
NLP的“第四范式”之Prompt Learning总结:44篇论文逐一梳理
作者 | 杨浩 @阿里达摩院
研究方向 | 自然语言处理
整理 | Paperweekly


论文整理——按照时间线
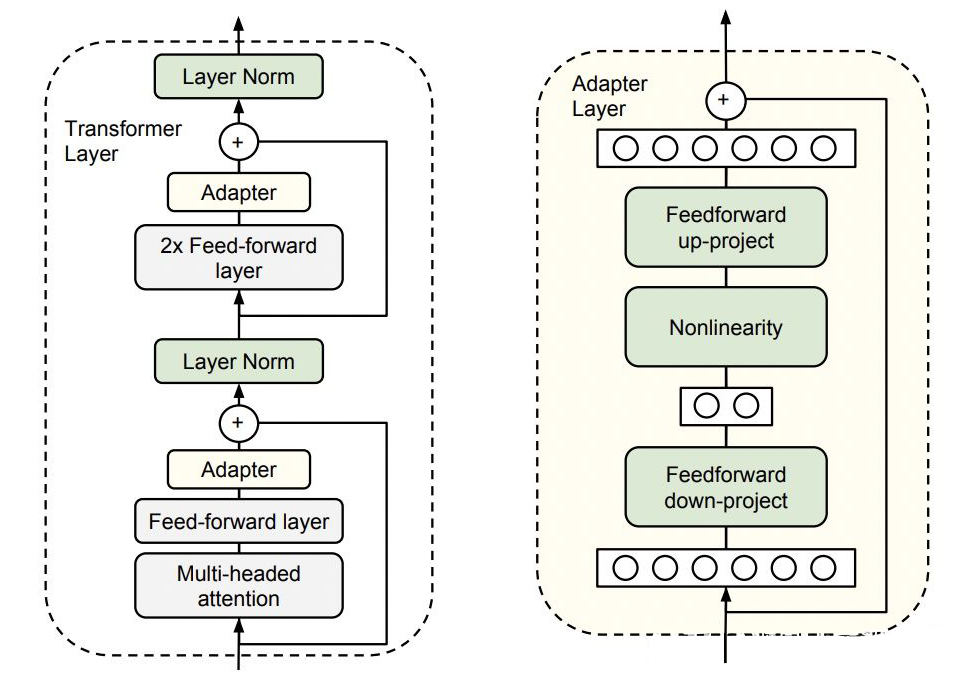
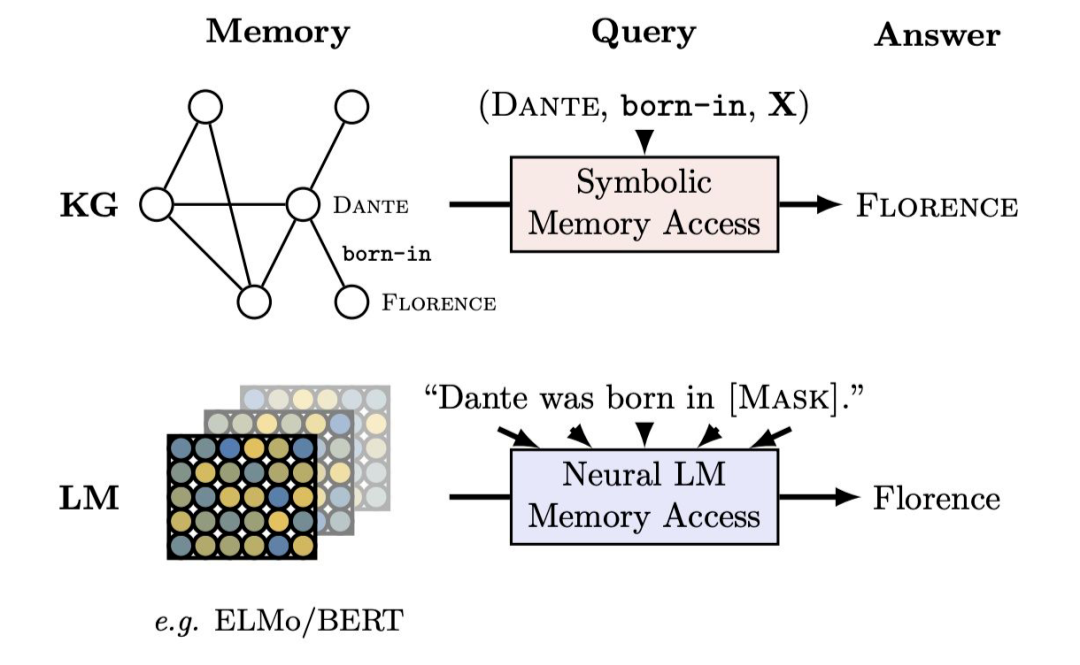
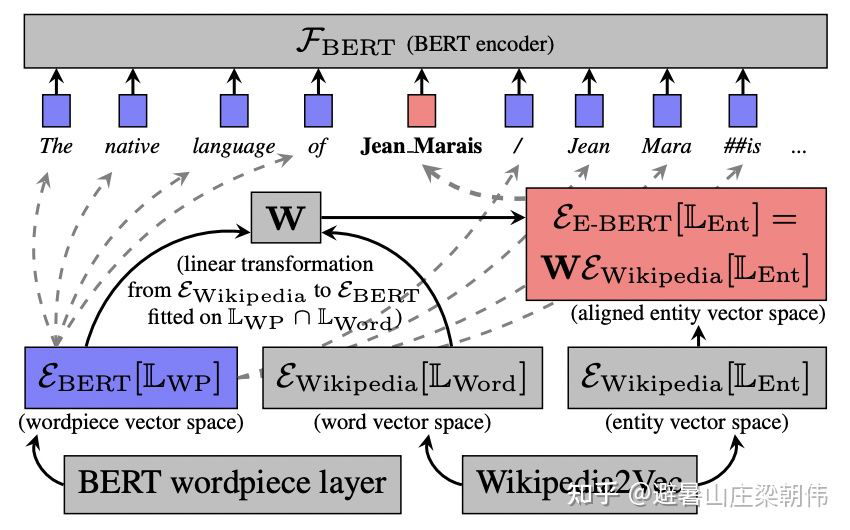
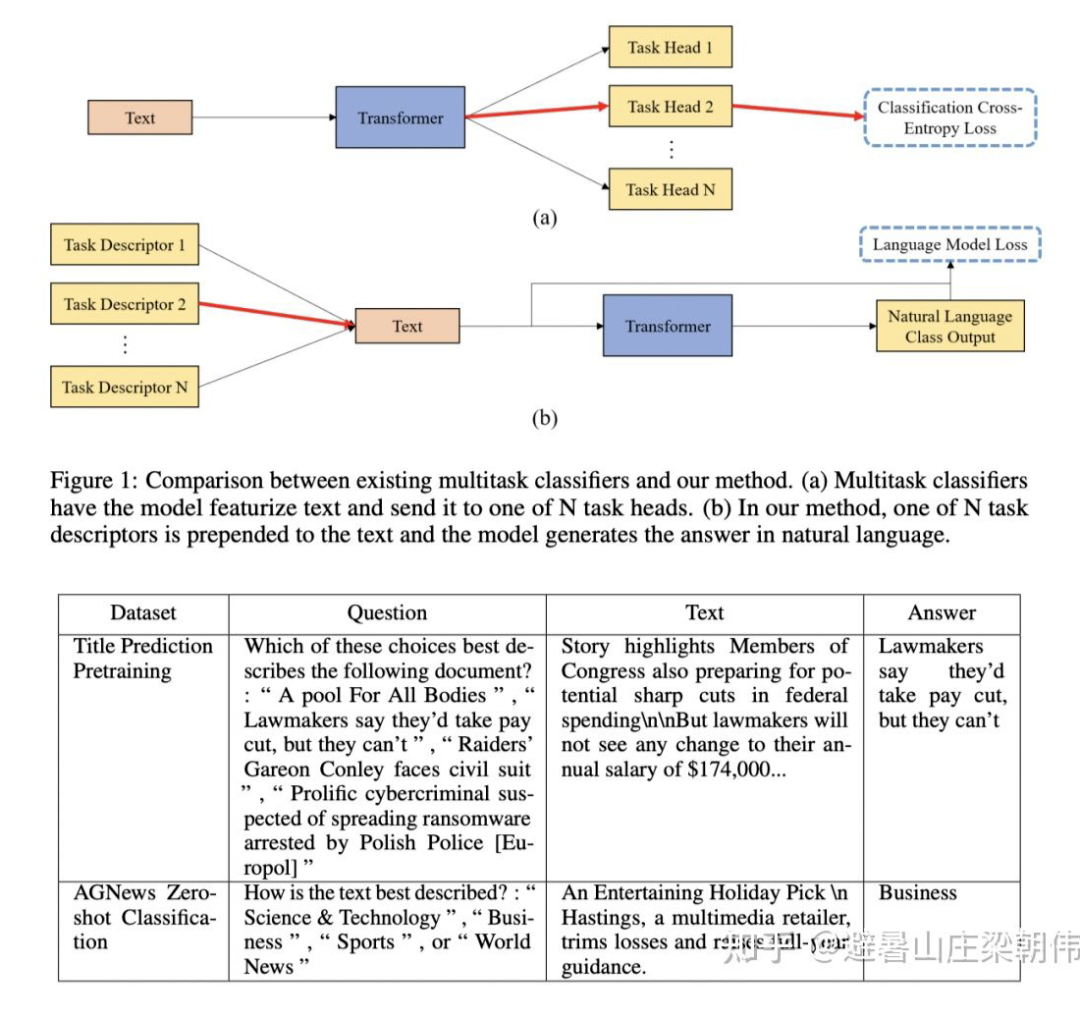


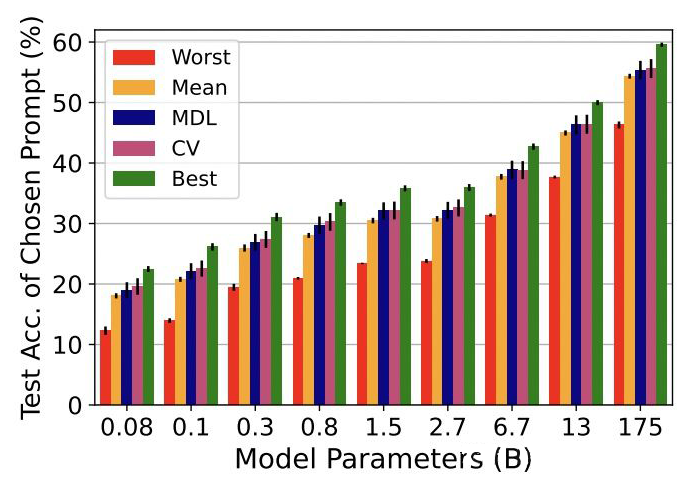
method:

motivation:
adapter 的延续,将原来的参数上增加新参数(L0 正则约束稀疏性)
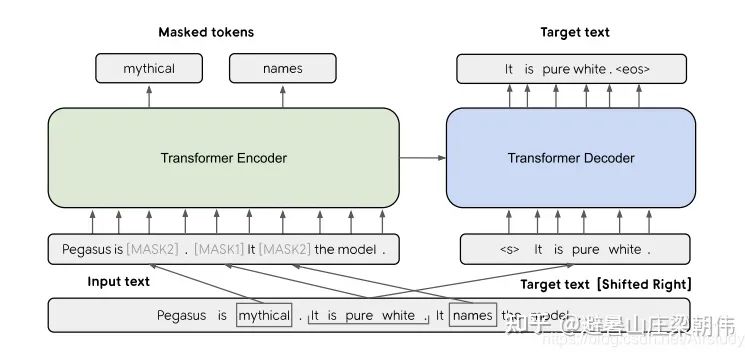
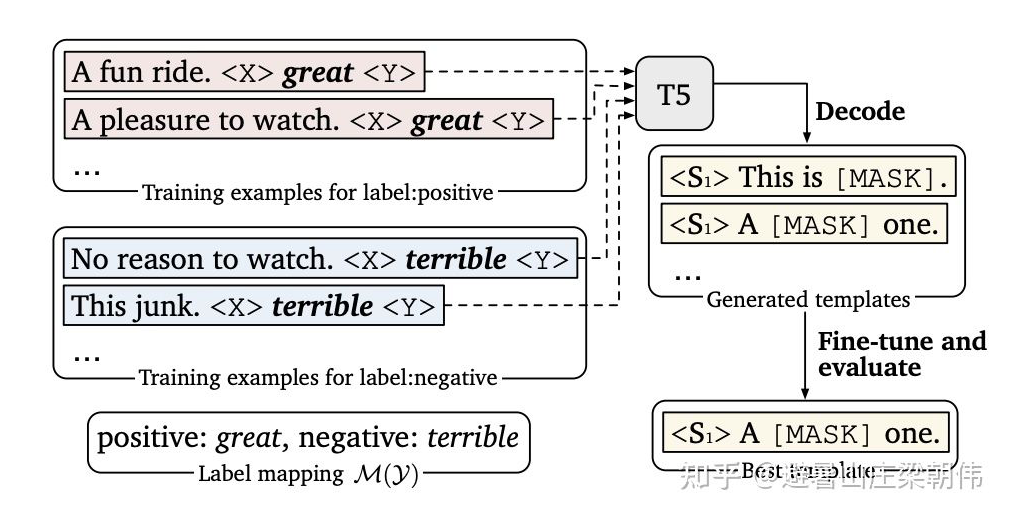
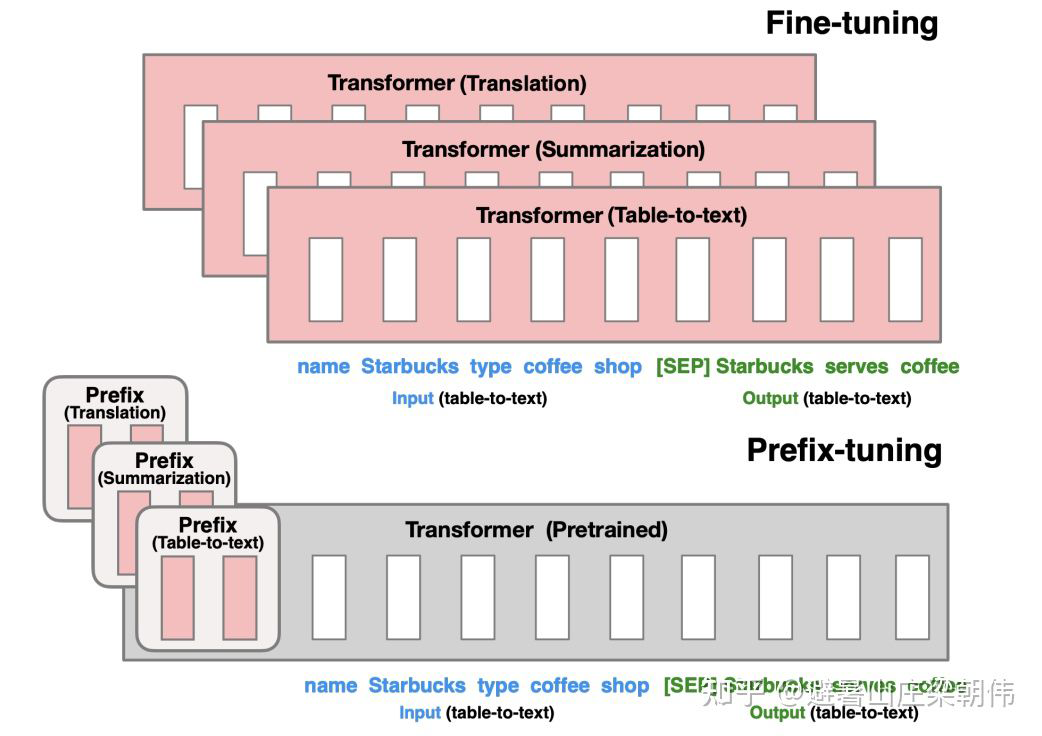


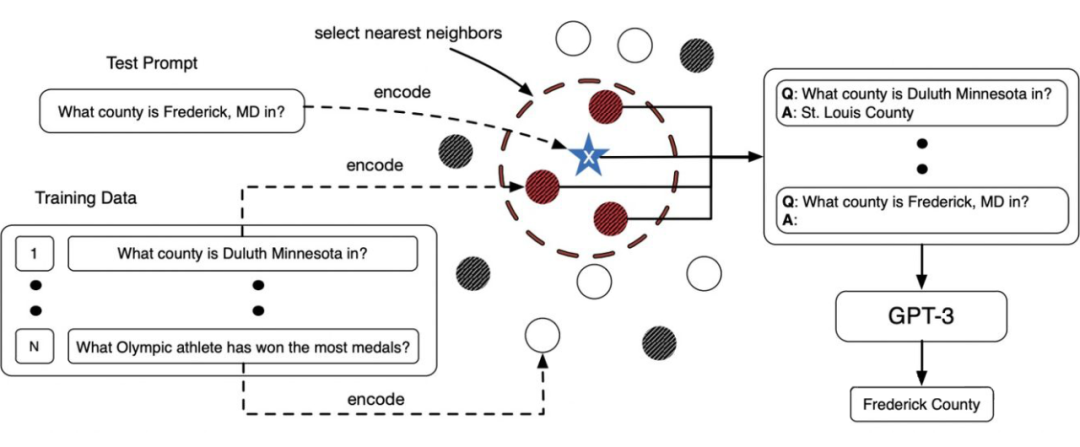
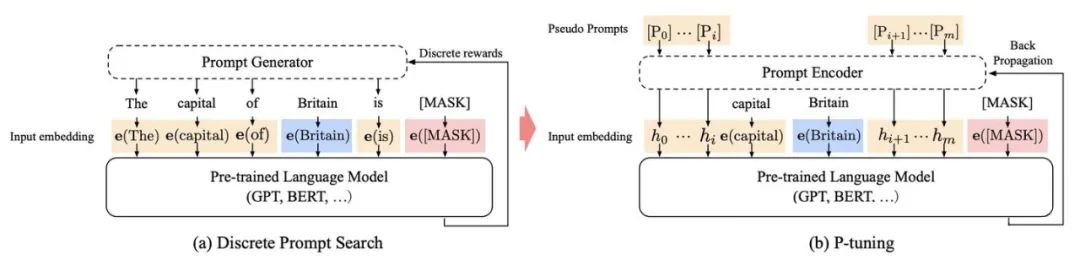


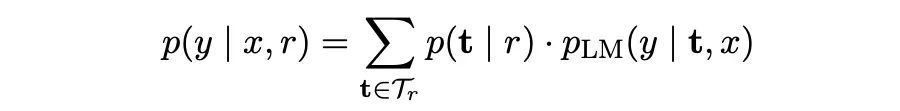





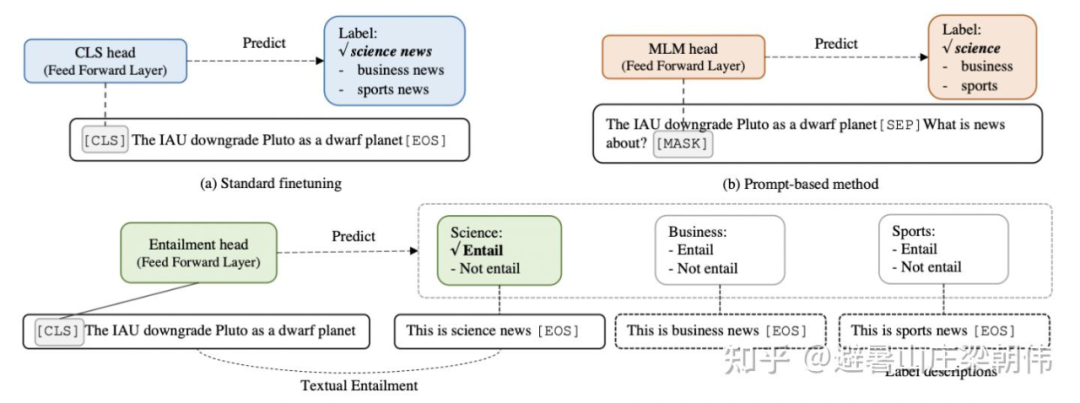
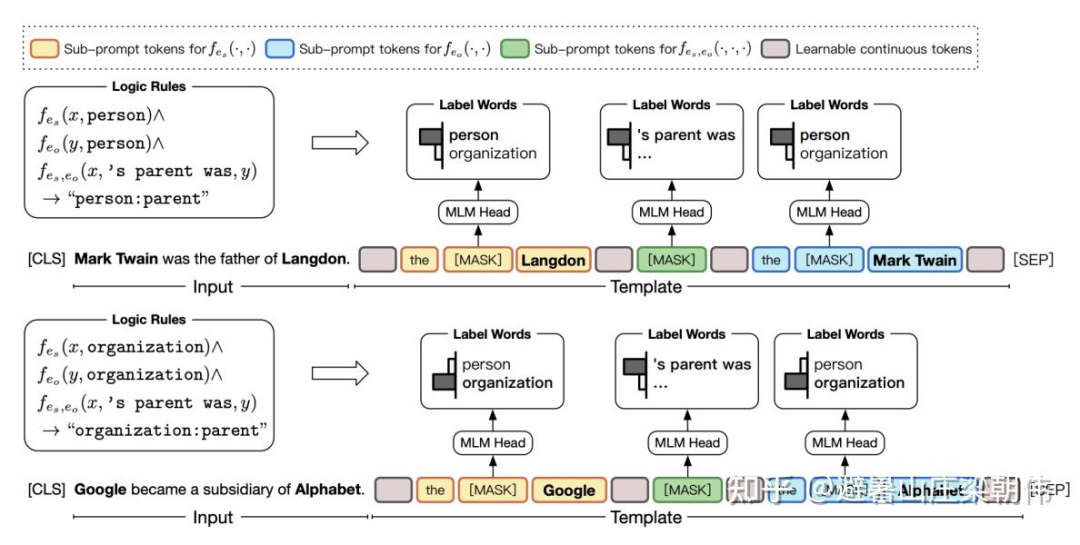
method:

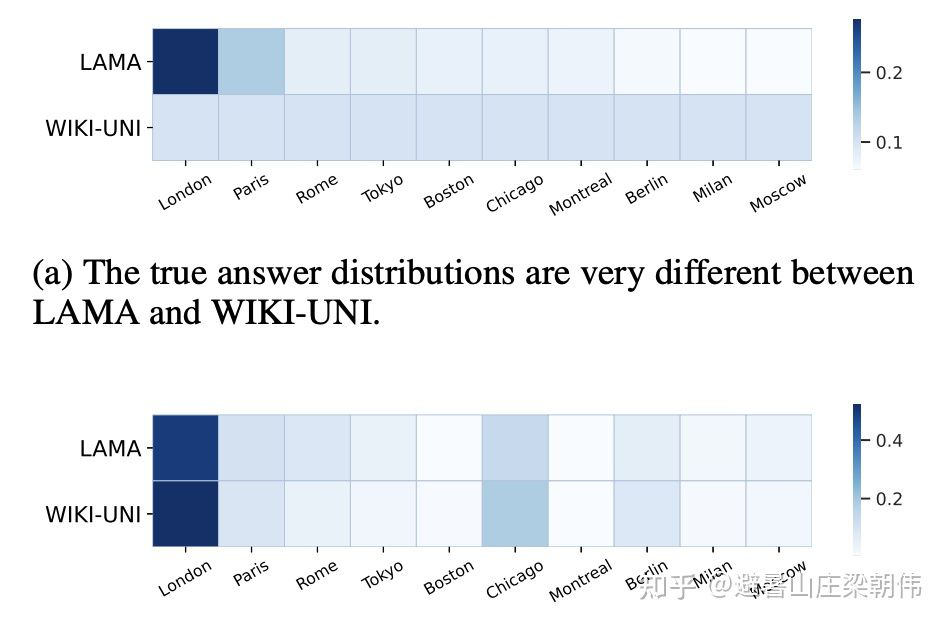
motivation:
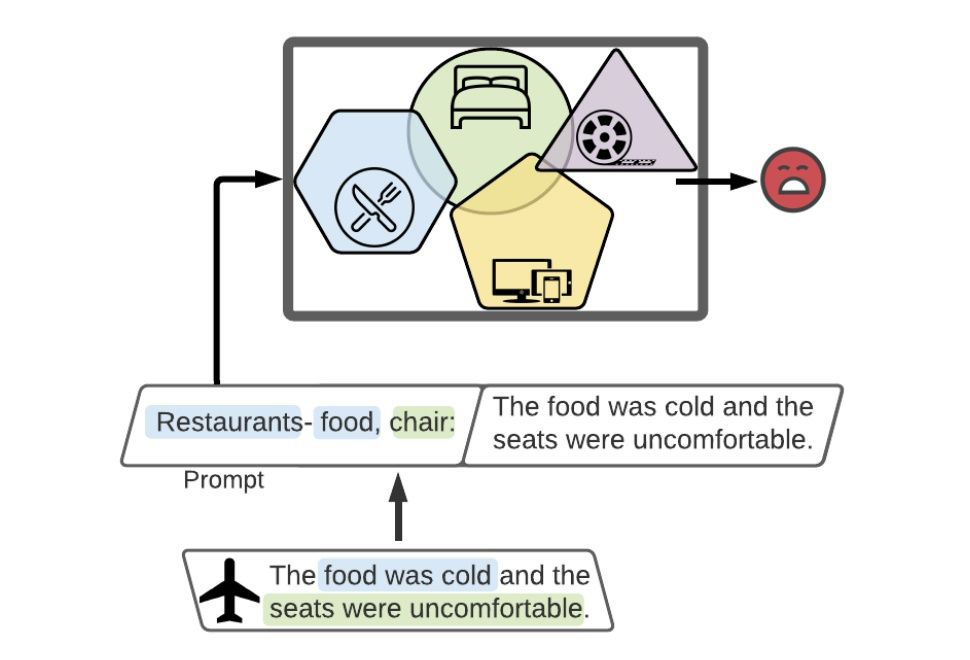
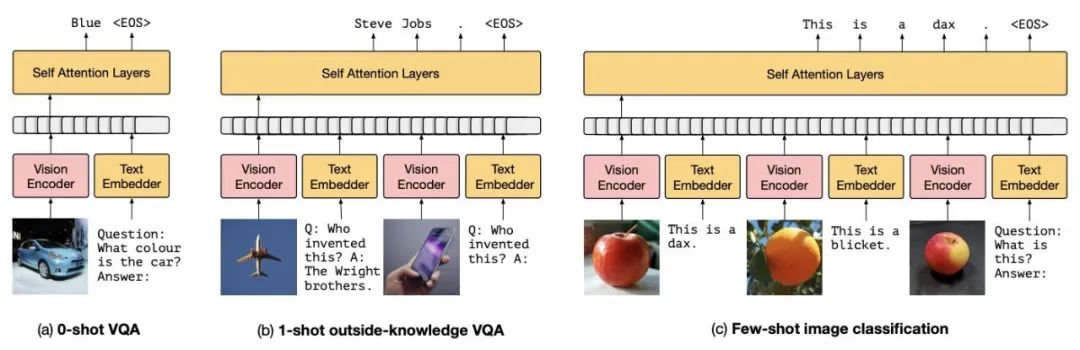
基于 prompt-tuning 的多模态小样本学习模型
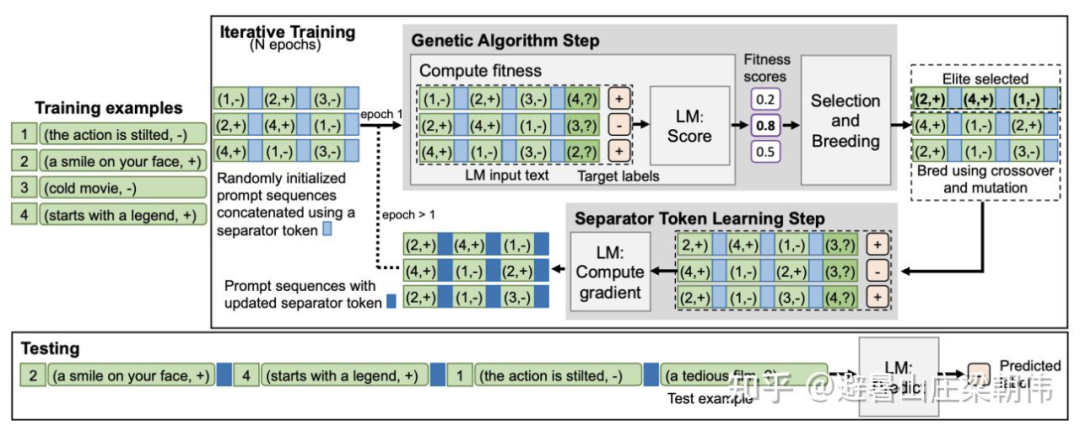
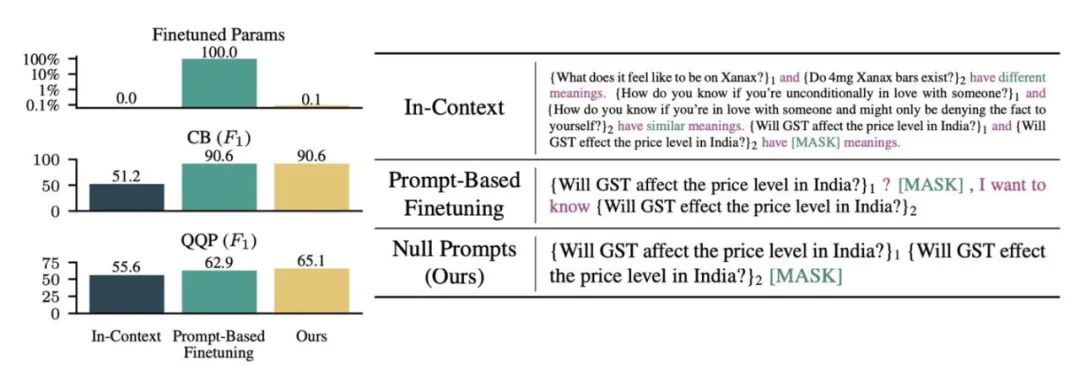
motivation:
method:
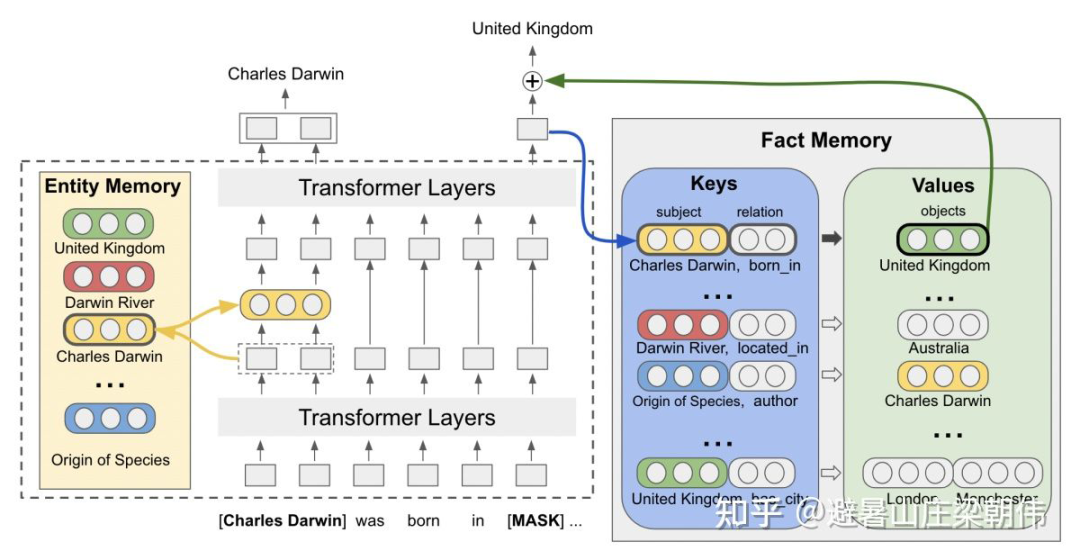
motivation:


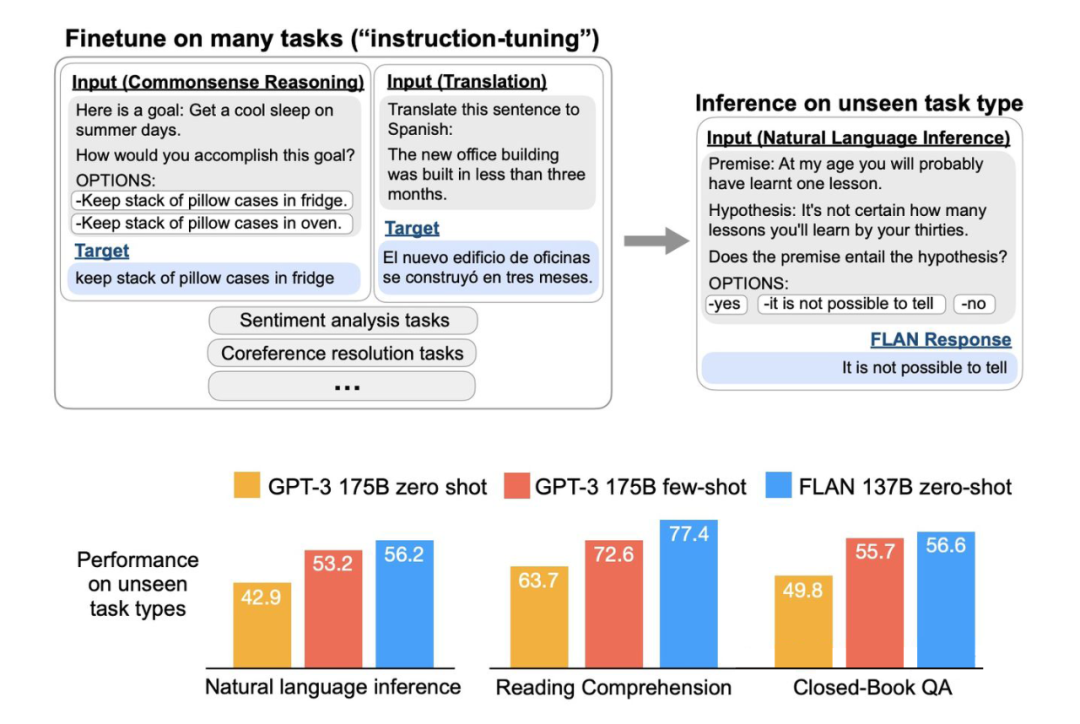
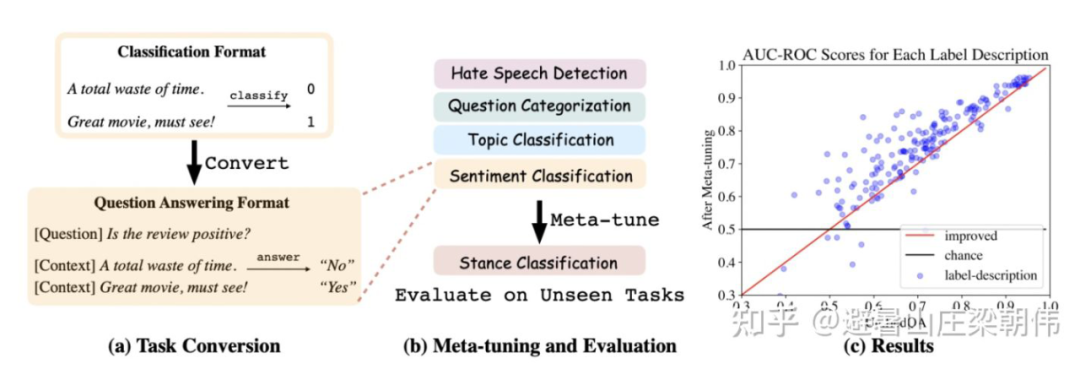
prompt pretraining 用于下游任务,提供好的初始化 prompt,使得效果更稳定

motivation:
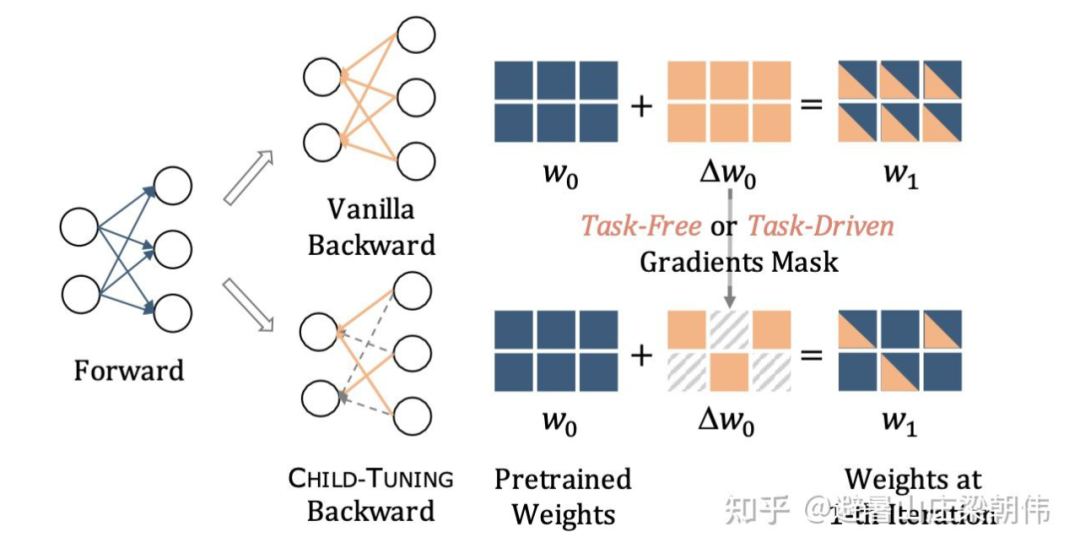
利用大规模预训练模型提供的强大知识,决海量参数与少量标注样本的不匹配问题,在前向传播的时候保持与正常 fine-tune 一样,利用整个模型的参数来编码输入样本;在后向传播传播更新参数的时候,无需利用少量样本来调整海量参数,而是仅仅更新这么庞大的参数网络中的一部分,即网络中的一个 Child Network。在 full-shot 和 few-shot 上超过 finetune。整个方法没有利用 prompt。
Step1:在预训练模型中发现确认 Child Network,并生成对应的 Gradients Mask;
Step2:在后向传播计算完梯度之后,仅仅对 Child Network 中的参数进行更新,而其他参数保持不变。
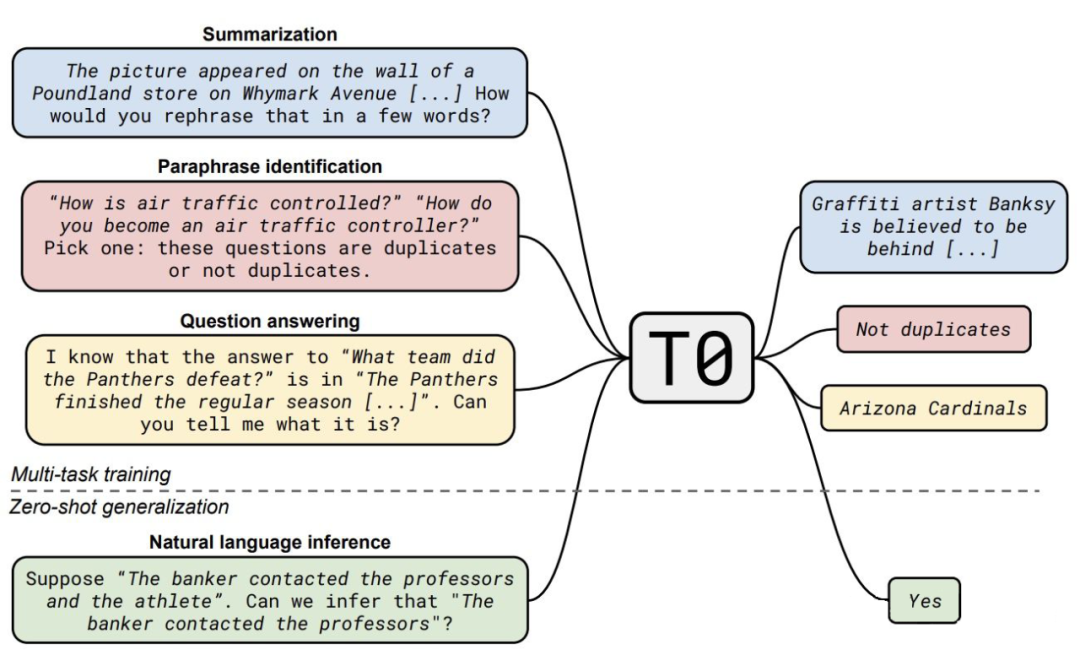

总结
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)
- END -

2021-11-03
2021-11-02
2021-11-01


评论