
NLP赛事数据分析和提分总结!
赛题名称:互联网舆情企业风险事件的识别和预警
赛题链接:http://ailab.aiwin.org.cn/competitions/48
赛题背景
近些年来,资本市场违约事件频发,财务造假、董事长被抓、股权质押爆仓、城投非标违约等负面事件屡屡出现。而在大数据和人工智能技术加持下,各种新兴的金融风险控制手段也正在高速发展,其中通过采集互联网上的企业舆情信息来挖掘潜在风险事件是一种较为有效的方式。但这些风险信息散落在互联网上的海量资讯中,若能从中及时识别出涉及企业的风险事件,并挖掘出潜在的风险特征,将使得银行、证券等金融机构在风险监控领域中更及时、全面和直观地掌握客户风险情况,大幅提升识别和揭示风险的能力。而风险事件以文本的形式存在,需要采用人工智能方法进行自然语言理解,实现风险事件的高精度智能识别。
赛题任务
从给定的互联网信息中提取、识别出企业主体名称,以及标记风险标签。选手预测标签对应格式为(新闻ID,主体全称,对应风险标签)。
注:
1)每篇互联网信息可能会涉及零到多个主体(公司),每篇互联网信息中对每个主体只预测一个风险标签;
2)赛事会提供一份主体(公司)的全称清单(其范围大于待预测名单),新闻中提及的主体可能为其简称或别名或主体相关的自然人(如其董事长、总经理等),选手提交答案时需要统一识别并将他们映射至主体全称输出在最终的结果文件中。主体全称的映射关系需选手自行处理。
3)请注意在训练集中存在一类「无」标签,其指的是对应的新闻内容中不包含需识别的金融风险事件。对于测试集中此类情况,选手模型在输出时只需准确打上「无」的标签,对应主体标记为「/」即可。即输出的为:"新闻 ID,/ ,无"。
4)测试集(需选手利用模型进行预测)的数据中会包含一些噪音数据,比如在主体(公司)的全称清单之外的舆情等,选手同样需要对其预测,不计入自动评分。
评价方式
统一评审阶段
将选手预测结果和答案进行对比计算出F1值,F1越大约好
F1计算公式为:
P = 预测对的标签总数 / 预测出的标签数
R = 预测对的标签总数 / 需要预测的总标签数
F1 = 2 * P * R /(P+R)
数据描述
数据集文件如下:
├── data
│ ├── RISKLABEL_Training
│ │ ├── 1_元数据格式.docx
│ │ ├── 2_公司实体汇总_20210414_A1.xlsx
│ │ ├── 3_训练集汇总_20210414_A1.xlsx
│ │ ├── readme.txt
│ │ ├── result.csv
│ │ └── ~$_元数据格式.docx
│ └── T1_ID
│ ├── readme.txt
│ └── result.csv
| 列名 | 数据类型 | 能否为空 | 备注 |
|---|---|---|---|
| NEWS_BASICINFO_SID | NUMBER(22) | NOT NULL | 新闻ID |
| NEWS_TITLE | VARCHAR2(3000) | 新闻标题 | |
| ABSTRACT | VARCHAR2(4000) | 摘要 | |
| CONTENT | CLOB | 正文 | |
| AUTHOR | VARCHAR2(1000) | 作者 | |
| SRC_URL | VARCHAR2(1000) | 下载源地址 | |
| SOURCE_TYPE | VARCHAR2(100) | 文章类型 | 01-新闻;02-论坛;03-博客;04-微博;05-平媒;06-微信;07-视频;08-长微博;09-APP;10-评论;99-其他 |
| PUBLISH_SITE | VARCHAR2(100) | 来源 | |
| FIRST_WEB | VARCHAR2(100) | 首发网站名称 | |
| CHANNEL | VARCHAR2(100) | 网站频道 | |
| NOTICE_DT | DATE | 发布时间 | |
| COMPANY_NM | VARCHAR2(300) | 企业名称 | |
| LABEL | VARCHAR2(60) | 业务标签 | 主板/创业板/中小板/债券退市 债务逾期 实控人变更 破产重整 股票质押率过高 被政府职能部 处罚 被监管机构罚款或查处 被采取监管措施 重大诉讼仲裁 信息披露违规等 |
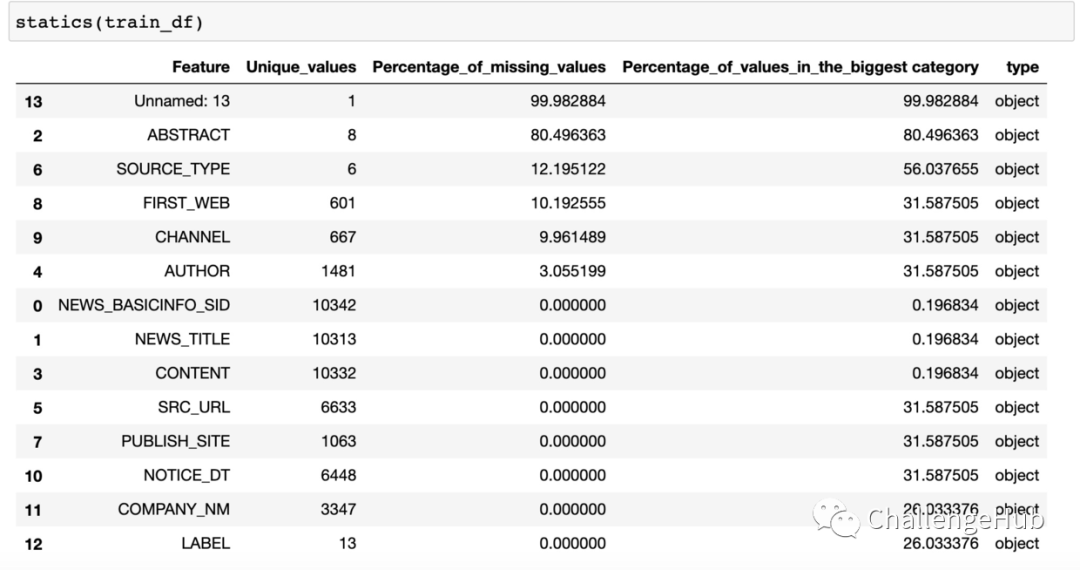
数据统计分析
首先加载看下数据内容:
接下来我们对数据集中出现的实体与文本进行分析,着重思考比赛思路以及赛题提分点。
def statics(data):
stats = []
for col in data.columns:
stats.append((col, data[col].nunique(), data[col].isnull().sum() * 100 / data.shape[0],
data[col].value_counts(normalize=True, dropna=False).values[0] * 100, data[col].dtype))
stats_df = pd.DataFrame(stats, columns=['Feature', 'Unique_values', 'Percentage_of_missing_values',
'Percentage_of_values_in_the_biggest category', 'type'])
stats_df.sort_values('Percentage_of_missing_values', ascending=False, inplace=True)
return stats_df
实体长度分布
统计每个实体的长度
stats = entities_df['entity_len'].value_counts().rename_axis('unique_entity_len').reset_index(name='counts')
fig = px.bar(stats, x='unique_entity_len', y='counts')
fig.show()
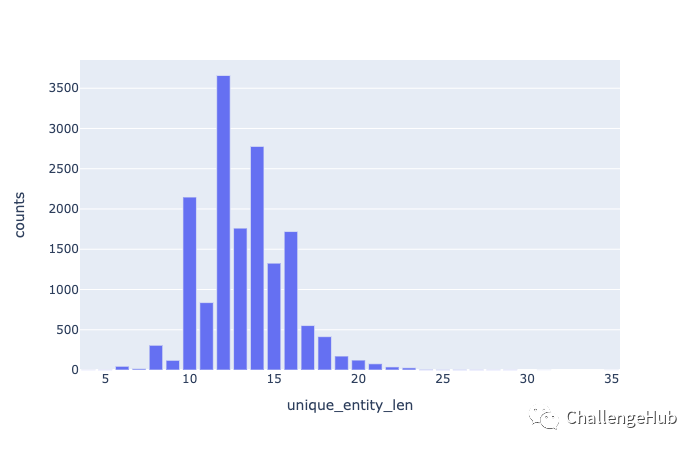
可以看出,实体最小长度为4,平均长度为13,最大长度为35,过长实体是我们需要解决的难点之一,我们可以通过将过长实体进行拆分标注,然后预测的时候根据是否相邻进行组合,也可以通过指针网络解决crf在过长实体识别时出现span断裂的问题。
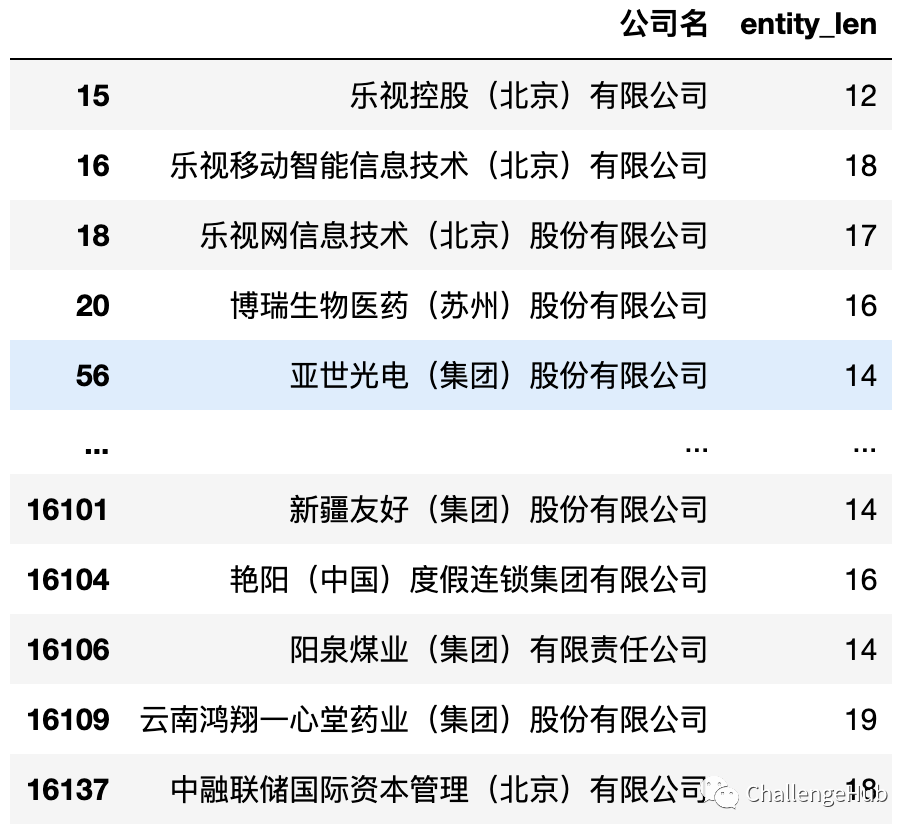
企业实体名称多样性
大部分企业实体都是以“公司”,“有些股份公司”,“集团"结尾的,另外也存在一些含有括号的实体:
entities_df[
(entities_df['公司名'].str.contains('('))|
(entities_df['公司名'].str.contains(')'))|
(entities_df['公司名'].str.contains('\('))|
(entities_df['公司名'].str.contains('\)'))
]
# 英文括号为0
例如:
除此之外还有一些其他名称比较灵活组合的实体
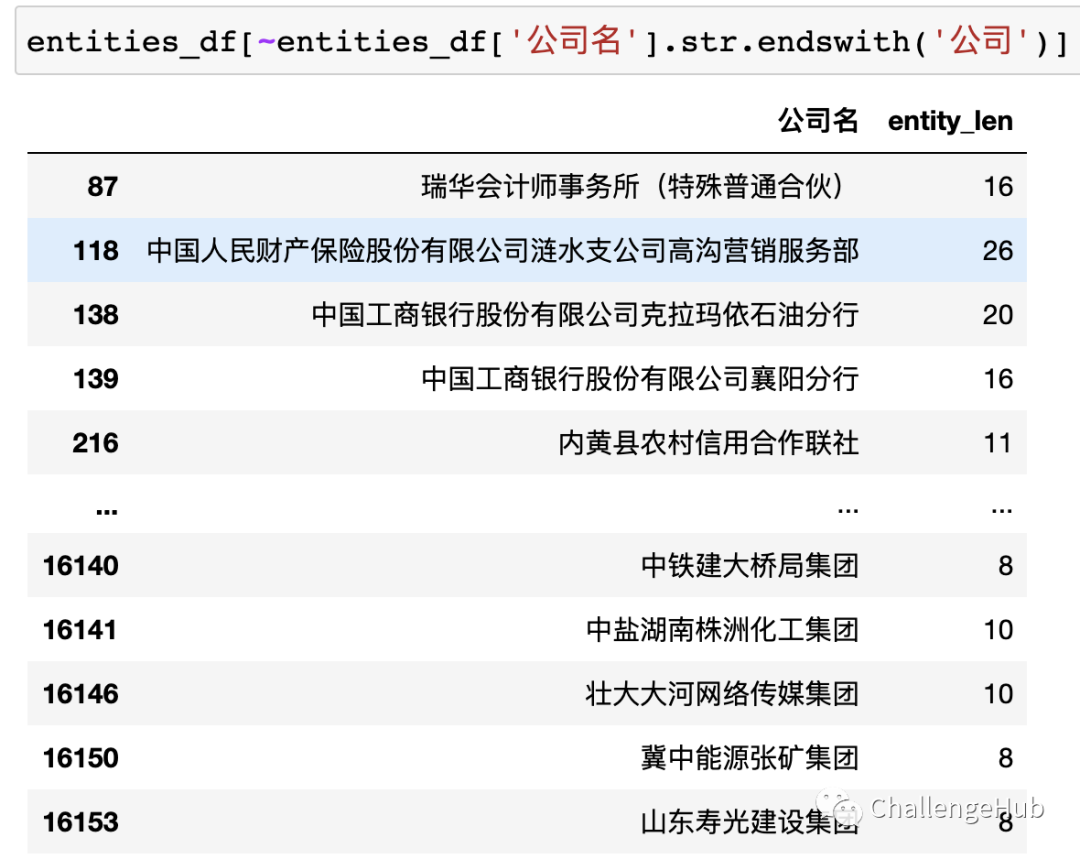
文本长度分析
新闻标题的长度分布
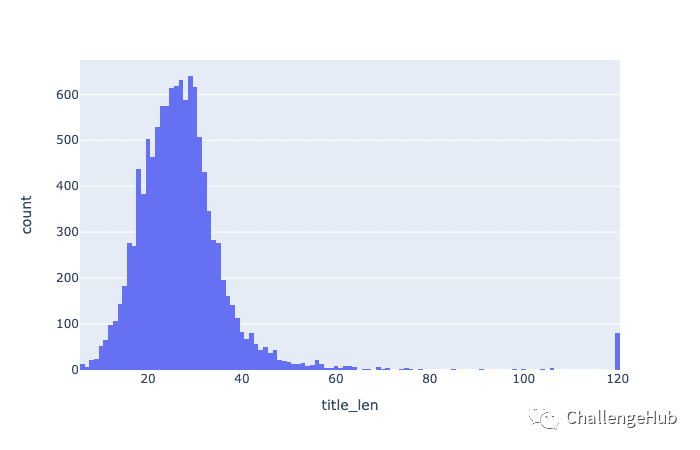
新闻标题最小长度为6,最大长度为120,平均长度为28。
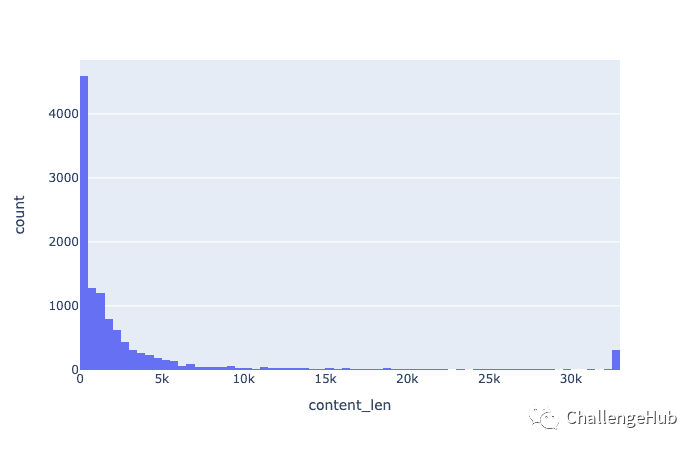
新闻内容的长度分布
train_df['content_len']=train_df['CONTENT'].apply(lambda x:len(x))
train_df['content_len'].describe()
可以看到的是新闻内容存在过长文本,并且严重超过了现有模型的输入长度
count 11685.000000
mean 3324.683098
std 6741.110801
min 4.000000
25% 31.000000
50% 979.000000
75% 2807.000000
max 32767.000000
Name: content_len, dtype: float64
通过查看文本,我们可以看到,新闻内容中存在大量html代码标签,我们可以通过正则表达式re和BeautifulSoup进行去除无关标签
# 方式1
import re
pattern = re.compile(r'<[^>]+>',re.S)
result = pattern.sub('', train_df['CONTENT'][11683])
print("".join(result.split()))
# 方式2
from bs4 import BeautifulSoup
cleantext = BeautifulSoup(train_df['CONTENT'][11683], "lxml").text
cleantext
处理前后的文本对比

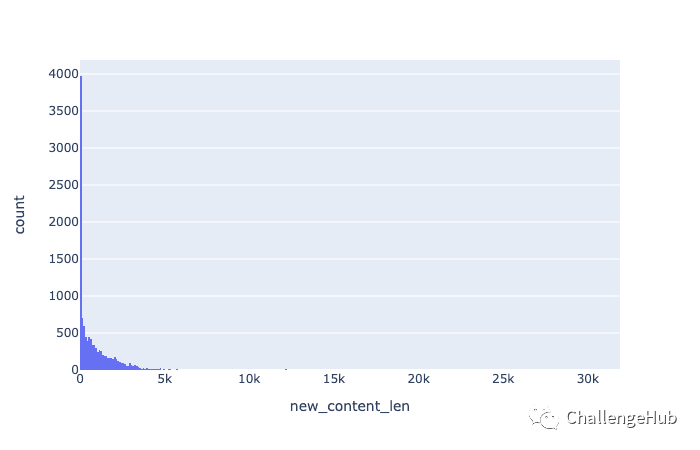
清洗文本之后,文本长度缩减一半:
train_df['content_len'].describe()
count 11685.000000
mean 3324.683098
std 6741.110801
min 4.000000
25% 31.000000
50% 979.000000
75% 2807.000000
max 32767.000000
Name: content_len, dtype: float64
train_df['new_content_len'].describe()
count 11685.000000
mean 890.949679
std 1328.754384
min 0.000000
25% 31.000000
50% 424.000000
75% 1298.000000
max 31840.000000
Name: new_content_len, dtype: float64
业务标签数量分布
train_df['LABEL'].value_counts()
无 3042
实控人变更 811
信息披露违规 800
重大诉讼仲裁 800
股票质押率过高 799
主板/创业板/中小板/债券退市 799
被政府职能部门处罚 799
债务逾期 798
被监管机构罚款或查处 796
被采取监管措施 796
破产重整 796
安全事故 326
环境污染 323
Name: LABEL, dtype: int64
从上面可以看出,不存在金融事件样本“无”所占比列最多,有3042个样本;其次是“信息披露违规 ”和“重大诉讼仲裁”,都是800个样本,出现次数最少的两个类别是“安全事故”和“环境污染 ”。
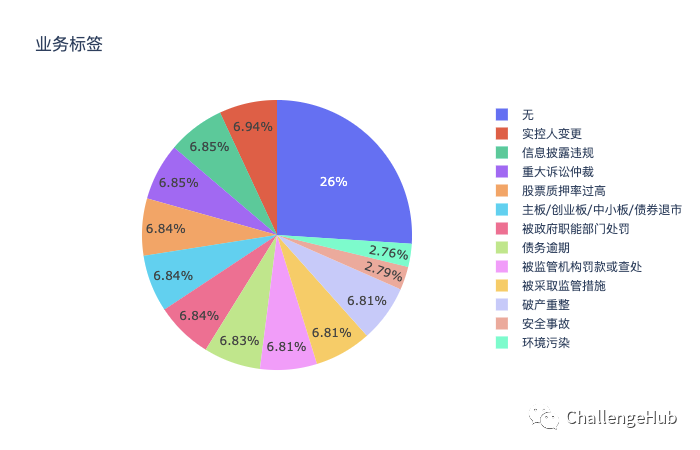
另外我们从业务标签字面我们可以看到的是大部分业务标签界限还是比较清晰的,但是“被监管机构罚款或查处 ”和“被采取监管措施”这两个类别的界限还是比较模糊的,这个也是我们提分的一个地方:

基于预训练模型的多任务学习
基于bert_multitask_learning进行标签分类和实体识别的联合任务训练,首先构建输入,
import bert_multitask_learning
from bert_multitask_learning.preproc_decorator import preprocessing_fn
from bert_multitask_learning.params import BaseParams
@preprocessing_fn
def toy_cls(params: BaseParams, mode: str):
"Simple example to demonstrate singe modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = ['this is a test' for _ in range(10)]
toy_target = ['a' if i <=5 else 'b' for i in range(10)]
else:
toy_input = ['this is a test' for _ in range(10)]
toy_target = ['a' if i <=5 else 'b' for i in range(10)]
return toy_input, toy_target
@preprocessing_fn
def toy_seq_tag(params: BaseParams, mode: str):
"Simple example to demonstrate singe modal tuple of list return"
if mode == bert_multitask_learning.TRAIN:
toy_input = ['this is a test'.split(' ') for _ in range(10)]
toy_target = [['a', 'b', 'c', 'd'] for _ in range(10)]
else:
toy_input = ['this is a test'.split(' ') for _ in range(10)]
toy_target = [['a', 'b', 'c', 'd'] for _ in range(10)]
return toy_input, toy_target
processing_fn_dict = {'toy_cls': toy_cls, 'toy_seq_tag': toy_seq_tag}
创建多任务实例并进行实例
from bert_multitask_learning import train_bert_multitask, eval_bert_multitask, predict_bert_multitask
problem_type_dict = {'toy_cls': 'cls', 'toy_seq_tag': 'seq_tag'}
problem = 'toy_cls&toy_seq_tag'
# train
model = train_bert_multitask(
problem=problem,
num_epochs=1,
problem_type_dict=problem_type_dict,
processing_fn_dict=processing_fn_dict,
continue_training=True
)
模型验证与预测
eval_dict = eval_bert_multitask(problem=problem,
problem_type_dict=problem_type_dict, processing_fn_dict=processing_fn_dict,
model_dir=model.params.ckpt_dir)
print(eval_dict)
# predict
fake_inputs = ['this is a test'.split(' ') for _ in range(10)]
pred, model = predict_bert_multitask(
problem=problem,
inputs=fake_inputs, model_dir=model.params.ckpt_dir,
problem_type_dict=problem_type_dict,
processing_fn_dict=processing_fn_dict, return_model=True)
for problem_name, prob_array in pred.items():
print(f'{problem_name} - {prob_array.shape}')
完整教程可以查看官网:https://jayyip.github.io/bert-multitask-learning/tutorial.html
提分点
企业实体提取:
实体出现位置 实体存在不是公司 集团结尾 实体中存在括号 实体可能为空 与 业务标签有关系 LABEL 过长实体 嵌套连续实体解决
比赛中可能用到的NER Trick
Q1、如何快速有效地提升NER性能?
如果1层lstm+crf,这么直接的打开方式导致NER性能达不到业务目标,这一点也不意外(这是万里长征的第一步~)。这时候除了badcase分析,不要忘记一个快速提升的重要手段:规则+领域词典。
在垂直领域,一个不断积累、不断完善的实体词典对NER性能的提升是稳健的,基于规则+词典也可以快速应急处理一些badcase;对于通⽤领域,可以多种分词工具和多种句法短语⼯具进行融合来提取候选实体,并结合词典进行NER。
Q2、如何构建引入词汇信息(词向量)的NER?
将词向量引入到模型中,一种简单粗暴的做法就是将词向量对齐到相应的字符,然后将字词向量进行混合,但这需要对原始文本进行分词(存在误差),性能提升通常是有限的。我们知道中文NER通常是基于字符进行标注的,这是由于基于词汇标注存在分词误差问题。但词汇边界对于实体边界是很有用的,我们该怎么把蕴藏词汇信息的词向量“恰当”地引入到模型中呢?
Q3、如何解决NER实体span过长的问题?
如果NER任务中某一类实体span比较长(⽐如医疗NER中的⼿术名称是很长的),直接采取CRF解码可能会导致很多连续的实体span断裂。除了加入规则进行修正外,这时候也可尝试引入指针网络+CRF构建多任务学习解决。
指针网络会更容易捕捉较长的span,不过指针网络的收敛是较慢的,可以对CRF和指针网络设置不同学习率,或者设置不同的loss权重。
Q4、如何客观看待BERT在NER中的作用?
在竞赛任务中,BERT很有用!我们可以选取不同的预训练语⾔模型在底层进行特征拼接。具体地,可以将char、bigram和BERT、XLNet等一起拼接喂入1层lstm+crf中。语⾔模型的差异越⼤,效果越好。如果需要对语言模型finetune,需要设置不同的学习率。
业务标签识别:
被采取监管措施 vs 被监管机构罚款或查处 统计特征:其他新闻字段统计,html标签分析
资料推荐
天池中药说明书实体识别挑战冠军方案开源 https://github.com/z814081807/DeepNER 2020阿里云tianchi零基础入门NLP比赛: rank4选手总结 https://github.com/MM-IR/rank4_NLP_textclassification 刷爆3路榜单,信息抽取冠军方案分享:嵌套NER+关系抽取+实体标准化 https://zhuanlan.zhihu.com/p/326302618 流水的NLP铁打的NER:命名实体识别实践与探索 https://zhuanlan.zhihu.com/p/166496466 工业界如何解决NER问题?12个trick,与你分享~ https://zhuanlan.zhihu.com/p/152463745 中文NER的正确打开方式: 词汇增强方法总结 (从Lattice LSTM到FLAT) https://zhuanlan.zhihu.com/p/142615620
