多模态3D目标检测发展路线方法汇总!(决策级/特征级/点/体素融合)
什么是多模态3D目标检测?
多模态3D目标检测是当前3D目标检测研究热点之一,主要是指利用跨模态数据提升模型的检测精度。一般而言,多模态数据包含:图像数据、激光雷达数据、毫米波雷达数据、双目深度数据等,本文主要关注于当前研究较多的RGB+LiDAR融合3D目标检测模型进行汇总和总结,希望可以给大家带来一定的启发。
多模态3D目标检测主要方法
(一) 决策级融合 (Decision-level)
所谓的决策级融合,一般而言是指直接利用2D/3D基础网络的检测结果,为后续bounding box的优化提供初始位置。决策级融合的优点是:仅对不同模态的输出进行多模态融合,避免了中间特征或输入点云上复杂的交互,因此往往更加高效。但是,也面临一定的缺陷:由于不依赖于相机和激光雷达传感器的深度特征,这些方法无法整合不同模式的丰富语义信息,限制了这类方法的潜力。
论文标题:CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
论文地址:https://arxiv.org/pdf/2009.00784.pdf
作者单位:Su Pang等,Michigan State University
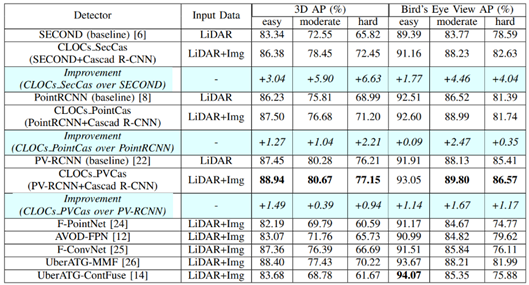
核心思想:作者认为,对于决策级的融合而言,多模态数据不需要与其他模态进行同步或对齐,且利用二者的检测结果排除了大部分冗余背景区域,因此更有助于网络学习。
方法简述:
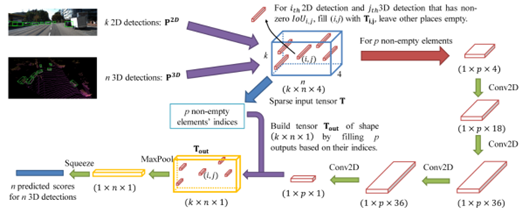
如上图所示,CLOCs整体流程可分为3步:
步骤1:分别输入图像和点云,分别预测2D detections和3D detections; 步骤2:去除部分IoU=0的候选框,对保留的候选框进行特征提取; 步骤3:得到最终的检测结果。
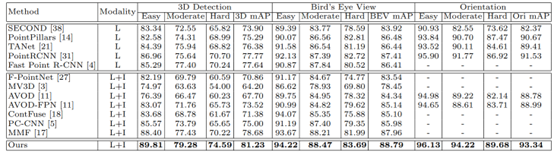
方法相对而言比较简单,从步骤1也能清晰看出,CLOCs是利用检测结果进行的跨模态融合,因此属于决策级融合的范畴。在KITTI testset的检测结果如下图所示,在多模态方法中还是比较具有竞争力的。
论文标题:Frustum Pointnets for 3D Object Detection from RGB-D Data
论文地址:https://arxiv.org/pdf/1711.08488.pdf
作者单位:Charles R. Qi等,Stanford University
核心思想:作者认为,使用2D目标检测结果生成3D锥形建议区域,省略直接在大范围的空间中检索,同时提升了目标的识别准确度。
方法简述:
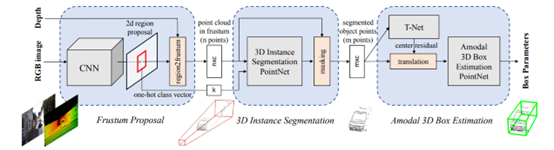
如上图所示,Frustum PointNet整体流程可分为3步:
步骤1:通过2D网络预测2D Proposal; 步骤2:将2D Proposal映射为3D锥体,作为后续3D检测的建议区域; 步骤3:在步骤2提取出的建议区域中,进行通用3D检测流程;
同样,整体思路也比较简单清晰,从步骤1也能看出,Frustum PointNet是利用2D检测结果,为3D检测提供initial region,因此,大大减少了3D搜索空间。从网络流程上看,更为简洁高效。同时,由于拥有2D proposal提供的初始位置,3D网络的搜索位置也更为准确,整体检测性能也略有提高,在KITTI testset的检测结果如下图所示,

(二) 特征级融合 (Feature-level)
所谓的特征级融合,就是在基于LiDAR的3D目标检测器的中间阶段,例如在骨干网络中,或在proposal生成阶段,或在RoI细化阶段,融合图像和激光雷达特征。
1. 感兴趣区域融合 (RoI-level)
感兴趣区域融合,通常是指:通过LiDAR检测器生成3D目标的proposals,这些3D的proposals被映射到多种视图中,例如鸟瞰图或者RGB图中。再分别从Image和LiDAR的主干网络中裁剪出特征,得到RoI Features,最后将Image RoI Features 和 LiDAR RoI Features 融合,并输入到RoI 头,输出每个3D目标的参数。
论文标题:Multi-View 3D Object Detection Network for Autonomous Driving
论文地址:https://arxiv.org/pdf/1611.07759.pdf
作者单位:Xiaozhi Chen等,Tsinghua University
核心思想:利用点云俯视图、点云前视图、图像数据进行融合,这样既能减少计算量,又不至于丧失过多的信息。
方法简述:
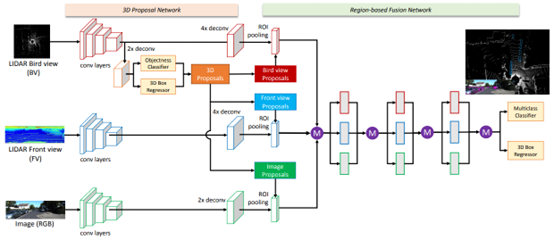
如上图所示,MV3D整体流程可分为4步:
步骤1:利用卷积网络分别在点云前视图、点云俯视图和图像数据上提取特征; 步骤2:在点云俯视图上进行proposal生成; 步骤3:将生成的3D proposal分别在不同模态数据中进行特征提取; 步骤4:将多模态proposal特征进行融合检测;
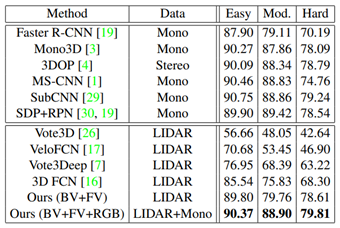
从步骤3也能看出,MV3D是利用点云俯视图生成的3D检测结果,在不同模态数据上进行特征提取,因此属于RoI-level的融合方式。在KITTI testset中,这种多模态融合方式也具有显著的优势。尤其是当增添了图像数据后,整体网络在Moderate子集上有了明显的性能提升,具体实验结果如下图所示:
论文标题:Joint 3D Proposal Generation and Object Detection from View Aggregation
论文地址:https://arxiv.org/pdf/1712.02294.pdf
作者单位:Jason Ku等,University of Waterloo
核心思想:借鉴了FPN思想,通过高分辨率特征提升检测性能。
方法简述:
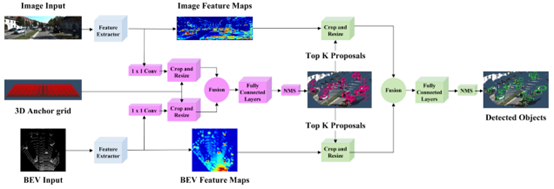
如上图所示,AVOD整体流程可以分为4步:
步骤1:分别提取图像和俯视图特征; 步骤2:利用融合后的特征提取3D Proposals; 步骤3:将生成的3D proposal分别在不同模态数据中进行特征提取; 步骤4:将多模态proposal特征进行融合检测;
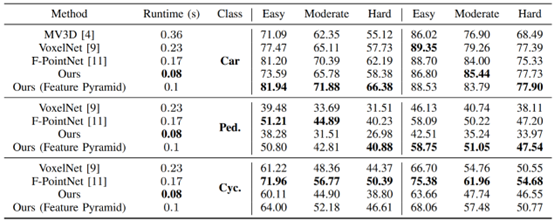
从上述步骤也能看出,整体检测流程与MV3D并无明显区别。主要区分点在于:其一,AVOD借鉴了FPN的特征提取方法,提取出的特征更加高效;其二,设计了10维bounding box编码策略,通过ground plane和top bottom corner center进行编码,更加简介高效。整体网络性能在KITTI上表现较好,尤其是对于Pedestrian和Cyclist两类,如下图所示:
论文标题:Cross-Modality 3D Object Detection
论文地址:https://arxiv.org/pdf/2008.10436.pdf
作者单位:Ming Zhu等,Shanghai Jiao Tong University
核心思想:提出了一种2D-3D耦合损耗,以充分利用图像信息,约束3D Bounding box与2D Bounding box一致。
方法简述:
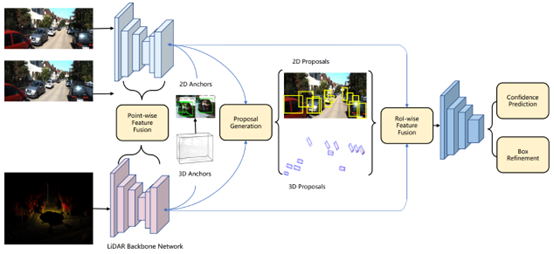
如上图所示,整体方法可分为4步:
步骤1:利用卷积网络分别在点云和图像数据上提取特征; 步骤2:利用提取出的特征提取2D Proposal和3D Proposal; 步骤3:对生成的2D和3D Proposal进行一致性约束; 步骤4:对约束后的proposal特征进行融合检测;
从步骤2也能看出,此方法是利用生成的2D和3D检测结果,在不同模态数据上进行特征提取,因此属于RoI-level的融合方式。方法的不同之处在于,作者提出了一种2D-3D的耦合损耗,用于约束3D和2D场景下Proposal的一致性。此方法在KITTI上有明显的提升,具体结果如下图所示:
论文标题:Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
论文地址:https://arxiv.org/pdf/2203.09780.pdf
作者单位:Xiaopei Wu等,Zhejiang University
核心思想:多模态特征加权融合,以及跨模态对齐问题。
方法简述:
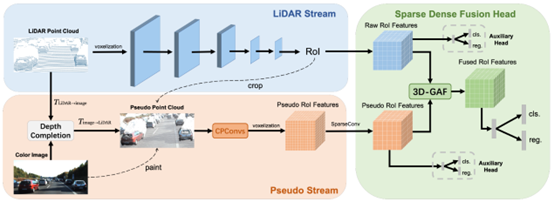
如上图所示,整体方法可以分为4步:
步骤1:利用深度补全网络,将原始RGB图像映射到3D场景中,生成伪点Pseudo Points; 步骤2:提取原始3D点云特征,并生成候选框; 步骤3:对每一个候选框,分别提取点云特征和伪点云特征; 步骤4:对点云特征和伪点云特征进行重新加权,并输出最后的检测结果;
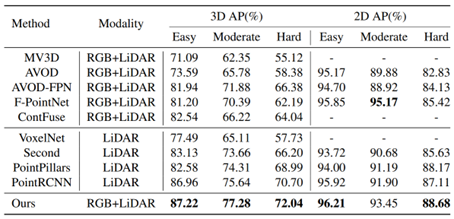
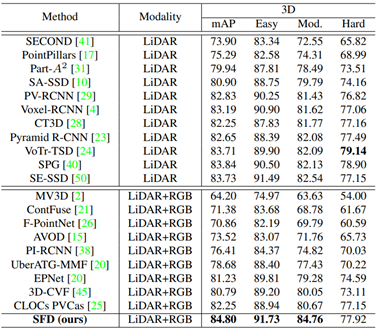
从步骤2可以看出,SFD利用的是3D场景预测出的候选框,并在不同模态数据上进行特征提取,因此属于RoI-level的融合范畴。此方法不同之处在于:其一,在网络预处理阶段,将跨模态数据增广进行了对齐,因此特征更加一致,其二,对候选框的多模态特征进行了加权,输出更鲁棒的fusion feature。此方法在KITTI testset具有非常优越的性能,具体实验结果如下图所示:
2. 点/体素融合 (Point/Voxel-level)
点/体素融合通常是指,对于点云场景中的每一个点或每一个体素框,利用其余模态特征对齐进行补全。这种补全往往是更精细化的,更全面的,但是也因此导致效率往往不是很高。
论文标题:Multi-task Multi-Sensor Fusion for 3D Object Detection
论文地址:https://arxiv.org/pdf/2012.12397.pdf
作者单位:Ming Liang等,Uber Advanced Technologies Group
核心思想:pixel-point层面的融合方式,同时增加了深度估计模块。
方法简述:
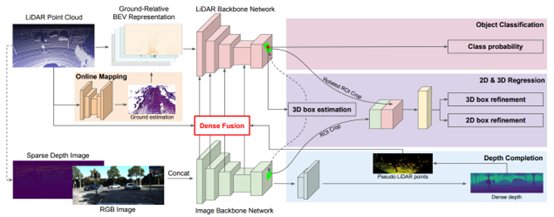
如上图所示,整体方法可分为4步:
步骤1:分别对点云和图像提取特征; 步骤2:利用Dense Fusion模块,在网络不同层级上进行特征融合; 步骤3:利用融合后的特征计算initial proposal; 步骤4:预测bounding box和深度图;
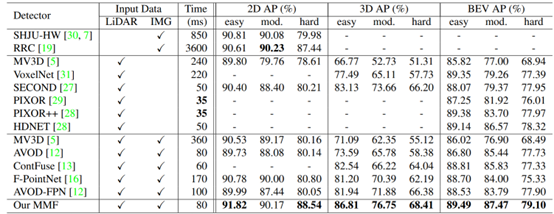
从步骤2可以看出,MMF是在基础网络的不同阶段进行的特征融合,属于全场景融合,因此可划分为Point/Voxel-level。后续的检测流程与通用的3D检测没有明显区域,只是额外添加了深度预测支路,用于图像到点云的映射校准。作者同样给出了KITTI testset的检测结果,如下图所示:
论文标题:MVX-Net: Multimodal VoxelNet for 3D Object Detection
论文地址:https://arxiv.org/pdf/1904.01649.pdf
作者单位:Vishwanath A. Sindagi等,Johns Hopkins University
核心思想:网络初期融合,以提取更丰富鲁棒的特征。
方法简述:
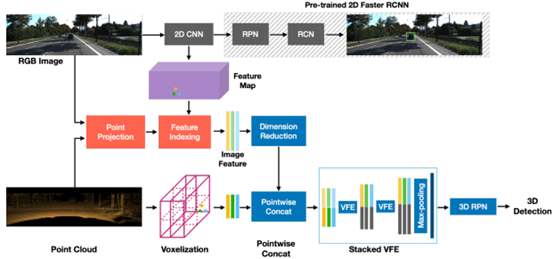
如上图所示,整体方法可分为3步:
步骤1:分别对点云和图像提取特征; 步骤2:找到3D体素和2D图像的对应关系,进行对应的特征融合; 步骤3:利用融合后的特征预测3D检测结果;
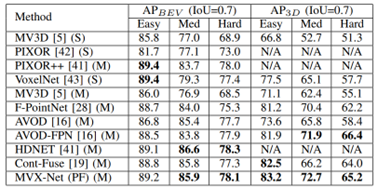
从步骤2可以看出,作者同样做的场景层面的融合,而非proposal/bbox的融合,因此属于Point/Voxel-level。整体网络框架也比较简单,在KITTI testset上有一定的性能提升,如下图所示:
论文标题:Pointpainting: Sequential Fusion for 3D Object Detection
论文地址:https://arxiv.org/pdf/1911.10150.pdf
作者单位:Sourabh Vora等,nuTonomy
核心思想:利用细粒度图像分割信息对3D点云进行补全;
方法简述:
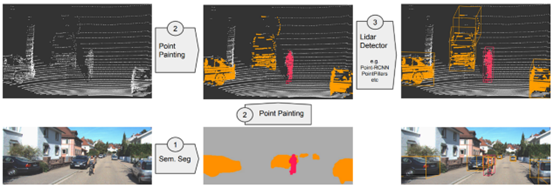
如上图所示,整体方法可分为3步:
步骤1:对2D图像进行分割预测; 步骤2:将2D中预测出的分割结果投影到对应的3D point中,对原始3D信息进行补全; 步骤3:利用补全后的3D点云进行预测;
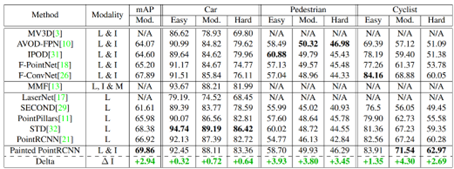
从步骤2可以看出,作者尝试对3D场景中每一个点进行信息补全,因此属于point-level的融合方式。PointPainting是比较经典的方法,其思想也被广泛应用在当前的3D检测网络中。虽然方法比较简单,但是性能提升显著,在KITTI testset的实验结果如下图所示:
论文标题:PI-RCNN: An Efficient Multi-Sensor 3D Object Detector with Point-based Attentive Cont-Conv Fusion Module
论文地址:https://arxiv.org/pdf/1911.06084.pdf
作者单位:Liang Xie等,Zhejiang University
核心思想:点云和图像融合过程中的对齐问题(量化误差)。
方法简述:
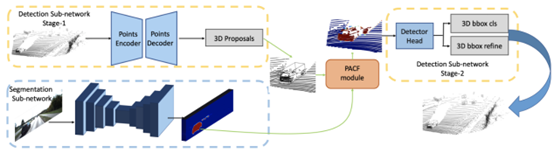
如上图所示,整体方法可分为4步:
步骤1:利用原始点云数据预测3D候选框; 步骤2:利用分割网络预测2D分割结果; 步骤3:利用PACF模块将2D和3D特征进行对齐,减小其量化误差; 步骤4:利用对齐后的特征进行3D bbox预测;
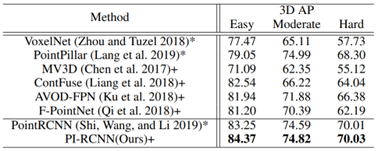
此方法归为Point/Voxel-level类别的主要原因是:作者在PACF模块中,对于点云上的每一个点,都会搜索K个近邻点,并将其投影到分割特征图上。之后,再利用紧邻点的语义信息和点云信息进行特征关联,输出最终的检测结果。所以,本质上讲,PI-RCNN网络属于Point-level的融合方式,在KITTI testset上性能显著,如下图所示:
论文标题:EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection
论文地址:https://arxiv.org/pdf/2007.08856.pdf
作者单位:Tengteng Huang等,Huazhong University of Science and Technology
核心思想:逐层融合,自适应加权多模态特征。
方法简述:
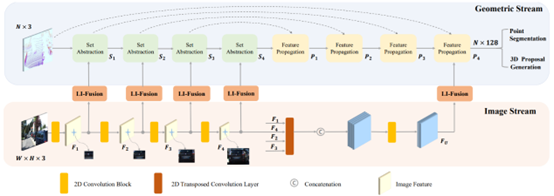
如上图所示,整体方法可分为4步:
步骤1:分别提取图像特征和点云特征; 步骤2:利用LI-Fusion模块对多模态特征进行逐层融合; 步骤3:利用Feature Propagation模块对多模态特征自适应加权; 步骤4:利用加权后的特征进行3D bbox的预测;
从步骤2和步骤3可以看出,作者提出的LIDAR-guided Image Fusion (LI-fusion)模块通过point-wise的方式,建立原始点云和图像间的对应关系,自适应地估计图像语义特征的重要性,用有用的图像特征来增强点云特征,同时抑制有干扰的图像特征。EPNet在KITTI testset上性能具有明显提升,如下图所示: