《ABCNet》文本识别
共 2419字,需浏览 5分钟
·
2022-02-09 17:41
《ABCNet:Real-time Scene Text Spotting with Adaptive Bezier-Curve Network》-- 2020CVPR
补充知识点:
伯恩斯坦多项式(Bernstein polynomials):是逼近连续函数的一系列多项式,可用来证明,在区间 区间上所有的连续函数都可以用多项式来逼近,并且收敛性很强,也就是一致收敛。
贝塞尔曲线(Bézier curve):又称贝兹曲线或贝济埃曲线,是应用于二维图形应用程序的数学曲线,可以使用很少的控制点生成复杂平滑曲线。常用类型分为:一阶贝塞尔(直线)、二阶贝塞尔(曲线)、三阶贝塞尔曲线。贝塞尔曲线可理解为伯恩斯坦多项式的图形化。
贡献:
- 本文是最早通过一个参数化的Bezier curve曲线来自适应拟合任意形状的文本的,这中方法可用于弯曲场景文本检测;
- 本文设计了一个新颖的BezierAlign layer,用于精确地提取任意形状文本实例的卷积特征。将BezierAlign用于特征对齐,那么识别分支可以自然地连接到整体结构之中,这使得识别分支可以设计成一个轻量级的结构。
- 相比于标准的bounding box detection方法,本文Bezier curve的检测方法引入了可忽略的计算负担,这使得我们的方法在效率和精度上都有提升。
Adaptive Bezier Curve Network(ABCNet)
ABCNet是一个端到端可训练的任意形状的场景文本识别网络。结构如下:

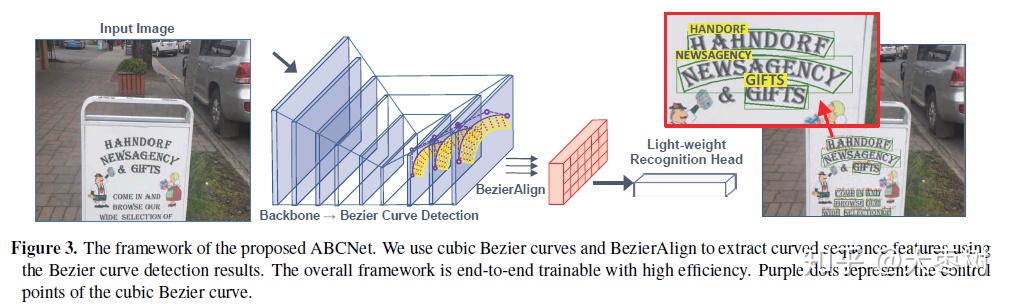
检测框架:采用了一个single-shot, anchor-free的神经网络。anchor boxes的移除极大地简化了检测任务。
ABCNet分为两个部分:1)Bezier curve检测; 2)Bezier-Align and 识别分支。
---------------------------------------------------------
Bezier Curve Detection
Bezier 曲线是一个参数化的曲线用表示,该曲线使用伯恩斯坦多项式作为它的偏置。定义如下:
n表示degree;表示第i个控制点; 表示Bernstein basis polynomials,其定义如下:
是binomial系数。

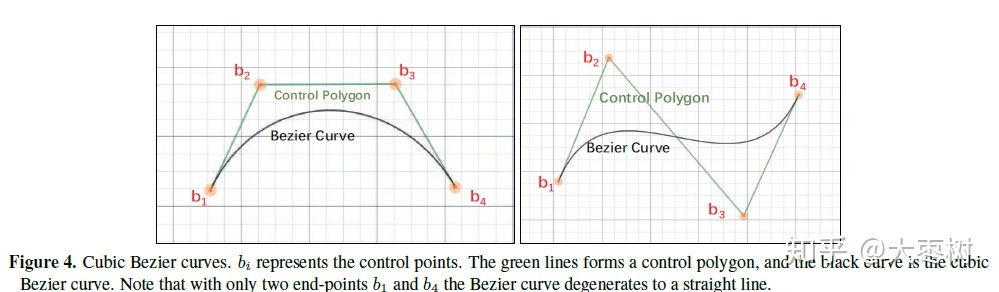
为了使用Bezier curves拟合任意形状的文本,本文从现有的数据集和真实世界中综合分析了任意形状的文本,发现cubic Bezier曲线能够拟合不同形状的场景文本的形状。
基于cubic Bezier曲线,我们可以将任意形状的场景文本简化到一个有八个控制点的bounding box回归任务中。特别地,笔直的文本有四个控制点(四个顶点),属于一种特殊的任意形状的文本,为了保持一致性,我们在每条边的上插入额外的两个控制点。
为了学习到控制点的坐标,我们首先要生成Bezier curve ground truth,然后使用回归的方法去学习目标。对于每一个文本样例:
和 表示4个顶点最小的x和y的值。预测相关距离的优势是它与Bezier curve的控制点是否超过了图形区域无关。在检测网络内部,我们仅仅需要一个有16个输出通道的卷积层去学习 和 ,这样操作的消耗是非常少的。
即:学习目标为四个顶点中最小的x、y的值以及控制点与最小值点的相关距离。
-------------------------------------------------
Bezier Ground truth generation
在本小节,主要介绍了怎样基于原始标注信息生成Bezier curve的ground truth。
从曲线边框中给定一个标注点 , 表示第i个标注点,主要的目的就是获得cubic Bezier曲线 的公式1的最优参数。为了实现这一点,使用了标准最小平方的方法(standard least square method),公式如下:
m表示曲线边框的标注点数目。对于CTW1500,m分别是5和7。t是用累计长度与多边周长之比来计算的。
根据公式1和公式4将原始的四边形标注转化为参数化的Bezier curve。注意,我们直接使用第一个和最后一个标注点作为第一个 和最后一个 控制点。原始标注和生成的Bezier curve的比较如图5。


另外,基于结构化的Bezier 曲线的bounding box,我们可以容易地使用我们的BezierAlign 去变换曲线文本到一个水平的形式而不需要过多的变形,更多Bezier curve生成的结果如图6所示:


-------------------------------------------------
Bezier Curve Synthetic Dataset
具体操作见原文。


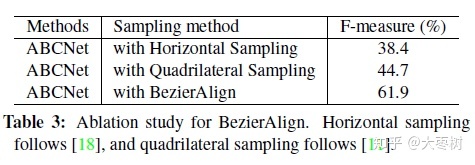
BezierAlign
为了能够实现端到端的训练,许多方法采用各种各样的的采样方式(特征对齐)去连接识别分支。
通过利用一个Bezier curve bounding box的参数化特性,本文提出了用于特征采样的BezierAlign。BezierAlign的采样网格并不是矩形。任意形状网格的每一列都与文本的Bezier曲线边界正交,采样点在宽度和高度上有等距的间隔,分别对坐标进行双线性插值。
给定一个输入特征图和Bezier曲线控制点,本文同时处理长方形的输入特征图的所有输入像素值,特征图的尺寸为。像素 的坐标为 ,则可以通过公式5进行计算:
然后使用t和公式1去计算上面Bezier curve边界 以及下面Bezier curve边界 。使用 和 ,可以通过公式6检索采样点 :
通过 的位置,可以使用双线性差值来计算最终的结果。


Recognition branch
识别分支的结构如下:


实验结果:
Total-Text:
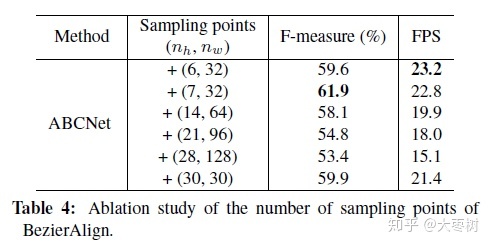
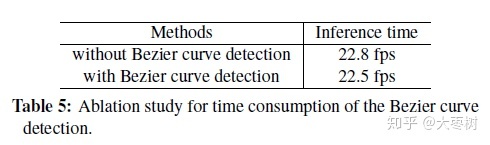
ablation study:



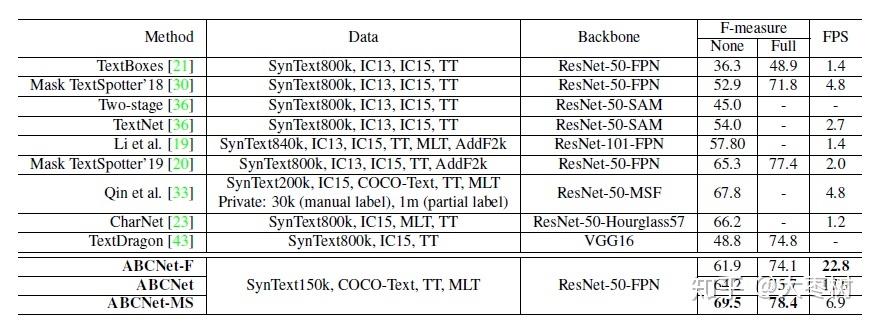
与其他方法的比较:

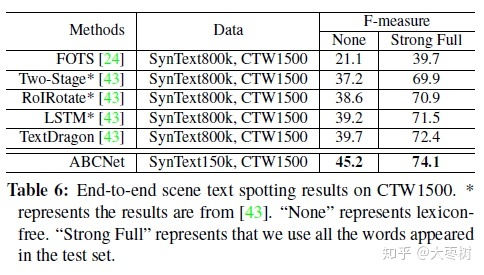
CTW1500: