元素
cache.erase(lru.back());
lru.pop_back();
}
// 插入新元素到链表头部
lru.push_front(key);
cache[key] = make_pair(value, lru.begin());
}
};
int main() {
LRUCache cache(2); // 创建容量为2的LRU缓存
cache.put(1, 1);
cache.put(2, 2);
cout << cache.get(1) << endl; // 输出 1
cache.put(3, 3); // 因为缓存容量已满,所以删除最久未使用的元素2
cout << cache.get(2) << endl; // 输出 -1,因为元素2已被删除
cache.put(4, 4); // 因为缓存容量已满,所以删除最久未使用的元素1
cout << cache.get(1) << endl; // 输出 -1,因为元素1已被删除
cout << cache.get(3) << endl; // 输出 3
cout << cache.get(4) << endl; // 输出 4
return 0;
}
历史好文: