
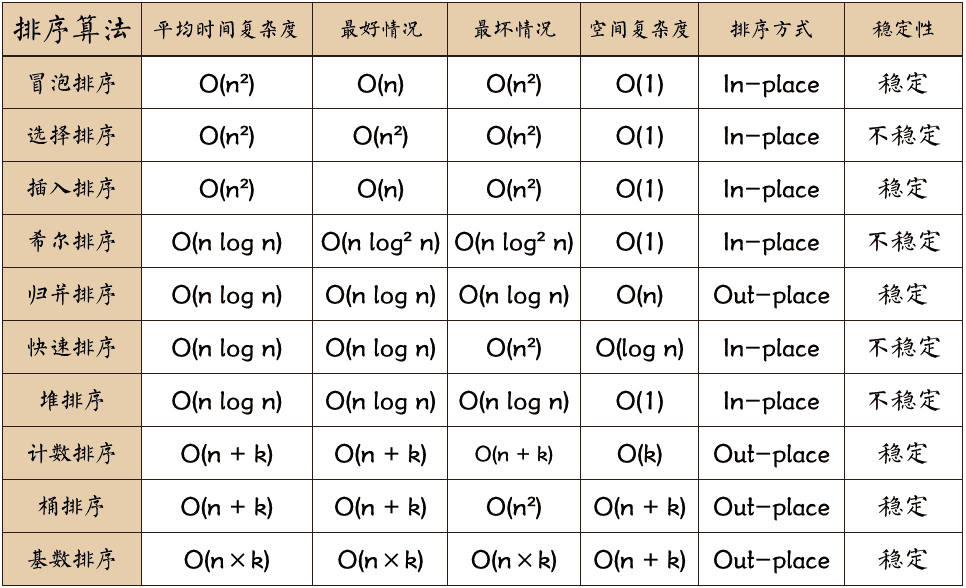
全面讲解十大经典排序算法(Python实现)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者 | hustcc
链接 | https://github.com/hustcc/JS-Sorting-Algorith
平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。 线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序; O(n1+§)) 排序,§ 是介于 0 和 1 之间的常数。希尔排序 线性阶 (O(n)) 排序 基数排序,此外还有桶、箱排序。
排序后 2 个相等键值的顺序和排序之前它们的顺序相同 稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序。 不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。
1、冒泡排序
(1)算法步骤
比较相邻的元素。如果第一个比第二个大,就交换他们两个。 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。 针对所有的元素重复以上的步骤,除了最后一个。 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
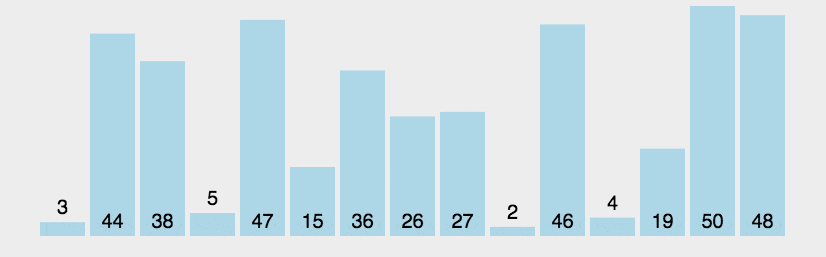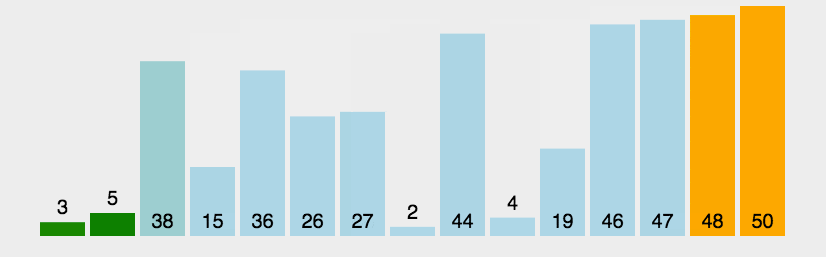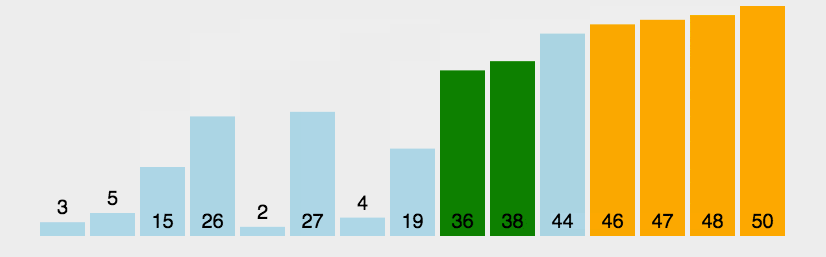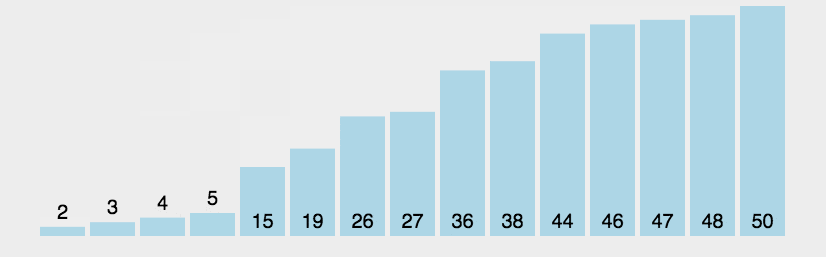
def bubbleSort(arr):
for i in range(1, len(arr)):
for j in range(0, len(arr)-i):
if arr[j] > arr[j+1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
2、选择排序
(1)算法步骤
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。 重复第二步,直到所有元素均排序完毕。
def selectionSort(arr):
for i in range(len(arr) - 1):
# 记录最小数的索引
minIndex = i
for j in range(i + 1, len(arr)):
if arr[j] < arr[minIndex]:
minIndex = j
# i 不是最小数时,将 i 和最小数进行交换
if i != minIndex:
arr[i], arr[minIndex] = arr[minIndex], arr[i]
return arr
3、插入排序
(1)算法步骤
将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
def insertionSort(arr):
for i in range(len(arr)):
preIndex = i-1
current = arr[i]
while preIndex >= 0 and arr[preIndex] > current:
arr[preIndex+1] = arr[preIndex]
preIndex-=1
arr[preIndex+1] = current
return arr
4、希尔排序
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率; 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
(1)算法步骤
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1; 按增量序列个数 k,对序列进行 k 趟排序; 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
def shellSort(arr):
import math
gap=1
while(gap < len(arr)/3):
gap = gap*3+1
while gap > 0:
for i in range(gap,len(arr)):
temp = arr[i]
j = i-gap
while j >=0 and arr[j] > temp:
arr[j+gap]=arr[j]
j-=gap
arr[j+gap] = temp
gap = math.floor(gap/3)
return arr
}
自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第 2 种方法) 自下而上的迭代
(1)算法步骤
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列; 设定两个指针,最初位置分别为两个已经排序序列的起始位置; 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置; 重复步骤 3 直到某一指针达到序列尾; 将另一序列剩下的所有元素直接复制到合并序列尾。
def mergeSort(arr):
import math
if(len(arr)<2):
return arr
middle = math.floor(len(arr)/2)
left, right = arr[0:middle], arr[middle:]
return merge(mergeSort(left), mergeSort(right))
def merge(left,right):
result = []
while left and right:
if left[0] <= right[0]:
result.append(left.pop(0));
else:
result.append(right.pop(0));
while left:
result.append(left.pop(0));
while right:
result.append(right.pop(0));
return result
6、快速排序
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
(1)算法步骤
从数列中挑出一个元素,称为 “基准”(pivot); 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作; 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
def quickSort(arr, left=None, right=None):
left = 0 if not isinstance(left,(int, float)) else left
right = len(arr)-1 if not isinstance(right,(int, float)) else right
if left < right:
partitionIndex = partition(arr, left, right)
quickSort(arr, left, partitionIndex-1)
quickSort(arr, partitionIndex+1, right)
return arr
def partition(arr, left, right):
pivot = left
index = pivot+1
i = index
while i <= right:
if arr[i] < arr[pivot]:
swap(arr, i, index)
index+=1
i+=1
swap(arr,pivot,index-1)
return index-1
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列; 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
(1)算法步骤
创建一个堆 H[0……n-1]; 把堆首(最大值)和堆尾互换; 把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置; 重复步骤 2,直到堆的尺寸为 1。

def buildMaxHeap(arr):
import math
for i in range(math.floor(len(arr)/2),-1,-1):
heapify(arr,i)
def heapify(arr, i):
left = 2*i+1
right = 2*i+2
largest = i
if left < arrLen and arr[left] > arr[largest]:
largest = left
if right < arrLen and arr[right] > arr[largest]:
largest = right
if largest != i:
swap(arr, i, largest)
heapify(arr, largest)
def swap(arr, i, j):
arr[i], arr[j] = arr[j], arr[i]
def heapSort(arr):
global arrLen
arrLen = len(arr)
buildMaxHeap(arr)
for i in range(len(arr)-1,0,-1):
swap(arr,0,i)
arrLen -=1
heapify(arr, 0)
return arr
8、计数排序
def countingSort(arr, maxValue):
bucketLen = maxValue+1
bucket = [0]*bucketLen
sortedIndex =0
arrLen = len(arr)
for i in range(arrLen):
if not bucket[arr[i]]:
bucket[arr[i]]=0
bucket[arr[i]]+=1
for j in range(bucketLen):
while bucket[j]>0:
arr[sortedIndex] = j
sortedIndex+=1
bucket[j]-=1
return arr
9、桶排序
在额外空间充足的情况下,尽量增大桶的数量 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
def bucket_sort(s):
"""桶排序"""
min_num = min(s)
max_num = max(s)
# 桶的大小
bucket_range = (max_num-min_num) / len(s)
# 桶数组
count_list = [ [] for i in range(len(s) + 1)]
# 向桶数组填数
for i in s:
count_list[int((i-min_num)//bucket_range)].append(i)
s.clear()
# 回填,这里桶内部排序直接调用了sorted
for i in count_list:
for j in sorted(i):
s.append(j)
if __name__ == __main__ :
a = [3.2,6,8,4,2,6,7,3]
bucket_sort(a)
print(a) # [2, 3, 3.2, 4, 6, 6, 7, 8]
10、基数排序
基数排序 vs 计数排序 vs 桶排序
基数排序:根据键值的每位数字来分配桶; 计数排序:每个桶只存储单一键值; 桶排序:每个桶存储一定范围的数值;

def RadixSort(list):
i = 0 #初始为个位排序
n = 1 #最小的位数置为1(包含0)
max_num = max(list) #得到带排序数组中最大数
while max_num > 10**n: #得到最大数是几位数
n += 1
while i < n:
bucket = {} #用字典构建桶
for x in range(10):
bucket.setdefault(x, []) #将每个桶置空
for x in list: #对每一位进行排序
radix =int((x / (10**i)) % 10) #得到每位的基数
bucket[radix].append(x) #将对应的数组元素加入到相 #应位基数的桶中
j = 0
for k in range(10):
if len(bucket[k]) != 0: #若桶不为空
for y in bucket[k]: #将该桶中每个元素
list[j] = y #放回到数组中
j += 1
i += 1
return list
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论