
聊聊接口优化的几种方法
往期热门文章:
1、3 步完成 Spring Boot 的日志脱敏 2、线上MySQL的自增id用尽怎么办?被面试官干趴下了! 3、求求你别再用 System.currentTimeMillis() 统计代码耗时了,真的太 Low 了! 4、如何将 @Transactional 事务注解运用到炉火纯青? 5、不知道怎么解耦业务?Spring Event 了解一下!
背景
哪些问题会引起接口性能问题?
数据库慢查询 深度分页问题 未加索引 索引失效 join过多 子查询过多 in中的值太多 单纯的数据量过大 业务逻辑复杂 循环调用 顺序调用 线程池设计不合理 锁设计不合理 机器问题(fullGC,机器重启,线程打满)
问题解决
慢查询(基于mysql)深度分页
select name,code from student limit 100,20
select name,code from student limit 1000000,20
select name,code from student where id>1000000 limit 20
慢查询未加索引
show create table xxxx(表名)
慢查询索引失效
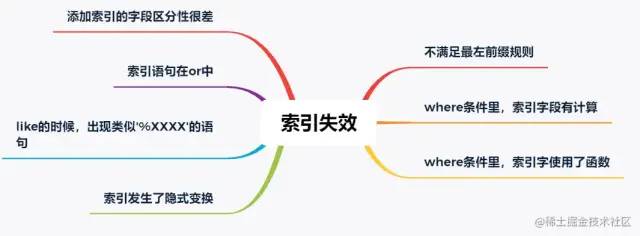
某个字段只可能有3个值,那这个字段的索引区分度就很低。 再比如,某个字段大量为空,只有少量有值; 再比如,某个字段值非常集中,90%都是1,剩下10%可能是2,3,4....
select name,code from student force index(XXXXXX) where name = '天才'
join过多 or 子查询过多
in的元素过多
select id from student where id in (1,2,3 ...... 1000) limit 200
if (ids.size() > 200) {
throw new Exception("单次查询数据量不能超过200");
}
单纯的数据量过大
业务逻辑复杂
循环调用
List<Model> list = new ArrayList<>();
for(int i = 0 ; i < 12 ; i ++) {
Model model = calOneMonthData(i); // 计算某个月的数据,逻辑比较复杂,难以批量计算,效率也无法很高
list.add(model);
}
// 建立一个线程池,注意要放在外面,不要每次执行代码就建立一个,具体线程池的使用就不展开了
public static ExecutorService commonThreadPool = new ThreadPoolExecutor(5, 5, 300L,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(10), commonThreadFactory, new ThreadPoolExecutor.DiscardPolicy());
// 开始多线程调用
List<Future<Model>> futures = new ArrayList<>();
for(int i = 0 ; i < 12 ; i ++) {
Future<Model> future = commonThreadPool.submit(() -> calOneMonthData(i););
futures.add(future);
}
// 获取结果
List<Model> list = new ArrayList<>();
try {
for (int i = 0 ; i < futures.size() ; i ++) {
list.add(futures.get(i).get());
}
} catch (Exception e) {
LOGGER.error("出现错误:", e);
}
顺序调用
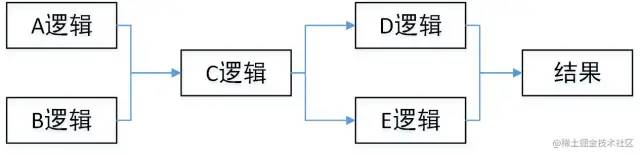
A a = doA();
B b = doB();
C c = doC(a, b);
D d = doD(c);
E e = doE(c);
return doResult(d, e);
CompletableFuture<A> futureA = CompletableFuture.supplyAsync(() -> doA());
CompletableFuture<B> futureB = CompletableFuture.supplyAsync(() -> doB());
CompletableFuture.allOf(futureA,futureB) // 等a b 两个任务都执行完成
C c = doC(futureA.join(), futureB.join());
CompletableFuture<D> futureD = CompletableFuture.supplyAsync(() -> doD(c));
CompletableFuture<E> futureE = CompletableFuture.supplyAsync(() -> doE(c));
CompletableFuture.allOf(futureD,futureE) // 等d e两个任务都执行完成
return doResult(futureD.join(),futureE.join());
线程池设计不合理
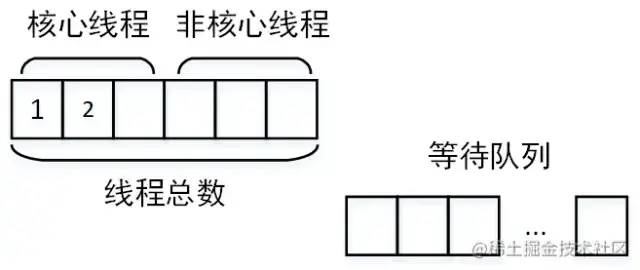
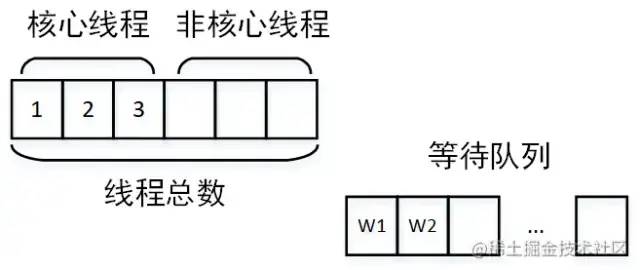
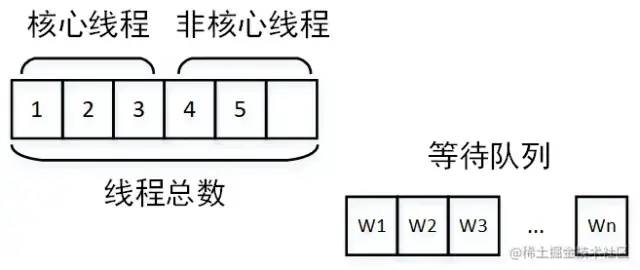 创建非核心线程运行
创建非核心线程运行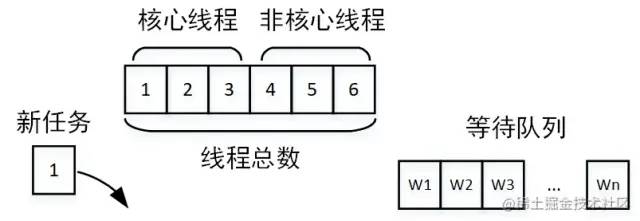
核心线程设置过小:核心线程设置过小则没有达到并行的效果 线程池公用,别的业务的任务执行时间太长,占用了核心线程,另一个业务的任务到达就直接进入了等待队列 任务太多,以至于占满了线程池,大量任务在队列中等待
锁设计不合理
public synchronized void doSome() {
File f = calData();
uploadToS3(f);
sendSuccessMessage();
}
public void doSome() {
File f = null;
synchronized(this) {
f = calData();
}
uploadToS3(f);
sendSuccessMessage();
}
机器问题(fullGC,机器重启,线程打满)
万金油解决方式
缓存
简单的 mapguava等本地缓存工具包缓存中间件: redis、tair或memcached
memcached现在用的很少了,因为相比于redis他不占优势。tair则是阿里开发的一个分布式缓存中间件,他的优势是理论上可以在不停服的情况下,动态扩展存储容量,适用于大数据量缓存存储。相比于单机redis缓存当然有优势,而他与可扩展Redis集群的对比则需要进一步调研。回调 or 反查
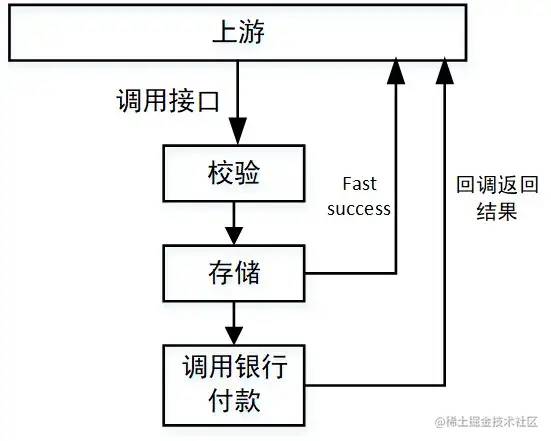
结语
往期热门文章:
1、线上MySQL的自增id用尽怎么办?被面试官干趴下了! 2、计算机专业会不会成为下一个土木? 3、xxl-job惊艳的设计,怎能叫人不爱 4、ArrayList#subList这四个坑,一不小心就中招 5、面试官:大量请求 Redis 不存在的数据,从而影响数据库,该如何解决? 6、MySQL 暴跌! 7、超越 Xshell!号称下一代 Terminal 终端神器,用完爱不释手! 8、IDEA 官宣全新默认 UI,太震撼了!! 9、让你直呼「卧槽」的 GitHub 项目! 10、Kafka又笨又重,为啥不选Redis?
评论