
Python-文字识别
共 656字,需浏览 2分钟
·
2022-02-09 17:41
首先还是要安装tesseract OCR,即Optical Character Recognition,光学字符识别,谷歌开发的,在免费库中还是非常友好的,应用场景比较多,比如在爬取数据时可以识别验证码等,我是因为有一大批扫描文件需要转换成Excel,研究了一下,中间也遇到了很多问题,接下来可以带大家入个门。
第一步需要下载tesseract OCR安装包(百度网上很多资源,如果搜到CSDN分析的文章里边的下载地址还是比较靠谱的,如果懒得百度可以后台私信无偿发你),还是注意安装位置,后边要设置环境变量


第二步下载语言包,可以搜索已经训练好的现成的语言包(GitHub官方搜索下载,如果下载不下来可以百度或者后台私信无偿发)下载后解压好,放在安装好的文件夹下

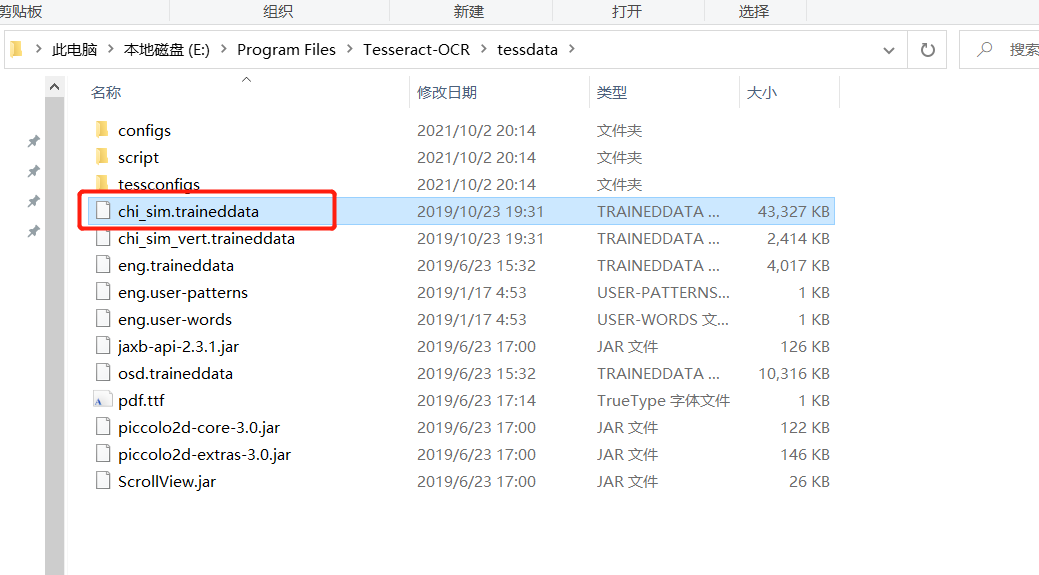
第三步配置环境变量,右击我的电脑,属性,高级系统设置,直接上图以下是我安装的位置

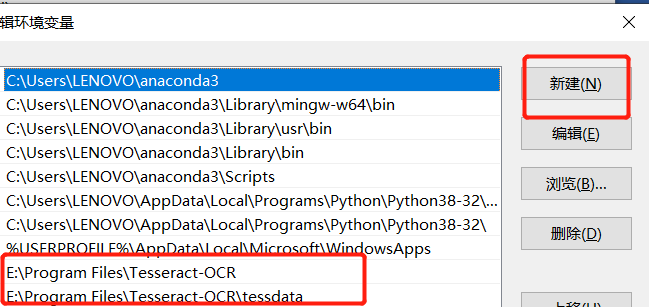
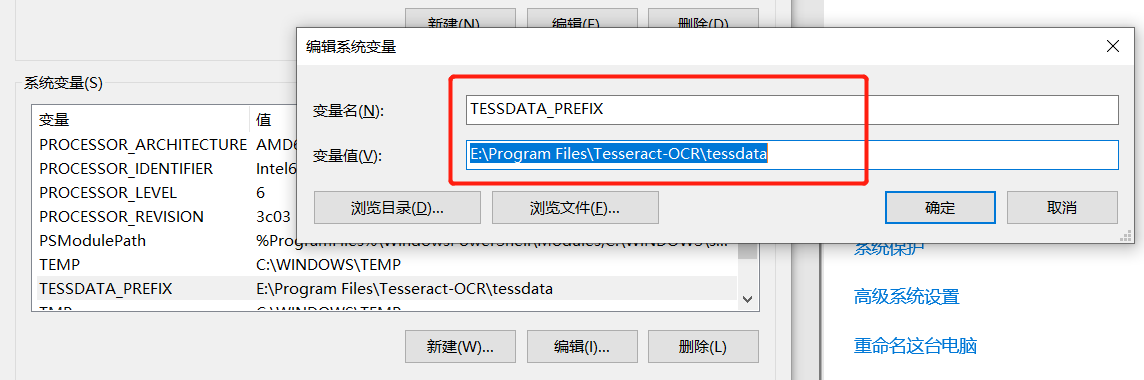
另外系统变量也加上

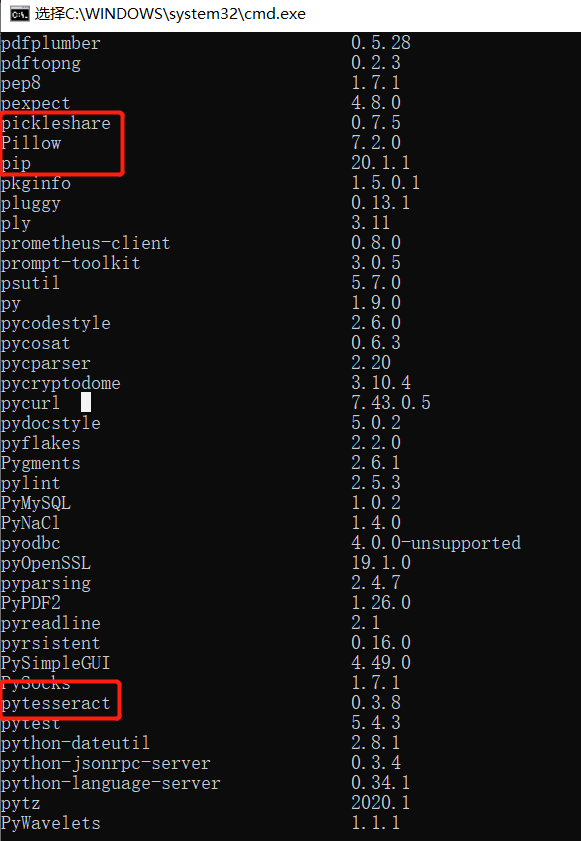
第四步安装Python的两个库(打开cmd 输入:pip install pytesseract和pip install pillow)如果安装成功,可以输入pip list
,可以看到下图的安装包。

最后的最后打开jupyter notebook,或者你的pycharm
输入代码,就成了

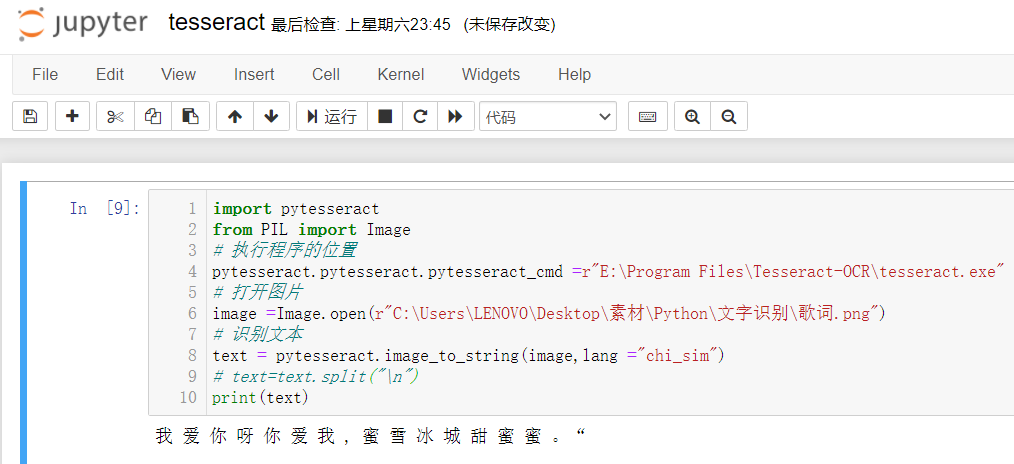
不过笔者扫描件都是表格,tesseract,识别失败,最后用Python调用百度AI做的的识别,但是表格线和文字都黏在一起了,效果并不理想,如果清晰地表格和文字应该是没问题的,以后有空再把代码分享出来。
VX“生活是个啥”“degreeoffree910”
评论