
Apache Iceberg核心原理分析文件存储及数据写入流程


第一部分:Iceberg文件存储格式
Apache Iceberg作为一款新兴的数据湖解决方案在实现上高度抽象,在存储上能够对接当前主流的HDFS,S3文件系统并且支持多种文件存储格式,例如Parquet、ORC、AVRO。相较于Hudi、Delta与Spark的强耦合,Iceberg可以与多种计算引擎对接,目前社区已经支持Spark读写Iceberg、Impala/Hive查询Iceberg。本文基于Apache Iceberg 0.10.0,介绍Iceberg文件的组织方式以及不同文件的存储格式。
Iceberg Table Format
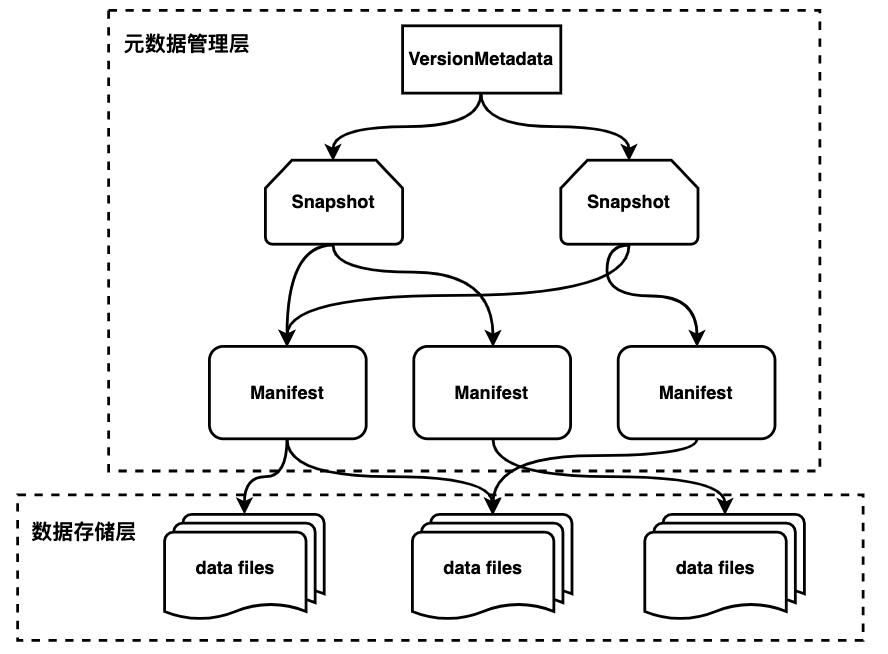
从图中可以看到iceberg将数据进行分层管理,主要分为元数据管理层和数据存储层。元数据管理层又可以细分为三层:
VersionMetadata Snapshot Manifest
VersionMetadata存储当前版本的元数据信息(所有snapshot信息);Snapshot表示当前操作的一个快照,每次commit都会生成一个快照,一个快照中包含多个Manifest,每个Manifest中记录了当前操作生成数据所对应的文件地址,也就是data files的地址。基于snapshot的管理方式,iceberg能够进行time travel(历史版本读取以及增量读取),并且提供了serializable isolation。
数据存储层支持不同的文件格式,目前支持Parquet、ORC、AVRO。
下面以HadoopTableOperation commit生成的数据为例介绍各层的数据格式。iceberg生成的数据目录结构如下所示:
├── data
│ ├── id=1
│ │ ├── 00000-0-04ae60eb-657d-45cb-bb99-d1cb7fe0ad5a-00001.parquet
│ │ └── 00000-4-487b841b-13b4-4ae8-9238-f70674d5102e-00001.parquet
│ ├── id=2
│ │ ├── 00001-1-e85b018b-e43a-44d7-9904-09c80a9b9c24-00001.parquet
│ │ └── 00001-5-0e2be766-c921-4269-8e1e-c3cff4b98a5a-00001.parquet
│ ├── id=3
│ │ ├── 00002-2-097171c5-d810-4de9-aa07-58f3f8a3f52e-00001.parquet
│ │ └── 00002-6-9d738169-1dbe-4cc5-9a87-f79457a9ec0b-00001.parquet
│ └── id=4
│ ├── 00003-3-b0c91d66-9e4e-4b7a-bcd5-db3dc1b847f2-00001.parquet
│ └── 00003-7-68c45a24-21a2-41e8-90f1-ef4be42f3002-00001.parquet
└── metadata
├── 1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m0.avro
├── 1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m1.avro
├── f475511f-877e-4da5-90aa-efa5928a7759-m0.avro
├── snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro
├── snap-5178718682852547007-1-f475511f-877e-4da5-90aa-efa5928a7759.avro
├── v1.metadata.json
├── v2.metadata.json
├── v3.metadata.json
└── version-hint.text
其中metadata目录存放元数据管理层的数据:
version-hint.text:存储version.metadata.json的版本号,即下文的number version[number].metadata.json snap-[snapshotID]-[attemptID]-[commitUUID].avro(snapshot文件) [commitUUID]-m-[manifestCount].avr- o(manifest文件)
data目录组织形式类似于hive,都是以分区进行目录组织(上图中id为分区列),最终数据可以使用不同文件格式进行存储:
[sparkPartitionID]-[sparkTaskID]-[UUID]-[fileCount].[parquet | avro | orc]
VersionMetadata
//
{
// 当前文件格式版本信息
// 目前为version 1
// 支持row-level delete等功能的version 2还在开发中
"format-version" : 1,
"table-uuid" : "a9114f94-911e-4acf-94cc-6d000b321812",
// hadoopTable location
"location" : "hdfs://10.242.199.202:9000/hive/empty_order_item",
// 最新snapshot的创建时间
"last-updated-ms" : 1608810968725,
"last-column-id" : 6,
// iceberg schema
"schema" : {
"type" : "struct",
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false, // 类似probuf中的required
"type" : "long"
}, {
"id" : 2,
"name" : "order_id",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "product_id",
"required" : false,
"type" : "long"
}, {
"id" : 4,
"name" : "product_price",
"required" : false,
"type" : "decimal(7, 2)"
}, {
"id" : 5,
"name" : "product_quantity",
"required" : false,
"type" : "int"
}, {
"id" : 6,
"name" : "product_name",
"required" : false,
"type" : "string"
} ]
},
"partition-spec" : [ {
"name" : "id",
"transform" : "identity", // transform类型
"source-id" : 1,
"field-id" : 1000
} ],
"default-spec-id" : 0,
// 分区信息
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "id",
// transform类型:目前支持identity,year,bucket等
"transform" : "identity",
// 对应schema.fields中相应field的ID
"source-id" : 1,
"field-id" : 1000
} ]
} ],
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
// hive创建该表存储的一些hive property信息
"properties" : {
"totalSize" : "0",
"rawDataSize" : "0",
"numRows" : "0",
"COLUMN_STATS_ACCURATE" : "{\"BASIC_STATS\":\"true\"}",
"numFiles" : "0"
},
// 当前snapshot id
"current-snapshot-id" : 2080639593951710914,
// snapshot信息
"snapshots" : [ {
"snapshot-id" : 5178718682852547007,
// 创建snapshot时间
"timestamp-ms" : 1608809818168,
"summary" : {
// spark写入方式,目前支持overwrite以及append
"operation" : "overwrite",
"spark.app.id" : "local-1608809790982",
"replace-partitions" : "true",
// 本次snapshot添加的文件数量
"added-data-files" : "4",
// 本次snapshot添加的record数量
"added-records" : "4",
// 本次snapshot添加的文件大小
"added-files-size" : "7217",
// 本次snapshot修改的分区数量
"changed-partition-count" : "4",
// 本次snapshot中record总数 = lastSnapshotTotalRecord - currentSnapshotDeleteRecord + currentSnapshotAddRecord
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-5178718682852547007-1-f475511f-877e-4da5-90aa-efa5928a7759.avro"
}, {
"snapshot-id" : 2080639593951710914,
// 上次snapshotID
"parent-snapshot-id" : 5178718682852547007,
"timestamp-ms" : 1608810968725,
"summary" : {
"operation" : "overwrite",
"spark.app.id" : "local-1608809790982",
"replace-partitions" : "true",
"added-data-files" : "4",
"deleted-data-files" : "4",
"added-records" : "4",
"deleted-records" : "4",
"added-files-size" : "7217",
"removed-files-size" : "7217",
"changed-partition-count" : "4",
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
// snapshot文件路径
"manifest-list" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro"
} ],
// snapshot记录
"snapshot-log" : [ {
"timestamp-ms" : 1608809818168,
"snapshot-id" : 5178718682852547007
}, {
"timestamp-ms" : 1608810968725,
"snapshot-id" : 2080639593951710914
} ],
// metada记录
"metadata-log" : [ {
"timestamp-ms" : 1608809758229,
"metadata-file" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1608809818168,
"metadata-file" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/v2.metadata.json"
} ]
}
上例展示的是v3.metadata.json中的数据,该文件保存了iceberg table schema、partition、snapshot信息,partition中的transform信息使得iceberg能够根据字段进行hidden partition,而无需像hive一样显示的指定分区字段。由于VersionMetadata中记录了每次snapshot的id以及create_time,我们可以通过时间或snapshotId查询相应snapshot的数据,实现Time Travel。
Snapshot
// Snapshot: 2080639593951710914
// Location: hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro
// manifest entry
{
"manifest_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m1.avro",
"manifest_length" : 5291,
"partition_spec_id" : 0,
// 该manifest entry所属的snapshot
"added_snapshot_id" : {
"long" : 2080639593951710914
},
// 该manifest中添加的文件数量
"added_data_files_count" : {
"int" : 4
},
// 创建该manifest时已经存在且
// 没有被这次创建操作删除的文件数量
"existing_data_files_count" : {
"int" : 0
},
// 创建manifest删除的文件
"deleted_data_files_count" : {
"int" : 0
},
// 该manifest中partition字段的范围
"partitions" : {
"array" : [ {
"contains_null" : false,
"lower_bound" : {
"bytes" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound" : {
"bytes" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
} ]
},
"added_rows_count" : {
"long" : 4
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
// manifest entry
{
"manifest_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m0.avro",
"manifest_length" : 5289,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 2080639593951710914
},
"added_data_files_count" : {
"int" : 0
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 4
},
"partitions" : {
"array" : [ {
"contains_null" : false,
"lower_bound" : {
"bytes" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound" : {
"bytes" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
} ]
},
"added_rows_count" : {
"long" : 0
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 4
}
}
一个snapshot中可以包含多个manifest entry,一个manifest entry表示一个manifest,其中重点需要关注的是每个manifest中的partitions字段,在根据filter进行过滤时可以首先通过该字段表示的分区范围对manifest进行过滤,避免无效的查询。
Manifest
//
{
// 当前文件格式版本信息
// 目前为version 1
// 支持row-level delete等功能的version 2还在开发中
"format-version" : 1,
"table-uuid" : "a9114f94-911e-4acf-94cc-6d000b321812",
// hadoopTable location
"location" : "hdfs://10.242.199.202:9000/hive/empty_order_item",
// 最新snapshot的创建时间
"last-updated-ms" : 1608810968725,
"last-column-id" : 6,
// iceberg schema
"schema" : {
"type" : "struct",
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false, // 类似probuf中的required
"type" : "long"
}, {
"id" : 2,
"name" : "order_id",
"required" : false,
"type" : "long"
}, {
"id" : 3,
"name" : "product_id",
"required" : false,
"type" : "long"
}, {
"id" : 4,
"name" : "product_price",
"required" : false,
"type" : "decimal(7, 2)"
}, {
"id" : 5,
"name" : "product_quantity",
"required" : false,
"type" : "int"
}, {
"id" : 6,
"name" : "product_name",
"required" : false,
"type" : "string"
} ]
},
"partition-spec" : [ {
"name" : "id",
"transform" : "identity", // transform类型
"source-id" : 1,
"field-id" : 1000
} ],
"default-spec-id" : 0,
// 分区信息
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ {
"name" : "id",
// transform类型:目前支持identity,year,bucket等
"transform" : "identity",
// 对应schema.fields中相应field的ID
"source-id" : 1,
"field-id" : 1000
} ]
} ],
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
// hive创建该表存储的一些hive property信息
"properties" : {
"totalSize" : "0",
"rawDataSize" : "0",
"numRows" : "0",
"COLUMN_STATS_ACCURATE" : "{\"BASIC_STATS\":\"true\"}",
"numFiles" : "0"
},
// 当前snapshot id
"current-snapshot-id" : 2080639593951710914,
// snapshot信息
"snapshots" : [ {
"snapshot-id" : 5178718682852547007,
// 创建snapshot时间
"timestamp-ms" : 1608809818168,
"summary" : {
// spark写入方式,目前支持overwrite以及append
"operation" : "overwrite",
"spark.app.id" : "local-1608809790982",
"replace-partitions" : "true",
// 本次snapshot添加的文件数量
"added-data-files" : "4",
// 本次snapshot添加的record数量
"added-records" : "4",
// 本次snapshot添加的文件大小
"added-files-size" : "7217",
// 本次snapshot修改的分区数量
"changed-partition-count" : "4",
// 本次snapshot中record总数 = lastSnapshotTotalRecord - currentSnapshotDeleteRecord + currentSnapshotAddRecord
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-5178718682852547007-1-f475511f-877e-4da5-90aa-efa5928a7759.avro"
}, {
"snapshot-id" : 2080639593951710914,
// 上次snapshotID
"parent-snapshot-id" : 5178718682852547007,
"timestamp-ms" : 1608810968725,
"summary" : {
"operation" : "overwrite",
"spark.app.id" : "local-1608809790982",
"replace-partitions" : "true",
"added-data-files" : "4",
"deleted-data-files" : "4",
"added-records" : "4",
"deleted-records" : "4",
"added-files-size" : "7217",
"removed-files-size" : "7217",
"changed-partition-count" : "4",
"total-records" : "4",
"total-data-files" : "4",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
// snapshot文件路径
"manifest-list" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro"
} ],
// snapshot记录
"snapshot-log" : [ {
"timestamp-ms" : 1608809818168,
"snapshot-id" : 5178718682852547007
}, {
"timestamp-ms" : 1608810968725,
"snapshot-id" : 2080639593951710914
} ],
// metada记录
"metadata-log" : [ {
"timestamp-ms" : 1608809758229,
"metadata-file" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1608809818168,
"metadata-file" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/v2.metadata.json"
} ]
}
上例展示的是v3.metadata.json中的数据,该文件保存了iceberg table schema、partition、snapshot信息,partition中的transform信息使得iceberg能够根据字段进行hidden partition,而无需像hive一样显示的指定分区字段。由于VersionMetadata中记录了每次snapshot的id以及create_time,我们可以通过时间或snapshotId查询相应snapshot的数据,实现Time Travel。
Snapshot
// Snapshot: 2080639593951710914
// Location: hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/snap-2080639593951710914-1-1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae.avro
// manifest entry
{
"manifest_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m1.avro",
"manifest_length" : 5291,
"partition_spec_id" : 0,
// 该manifest entry所属的snapshot
"added_snapshot_id" : {
"long" : 2080639593951710914
},
// 该manifest中添加的文件数量
"added_data_files_count" : {
"int" : 4
},
// 创建该manifest时已经存在且
// 没有被这次创建操作删除的文件数量
"existing_data_files_count" : {
"int" : 0
},
// 创建manifest删除的文件
"deleted_data_files_count" : {
"int" : 0
},
// 该manifest中partition字段的范围
"partitions" : {
"array" : [ {
"contains_null" : false,
"lower_bound" : {
"bytes" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound" : {
"bytes" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
} ]
},
"added_rows_count" : {
"long" : 4
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
// manifest entry
{
"manifest_path" : "hdfs://10.242.199.202:9000/hive/empty_order_item/metadata/1f8279fb-5b2d-464c-af12-d9d6fbe9b5ae-m0.avro",
"manifest_length" : 5289,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 2080639593951710914
},
"added_data_files_count" : {
"int" : 0
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 4
},
"partitions" : {
"array" : [ {
"contains_null" : false,
"lower_bound" : {
"bytes" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
},
"upper_bound" : {
"bytes" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}
} ]
},
"added_rows_count" : {
"long" : 0
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 4
}
}
Manifest管理多个data文件,一条DataFileEntry对应一个data文件,DataFileEntry中记录了所属partition,value bounds等信息,value_counts和null_value_counts可以用于过滤null列,例:column a所对应的value_count为3,且对应的null_value_count也为3,此时如果select a,则可以根据value_count-null_value_count=0判断a全为null直接返回而无需再进行parquet文件的查询;除此之外,可以根据value bounds进行过滤,加速查询。
第二部分:Spark写Iceberg流程分析
spark写入示例
import org.apache.iceberg.hadoop.HadoopTables
import org.apache.hadoop.conf.Configuration
import org.apache.iceberg.catalog.TableIdentifier
import org.apache.iceberg.Schema
import org.apache.iceberg.types._
import org.apache.spark.sql.types._
import org.apache.iceberg.PartitionSpec
import org.apache.iceberg.spark.SparkSchemaUtil
import org.apache.spark.sql._
import spark.implicits._
val order_item_schema = StructType(List(
StructField("id", LongType, true),
StructField("order_id", LongType, true),
StructField("product_id", LongType, true),
StructField("product_price", DecimalType(7,2), true),
StructField("product_quantity", IntegerType, true),
StructField("product_name", StringType, true)
))
val order_item_action = Seq(
Row(1L, 1L, 1L, Decimal.apply(50.00, 7, 2), 2, "table lamp"),
Row(2L, 1L, 2L, Decimal.apply(100.5, 7, 2), 1, "skirt"),
Row(3L, 2L, 1L, Decimal.apply(50.00, 7, 2), 1, "table lamp"),
Row(4L, 3L, 3L, Decimal.apply(0.99, 7, 2), 1, "match")
)
val iceberg_schema = new Schema(
Types.NestedField.optional(1, "id", Types.LongType.get()),
Types.NestedField.optional(2, "order_id", Types.LongType.get()),
Types.NestedField.optional(3, "product_id", Types.LongType.get()),
Types.NestedField.optional(4, "product_price", Types.DecimalType.of(7, 2)),
Types.NestedField.optional(5, "product_quantity", Types.IntegerType.get()),
Types.NestedField.optional(6, "product_name", Types.StringType.get())
)
val iceberg_partition = PartitionSpec.builderFor(iceberg_schema).identity("id").build()
val hadoopTable = new HadoopTables(sc.hadoopConfiguration);
val location = "hdfs://10.242.199.202:9000/hive/empty_order_item";
hadoopTable.create(iceberg_schema, iceberg_partition, location)
val df = spark.createDataFrame(sc.makeRDD(order_item_action), order_item_schema)
df.write.format("iceberg").mode("overwrite").save("hdfs://10.242.199.202:9000/hive/empty_order_item")
spark写入iceberg主要分为两步:
Executor写入数据 Driver commit生成元数据
Executor写入逻辑
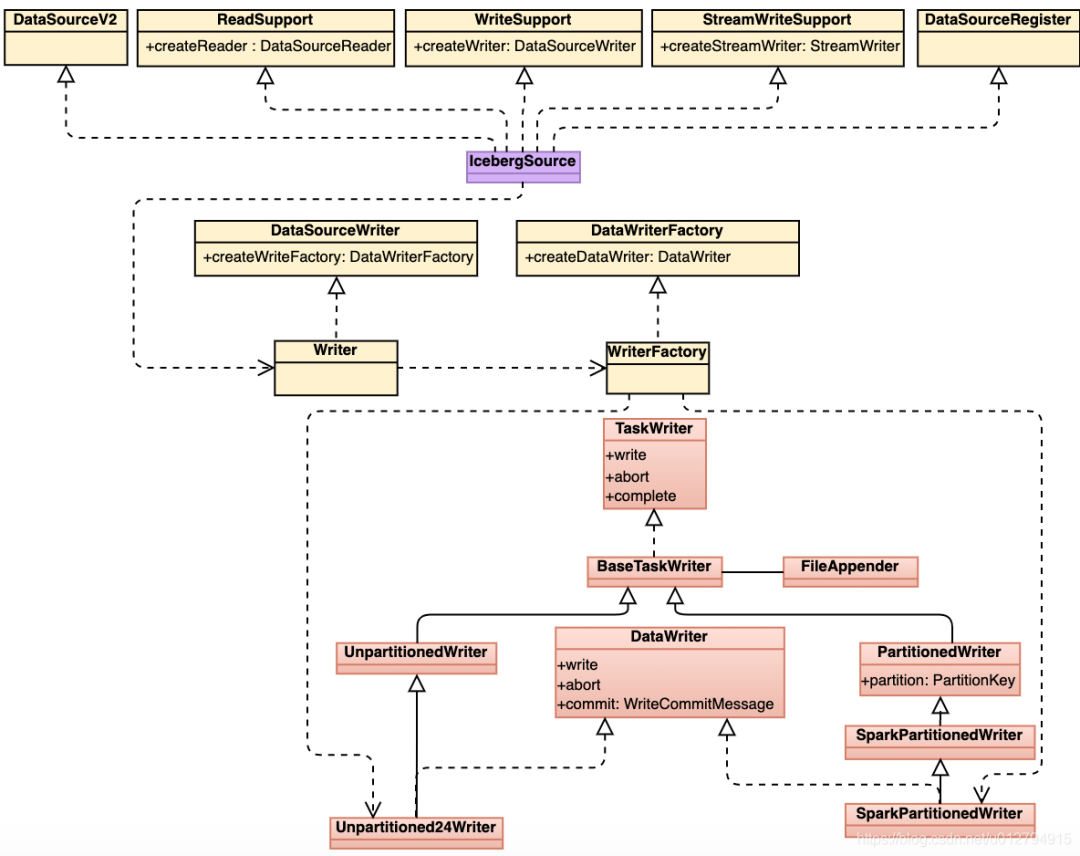
由上图可以看到IcebergSource实现了spark ReadSupport、WriteSupport、StreamWriteSupport等接口,WriteFactory根据写入表的类型:(1) 分区表 (2) 非分区表,生成不同的writer,最后通过write方法写入数据。
我们以写入分区表为例简单介绍一下executor端iceberg写入数据的流程:
根据file format生成对应的FileAppender,FileAppender完成实际的写文件操作。目前支持3种文件格式的写入:Parquet、Avro以及Orc
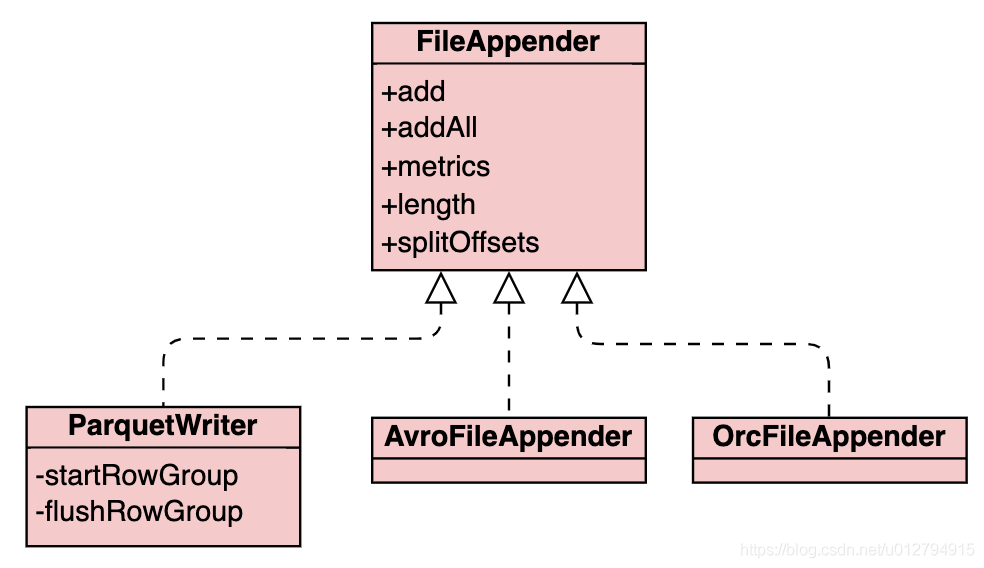
iceberg分区数据不直接写入数据文件中,而是通过目录树结构来进行存储,分区目录结构与hive类型,都是以key1=value1/key2=value2的形式进行组织。在写入数据之前,partitionWriter首先根据partition transform函数得到对应的partition value,然后创建对应的分区目录 fileAppender通过调用不同的file format组件将数据写入到文件中。iceberg写入时可以通过设置write.target-file-size-bytes table property调整写入文件target大小,默认为LONG_MAX 当所有数据写入完成后,iceberg会收集写入的统计信息,例如record_count, lower_bound, upper_bound, value_count等用于driver端生成对应的manifest文件,最后executor端将这些信息传回driver端。
Driver commit逻辑
iceberg snapshot中的统计信息实际是累计更新的结果,相较于上次commit,本次commit发生了哪些变化,例新增了多少条记录,删除了多少条记录,新增了多少文件,删除了多少文件等等。既然是累计更新,首先需要知道上次snapshot的信息,然后计算最后的结果。iceberg读取当前最新snapshot数据过程如下:
读取version.hint中记录的最新metadata版本号versionNumber 读取version[versionNumber].metadata.json文件,根据metadata中记录的snpshots信息以及current snapshot id得到最新snapshot的location 最后根据获得的location读取对应的snapshot文件得到最新的snapshot数据
overwrite实际上可以等价划分成两个步骤:
delete insert
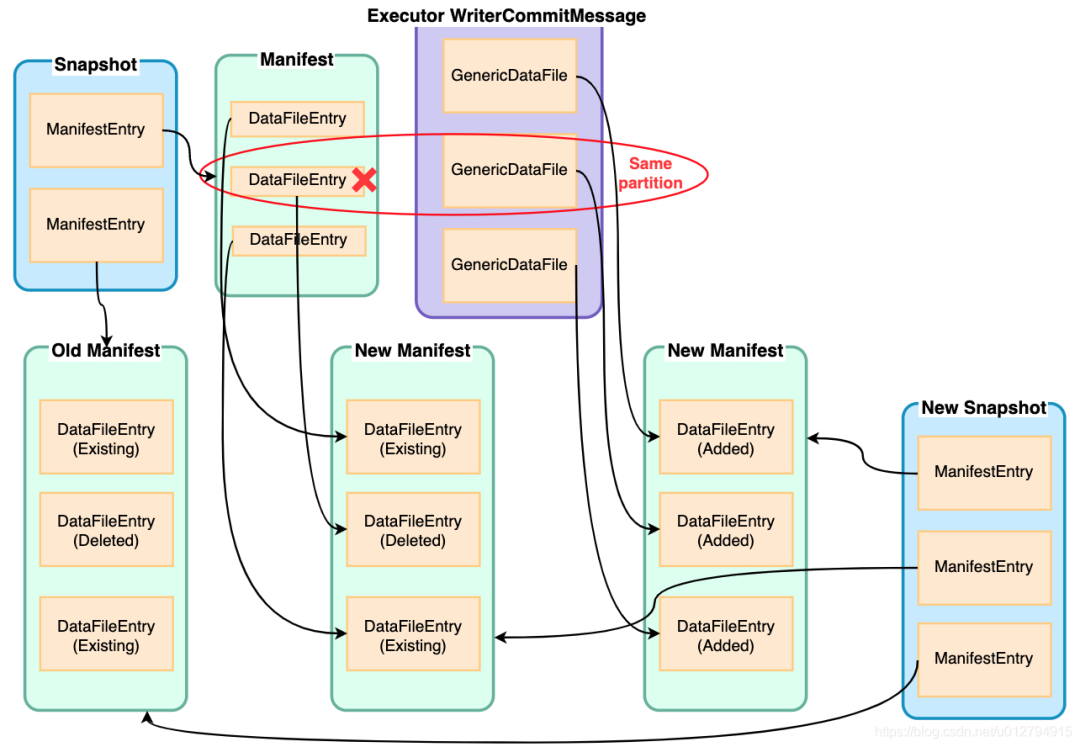
那么我们如何知道需要删除哪些数据呢?这里就要用到刚刚读取的current snapshot数据以及executor传回的信息,根据这些信息,我们可以计算得到哪些分区文件是需要通过覆盖删除的,实际上是将manifest中的对应DataFileEntry标记成删除写入到新的manifest文件中,没有被删除的DataFileEntry则标记成Existing写入到manifest文件中
在完成了delete操作之后,insert操作就相对比较简单,只要将GenericDataFile全部写入到新的manifest中即可
iceberg默认开启merge manifest功能,当manifest文件数量超过commit.manifest.min-count-to-merge时(默认100),将多个small manifest文件合并成large manifest(large manifest文件大小由commit.manifest.target-size-bytes指定,默认为8M)
最后iceberg根据这些Added/Deleted/Existing DataFileEntry得到本次commit的差值统计信息,与前一次snapshot统计信息累加最终得到本次snapshot的统计信息(added_data_files_count, added_rows_count等)。生成snapshot的整个过程如下图所示:
在生成新的snapshot后,只剩最后一步那就是生成新版本的version.metadata.json文件,同时将版本号写入到version.hint中,至此完成了所有iceberg数据的写入。
第三部分:Flink写Iceberg流程分析
开始实例
flink支持DataStream和DataStream写入iceberg
StreamExecutionEnvironment env = ...;
DataStream<RowData> input = ... ;
Configuration hadoopConf = new Configuration();
TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://nn:8020/warehouse/path", hadoopConf);
FlinkSink.forRowData(input, FLINK_SCHEMA)
.tableLoader(tableLoader)
.writeParallelism(1)
.build();
env.execute("Test Iceberg DataStream");
input为DataStream和DataStream形式的输入流,FLINK_SCHEMA为TableSchema;
首先看build()方法:
public DataStreamSink<RowData> build() {
Preconditions.checkArgument(this.rowDataInput != null, "Please use forRowData() to initialize the input DataStream.");
Preconditions.checkNotNull(this.tableLoader, "Table loader shouldn't be null");
if (this.table == null) {
this.tableLoader.open();
try {
TableLoader loader = this.tableLoader;
Throwable var2 = null;
try {
this.table = loader.loadTable();
} catch (Throwable var12) {
var2 = var12;
throw var12;
} finally {
if (loader != null) {
if (var2 != null) {
try {
loader.close();
} catch (Throwable var11) {
var2.addSuppressed(var11);
}
} else {
loader.close();
}
}
}
} catch (IOException var14) {
throw new UncheckedIOException("Failed to load iceberg table from table loader: " + this.tableLoader, var14);
}
}
List<Integer> equalityFieldIds = Lists.newArrayList();
if (this.equalityFieldColumns != null && this.equalityFieldColumns.size() > 0) {
Iterator var16 = this.equalityFieldColumns.iterator();
while(var16.hasNext()) {
String column = (String)var16.next();
NestedField field = this.table.schema().findField(column);
Preconditions.checkNotNull(field, "Missing required equality field column '%s' in table schema %s", column, this.table.schema());
equalityFieldIds.add(field.fieldId());
}
}
RowType flinkRowType = FlinkSink.toFlinkRowType(this.table.schema(), this.tableSchema);
this.rowDataInput = this.distributeDataStream(this.rowDataInput, this.table.properties(), this.table.spec(), this.table.schema(), flinkRowType);
IcebergStreamWriter<RowData> streamWriter = FlinkSink.createStreamWriter(this.table, flinkRowType, equalityFieldIds);
IcebergFilesCommitter filesCommitter = new IcebergFilesCommitter(this.tableLoader, this.overwrite);
this.writeParallelism = this.writeParallelism == null ? this.rowDataInput.getParallelism() : this.writeParallelism;
DataStream<Void> returnStream = this.rowDataInput.transform(FlinkSink.ICEBERG_STREAM_WRITER_NAME, TypeInformation.of(WriteResult.class), streamWriter).setParallelism(this.writeParallelism).transform(FlinkSink.ICEBERG_FILES_COMMITTER_NAME, Types.VOID, filesCommitter).setParallelism(1).setMaxParallelism(1);
return returnStream.addSink(new DiscardingSink()).name(String.format("IcebergSink %s", this.table.name())).setParallelism(1);
}
此处创建写的iceberg核心算子IcebergStreamWriter和IcebergFilesCommitter
IcebergStreamWriter
IcebergStreamWriter<RowData> streamWriter = FlinkSink.createStreamWriter(this.table, flinkRowType, equalityFieldIds);
build()方法中,调用createStreamWriter()创建IcebergStreamWriter
static IcebergStreamWriter<RowData> createStreamWriter(Table table, RowType flinkRowType, List<Integer> equalityFieldIds) {
Map<String, String> props = table.properties();
long targetFileSize = getTargetFileSizeBytes(props);
FileFormat fileFormat = getFileFormat(props);
TaskWriterFactory<RowData> taskWriterFactory = new RowDataTaskWriterFactory(table.schema(), flinkRowType, table.spec(), table.locationProvider(), table.io(), table.encryption(), targetFileSize, fileFormat, props, equalityFieldIds);
return new IcebergStreamWriter(table.name(), taskWriterFactory);
}
根据表信息构建TaskWriterFactory,并传入到IcebergStreamWriter
class IcebergStreamWriter<T> extends AbstractStreamOperator<WriteResult> implements OneInputStreamOperator<T, WriteResult>, BoundedOneInput {
private static final long serialVersionUID = 1L;
private final String fullTableName;
private final TaskWriterFactory<T> taskWriterFactory;
private transient TaskWriter<T> writer;
private transient int subTaskId;
private transient int attemptId;
IcebergStreamWriter(String fullTableName, TaskWriterFactory<T> taskWriterFactory) {
this.fullTableName = fullTableName;
this.taskWriterFactory = taskWriterFactory;
this.setChainingStrategy(ChainingStrategy.ALWAYS);
}
public void open() {
this.subTaskId = this.getRuntimeContext().getIndexOfThisSubtask();
this.attemptId = this.getRuntimeContext().getAttemptNumber();
this.taskWriterFactory.initialize(this.subTaskId, this.attemptId);
this.writer = this.taskWriterFactory.create();
}
public void prepareSnapshotPreBarrier(long checkpointId) throws Exception {
this.emit(this.writer.complete());
this.writer = this.taskWriterFactory.create();
}
public void processElement(StreamRecord<T> element) throws Exception {
this.writer.write(element.getValue());
}
}
在open中通过传入的taskWriterFactory构建TaskWriter
public TaskWriter<RowData> create() {
Preconditions.checkNotNull(this.outputFileFactory, "The outputFileFactory shouldn't be null if we have invoked the initialize().");
if (this.equalityFieldIds != null && !this.equalityFieldIds.isEmpty()) {
return (TaskWriter)(this.spec.isUnpartitioned() ? new UnpartitionedDeltaWriter(this.spec, this.format, this.appenderFactory, this.outputFileFactory, this.io, this.targetFileSizeBytes, this.schema, this.flinkSchema, this.equalityFieldIds) : new PartitionedDeltaWriter(this.spec, this.format, this.appenderFactory, this.outputFileFactory, this.io, this.targetFileSizeBytes, this.schema, this.flinkSchema, this.equalityFieldIds));
} else {
return (TaskWriter)(this.spec.isUnpartitioned() ? new UnpartitionedWriter(this.spec, this.format, this.appenderFactory, this.outputFileFactory, this.io, this.targetFileSizeBytes) : new RowDataTaskWriterFactory.RowDataPartitionedFanoutWriter(this.spec, this.format, this.appenderFactory, this.outputFileFactory, this.io, this.targetFileSizeBytes, this.schema, this.flinkSchema));
}
}
此方法中根据是否指定字段,构造分区写(PartitionedDeltaWriter/RowDataPartitionedFanoutWriter)和非分区写实例(UnpartitionedDeltaWriter/UnpartitionedWriter) 四个类的调用关系:
指定字段:
UnpartitionedDeltaWriter -> BaseEqualityDeltaWriter.write() -> RollingFileWriter.write() -> appender.add() PartitionedDeltaWriter -> BaseDeltaTaskWriter.write() -> RollingFileWriter.write() -> appender.add()
未指定字段:
UnpartitionedWriter -> RollingFileWriter.write() -> appender.add()
RowDataPartitionedFanoutWriter -> BaseRollingWriter.write -> RollingFileWriter.write() -> appender.add()
底层调用的appender为创建TaskWriter传入的FlinkAppenderFactory创建的
在processElement()中调用write(element.getValue())方法,将数据写入,最后在checkpoint时提交。
提示:task执行三部曲:beforeInvoke() -> runMailboxLoop() -> afterInvoke() beforeInvoke调用open()和initializeState(),runMailboxLoop调用processElement()处理数据
IcebergFilesCommitter
IcebergFilesCommitter filesCommitter = new IcebergFilesCommitter(this.tableLoader, this.overwrite);
build()方法中,传入tableLoader和overwrite直接创建IcebergFilesCommitter。
checkpoint初始化操作在IcebergFilesCommitter的initializeState()
public void initializeState(StateInitializationContext context) throws Exception {
super.initializeState(context);
this.flinkJobId = this.getContainingTask().getEnvironment().getJobID().toString();
this.tableLoader.open();
this.table = this.tableLoader.loadTable();
int subTaskId = this.getRuntimeContext().getIndexOfThisSubtask();
int attemptId = this.getRuntimeContext().getAttemptNumber();
this.manifestOutputFileFactory = FlinkManifestUtil.createOutputFileFactory(this.table, this.flinkJobId, subTaskId, (long)attemptId);
this.maxCommittedCheckpointId = -1L;
this.checkpointsState = context.getOperatorStateStore().getListState(STATE_DESCRIPTOR);
this.jobIdState = context.getOperatorStateStore().getListState(JOB_ID_DESCRIPTOR);
if (context.isRestored()) {
String restoredFlinkJobId = (String)((Iterable)this.jobIdState.get()).iterator().next();
Preconditions.checkState(!Strings.isNullOrEmpty(restoredFlinkJobId), "Flink job id parsed from checkpoint snapshot shouldn't be null or empty");
this.maxCommittedCheckpointId = getMaxCommittedCheckpointId(this.table, restoredFlinkJobId);
NavigableMap<Long, byte[]> uncommittedDataFiles = Maps.newTreeMap((SortedMap)((Iterable)this.checkpointsState.get()).iterator().next()).tailMap(this.maxCommittedCheckpointId, false);
if (!uncommittedDataFiles.isEmpty()) {
long maxUncommittedCheckpointId = (Long)uncommittedDataFiles.lastKey();
this.commitUpToCheckpoint(uncommittedDataFiles, restoredFlinkJobId, maxUncommittedCheckpointId);
}
}
}
checkpoint提交流程在IcebergFilesCommitter的snapshotState中
public void snapshotState(StateSnapshotContext context) throws Exception {
super.snapshotState(context);
long checkpointId = context.getCheckpointId();
LOG.info("Start to flush snapshot state to state backend, table: {}, checkpointId: {}", this.table, checkpointId);
this.dataFilesPerCheckpoint.put(checkpointId, this.writeToManifest(checkpointId));
this.checkpointsState.clear();
this.checkpointsState.add(this.dataFilesPerCheckpoint);
this.jobIdState.clear();
this.jobIdState.add(this.flinkJobId);
this.writeResultsOfCurrentCkpt.clear();
}
this.dataFilesPerCheckpoint.put(checkpointId, this.writeToManifest(checkpointId)); 为更新当前的checkpointId和manifest元文件信息
dataFilesPerCheckpoint与调用关系如下:
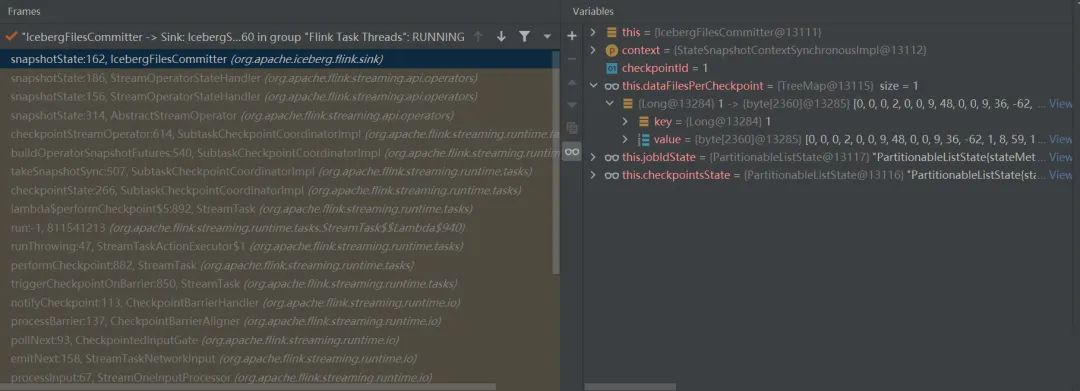
private byte[] writeToManifest(long checkpointId) throws IOException {
if (this.writeResultsOfCurrentCkpt.isEmpty()) {
return EMPTY_MANIFEST_DATA;
} else {
WriteResult result = WriteResult.builder().addAll(this.writeResultsOfCurrentCkpt).build();
DeltaManifests deltaManifests = FlinkManifestUtil.writeCompletedFiles(result, () -> {
return this.manifestOutputFileFactory.create(checkpointId);
}, this.table.spec());
return SimpleVersionedSerialization.writeVersionAndSerialize(DeltaManifestsSerializer.INSTANCE, deltaManifests);
}
}
writeResultsOfCurrentCkpt中包含了datafile文件、deletefile文件和referenced数据文件。然后,根据result创建deltaManifests ,并且返回序列化后的manifest信息。

deltaManifests 值如下:
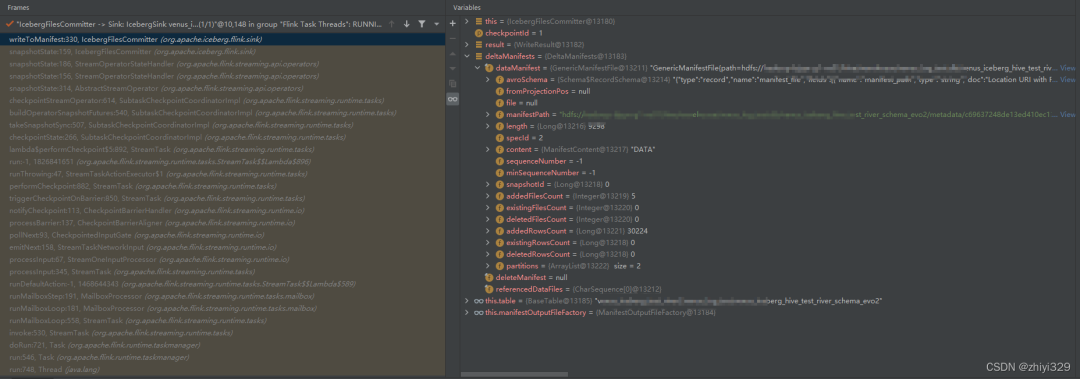
static DeltaManifests writeCompletedFiles(WriteResult result, Supplier<OutputFile> outputFileSupplier, PartitionSpec spec) throws IOException {
ManifestFile dataManifest = null;
ManifestFile deleteManifest = null;
if (result.dataFiles() != null && result.dataFiles().length > 0) {
dataManifest = writeDataFiles((OutputFile)outputFileSupplier.get(), spec, Lists.newArrayList(result.dataFiles()));
}
if (result.deleteFiles() != null && result.deleteFiles().length > 0) {
OutputFile deleteManifestFile = (OutputFile)outputFileSupplier.get();
ManifestWriter<DeleteFile> deleteManifestWriter = ManifestFiles.writeDeleteManifest(2, spec, deleteManifestFile, DUMMY_SNAPSHOT_ID);
ManifestWriter<DeleteFile> writer = deleteManifestWriter;
Throwable var8 = null;
try {
DeleteFile[] var9 = result.deleteFiles();
int var10 = var9.length;
for(int var11 = 0; var11 < var10; ++var11) {
DeleteFile deleteFile = var9[var11];
writer.add(deleteFile);
}
} catch (Throwable var16) {
var8 = var16;
throw var16;
} finally {
if (writer != null) {
$closeResource(var8, writer);
}
}
deleteManifest = deleteManifestWriter.toManifestFile();
}
return new DeltaManifests(dataManifest, deleteManifest, result.referencedDataFiles());
}
从上面写入过程可以看出,datafile和deletefile写入后,分别生成各自的Manifest文件,最后创建DeltaManifests返回。
最后通知checkpoint完成,提交checkpoint
public void notifyCheckpointComplete(long checkpointId) throws Exception {
super.notifyCheckpointComplete(checkpointId);
if (checkpointId > this.maxCommittedCheckpointId) {
this.commitUpToCheckpoint(this.dataFilesPerCheckpoint, this.flinkJobId, checkpointId);
this.maxCommittedCheckpointId = checkpointId;
}
}
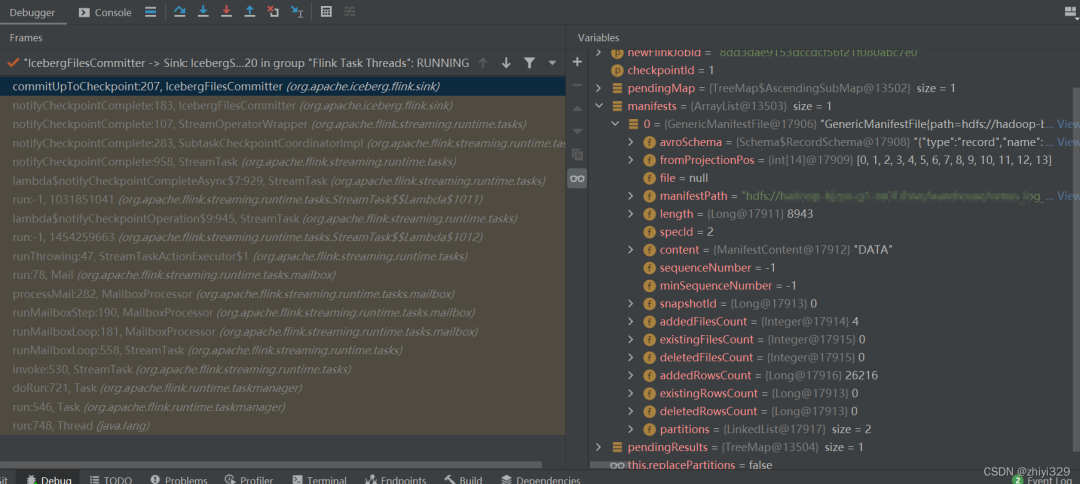
private void commitUpToCheckpoint(NavigableMap<Long, byte[]> deltaManifestsMap, String newFlinkJobId, long checkpointId) throws IOException {
NavigableMap<Long, byte[]> pendingMap = deltaManifestsMap.headMap(checkpointId, true);
List<ManifestFile> manifests = Lists.newArrayList();
NavigableMap<Long, WriteResult> pendingResults = Maps.newTreeMap();
Iterator var8 = pendingMap.entrySet().iterator();
while(var8.hasNext()) {
Entry<Long, byte[]> e = (Entry)var8.next();
if (!Arrays.equals(EMPTY_MANIFEST_DATA, (byte[])e.getValue())) {
DeltaManifests deltaManifests = (DeltaManifests)SimpleVersionedSerialization.readVersionAndDeSerialize(DeltaManifestsSerializer.INSTANCE, (byte[])e.getValue());
pendingResults.put((Long)e.getKey(), FlinkManifestUtil.readCompletedFiles(deltaManifests, this.table.io()));
manifests.addAll(deltaManifests.manifests());
}
}
if (this.replacePartitions) {
this.replacePartitions(pendingResults, newFlinkJobId, checkpointId);
} else {
this.commitDeltaTxn(pendingResults, newFlinkJobId, checkpointId);
}
pendingMap.clear();
var8 = manifests.iterator();
while(var8.hasNext()) {
ManifestFile manifest = (ManifestFile)var8.next();
try {
this.table.io().deleteFile(manifest.path());
} catch (Exception var12) {
String details = MoreObjects.toStringHelper(this).add("flinkJobId", newFlinkJobId).add("checkpointId", checkpointId).add("manifestPath", manifest.path()).toString();
LOG.warn("The iceberg transaction has been committed, but we failed to clean the temporary flink manifests: {}", details, var12);
}
}
}
这里会反序列化之前序列化的值,生成deltaManifests,添加到manifests列表中,manifests值:
然后根据replacePartitions(创建时传入的overwrite值,默认为false)值提交事务,默认情况下调用commitDeltaTxn()
private void commitDeltaTxn(NavigableMap<Long, WriteResult> pendingResults, String newFlinkJobId, long checkpointId) {
int deleteFilesNum = pendingResults.values().stream().mapToInt((r) -> {
return r.deleteFiles().length;
}).sum();
Stream var10000;
if (deleteFilesNum == 0) {
AppendFiles appendFiles = this.table.newAppend();
int numFiles = 0;
Iterator var8 = pendingResults.values().iterator();
while(var8.hasNext()) {
WriteResult result = (WriteResult)var8.next();
Preconditions.checkState(result.referencedDataFiles().length == 0, "Should have no referenced data files.");
numFiles += result.dataFiles().length;
var10000 = Arrays.stream(result.dataFiles());
Objects.requireNonNull(appendFiles);
var10000.forEach(appendFiles::appendFile);
}
this.commitOperation(appendFiles, numFiles, 0, "append", newFlinkJobId, checkpointId);
} else {
Iterator var12 = pendingResults.entrySet().iterator();
while(var12.hasNext()) {
Entry<Long, WriteResult> e = (Entry)var12.next();
WriteResult result = (WriteResult)e.getValue();
RowDelta rowDelta = this.table.newRowDelta().validateDataFilesExist(ImmutableList.copyOf(result.referencedDataFiles())).validateDeletedFiles();
int numDataFiles = result.dataFiles().length;
var10000 = Arrays.stream(result.dataFiles());
Objects.requireNonNull(rowDelta);
var10000.forEach(rowDelta::addRows);
int numDeleteFiles = result.deleteFiles().length;
var10000 = Arrays.stream(result.deleteFiles());
Objects.requireNonNull(rowDelta);
var10000.forEach(rowDelta::addDeletes);
this.commitOperation(rowDelta, numDataFiles, numDeleteFiles, "rowDelta", newFlinkJobId, (Long)e.getKey());
}
}
}
创建一个RowDelta的对象rowDelta或MergeAppend的appendFiles,rowDelta的实现类为BaseRowDelta继承自MergingSnapshotProducer作为一个新的snapshot提交;appendFiles的实现类MergeAppend,同样继承MergingSnapshotProducer。
private void commitOperation(SnapshotUpdate<?> operation, int numDataFiles, int numDeleteFiles, String description, String newFlinkJobId, long checkpointId) {
LOG.info("Committing {} with {} data files and {} delete files to table {}", new Object[]{description, numDataFiles, numDeleteFiles, this.table});
operation.set("flink.max-committed-checkpoint-id", Long.toString(checkpointId));
operation.set("flink.job-id", newFlinkJobId);
long start = System.currentTimeMillis();
operation.commit();
long duration = System.currentTimeMillis() - start;
LOG.info("Committed in {} ms", duration);
}
operation.commit()会调用SnapshotProducer中的commit()方法
public void commit() {
AtomicLong newSnapshotId = new AtomicLong(-1L);
try {
Tasks.foreach(new TableOperations[]{this.ops}).retry(this.base.propertyAsInt("commit.retry.num-retries", 4)).exponentialBackoff((long)this.base.propertyAsInt("commit.retry.min-wait-ms", 100), (long)this.base.propertyAsInt("commit.retry.max-wait-ms", 60000), (long)this.base.propertyAsInt("commit.retry.total-timeout-ms", 1800000), 2.0D).onlyRetryOn(CommitFailedException.class).run((taskOps) -> {
Snapshot newSnapshot = this.apply();
newSnapshotId.set(newSnapshot.snapshotId());
TableMetadata updated;
if (this.stageOnly) {
updated = this.base.addStagedSnapshot(newSnapshot);
} else {
updated = this.base.replaceCurrentSnapshot(newSnapshot);
}
if (updated != this.base) {
taskOps.commit(this.base, updated.withUUID());
}
});
} catch (RuntimeException var5) {
Exceptions.suppressAndThrow(var5, this::cleanAll);
}
LOG.info("Committed snapshot {} ({})", newSnapshotId.get(), this.getClass().getSimpleName());
try {
Snapshot saved = this.ops.refresh().snapshot(newSnapshotId.get());
if (saved != null) {
this.cleanUncommitted(Sets.newHashSet(saved.allManifests()));
Iterator var3 = this.manifestLists.iterator();
while(var3.hasNext()) {
String manifestList = (String)var3.next();
if (!saved.manifestListLocation().equals(manifestList)) {
this.deleteFile(manifestList);
}
}
} else {
LOG.warn("Failed to load committed snapshot, skipping manifest clean-up");
}
} catch (RuntimeException var6) {
LOG.warn("Failed to load committed table metadata, skipping manifest clean-up", var6);
}
this.notifyListeners();
}
SnapshotProducer.apply() 方法执行写入manifestFiles数据,返回快照数据;
public Snapshot apply() {
this.base = this.refresh();
Long parentSnapshotId = this.base.currentSnapshot() != null ? this.base.currentSnapshot().snapshotId() : null;
long sequenceNumber = this.base.nextSequenceNumber();
this.validate(this.base);
List<ManifestFile> manifests = this.apply(this.base);
if (this.base.formatVersion() <= 1 && !this.base.propertyAsBoolean("write.manifest-lists.enabled", true)) {
return new BaseSnapshot(this.ops.io(), this.snapshotId(), parentSnapshotId, System.currentTimeMillis(), this.operation(), this.summary(this.base), manifests);
} else {
OutputFile manifestList = this.manifestListPath();
try {
ManifestListWriter writer = ManifestLists.write(this.ops.current().formatVersion(), manifestList, this.snapshotId(), parentSnapshotId, sequenceNumber);
Throwable var7 = null;
try {
this.manifestLists.add(manifestList.location());
ManifestFile[] manifestFiles = new ManifestFile[manifests.size()];
Tasks.range(manifestFiles.length).stopOnFailure().throwFailureWhenFinished().executeWith(ThreadPools.getWorkerPool()).run((index) -> {
manifestFiles[index] = (ManifestFile)this.manifestsWithMetadata.get((ManifestFile)manifests.get(index));
});
writer.addAll(Arrays.asList(manifestFiles));
} catch (Throwable var13) {
var7 = var13;
throw var13;
} finally {
if (writer != null) {
$closeResource(var7, writer);
}
}
} catch (IOException var15) {
throw new RuntimeIOException(var15, "Failed to write manifest list file", new Object[0]);
}
return new BaseSnapshot(this.ops.io(), sequenceNumber, this.snapshotId(), parentSnapshotId, System.currentTimeMillis(), this.operation(), this.summary(this.base), manifestList.location());
}
}
然后生成表的元数据updated
public TableMetadata replaceCurrentSnapshot(Snapshot snapshot) {
if (this.snapshotsById.containsKey(snapshot.snapshotId())) {
return this.setCurrentSnapshotTo(snapshot);
} else {
ValidationException.check(this.formatVersion == 1 || snapshot.sequenceNumber() > this.lastSequenceNumber, "Cannot add snapshot with sequence number %s older than last sequence number %s", new Object[]{snapshot.sequenceNumber(), this.lastSequenceNumber});
List<Snapshot> newSnapshots = ImmutableList.builder().addAll(this.snapshots).add(snapshot).build();
List<HistoryEntry> newSnapshotLog = ImmutableList.builder().addAll(this.snapshotLog).add(new TableMetadata.SnapshotLogEntry(snapshot.timestampMillis(), snapshot.snapshotId())).build();
return new TableMetadata((InputFile)null, this.formatVersion, this.uuid, this.location, snapshot.sequenceNumber(), snapshot.timestampMillis(), this.lastColumnId, this.schema, this.defaultSpecId, this.specs, this.defaultSortOrderId, this.sortOrders, this.properties, snapshot.snapshotId(), newSnapshots, newSnapshotLog, this.addPreviousFile(this.file, this.lastUpdatedMillis));
}
}
调用BaseMetastoreTableOperations算子的commit()方法
public void commit(TableMetadata base, TableMetadata metadata) {
if (base != this.current()) {
throw new CommitFailedException("Cannot commit: stale table metadata", new Object[0]);
} else if (base == metadata) {
LOG.info("Nothing to commit.");
} else {
long start = System.currentTimeMillis();
this.doCommit(base, metadata);
this.deleteRemovedMetadataFiles(base, metadata);
this.requestRefresh();
LOG.info("Successfully committed to table {} in {} ms", this.tableName(), System.currentTimeMillis() - start);
}
}
最后调用HiveTableOperations的doCommit(),执行提交操作。
protected void doCommit(TableMetadata base, TableMetadata metadata) {
String newMetadataLocation = this.writeNewMetadata(metadata, this.currentVersion() + 1);
boolean hiveEngineEnabled = hiveEngineEnabled(metadata, this.conf);
boolean threw = true;
boolean updateHiveTable = false;
Optional lockId = Optional.empty();
try {
lockId = Optional.of(this.acquireLock());
Table tbl = this.loadHmsTable();
if (tbl != null) {
if (base == null && tbl.getParameters().get("metadata_location") != null) {
throw new AlreadyExistsException("Table already exists: %s.%s", new Object[]{this.database, this.tableName});
}
updateHiveTable = true;
LOG.debug("Committing existing table: {}", this.fullName);
} else {
tbl = this.newHmsTable();
LOG.debug("Committing new table: {}", this.fullName);
}
tbl.setSd(this.storageDescriptor(metadata, hiveEngineEnabled));
String metadataLocation = (String)tbl.getParameters().get("metadata_location");
String baseMetadataLocation = base != null ? base.metadataFileLocation() : null;
if (!Objects.equals(baseMetadataLocation, metadataLocation)) {
throw new CommitFailedException("Base metadata location '%s' is not same as the current table metadata location '%s' for %s.%s", new Object[]{baseMetadataLocation, metadataLocation, this.database, this.tableName});
}
this.setParameters(newMetadataLocation, tbl, hiveEngineEnabled);
this.persistTable(tbl, updateHiveTable);
threw = false;
} catch (org.apache.hadoop.hive.metastore.api.AlreadyExistsException var16) {
throw new AlreadyExistsException("Table already exists: %s.%s", new Object[]{this.database, this.tableName});
} catch (UnknownHostException | TException var17) {
if (var17.getMessage() != null && var17.getMessage().contains("Table/View 'HIVE_LOCKS' does not exist")) {
throw new RuntimeException("Failed to acquire locks from metastore because 'HIVE_LOCKS' doesn't exist, this probably happened when using embedded metastore or doesn't create a transactional meta table. To fix this, use an alternative metastore", var17);
}
throw new RuntimeException(String.format("Metastore operation failed for %s.%s", this.database, this.tableName), var17);
} catch (InterruptedException var18) {
Thread.currentThread().interrupt();
throw new RuntimeException("Interrupted during commit", var18);
} finally {
this.cleanupMetadataAndUnlock(threw, newMetadataLocation, lockId);
}
附:flink task执行流程
task的生命周期:
StreamTask是所有stream task的基本类。一个task 运行一个或者多个StreamOperator(如果成chain)。成chain的算子在同一个线程内同步运行。
执行过程:
@Override
public final void invoke() throws Exception {
try {
beforeInvoke();
// final check to exit early before starting to run
if (canceled) {
throw new CancelTaskException();
}
// let the task do its work
runMailboxLoop();
// if this left the run() method cleanly despite the fact that this was canceled,
// make sure the "clean shutdown" is not attempted
if (canceled) {
throw new CancelTaskException();
}
afterInvoke();
}
catch (Exception invokeException) {
try {
cleanUpInvoke();
}
catch (Throwable cleanUpException) {
throw (Exception) ExceptionUtils.firstOrSuppressed(cleanUpException, invokeException);
}
throw invokeException;
}
cleanUpInvoke();
}
在beforeInvoke中会做一些初始化工作,包括提取出所有的operator等。 在runMailboxLoop中调用task运行 在afterInvoke中结束
调用关系:
-- invoke()
* |
* +----> Create basic utils (config, etc) and load the chain of operators
* +----> operators.setup()
* +----> task specific init()
* +----> initialize-operator-states()
* +----> open-operators()
* +----> run()
* --------------> mailboxProcessor.runMailboxLoop();
* --------------> StreamTask.processInput()
* --------------> StreamTask.inputProcessor.processInput()
* --------------> 间接调用 operator的processElement()和processWatermark()方法
* +----> close-operators()
* +----> dispose-operators()
* +----> common cleanup
* +----> task specific cleanup()
创建状态存储后端,为 OperatorChain 中的所有算子提供状态 加载 OperatorChain 中的所有算子 所有的 operator 调用 setup task 相关的初始化操作 所有 operator 调用 initializeState 初始化状态 所有的 operator 调用 open run 方法循环处理数据 所有 operator 调用 close 所有 operator 调用 dispose 通用的 cleanup 操作 task 相关的 cleanup 操作
