
如何给TiDB插上全文检索的翅膀
“搜索”是内容类App产品非常重要的一个功能,“全文检索”是支持它不可或缺的一项基本能力。
目前业界很多公司产品的业务数据已经向 TiDB 迁移了,但目前在 TiDB 上只能使用 SQL Like 对内容进行简单的检索。
即便不考虑性能问题,SQL Like 仍然无法实现搜索场景下常见的信息检索需求,单纯使用 Like 会导致查询到有歧义的结果或满足搜索条件的结果无法返回。
由于TiDB 全文检索能力的缺失,岁月很多公司依旧需要使用传统的方式将数据同步到搜索引擎,在过程中根据业务特点做大量繁琐的数据流水线工作来维护业务数据的全文索引。为了减少这样的重复劳动,TiDB 引入“全文检索”功能,为存储在 TiDB 中的文本数据提供随时随地搜索的能力。
方案设计
选择了一条稳妥的设计方案——整合 Elasticsearch。
为什么选择 Elasticsearch?
可以充分利用其成熟的生态直接获得中文分词和 Query 理解能力。
考虑到工作量,对于全文索引的数据同步方案,没有采用 TiKV Raft Learner 机制,也没有使用 TiDB Binlog 的方式进行同步,而是采用了最保守的双写机制直接在 TiDB 的写入流程中增加了全文索引更新的流程。
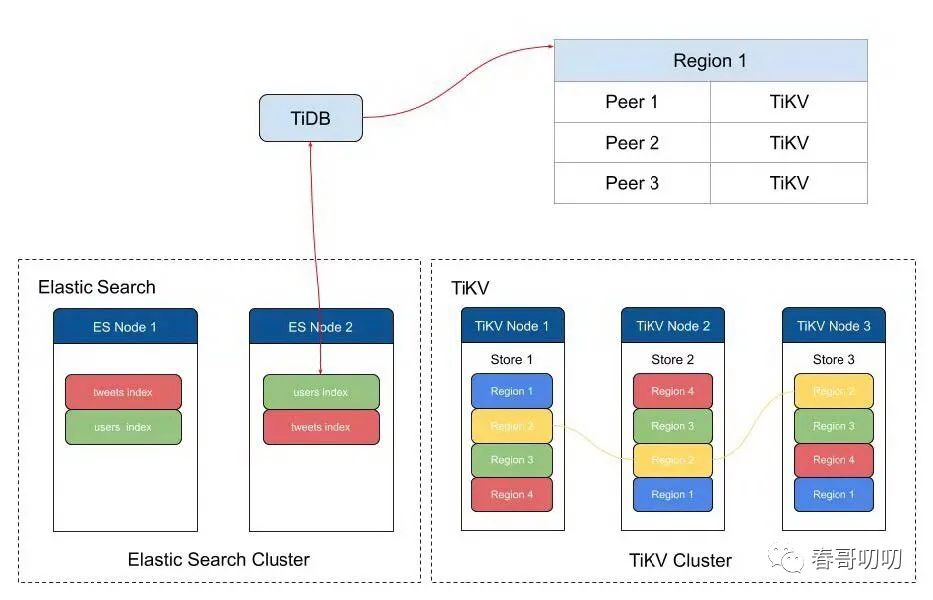
如上图所示,TiDB 作为 Elasticsearch 和 TiKV 之间的桥梁,所有同 Elasticsearch 的交互操作都嵌入在 TiDB 内部直接完成。
在 TiDB 内部,将表额外增加了支持 全文(FULLTEXT)索引的元数据记录,并且在 Elasticsearch 上面创建了对应的索引和 Mapping,对于全文索引中的每一个文本列,都将它添加到 Mapping 中并指定好需要的 Analyzer,这样就可以在索引上对这些文本列进行全文检索了。
在 Elasticsearch 索引的帮助下,只需要在写入数据或者对数据进行更新时在 Elasticsearch 的索引上进行对应的更新操作,就保持 TiDB 和 Elasticsearch 数据的同步。
而对于查询,流程如下:
1. TiDB 解析用户发送的 Query。
2. 如果发现该 Query 带有全文检索的 hint,TiDB 则会将请求发给 Elasticsearch,使用 Elasticsearch 索引查询到记录主键。
3. TiDB 拿到所有记录主键之后,在 TiDB 内部获取实际的数据,完成最终的数据读取。
4. TiDB 将结果返回给用户。
未来规划
基于以上方案验证了整合 TiDB 和 ES 的可能性,当然,也不会满足于这套双写的方案。
未来考虑基于 Raft Learner 实时将数据变更同步给 Elasticsearch,将 TiDB 打造成一个真正的能支持实时全文检索的 HTAP 数据库。
使用 Raft Learner,对于写流程,TiDB 会直接将数据写给底层的 TiKV,而 TiKV 会通过 Raft 协议将写入数据同步到 ES Learner 节点,通过该 Learner 节点写入到 ES。
对于读流程,TiDB 会解析到用户发过来的 Query 带有全文检索的 hint,然后将请求发给 ES Learner 节点。
ES Learner 节点首先通过 Raft 协议来确保节点上面有了最新的数据,并且最新的数据已经写入到 Elasticsearch,再通过索引读取到对应的记录主键,返回给 TiDB。
最后 TiDB 使用记录主键获取到完整的数据,并返回给客户端。
相比于之前让 TiDB 双写到 Elasticsearch 和 TiKV 的方案,在写入上面,TiDB 并不需要跟 Elasticsearch 进行交互,而在读取方面,通过 Raft 协议,TiDB 也能保证从 Elasticsearch 读取到最新的数据,保证了数据的一致性。