
深入理解协程
C++ 在互联网服务端开发方向依然占据着相当大的份额;百度,腾讯,甚至以java为主流开发语言的阿里都在大规模使用C++做互联网服务端开发,今天以C++为例子,分析一下要支持协程,需要考虑哪些问题,如何权衡利弊,反过来也可以了解到协程适合哪些场景。
第1章 C++协程近况简介
第1节.旧时代
每个流程都要定义一个上下文struct,并手动保存与恢复; 每次回调都会切断栈上变量的生命周期,导致需要延续使用的变量必须申请到堆上或存入上下文结构中; 由于C++是无GC的语言,碎片化的逻辑给内存管理也带来了更多挑战; 回调式的逻辑是“不知何时会被触发”的,用户状态管理也会有更多挑战;
第2节.新时代
第2章.协程库的设计与实现
1.API级
2.玩具级
3.工业级
4.框架级
5.语言级
第1节.协程上下文切换
1.使用操作系统提供的api:ucontext、fiber 这种方式是最安全可靠的,但是性能比较差。(切换性能大概在200万次/秒左右) 2.使用setjump、longjump: 代表作:libmill 3.自己写汇编码实现 这种方式的性能可以很好,但是不同系统、甚至不同版本的linux都需要不同的汇编码,兼容性奇差无比,代表作:libco 4.使用boost.coroutine 这种方式的性能很好,boost也帮忙处理了各种平台架构的兼容性问题,缺陷是这东西随着boost的升级,并不是向后兼容的,不推荐使用 5.使用boost.context 性能、兼容性都是当前最佳的,推荐使用。(切换性能大概在1.25亿次/秒左右)
不愿意依赖boost库的用户直接编译即可选择第1种方案; 追求更佳性能的用户编译时使用cmake参数-DENABLE_BOOST_CONTEXT=ON即可选择第5种方案
第2节.协程栈
静态栈(Static Stack)
分段栈(Segmented Stack)
拷贝栈(Copy Stack)
共享栈(Shared Stack)
1.协程切换慢:每次协程切换,都需要2次Copy协程栈内存,这个内存量基本上都在1KB以上,通常是几十kb甚至几百kb,这样的2次Copy要花费很长的时间。 2.栈上引用失效导致隐蔽的bug:例如下面的代码
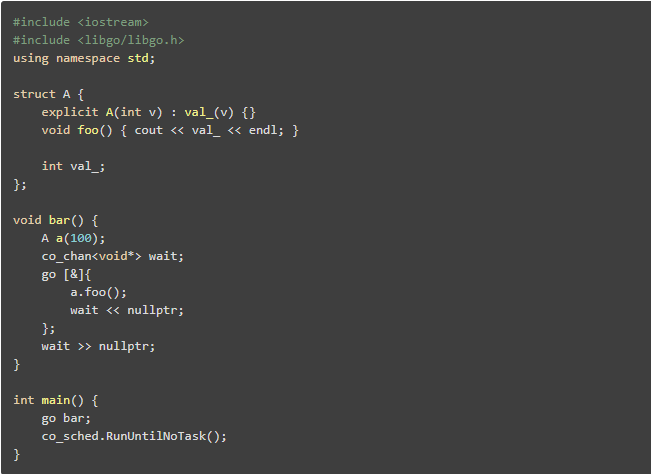
虚拟内存栈(Virtual Memory Stack)
第3节.协程调度
栈式调度
星切调度(非对称协程调度)
环切调度(对称协程调度)
多线程调度、负载均衡与WorkSteal
第4节.HOOK
基本守则:HOOK接口表现出来的行为与被HOOK的接口保持100%一致
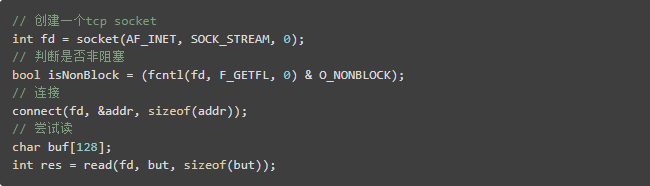
网络io
DNS
gethostbyname2
gethostbyname_r
gethostbyname2_r
gethostbyaddr
gethostbyaddr_r
signal

其他会导致阻塞的syscall
第5节.完整生态
Channel





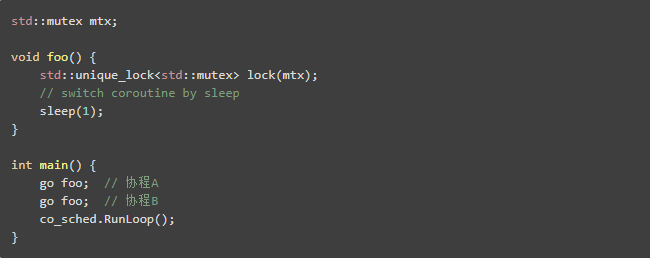
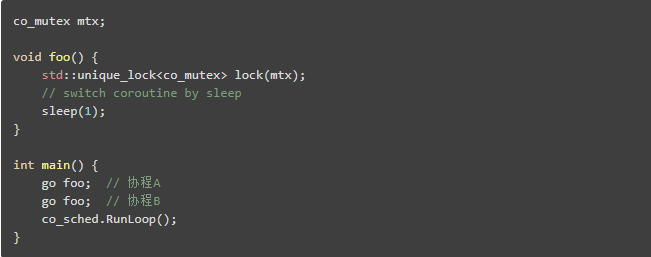
协程锁、协程读写锁

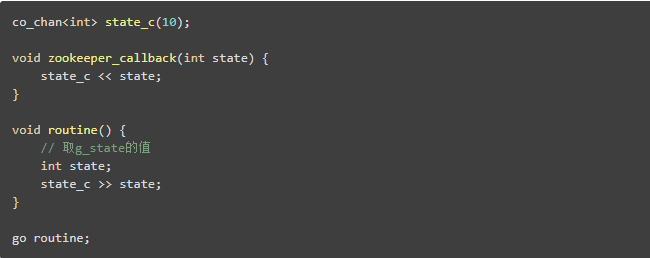
定时器
CLS(Coroutine Local Storage)(协程本地存储)
线程池



1.可以设置co_sched.GetOptions().debug打印一些log,具体flag见config.h 2.可以设置一个协程事件监听器,详见tutorial文件夹下的sample12_listener.cpp教程代码 3.编译时添加cmake参数:-DENABLE_DEBUGGER=ON 开启debug信息收集后,可以使用co::CoDebugger类获取一些调试信息,详见debugger.h的注释 4.后续还会提供更多调试手段
协程之外(运行在线程上的代码)
跨平台
libgo支持三大主流系统:linux、windows、mac-os
上层封装
未来的发展方向
1.目前是使用go、go_stack、go_dispatch三个不同的宏来设置协程的属性,这种方式不够灵活,后续要改成:go stack(1024 * 1024) dispatch(::co::egod_robin) func; 这样的语法形式,可以更灵活的定制协程属性。 2.基于(1)的新语法,实现“协程亲缘性”功能,将协程绑定到指定线程上,并防止被steal。 3.优化协程切换速度: A)使用环切调度替代现在的星切调度(CoYeild时选择下一个切换目标),必要时才切换回线程处理epoll、定时器、sleep等逻辑,同时协调好多线程调度 B)调度器的Run函数里面做了很多协程切换之外的事情,尽量降低这部分在非必要时的cpu消耗,比如:有任务加入定时器是设置一个tls标记为true,只有标记为true时才去处理定时器相关逻辑。 C)调度器中的runnable队列使用了自旋锁,没有竞争时对原子变量的操作也是比较昂贵的,runnable队列可以优化成多写一读,仅在写入端加锁的队列。 4.协程对象Task内存布局调优,tls池化,每个池使用多写一读链表队列,申请时仅在当前线程的池中申请,可以免锁,释放时均衡每个线程的池水水位,可以塞入其他线程的池中。 5.libgo之外,会进一步寻找和当前已经比较成熟的非协程的开发框架的结合方案,让还未能用上协程的用户低成本的用上协程。
https://github.com/yyzybb537/libgo
作者:Li_Mr https://my.oschina.net/yyzybb/blog/1817226
评论