
谱聚类(spectral clustering)原理总结
日期:2020年10月02日
正文共:4399字1图
预计阅读时间:11分钟
来源:刘建平博客
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也不复杂。在处理实际的聚类问题时,个人认为谱聚类是应该首先考虑的几种算法之一。下面我们就对谱聚类的算法原理做一个总结。
1. 谱聚类概述
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
乍一看,这个算法原理的确简单,但是要完全理解这个算法的话,需要对图论中的无向图,线性代数和矩阵分析都有一定的了解。下面我们就从这些需要的基础知识开始,一步步学习谱聚类。
2. 谱聚类基础之一:无向权重图
由于谱聚类是基于图论的,因此我们首先温习下图的概念。对于一个图GG,我们一般用点的集合V和边的集合E来描述。即为G(V,E)。其中V即为我们数据集里面所有的点(v1,v2,...vn)。对于V中的任意两个点,可以有边连接,也可以没有边连接。我们定义权重wij为点vi和点vj之间的权重。由于我们是无向图,所以wij=wji。
对于有边连接的两个点vi和vj,wij>0,对于没有边连接的两个点vivi和vj,wij=0。对于图中的任意一个点vi,它的度定义为和它相连的所有边的权重之和,即
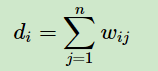
利用每个点度的定义,我们可以得到一个nxn的度矩阵D,它是一个对角矩阵,只有主对角线有值,对应第i行的第i个点的度数,定义如下:
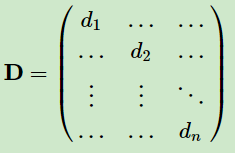
利用所有点之间的权重值,我们可以得到图的邻接矩阵W,它也是一个nxn的矩阵,第i行的第j个值对应我们的权重wij。
除此之外,对于点集V的的一个子集A⊂V,我们定义:
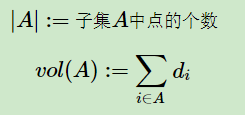
3. 谱聚类基础之二:相似矩阵
在上一节我们讲到了邻接矩阵W,它是由任意两点之间的权重值wij组成的矩阵。通常我们可以自己输入权重,但是在谱聚类中,我们只有数据点的定义,并没有直接给出这个邻接矩阵,那么怎么得到这个邻接矩阵呢?
基本思想是,距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,不过这仅仅是定性,我们需要定量的权重值。一般来说,我们可以通过样本点距离度量的相似矩阵S来获得邻接矩阵W。
构建邻接矩阵W的方法有三类。ϵ-邻近法,K邻近法和全连接法。
对于ϵ-邻近法,它设置了一个距离阈值ϵϵ,然后用欧式距离sijsij度量任意两点xi和xj的距离。即相似矩阵的, 然后根据sij和ϵ的大小关系,来定义邻接矩阵W如下:
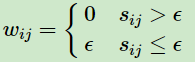
从上式可见,两点间的权重要不就是ϵ,要不就是0,没有其他的信息了。距离远近度量很不精确,因此在实际应用中,我们很少使用ϵ-邻近法。
第二种定义邻接矩阵W的方法是K邻近法,利用KNN算法遍历所有的样本点,取每个样本最近的k个点作为近邻,只有和样本距离最近的k个点之间的wij>0。但是这种方法会造成重构之后的邻接矩阵W非对称,我们后面的算法需要对称邻接矩阵。为了解决这种问题,一般采取下面两种方法之一:
第一种K邻近法是只要一个点在另一个点的K近邻中,则保留sij
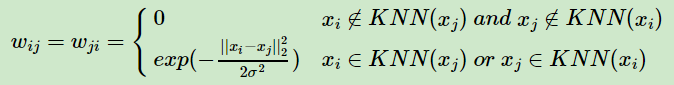
第二种K邻近法是必须两个点互为K近邻中,才能保留sij
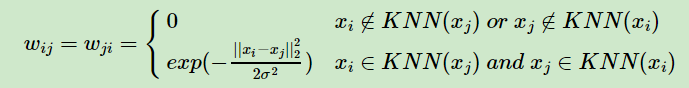
第三种定义邻接矩阵W的方法是全连接法,相比前两种方法,第三种方法所有的点之间的权重值都大于0,因此称之为全连接法。可以选择不同的核函数来定义边权重,常用的有多项式核函数,高斯核函数和Sigmoid核函数。最常用的是高斯核函数RBF,此时相似矩阵和邻接矩阵相同:
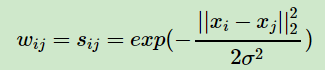
在实际的应用中,使用第三种全连接法来建立邻接矩阵是最普遍的,而在全连接法中使用高斯径向核RBF是最普遍的。
4. 谱聚类基础之三:拉普拉斯矩阵
单独把拉普拉斯矩阵(Graph Laplacians)拿出来介绍是因为后面的算法和这个矩阵的性质息息相关。它的定义很简单,拉普拉斯矩阵L=D−WL=D−W。DD即为我们第二节讲的度矩阵,它是一个对角矩阵。而WW即为我们第二节讲的邻接矩阵,它可以由我们第三节的方法构建出。
拉普拉斯矩阵有一些很好的性质如下:
1)拉普拉斯矩阵是对称矩阵,这可以由DD和WW都是对称矩阵而得。
2)由于拉普拉斯矩阵是对称矩阵,则它的所有的特征值都是实数。
3)对于任意的向量ff,我们有
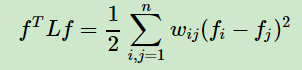
这个利用拉普拉斯矩阵的定义很容易得到如下:
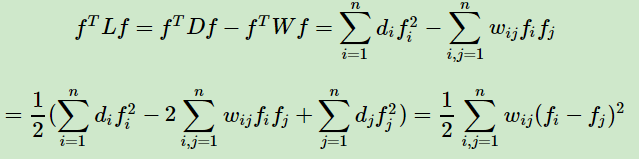
4) 拉普拉斯矩阵是半正定的,且对应的n个实数特征值都大于等于0,即0=λ1≤λ2≤...≤λn,且最小的特征值为0,这个由性质3很容易得出。
5. 谱聚类基础之四:无向图切图
对于无向图GG的切图,我们的目标是将图G(V,E)G(V,E)切成相互没有连接的k个子图,每个子图点的集合为:A1,A2,..Ak ,它们满足Ai∩Aj=∅,且A1∪A2∪...∪Ak=V.
对于任意两个子图点的集合A,B⊂V, A∩B=∅, 我们定义A和B之间的切图权重为:
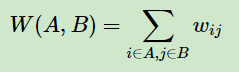
那么对于我们k个子图点的集合:A1,A2,..Ak,我们定义切图cut为:
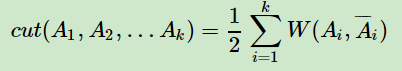
其中为Ai的补集,意为除Ai子集外其他V的子集的并集。
那么如何切图可以让子图内的点权重和高,子图间的点权重和低呢?一个自然的想法就是最小化cut(A1,A2,...Ak), 但是可以发现,这种极小化的切图存在问题,如下图:
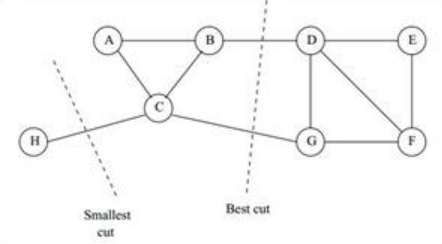
我们选择一个权重最小的边缘的点,比如C和H之间进行cut,这样可以最小化cut(A1,A2,...Ak), 但是却不是最优的切图,如何避免这种切图,并且找到类似图中"Best Cut"这样的最优切图呢?我们下一节就来看看谱聚类使用的切图方法。
6. 谱聚类之切图聚类
为了避免最小切图导致的切图效果不佳,我们需要对每个子图的规模做出限定,一般来说,有两种切图方式,第一种是RatioCut,第二种是Ncut。下面我们分别加以介绍。
6.1 RatioCut切图
RatioCut切图为了避免第五节的最小切图,对每个切图,不光考虑最小化cut(A1,A2,...Ak),它还同时考虑最大化每个子图点的个数,即:
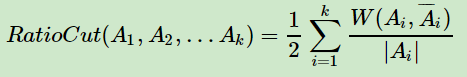
那么怎么最小化这个RatioCut函数呢?牛人们发现,RatioCut函数可以通过如下方式表示。
我们引入指示向量hj∈{h1,h2,..hk}j=1,2,...k,对于任意一个向量hj, 它是一个n维向量(n为样本数),我们定义hij为:
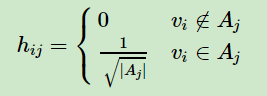
那么我们对于,有:
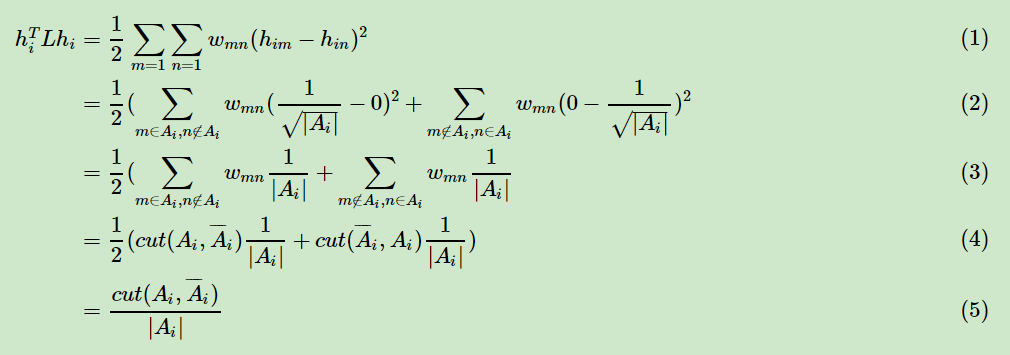
上述第(1)式用了上面第四节的拉普拉斯矩阵的性质3. 第二式用到了指示向量的定义。可以看出,对于某一个子图i,它的RatioCut对应于,那么我们的k个子图呢?对应的RatioCut函数表达式为:
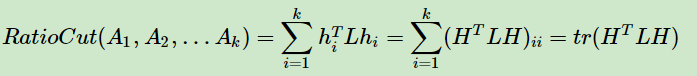
其中tr(HTLH)为矩阵的迹。也就是说,我们的RatioCut切图,实际上就是最小化我们的tr(HTLH)。注意到HTH=I,则我们的切图优化目标为:
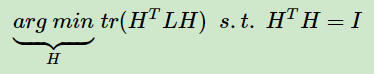
注意到我们H矩阵里面的每一个指示向量都是n维的,向量中每个变量的取值为0或者,就有2^n种取值,有k个子图的话就有k个指示向量,共有k2^n种H,因此找到满足上面优化目标的H是一个NP难的问题。那么是不是就没有办法了呢?
注意观察tr(HTLH)中每一个优化子目标,其中h是单位正交基, L为对称矩阵,此时
的最大值为L的最大特征值,最小值是L的最小特征值。如果你对主成分分析PCA很熟悉的话,这里很好理解。在PCA中,我们的目标是找到协方差矩阵(对应此处的拉普拉斯矩阵L)的最大的特征值,而在我们的谱聚类中,我们的目标是找到目标的最小的特征值,得到对应的特征向量,此时对应二分切图效果最佳。也就是说,我们这里要用到维度规约的思想来近似去解决这个NP难的问题。
对于,我们的目标是找到最小的L的特征值,而对于
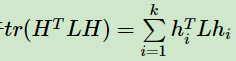 ,则我们的目标就是找到k个最小的特征值,一般来说,k远远小于n,也就是说,此时我们进行了维度规约,将维度从n降到了k,从而近似可以解决这个NP难的问题。
,则我们的目标就是找到k个最小的特征值,一般来说,k远远小于n,也就是说,此时我们进行了维度规约,将维度从n降到了k,从而近似可以解决这个NP难的问题。
通过找到L的最小的k个特征值,可以得到对应的k个特征向量,这k个特征向量组成一个nxk维度的矩阵,即为我们的H。一般需要对H矩阵按行做标准化,即
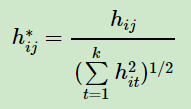
由于我们在使用维度规约的时候损失了少量信息,导致得到的优化后的指示向量h对应的H现在不能完全指示各样本的归属,因此一般在得到nxk维度的矩阵H后还需要对每一行进行一次传统的聚类,比如使用K-Means聚类.
6.2 Ncut切图
Ncut切图和RatioCut切图很类似,但是把Ratiocut的分母|Ai|换成vol(Ai). 由于子图样本的个数多并不一定权重就大,我们切图时基于权重也更合我们的目标,因此一般来说Ncut切图优于RatioCut切图。
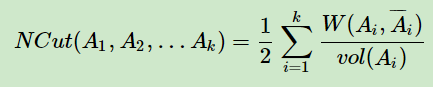
对应的,Ncut切图对指示向量hh做了改进。注意到RatioCut切图的指示向量使用的是标示样本归属,而Ncut切图使用了子图权重
来标示指示向量h,定义如下:
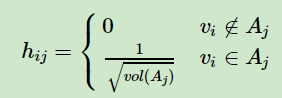
那么我们对于,有:
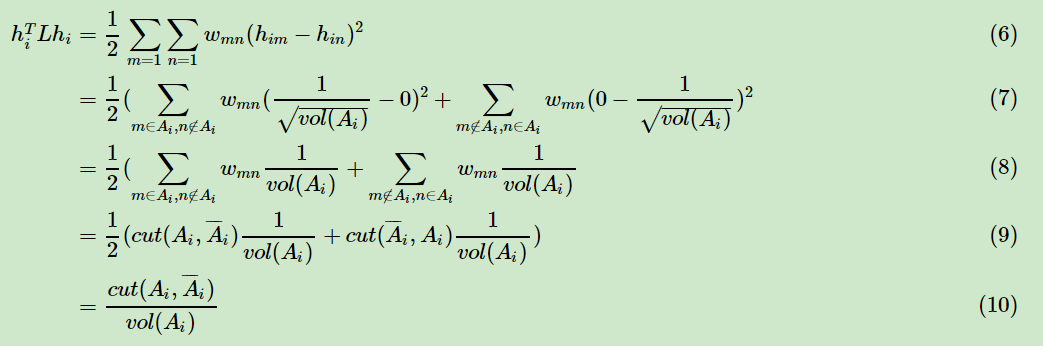
推导方式和RatioCut完全一致。也就是说,我们的优化目标仍然是
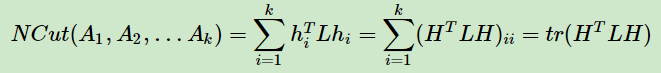
但是此时我们的HTH≠1,而是HTDH=I。推导如下:
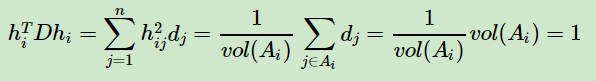
也就是说,此时我们的优化目标最终为:
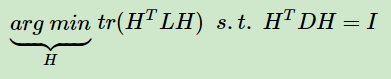
此时我们的H中的指示向量h并不是标准正交基,所以在RatioCut里面的降维思想不能直接用。怎么办呢?其实只需要将指示向量矩阵H做一个小小的转化即可。
我们令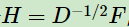 ,则:
,则:
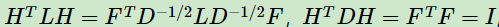
也就是说优化目标变成了:
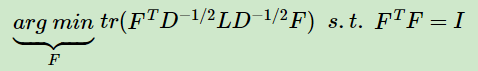
可以发现这个式子和RatioCut基本一致,只是中间的L变成了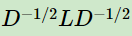 。这样我们就可以继续按照RatioCut的思想,求出的最小的前k个特征值,然后求出对应的特征向量,并标准化,得到最后的特征矩阵F,最后对F进行一次传统的聚类(比如K-Means)即可。
。这样我们就可以继续按照RatioCut的思想,求出的最小的前k个特征值,然后求出对应的特征向量,并标准化,得到最后的特征矩阵F,最后对F进行一次传统的聚类(比如K-Means)即可。
一般来说, 相当于对拉普拉斯矩阵L做了一次标准化, 即
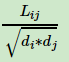
7. 谱聚类算法流程
铺垫了这么久,终于可以总结下谱聚类的基本流程了。一般来说,谱聚类主要的注意点为相似矩阵的生成方式(参见第二节),切图的方式(参见第六节)以及最后的聚类方法(参见第六节)。
最常用的相似矩阵的生成方式是基于高斯核距离的全连接方式,最常用的切图方式是Ncut。而到最后常用的聚类方法为K-Means。下面以Ncut总结谱聚类算法流程。
输入:样本集D=(x1,x2,...,xn),相似矩阵的生成方式, 降维后的维度k1, 聚类方法,聚类后的维度k2
输出:簇划分C(c1,c2,...ck2).
1) 根据输入的相似矩阵的生成方式构建样本的相似矩阵S
2)根据相似矩阵S构建邻接矩阵W,构建度矩阵D
3)计算出拉普拉斯矩阵L
4)构建标准化后的拉普拉斯矩阵
5)计算最小的k1个特征值所各自对应的特征向量f
6) 将各自对应的特征向量ff组成的矩阵按行标准化,最终组成n×k1维的特征矩阵F
7)对F中的每一行作为一个k1维的样本,共n个样本,用输入的聚类方法进行聚类,聚类维数为k2。
8)得到簇划分C(c1,c2,...ck2).
8. 谱聚类算法总结
谱聚类算法是一个使用起来简单,但是讲清楚却不是那么容易的算法,它需要你有一定的数学基础。如果你掌握了谱聚类,相信你会对矩阵分析,图论有更深入的理解。同时对降维里的主成分分析也会加深理解。
下面总结下谱聚类算法的优缺点。
谱聚类算法的主要优点有:
1)谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到
2)由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
谱聚类算法的主要缺点有:
1)如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
2) 聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
— THE END —
