
R语言K-Means(K-均值)聚类、朴素贝叶斯(Naive Bayes)模型分类可视化
分类是把某个对象划分到某个具体的已经定义的类别当中,而聚类是把一些对象按照具体特征组织 到若干个类别里 ( 点击文末“阅读原文”获取完整代码数据 )。
相关视频
虽然都是把某个对象划分到某个类别中,但是分类的类别是已经预定义的,而聚类操作时,某个对象所属的类别却不是预定义的。所以,对象所属类别是否为事先,是二者的最基本区别。而这个区别,仅仅是从算法实现流程来看的。
本文帮助客户对数据进行聚类和分类,需要得到的结果是,聚类的二维效果图,聚类个数,聚类中心点值。用聚类得到的结果贝叶斯建模后去预测分类。需要得到贝叶斯的模型精度,分类预测结果。
K-Means聚类成3个类别聚类算法(clustering analysis)是指将一堆没有标签的数据自动划分成几类的方法,属于无监督学习方法。K-means算法,也被称为K-平均或K-均值,是一种广泛使用的聚类算法,或者成为其他聚类算法的基础,它是基于点与点距离的相似度来计算最佳类别归属。几个相关概念:
K值:要得到的簇的个数;
质心:每个簇的均值向量,即向量各维取平均即可;
距离量度:常用欧几里得距离和余弦相似度(先标准化);
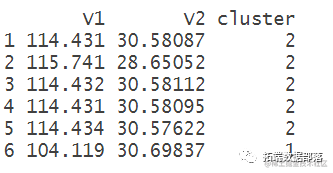
kmeans(data, 3)
聚类中心

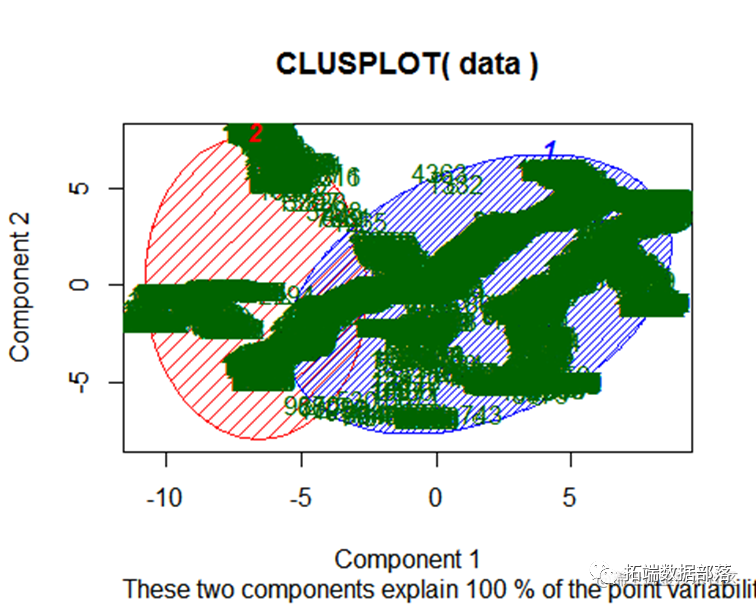
lusplot(data, fit$cluster
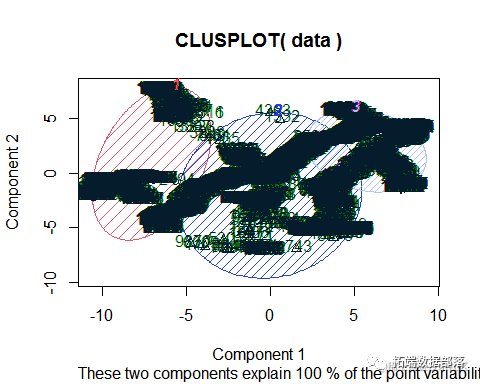
将数据使用kmean算法分成3个类别后可以看到 每个类别之间分布呈不同的簇,交集较少 ,因此 可以认为得到的聚类结果较好。
点击标题查阅往期内容

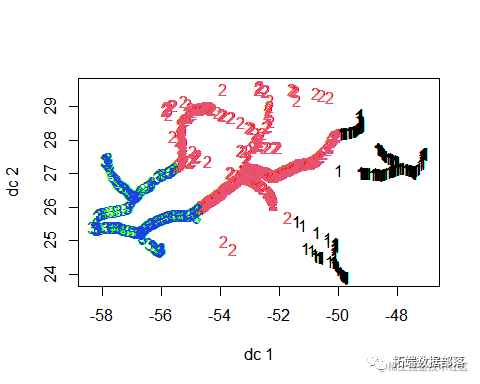
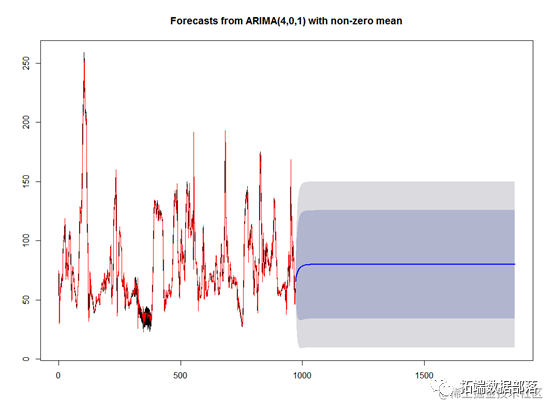
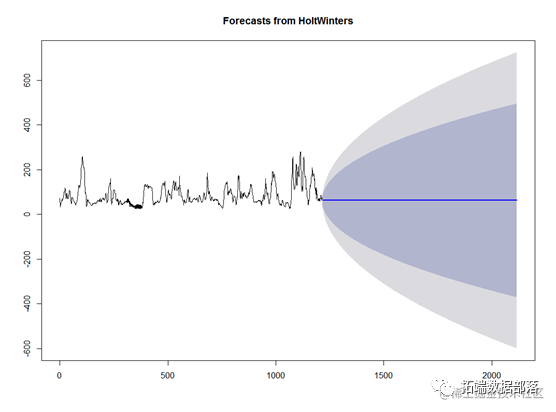
数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法

左右滑动查看更多
01
02
03
04
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法 。
和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier 或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。
朴素贝叶斯算法(Naive Bayesian algorithm) 是应用最为广泛的分类算法之一。
也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。
虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性。
head(train)
naiveBayes(as.factor(clus

tab=table(preds,train[,ncol(train)])#分类混淆矩阵
tab

predict(m, datapred,type="clas
预测分类
preds

fit <- kmeans(dat
聚类中心
fit$centers

usplot(data, fit
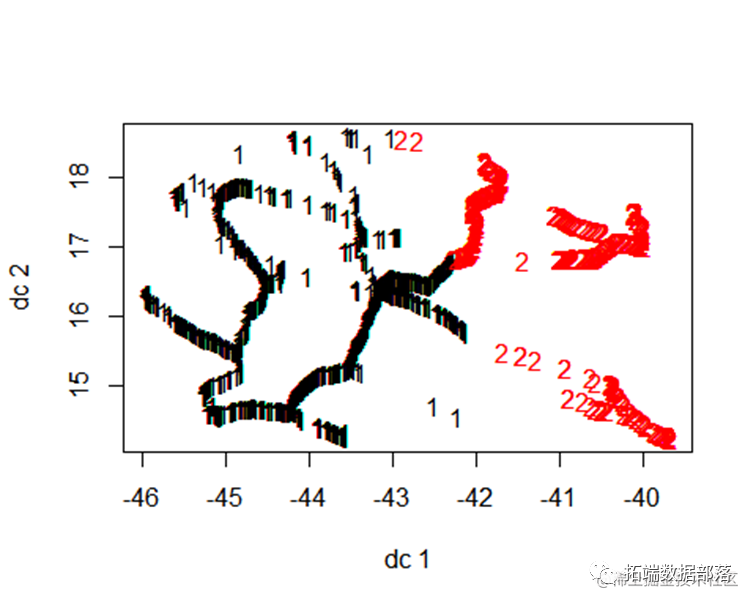
将数据使用kmean算法分成2个类别后可以看到每个类别之间分布呈不同的簇,交集较少 ,因此可以认为得到的聚类结果较好。
建立贝叶斯模型
naiveBayes(as.factor(clu

table(preds,train[,n

predict(m, datapred,type="cla

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言K-Means(K-均值)聚类、朴素贝叶斯(Naive Bayes)模型分类可视化》。
点击标题查阅往期内容
R语言文本挖掘:kmeans聚类分析上海玛雅水公园景区五一假期评论词云可视化R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
PYTHON实现谱聚类算法和改变聚类簇数结果可视化比较
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据
r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化
Python Monte Carlo K-Means聚类实战研究
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言谱聚类、K-MEANS聚类分析非线性环状数据比较
R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化 Python、R对小说进行文本挖掘和层次聚类可视化分析案例
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
R语言复杂网络分析:聚类(社区检测)和可视化
R语言中的划分聚类模型
基于模型的聚类和R语言中的高斯混合模型
r语言聚类分析:k-means和层次聚类
SAS用K-Means 聚类最优k值的选取和分析
用R语言进行网站评论文本挖掘聚类
基于LDA主题模型聚类的商品评论文本挖掘
R语言鸢尾花iris数据集的层次聚类分析
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言聚类算法的应用实例

![]()