
DCM:中间件家族迎来新成员
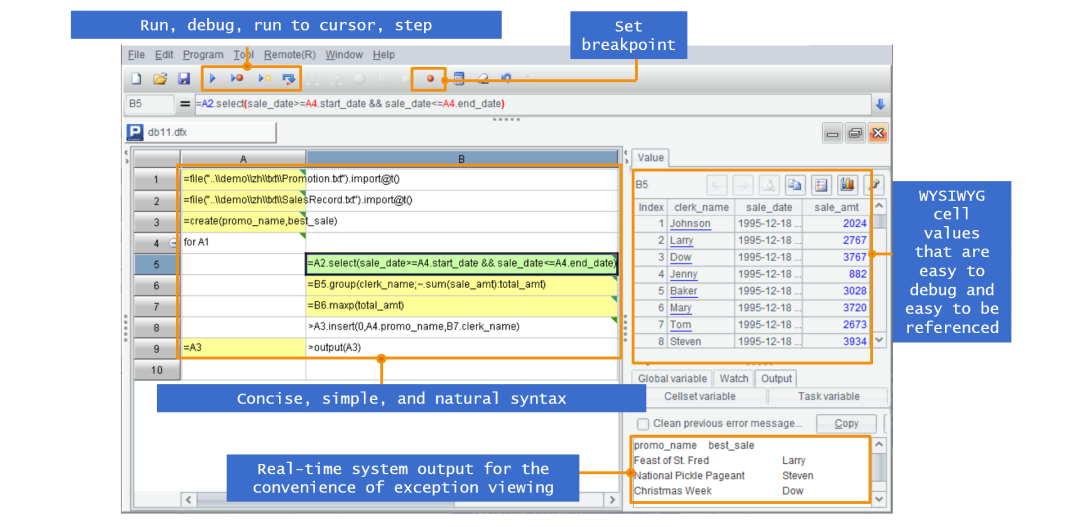
优化应用开发

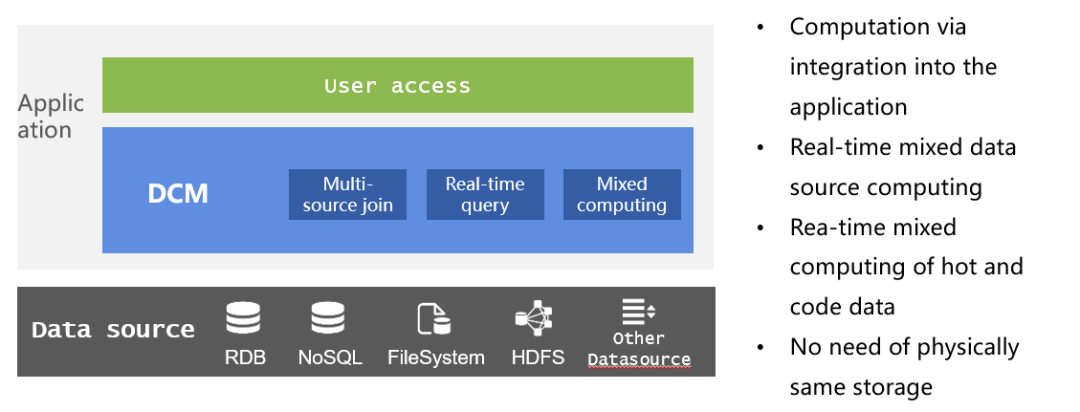
多样性数据源计算
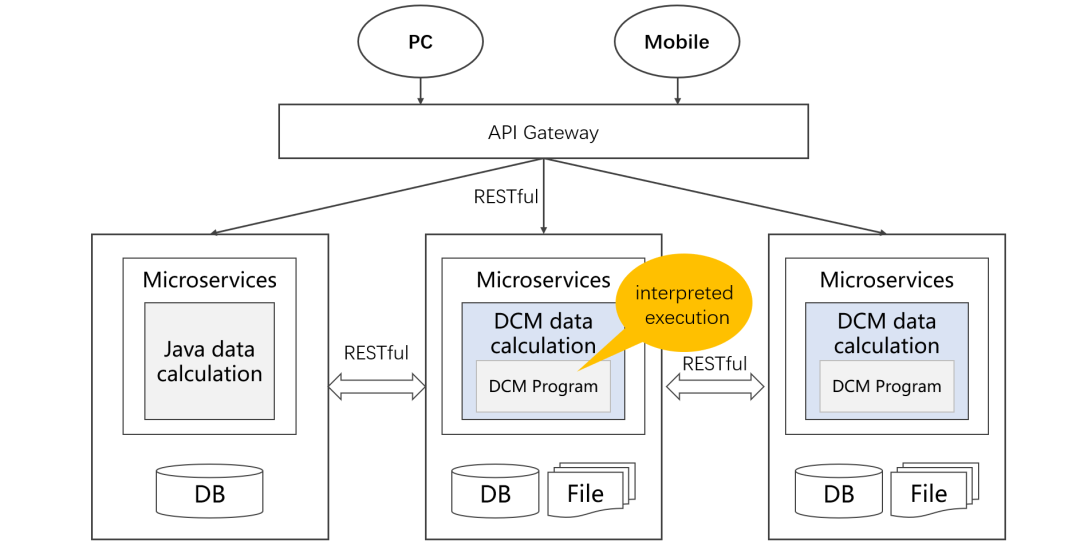
微服务实现
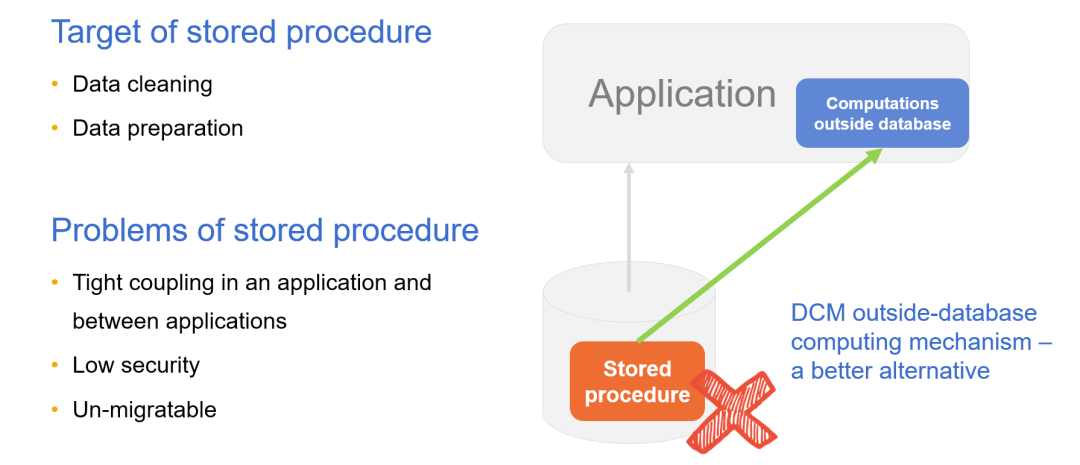
存储过程替代
报表 BI 数据准备

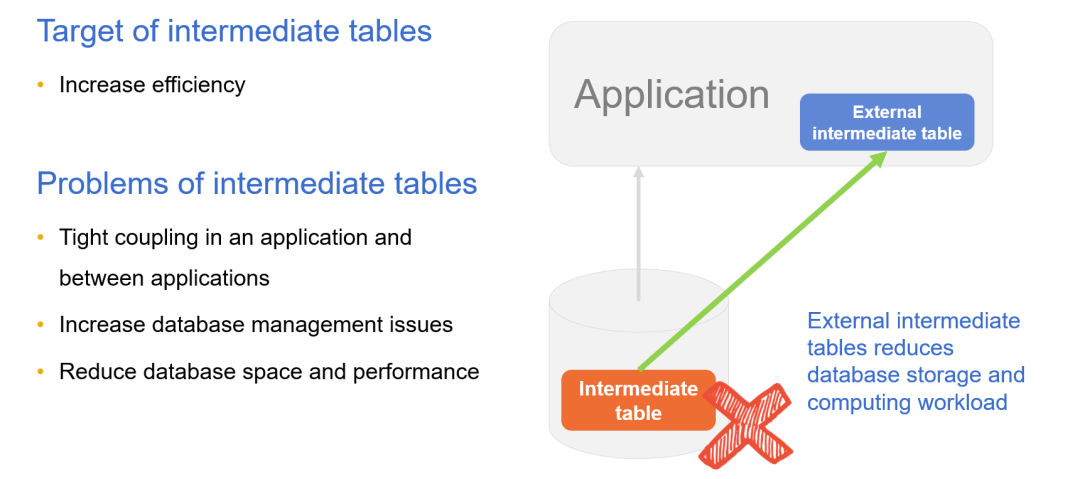
中间表消除
T+0 查询
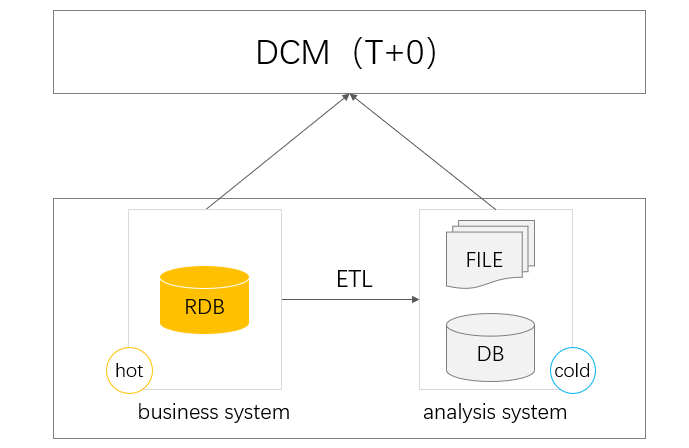
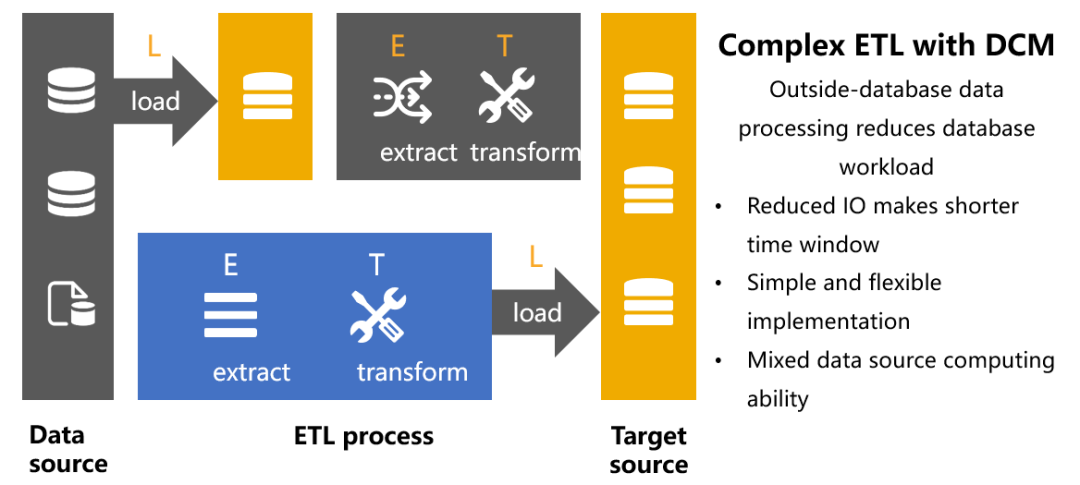
ETL
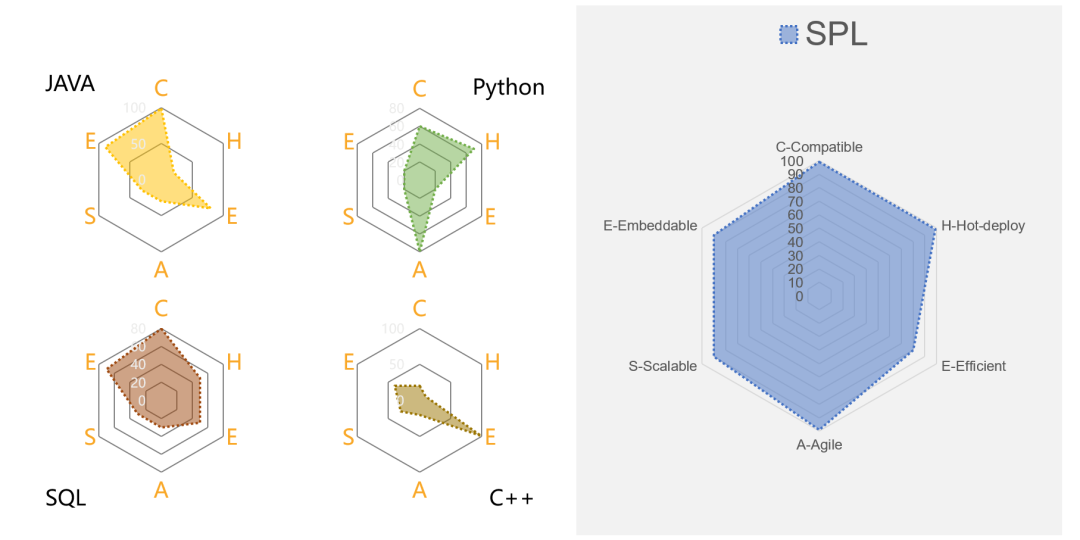
兼容性(Compatible)
热部署(Hot-deploy)
高性能(Efficient)
敏捷性(Agile)
扩展性(Scalable)
集成性(Embeddable)

SQL
Java
Python
兼容性


热部署
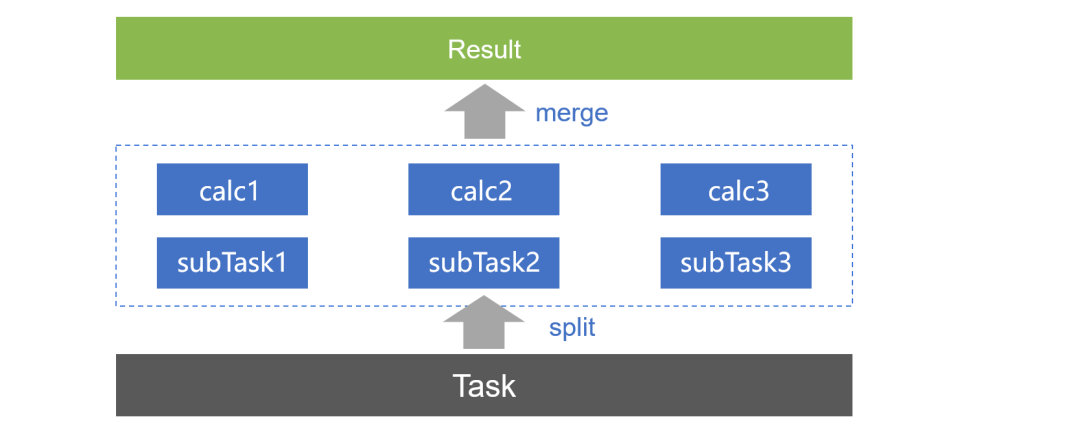
高性能
A | ||
1 | =file(“data.ctx”).create().cursor() | |
2 | =A1.groups(;top(10,amount)) | 金额在前 10 名的订单 |
3 | =A1.groups(area;top(10,amount)) | 每个地区金额在前 10 名的订单 |
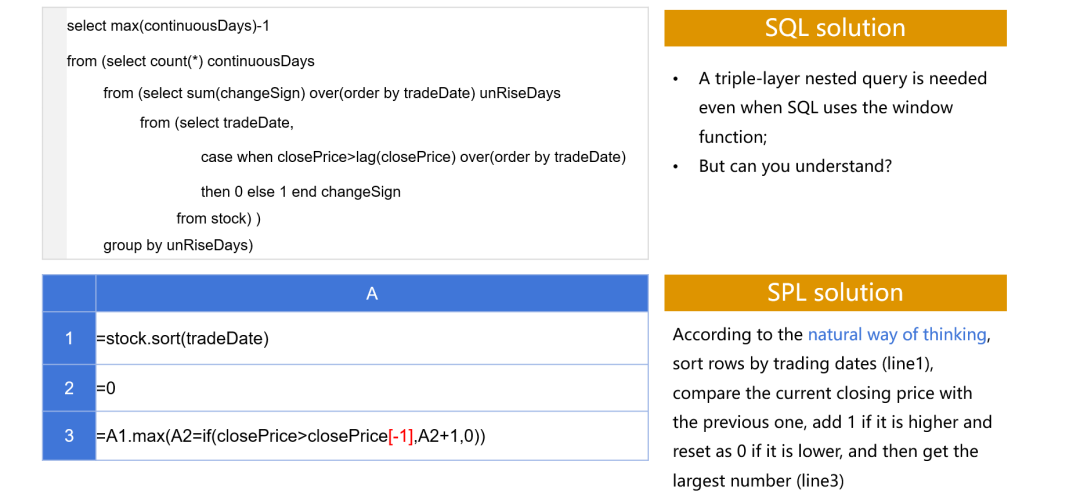
这里的语句中没有排序字样,也不会产生大排序的动作,在全集还是分组中计算 TopN 的语法基本一致,而且都会有较高的性能,类似的算法在 SPL 中还有很多。
敏捷性

扩展性
集成性
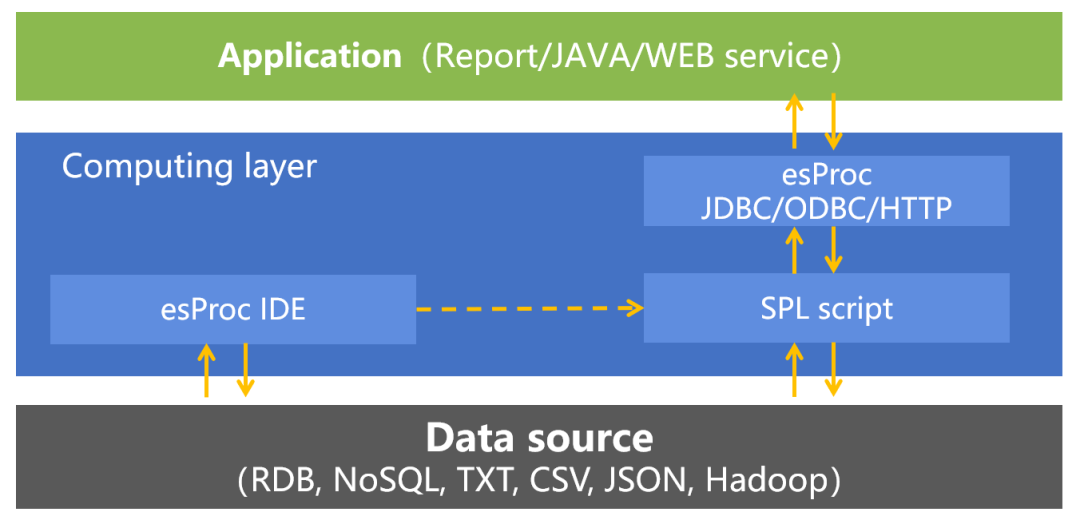
Class.forName("com.esproc.jdbc.InternalDriver");Connection conn =DriverManager.getConnection("jdbc:esproc:local://");CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");st.setObject(1, 3000);st.setObject(2, 5000);ResultSet result=st.execute();
综合起来,从 DCM 的 6 个特性(CHEASE)来看,SPL 在各方面能力综合起来十分均衡,整体远优于其他技术,是 DCM 的理想选择。

评论