
Python+SQL实战:京东用户行为数据分析案例解析(上)
共 14801字,需浏览 30分钟
·
2020-10-26 01:18
1
项目背景
项目对京东电商运营数据集进行指标分析以了解用户购物行为特征,为运营决策提供支持建议。本文采用了MySQL和Python两种代码进行指标计算以适应不同的数据分析开发环境。
2
数据集介绍
本数据集为京东竞赛数据集,详细介绍请访问链接:
https://jdata.jd.com/html/detail.html?id=8
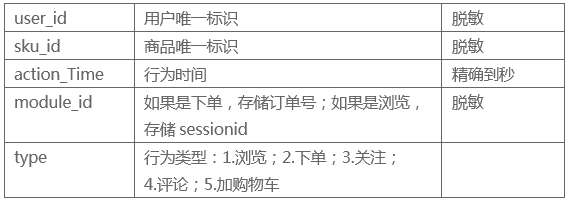
数据集共有五个文件,包含了'2018-02-01'至'2018-04-15'之间的用户数据,数据已进行了脱敏处理,本文使用了其中的行为数据表,表中共有五个字段,各字段含义如下图所示:
3
数据清洗
# 导入python相关模块
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from datetime import datetime
plt.style.use('ggplot')
%matplotlib inline
# 设置中文编码和负号的正常显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False# 读取数据,数据集较大,如果计算机读取内存不够用,可以尝试kaggle比赛
# 中的reduce_mem_usage函数,附在文末,主要原理是把int64/float64
# 类型的数值用更小的int(float)32/16/8来搞定
user_action = pd.read_csv('jdata_action.csv')# 因数据集过大,本文截取'2018-03-30'至'2018-04-15'之间的数据完成本次分析
# 注:仅4月份的数据包含加购物车行为,即type == 5
user_data = user_action[(user_action['action_time'] > '2018-03-30') & (user_action['action_time'] < '2018-04-15')]# 存至本地备用
user_data.to_csv('user_data.csv',sep=',')# 查看原始数据各字段类型
behavior = pd.read_csv('user_data.csv', index_col=0)
behavior[:10]# OUTPUT
user_id sku_id action_time module_id type
17 1455298 208441 2018-04-11 15:21:43 6190659 1
18 1455298 334318 2018-04-11 15:14:54 6190659 1
19 1455298 237755 2018-04-11 15:14:13 6190659 1
20 1455298 6422 2018-04-11 15:22:25 6190659 1
21 1455298 268566 2018-04-11 15:14:26 6190659 1
22 1455298 115915 2018-04-11 15:13:35 6190659 1
23 1455298 208254 2018-04-11 15:22:16 6190659 1
24 1455298 177209 2018-04-14 14:09:59 6628254 1
25 1455298 71793 2018-04-14 14:10:29 6628254 1
26 1455298 141950 2018-04-12 15:37:53 10207258 1behavior.info()# OUTPUT
'pandas.core.frame.DataFrame'>
Int64Index: 7540394 entries, 17 to 37214234
Data columns (total 5 columns):
user_id int64
sku_id int64
action_time object
module_id int64
type int64
dtypes: int64(4), object(1)
memory usage: 345.2+ MB # 查看缺失值
behavior.isnull().sum()# OUTPUT
user_id 0
sku_id 0
action_time 0
module_id 0
type 0
dtype: int64数据各列无缺失值。
# 原始数据中时间列action_time,时间和日期是在一起的,不方便分析,对action_time列进行处理,拆分出日期和时间列,并添加星期字段求出每天对应
# 的星期,方便后续按时间纬度对数据进行分析
behavior['date'] = pd.to_datetime(behavior['action_time']).dt.date # 日期
behavior['hour'] = pd.to_datetime(behavior['action_time']).dt.hour # 时间
behavior['weekday'] = pd.to_datetime(behavior['action_time']).dt.weekday_name # 周# 去除与分析无关的列
behavior = behavior.drop('module_id', axis=1)# 将用户行为标签由数字类型改为用字符表示
behavior_type = {1:'pv',2:'pay',3:'fav',4:'comm',5:'cart'}
behavior['type'] = behavior['type'].apply(lambda x: behavior_type[x])
behavior.reset_index(drop=True,inplace=True)# 查看处理好的数据
behavior[:10]# OUTPUT
user_id sku_id action_time type date hour weekday
0 1455298 208441 2018-04-11 15:21:43 pv 2018-04-11 15 Wednesday
1 1455298 334318 2018-04-11 15:14:54 pv 2018-04-11 15 Wednesday
2 1455298 237755 2018-04-11 15:14:13 pv 2018-04-11 15 Wednesday
3 1455298 6422 2018-04-11 15:22:25 pv 2018-04-11 15 Wednesday
4 1455298 268566 2018-04-11 15:14:26 pv 2018-04-11 15 Wednesday
5 1455298 115915 2018-04-11 15:13:35 pv 2018-04-11 15 Wednesday
6 1455298 208254 2018-04-11 15:22:16 pv 2018-04-11 15 Wednesday
7 1455298 177209 2018-04-14 14:09:59 pv 2018-04-14 14 Saturday
8 1455298 71793 2018-04-14 14:10:29 pv 2018-04-14 14 Saturday
9 1455298 141950 2018-04-12 15:37:53 pv 2018-04-12 15 Thursday4
分析模型构建分析指标
1.流量指标分析
pv、uv、消费用户数占比、消费用户总访问量占比、消费用户人均访问量、跳失率
PV UV
# 总访问量
pv = behavior[behavior['type'] == 'pv']['user_id'].count()
# 总访客数
uv = behavior['user_id'].nunique()
# 消费用户数
user_pay = behavior[behavior['type'] == 'pay']['user_id'].unique()
# 日均访问量
pv_per_day = pv / behavior['date'].nunique()
# 人均访问量
pv_per_user = pv / uv
# 消费用户访问量
pv_pay = behavior[behavior['user_id'].isin(user_pay)]['type'].value_counts().pv
# 消费用户数占比
user_pay_rate = len(user_pay) / uv
# 消费用户访问量占比
pv_pay_rate = pv_pay / pv
# 消费用户人均访问量
pv_per_buy_user = pv_pay / len(user_pay)# SQL
SELECT count(DISTINCT user_id) UV,
(SELECT count(*) PV from behavior_sql WHERE type = 'pv') PV
FROM behavior_sql;
SELECT count(DISTINCT user_id)
FROM behavior_sql
WHERE WHERE type = 'pay';
SELECT type, COUNT(*) FROM behavior_sql
WHERE
user_id IN
(SELECT DISTINCT user_id
FROM behavior_sql
WHERE type = 'pay')
AND type = 'pv'
GROUP BY type;print('总访问量为 %i' %pv)
print('总访客数为 %i' %uv)
print('消费用户数为 %i' %len(user_pay))
print('消费用户访问量为 %i' %pv_pay)
print('日均访问量为 %.3f' %pv_per_day)
print('人均访问量为 %.3f' %pv_per_user)
print('消费用户人均访问量为 %.3f' %pv_per_buy_user)
print('消费用户数占比为 %.3f%%' %(user_pay_rate * 100))
print('消费用户访问量占比为 %.3f%%' %(pv_pay_rate * 100))# OUTPUT
总访问量为 6229177
总访客数为 728959
消费用户数为 395874
消费用户访问量为 3918000
日均访问量为 389323.562
人均访问量为 8.545
消费用户人均访问量为 9.897
消费用户数占比为 54.307%
消费用户访问量占比为 62.898%消费用户人均访问量和总访问量占比都在平均值以上,有过消费记录的用户更愿意在网站上花费更多时间,说明网站的购物体验尚可,老用户对网站有一定依赖性,对没有过消费记录的用户要让快速了解产品的使用方法和价值,加强用户和平台的黏连。
跳失率
# 跳失率:只进行了一次操作就离开的用户数/总用户数
attrition_rates = sum(behavior.groupby('user_id')['type'].count() == 1) / (behavior['user_id'].nunique())# SQL
SELECT
(SELECT COUNT(*)
FROM (SELECT user_id
FROM behavior_sql GROUP BY user_id
HAVING COUNT(type)=1) A) /
(SELECT COUNT(DISTINCT user_id) UV FROM behavior_sql) attrition_rates;print('跳失率为 %.3f%%' %(attrition_rates * 100) )# OUTPUT
跳失率为 22.585%整个计算周期内跳失率为22.585%,还是有较多的用户仅做了单次操作就离开了页面,需要从首页页面布局以及产品用户体验等方面加以改善,提高产品吸引力。
2. 用户消费频次分析
# 单个用户消费总次数
total_buy_count = (behavior[behavior['type']=='pay'].groupby(['user_id'])['type'].count()
.to_frame().rename(columns={'type':'total'}))
# 消费次数前10客户
topbuyer10 = total_buy_count.sort_values(by='total',ascending=False)[:10]
# 复购率
re_buy_rate = total_buy_count[total_buy_count>=2].count()/total_buy_count.count()# SQL
#消费次数前10客户
SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = 'pay'
GROUP BY user_id
ORDER BY COUNT(type) DESC
LIMIT 10
#复购率
CREAT VIEW v_buy_count
AS SELECT user_id, COUNT(type) total_buy_count
FROM behavior_sql
WHERE type = 'pay'
GROUP BY user_id;
SELECT CONCAT(ROUND((SUM(CASE WHEN total_buy_count>=2 THEN 1 ELSE 0 END)/
SUM(CASE WHEN total_buy_count>0 THEN 1 ELSE 0 END))*100,2),'%') AS re_buy_rate
FROM v_buy_count;topbuyer10.reset_index().style.bar(color='skyblue',subset=['total'])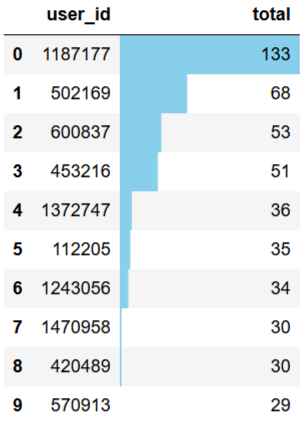
# 单个用户消费总次数可视化
tbc_box = total_buy_count.reset_index()
fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale("log")
sns.countplot(x=tbc_box['total'],data=tbc_box,palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(tbc_box['total'])), (p.get_x() - 0.1, p.get_height()))
plt.title('用户消费总次数')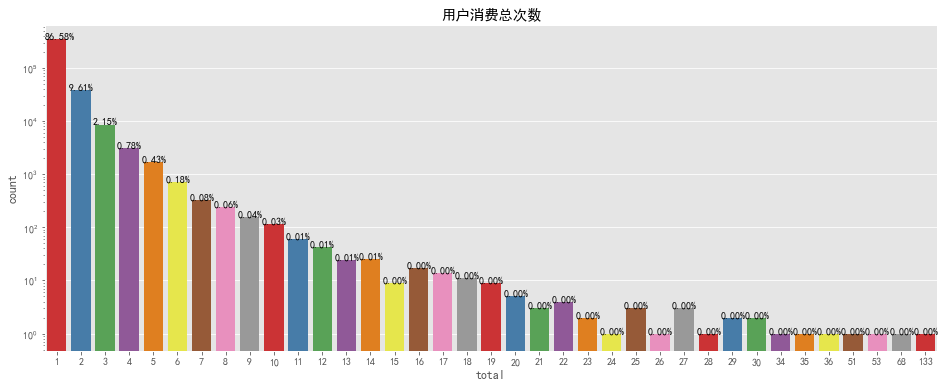
整个计算周期内,最高购物次数为133次,最低为1次,大部分用户的购物次数在6次以下,可适当增加推广,完善购物体验,提高用户消费次数。购物次数前10用户为1187177、502169等,应提高其满意度,增大留存率。
print('复购率为 %.3f%%' %(re_buy_rate * 100) )# OUTPUT
复购率为 13.419%复购率较低,应加强老用户召回机制,提升购物体验,也可能因数据量较少,统计周期之内的数据 无法解释完整的购物周期,从而得出结论有误。
3. 用户行为在时间纬度的分布
日消费次数、日活跃人数、日消费人数、日消费人数占比、消费用户日人均消费次数
# 日活跃人数(有一次操作即视为活跃)
daily_active_user = behavior.groupby('date')['user_id'].nunique()
# 日消费人数
daily_buy_user = behavior[behavior['type'] == 'pay'].groupby('date')['user_id'].nunique()
# 日消费人数占比
proportion_of_buyer = daily_buy_user / daily_active_user
# 日消费总次数
daily_buy_count = behavior[behavior['type'] == 'pay'].groupby('date')['type'].count()
# 消费用户日人均消费次数
consumption_per_buyer = daily_buy_count / daily_buy_user# SQL
# 日消费总次数
SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date;
# 日活跃人数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;
# 日消费人数
SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date;
# 日消费人数占比
SELECT
(SELECT date, COUNT(DISTINCT user_id) user_pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)
# 日人均消费次数
SELECT
(SELECT date, COUNT(type) pay_daily FROM behavior_sql
WHERE type = 'pay'
GROUP BY date) /
(SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date)# 日消费人数占比可视化
# 柱状图数据
pob_bar = (pd.merge(daily_active_user,daily_buy_user,on='date').reset_index()
.rename(columns={'user_id_x':'日活跃人数','user_id_y':'日消费人数'})
.set_index('date').stack().reset_index().rename(columns={'level_1':'Variable',0: 'Value'}))
# 线图数据
pob_line = proportion_of_buyer.reset_index().rename(columns={'user_id':'Rate'})
fig1 = plt.figure(figsize=[16,6])
ax1 = fig1.add_subplot(111)
ax2 = ax1.twinx()
sns.barplot(x='date', y='Value', hue='Variable', data=pob_bar, ax=ax1, alpha=0.8, palette='husl')
ax1.legend().set_title('')
ax1.legend().remove()
sns.pointplot(pob_line['date'], pob_line['Rate'], ax=ax2,markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,pob_line['Rate']):
plt.text(a+0.1, b + 0.001, '%.2f%%' % (b*100), ha='center', va= 'bottom',fontsize=12)
fig1.legend(loc='upper center',ncol=2)
plt.title('日消费人数占比')
日活跃人数与日消费人数无明显波动,日消费人数占比均在20%以上。
# 消费用户日人均消费次数可视化
# 柱状图数据
cpb_bar = (daily_buy_count.reset_index().rename(columns={'type':'Num'}))
# 线图数据
cpb_line = (consumption_per_buyer.reset_index().rename(columns={0:'Frequency'}))
fig2 = plt.figure(figsize=[16,6])
ax3 = fig2.add_subplot(111)
ax4 = ax3.twinx()
sns.barplot(x='date', y='Num', data=cpb_bar, ax=ax3, alpha=0.8, palette='pastel')
sns.pointplot(cpb_line['date'], cpb_line['Frequency'], ax=ax4, markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,cpb_line['Frequency']):
plt.text(a+0.1, b + 0.001, '%.2f' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('消费用户日人均消费次数')
日消费人数在25000以上,日人均消费次数大于1次。
dau3_df = behavior.groupby(['date','user_id'])['type'].count().reset_index()
dau3_df = dau3_df[dau3_df['type'] >= 3]# 每日高活跃用户数(每日操作数大于3次)
dau3_num = dau3_df.groupby('date')['user_id'].nunique()# SQL
SELECT date, COUNT(DISTINCT user_id)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY date;fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(dau3_num.index, dau3_num.values, markers='D', linestyles='--',color='teal')
x=list(range(0,16))
for a,b in zip(x,dau3_num.values):
plt.text(a+0.1, b + 300 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日高活跃用户数')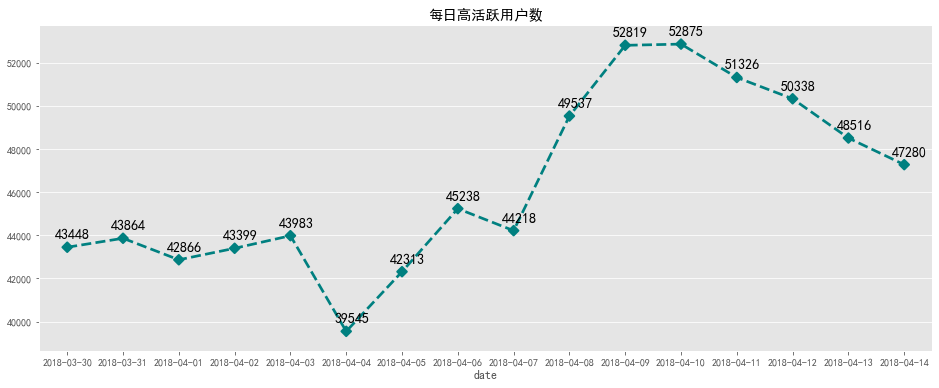
每日高活跃用户数在大部分4万以上,2018-04-04之前数量比较平稳,之后数量一直攀升,8号9号达到最高,随后下降,推测数据波动应为营销活动产生的。
# 高活跃用户累计活跃天数分布
dau3_cumsum = dau3_df.groupby('user_id')['date'].count()# SQL
SELECT user_id, COUNT(date)
FROM
(SELECT date, user_id, COUNT(type)
FROM behavior_sql
GROUP BY date, user_id
HAVING COUNT(type) >= 3) dau3
GROUP BY user_id;fig, ax = plt.subplots(figsize=[16,6])
ax.set_yscale("log")
sns.countplot(dau3_cumsum.values,palette='Set1')
for p in ax.patches:
ax.annotate('{:.2f}%'.format(100*p.get_height()/len(dau3_cumsum.values)), (p.get_x() + 0.2, p.get_height() + 100))
plt.title('高活跃用户累计活跃天数分布')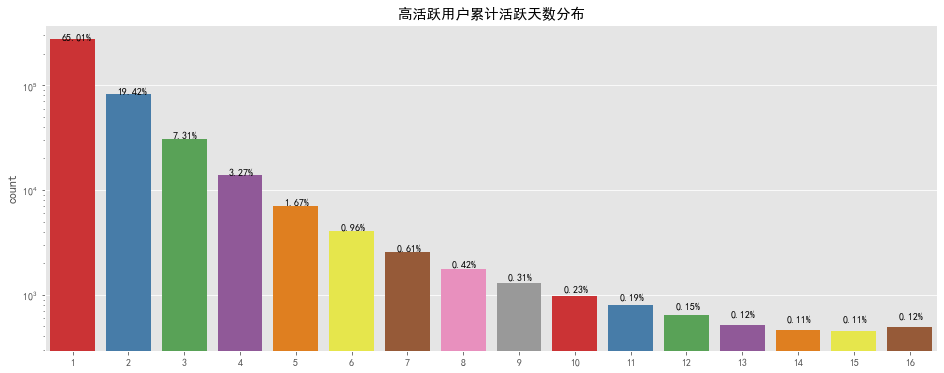
统计周期内,大部分高活跃用户累计活跃天数在六天以下,但也存在高达十六天的超级活跃用户数量,对累计天数较高的用户要推出连续登录奖励等继续维持其对平台的黏性,对累计天数较低的用户要适当进行推送活动消息等对其进行召回。
#每日浏览量
pv_daily = behavior[behavior['type'] == 'pv'].groupby('date')['user_id'].count()
#每日访客数
uv_daily = behavior.groupby('date')['user_id'].nunique()# SQL
#每日浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = 'pv'
GROUP BY date;
#每日访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY date;# 每日浏览量可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_daily.index, pv_daily.values,markers='D', linestyles='--',color='dodgerblue')
x=list(range(0,16))
for a,b in zip(x,pv_daily.values):
plt.text(a+0.1, b + 2000 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日浏览量')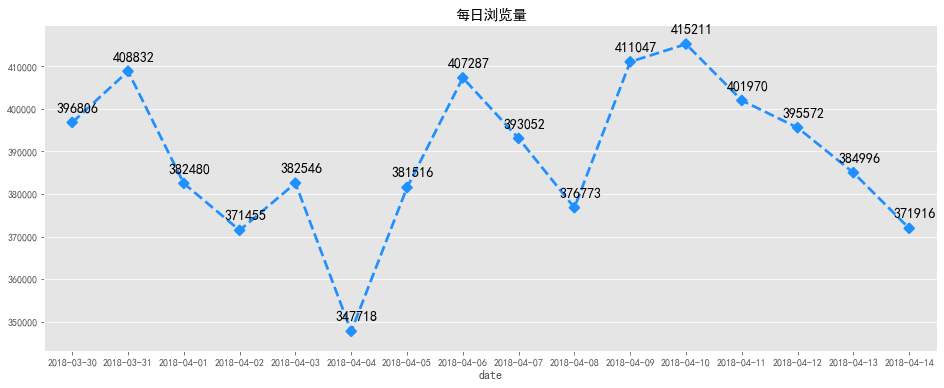
# 每日访客数可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_daily.index, uv_daily.values, markers='H', linestyles='--',color='m')
x=list(range(0,16))
for a,b in zip(x,uv_daily.values):
plt.text(a+0.1, b + 500 , '%i' % b, ha='center', va= 'bottom',fontsize=14)
plt.title('每日访客数')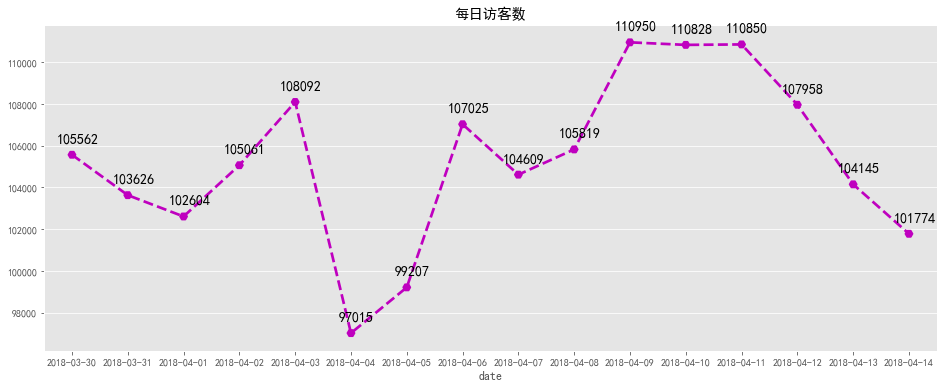
浏览量和访客数每日变化趋势大致相同,2018-04-04日前后用户数量变化波动较大,4月4日为清明节假日前一天,各数据量在当天均有明显下降,但之后逐步回升,推测应为节假日营销活动或推广拉新活动带来的影响。
#每时浏览量
pv_hourly = behavior[behavior['type'] == 'pv'].groupby('hour')['user_id'].count()
#每时访客数
uv_hourly = behavior.groupby('hour')['user_id'].nunique()# SQL
# 每时浏览量
SELECT date, COUNT(type) pv_daily FROM behavior_sql
WHERE type = 'pv'
GROUP BY hour;
# 每时访客数
SELECT date, COUNT(DISTINCT user_id) uv_daily FROM behavior_sql
GROUP BY hour;# 浏览量随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(pv_hourly.index, pv_hourly.values, markers='H', linestyles='--',color='dodgerblue')
for a,b in zip(pv_hourly.index,pv_hourly.values):
plt.text(a, b + 10000 , '%i' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('浏览量随小时变化')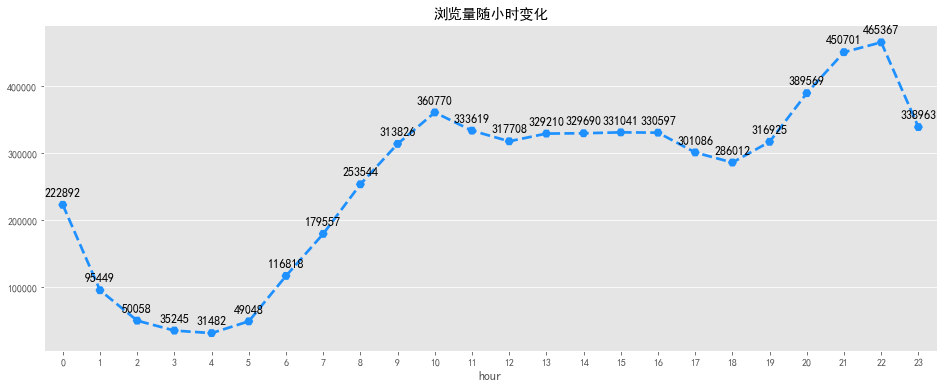
# 访客数随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(uv_hourly.index, uv_hourly.values, markers='H', linestyles='--',color='m')
for a,b in zip(uv_hourly.index,uv_hourly.values):
plt.text(a, b + 1000 , '%i' % b, ha='center', va= 'bottom',fontsize=12)
plt.title('访客数随小时变化')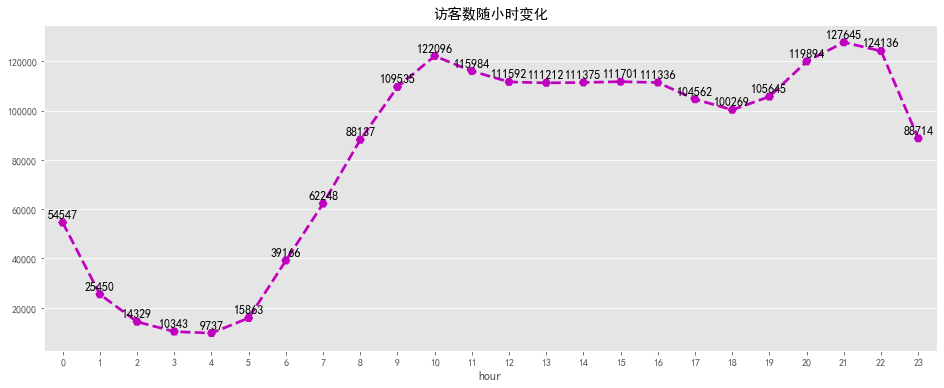
浏览量及访客数随小时变化趋势一致,在凌晨1点到凌晨5点之间,大部分用户正在休息,整体活跃度较低。凌晨5点到10点用户开始起床工作,活跃度逐渐增加,之后趋于平稳,下午6点之后大部分人恢复空闲,浏览量及访客数迎来了第二波攀升,在晚上8点中到达高峰,随后逐渐下降。可以考虑在上午9点及晚上8点增大商品推广力度,加大营销活动投入,可取的较好的收益,1点到5点之间适合做系统维护。
# 用户各操作随小时变化
type_detail_hour = pd.pivot_table(columns = 'type',index = 'hour', data = behavior,aggfunc=np.size,values = 'user_id')
# 用户各操作随星期变化
type_detail_weekday = pd.pivot_table(columns = 'type',index = 'weekday', data = behavior,aggfunc=np.size,values = 'user_id')
type_detail_weekday = type_detail_weekday.reindex(['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'])# SQL
# 用户各操作随小时变化
SELECT hour,
SUM(CASE WHEN behavior='pv' THEN 1 ELSE 0 END)AS 'pv',
SUM(CASE WHEN behavior='fav' THEN 1 ELSE 0 END)AS 'fav',
SUM(CASE WHEN behavior='cart' THEN 1 ELSE 0 END)AS 'cart',
SUM(CASE WHEN behavior='pay' THEN 1 ELSE 0 END)AS 'pay'
FROM behavior_sql
GROUP BY hour
ORDER BY hour
# 用户各操作随星期变化
SELECT weekday,
SUM(CASE WHEN behavior='pv' THEN 1 ELSE 0 END)AS 'pv',
SUM(CASE WHEN behavior='fav' THEN 1 ELSE 0 END)AS 'fav',
SUM(CASE WHEN behavior='cart' THEN 1 ELSE 0 END)AS 'cart',
SUM(CASE WHEN behavior='pay' THEN 1 ELSE 0 END)AS 'pay'
FROM behavior_sql
GROUP BY weekday
ORDER BY weekdaytdh_line = type_detail_hour.stack().reset_index().rename(columns={0: 'Value'})
tdw_line = type_detail_weekday.stack().reset_index().rename(columns={0: 'Value'})
tdh_line= tdh_line[~(tdh_line['type'] == 'pv')]
tdw_line= tdw_line[~(tdw_line['type'] == 'pv')]# 用户操作随小时变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x='hour', y='Value', hue='type', data=tdh_line, linestyles='--')
plt.title('用户操作随小时变化')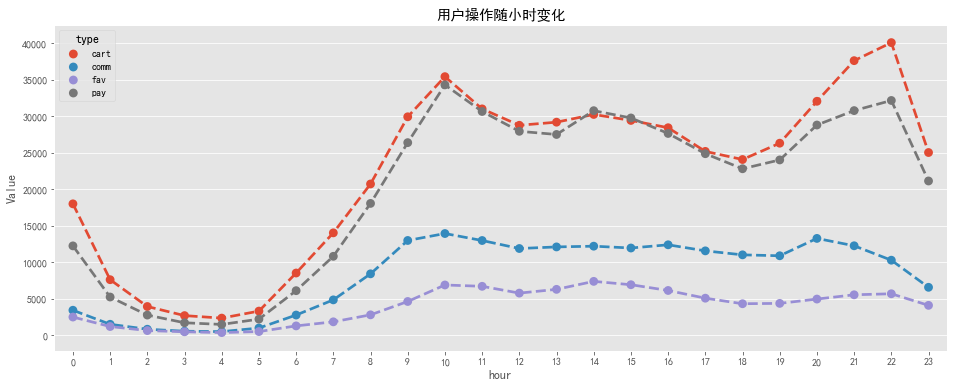
用户操作随小时变化规律与PV、UV随小时规律相似,与用户作息规律相关,加入购物车和付款两条曲线贴合比比较紧密,说明大部分用户习惯加入购物车后直接购买。
关注数相对较少,可以根据用户购物车内商品进行精准推送。评论数也相对较少,说明大部分用户不是很热衷对购物体验进行反馈,可以设置一些奖励制度提高用户评论数,增大用用户粘性。
# 用户操作随星期变化可视化
fig, ax = plt.subplots(figsize=[16,6])
sns.pointplot(x='weekday', y='Value', hue='type', data=tdw_line[~(tdw_line['type'] == 'pv')], linestyles='--')
plt.title('用户操作随星期变化')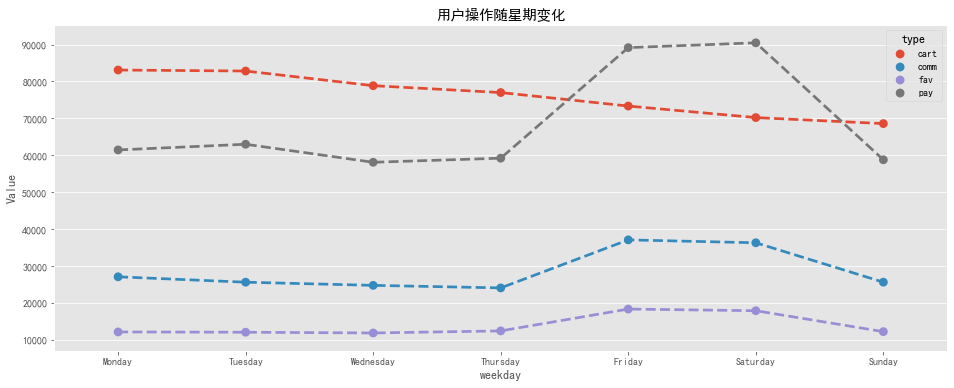
周一到周四工作日期间,用户操作随星期变化比较平稳,周五至周六进入休息日,用户操作明显增多,周日又恢复正常。
- END -
本文为转载分享&推荐阅读,若侵权请联系后台删除