一个小小emoji尽然牵扯出来这么多东西?

前言
商品评价列表页,显示每条用户的评价详情,为了保护用户隐私,要求显示用户昵称时只能显示第一位和最后一位,其他的用※代替。
例如输入:???,输出:?***?
看似一个平淡无奇的需求,我也没有太在意。服务端将用户的评论信息存储到db中,评价列表接口就是将数据库中该商品的评论信息展示出来,特殊处理下评论人的昵称就可以了。
但是!! 测试同学发现用户昵称包含emoji表情时就会出问题,切割的数据会有问号显示!!
模拟的示例代码如下:
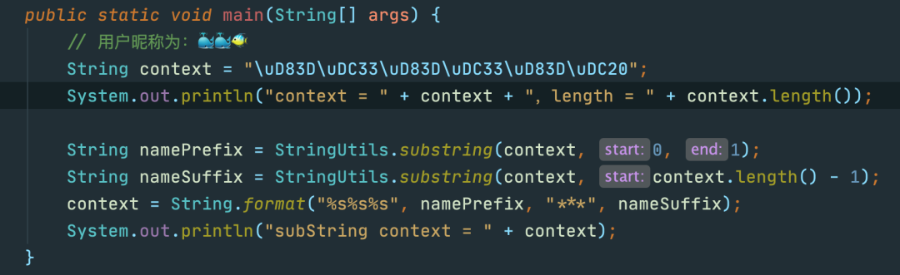
输出:

看到这个输出,我真的是一脸懵逼,这完全不是我想要的结果呀!!!
这三个鱼可算是难倒我了,难道只能给测试说 emoji太特殊 不予处理?然后撒个娇蒙混过关?
思考了良久,我还是决定要正视这个问题并解决掉它!(毕竟我还是那个不畏困难的小机灵鬼?)
PS:本文很大程度是受到之前公司一位同事unicode分享的启发,在这里向我的这位老师致敬!下面的内容会一步步分析这个问题的产生以及最终的解决方案。
概念常识
要解决这些问题,就必须要铺垫一些基础知识,大家等不及看解决方案 可以拉到文章最后的代码示例。
utf8mb4
一般我们在数据库创建表时都会默认使用这种编码格式:
相信大家对这个编码格式都不陌生吧,当我们想存储emoji数据到数据库中,那么数据库的格式就需要指定为utf8mb4了,要不然存储就会报错了。所以在很多公司的db规范中,数据库默认编码必须为utf8mb4
但是大家有没有过这样的疑惑,为何utf8不行而utf8mb4就行?这里面到底有什么弯弯道道?
这里面涉及到unicode相关知识,我们下面会提到,大家继续看。
在mysql 5.5 之前,utf8编码只支持1-3个字节,从mysql 5.5开始,可支持4个字节UTF编码utf8mb4,一个字符最多能有4字节,所以能支持更多的字符集。
这个表格中包含了所有的 emoji 以及它所对应的 unicode编码,同时也有对应的 utf-8编码的实现。
从图中也可以看出 emoji 表情用 utf-8 表示时会占用 4个字节,这也就是为什么数据库用utf8无法存储emoji表情的原因了。
同样我们也可以在java代码中看看emoji占用几个字节长度:
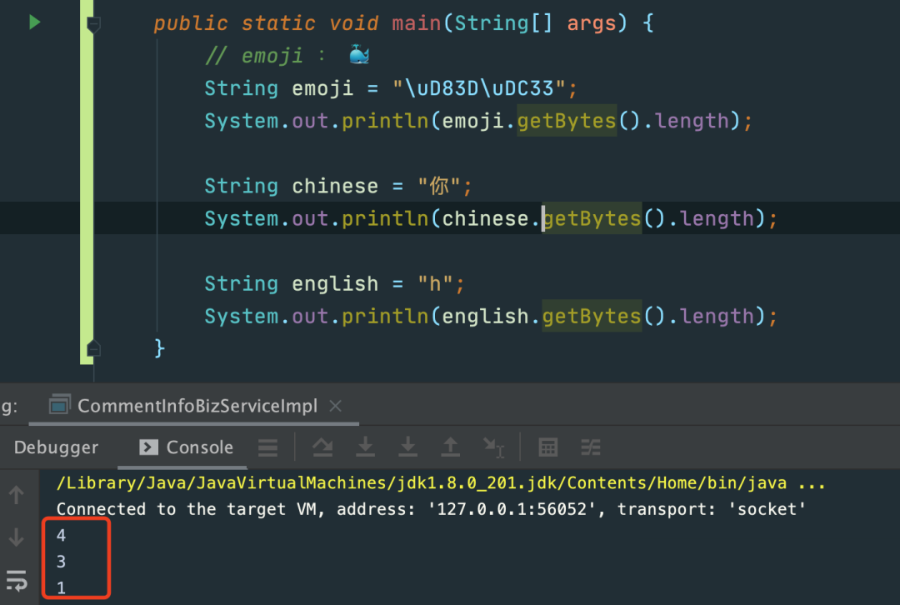
我们也可以看到String.getBytes(),默认是utf-8编码的:
ASCII码
上面介绍utf8mb4时有提过unicode,介绍它之前我们也需要先提一嘴我们的老朋友:ASCII码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语。
这样我们就可以使用一个字节来表示现代英文,看起来非常不错,部分数据对应关系如下:
但这个只能显示的代表拉丁文,这显然是远远不够的。
Unicode
显而易见,计算机的发展并不是只支持英文一种语言的,ASCII的局限在于只能显示26个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语。
这时如果能有一种包含了世界上所有的文字的字符集,每一个地区的文字都在这个字符集中有唯一的二进制表示,这样便不会出现乱码问题了。所以Unicode也应运而生了。
概念
Unicode,中文又称万国码、国际码、统一码、单一码,是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
平面
Unicode 首先承认了 ASCII 占用 0-127 整数资源的合法性,之后又一次占用了 128-65535 的整数资源,有了这么多的整数资源,我们就可以把世界各种文字的每一种字符分配一个整数来表示了。
之后,Unicode 联盟发现 65536 个整数也不够分配的,于是就索性一次性又把之后的 16 个 65536 的数字即 65536-1114111 的整数资源给占了,然后把多占的 16 个 65536 的段分别命名为 16 个平面,加上原来的 0-65535 平面,Unicode 总共有 17 个平面。比如第 1 平面就是 65536-131072。当然,到目前为止,还只分配了 7 个平面出去。
第0平面(Plane 0),是Unicode中的一个编码区段。编码从U+0000至U+FFFF,这个平面里面的字符是我们最常用到的。
65535 之后分配的字符大多数是 emoji 表情,比如 ? 是 128570(\uD83D\uDE3A)
这里推荐一个在线的编码转换网站:http://ctf.ssleye.com/cencode.html
表示范围
Unicode表示范围:U+0000 ~ U+10FFFF
也就大概是:U+0000~U+110000(加上1),也就是17个FFFF(65535) 差不多17*6w,大概有100w个码点可以用来映射字符 准确的值是 1114,112,差不多112w个码点 最新版本的Unicode含有136,690 个字符,离100w还很远。 Unicode 官方表示目前的码点已经够用,以后不再扩充
实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
对于被Unicode收录的字符其编码是唯一且确定的。但是Unicode的实现方式(出于传输、存储、处理或向后兼容的考虑)却有不同的几种,其中最流行的是UTF-8、UTF-16、UCS2、UCS4/UTF-32等,细分的话还有大小端的区别。
对于我们Java而言,可以从char占用2字节来推断出使用的是UTF-16编码来存储
对于各种编码问题推荐一篇好文:深入分析 Java 中的中文编码问题(https://developer.ibm.com/zh/articles/j-lo-chinesecoding/)
判断是否包含中文
上面大概了解了Unicode的含义及用途,那么了解这个玩意有什么实际作用呢?
我们再来看一个小的需求,比如:如何判断一个字符串中包含中文?
相信大家也遇到过这种需求吧,一般我们都会去百度一通,一定都能找到一个判断是否包含中文的正则表达式,然后满心欢喜解决了问题。
恰巧我们系统中也有这么一个正则判断,是架构组的同事封装好的,一起来看下:
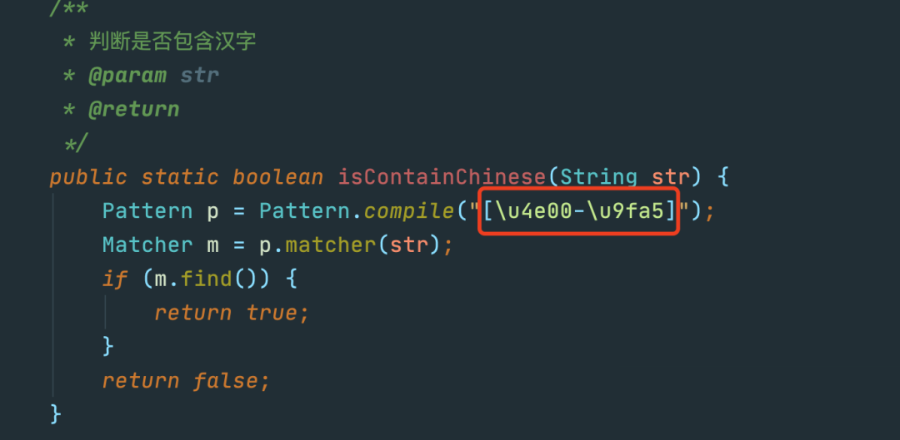
显然,这里是通过Unicode区间去判断的,有没有问题呢?
这里的区间是用的中日韩统一表意文字,但是这个是1993年的版本,包含了大部分我们常用的中文,共有20902个字,看到后面补充的版本,还添加了很多字,由此可想像我们现在使用的判断方式肯定会漏掉后添加的字:
我们用2000年增加的中日韩统一表意文字扩展区A 来举例测试一下:
这里加了很多生僻字,甚至都没有我认识的,我们用第二排的数据来做一个验证:
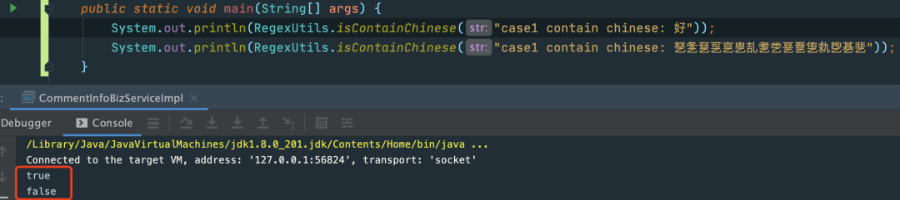
看到这里是不是很惊讶?并高呼你们这里写了一个bug,哈哈。
其实这里并不能说我们的正则判断有bug,这个需要看我们的需求是否精准到所有的生僻词都得识别到。根据用户的使用习惯,输入这些生僻字的概率不是很高,所以这个正则并没有小伙伴反馈有问题。
解决emoji截取的问题
言归正传,我们终究还是要解决开头提出的问题,如何正确的截取含有emoji的字符串?这里从UTF-16编码开始说起。
UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
在基本多语言平面(码位范围U+0000-U+FFFF)内的码位UTF-16编码使用1个码元且其值与Unicode是相等的(不需要转换),这个就是我们正常的汉字,比如在辅助平面(码位范围U+10000-U+10FFFF)内的码位在UTF-16中被编码为一对16bit的码元(即32bit,4字节),称作代理对(surrogate pair)。组成代理对的两个码元前一个称为 前导代理(lead surrogates) 范围为0xD800-0xDBFF,后一个称为 后尾代理(trail surrogates) 范围为0xDC00-0xDFFF
surrogate
上面有提到surrogate,surrogate是代理的意思, 这个概念不是来自 Java 语言,而是来自 Unicode 编码方式之一 UTF-16。具体请见:https://zh.wikipedia.org/wiki/UTF-16
简而言之,Java 语言内部的字符信息是使用 UTF-16 编码。因为char 这个类型是 16-bit 的。它可以有65536种取值,即65536个编号,每个编号可以代表1种字符。但是,Unicode 包含的字符已经远远超过65536个。那么编号大于65536的,还要用 16-bit 编码,该怎么办?于是Unicode 标准制定组想出的办法就是,从这65536个编号里,拿出2048个,规定它们是「Surrogates」,让它们两个为一组,来代表编号大于65536的那些字符。
更具体地,编号为 U+D800 至 U+DBFF 的规定为「High Surrogates」,共1024个。编号为 U+DC00至 U+DFFF 的规定为「Low Surrogates」,也是1024个。它们两两组合出现,就又可以多表示1048576种字符。
emoji截取异常原因
上面都是一些概念性的知识,如果硬看确实容易懵,我们还是回过头看一下吧,从代码入手:

我们可以把emoji分离出来,如下:
? -> \uD83D\uDC33
? -> \uD83D\uDC33
? -> \uD83D\uDC20
emoji肯定是大于65536的,所以这里就用「High Surrogates」和「Low Surrogates」两两组合的方式来呈现的。
由上面的UTF-16编码知识可以推断出,我们的emoji表情截取一个char后出现乱码的原因,是因为它是属于UTF-16编码辅助平面内的代理对,而我们如果截取时将代理对拆分开 就会出现异常的问题。
对于这种情况,我们可以通过Character类的静态方法isHighSurrogate和isLowSurrogate来判断,单个emoji的组合就是高位+低位,所以对于辅助平面内的代理对,做到整个移除或保留即可。
isHighSurrogate方法的源码如下:
public static final char MIN_HIGH_SURROGATE = '\uD800';
public static final char MAX_HIGH_SURROGATE = '\uDBFF';
public static boolean isHighSurrogate(char ch) {
return ch >= MIN_HIGH_SURROGATE && ch < (MAX_HIGH_SURROGATE + 1);
}
这个判断其实就是上面说的「High Surrogates」的判定方式,我们可以转换一下:
U+D800 <= ch <= U+DBFF
同理,isLowSurrogate方法的判定方式也是一样的:
U+DC00 <= ch <= U+DFFF
问题解决
还是先运行一下代码,看看效果:
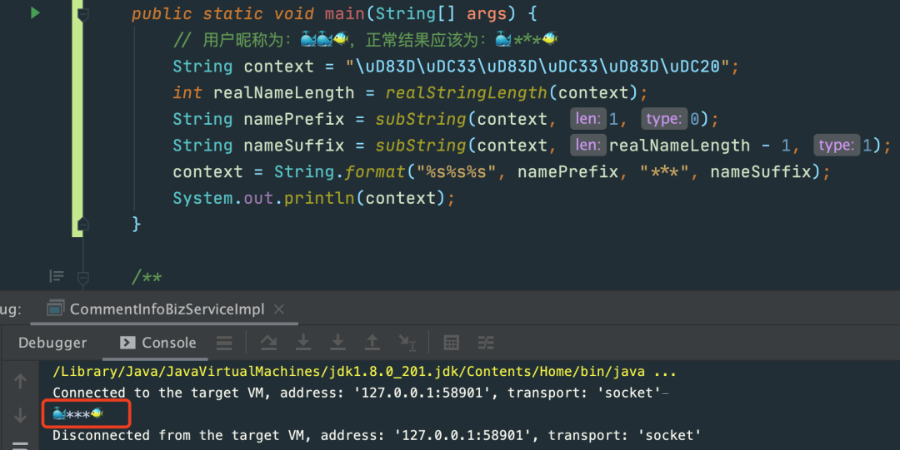
具体实现代码如下:
public static void main(String[] args) {
// 用户昵称为:???,正常结果应该为:?***?
String context = "\uD83D\uDC33\uD83D\uDC33\uD83D\uDC20";
int realNameLength = realStringLength(context);
String namePrefix = subString(context, 1, 0);
String nameSuffix = subString(context, realNameLength - 1, 1);
context = String.format("%s%s%s", namePrefix, "***", nameSuffix);
System.out.println(context);
}
/**
* 包含emoji表情的subString方法
*
* @param str 原有的str
* @param len str长度
* @param type type = 0 代表prefix,其他代表suffix
*/
private static String subString(String str, int len, int type) {
if (len < 0) {
return str;
}
int count = 0;
for (int i = 0; i < str.length(); i++) {
if (count == len) {
// type = 0 代表prefix,其他代表suffix
if (type == 0) {
return str.substring(0, i);
}
return str.substring(i);
}
char c = str.charAt(i);
if (Character.isHighSurrogate(c) || Character.isLowSurrogate(c)) {
i++;
}
count++;
}
return str;
}
/**
* 包含emoji表情的字符串实际长度
*
* @param str 原有str
* @return str实际长度
*/
private static int realStringLength(String str) {
int count = 0;
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
if (Character.isHighSurrogate(c) || Character.isLowSurrogate(c)) {
i++;
}
count++;
}
return count;
}
总结
一个小小的emoji真是学问无穷,由于篇幅的问题我这里还省略了很多东西,比如UTF-8和UTF-16两种编码形式并没有深入讲解,这里面又会牵扯到很多内容。
我希望这篇文章能够做到一个抛砖引玉的作用,激发小伙伴们一起去探究更多的奥秘。