
为深度学习选择最好的GPU

加快训练速度,更快的迭代模型。
在进行机器学习项目时,特别是在处理深度学习和神经网络时,最好使用GPU而不是CPU来处理,因为在神经网络方面,即使是一个非常基本的GPU也会胜过CPU。

但是你应该买哪种GPU呢?本文将总结需要考虑的相关因素,以便可以根据预算和特定的建模要求做出明智的选择。
为什么 GPU 比 CPU 更适合机器学习?
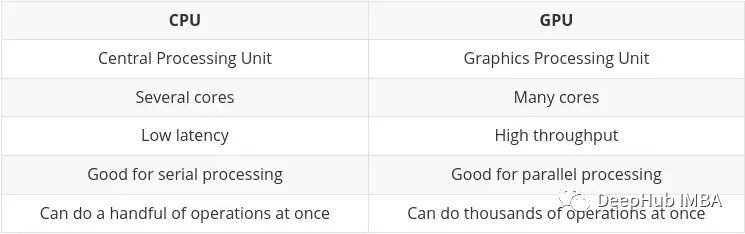
CPU(中央处理器)是计算机的主力,它非常灵活,不仅需要处理来自各种程序和硬件的指令,并且处理速度也有一定的要求。为了在这种多任务环境中表现出色,CPU 具有少量且灵活快速的处理单元(也称为核)。
GPU(图形处理单元)GPU在多任务处理方面不那么灵活。但它可以并行执行大量复杂的数学计算。这是通过拥有更多数量的简单核心(数千个到上万)来实现的,这样可以同时处理许多简单的计算。
并行执行多个计算的要求非常适合于:
图形渲染——移动的图形对象需要不断地计算它们的轨迹,这需要大量不断重复的并行数学计算。
机器和深度学习——大量的矩阵/张量计算,GPU可以并行处理。
任何类型的数学计算,可以拆分为并行运行。
在Nvidia自己的博客上已经总结了CPU和GPU的主要区别:
张量处理单元(TPU)
随着人工智能和机器/深度学习的发展,现在已经有了更专门的处理核心,称为张量核(Tensor cores)。在执行张量/矩阵计算时,它们更快更有效。因为我们在机器/深度学习中所处理的数据类型就是张量。
虽然有专用的tpu,但一些最新的GPU也包括许多张量核,我们会在后面总结。
Nvidia vs AMD
这将是一个相当短的部分,因为这个问题的答案肯定是Nvidia
虽然可以使用AMD的gpu进行机器/深度学习,但在写本文时,Nvidia的GPU具有更高的兼容性,并且通常更好地集成到TensorFlow和PyTorch等工具中(比如目前PyTorch的AMD GPU的支持还只能在Linux上使用)。
使用AMD GPU需要使用额外的工具(ROCm),这个会有一些额外的工作,并且版本可能也不会更新的很快。这种情况将来可能会有所改善,但是现在为止,最好还是使用Nvidia。
GPU选择的主要属性
选择一个够完成机器学习任务并且符合预算的GPU,基本上归结为四个主要因素的平衡:
GPU有多少内存?
GPU有多少个CUDA和/或张量核?
卡使用什么芯片架构?
功耗要求是多少(如果有)?
下面将逐一探讨这些方面,希望能让你更好地理解什么对你来说是重要的。
GPU内存
答案是,越多越好!
这实际上取决于你的任务,以及这些模型有多大。例如,如果你正在处理图像、视频或音频,那么根据定义,你将处理相当大量的数据,GPU RAM将是一个非常重要的考虑因素。
总有办法解决内存不足的问题(例如减少批处理大小)。但是这将会浪费训练的时间,因此需要很好地平衡需求。

根据经验,我的建议如下:
4GB:我认为这是绝对的最小值,只要你不是在处理过于复杂的模型,或者大的图像、视频或音频,这个在大多数情况下能工作,但是达不到日常使用的需要。如果你刚刚起步,想尝试一下又不想全力投入,那么可以从它开始。
8GB:这是一个日常学习很好的开始,可以在不超过RAM限制的情况下完成大多数任务,但在使用更复杂的图像、视频或音频模型时会遇到问题。
12GB:我认为这是科研最基本的的要求。可以处理大多数较大的模型,甚至是那些处理图像、视频或音频的模型。
12GB+ :越多越好,你将能够处理更大的数据集和更大的批处理大小。超过12GB才是价格真正开始上涨的开始。
一般来说,如果成本相同的话,选择“速度较慢”但内存较大的卡会更好。请记住,GPU的优势是高吞吐量,这在很大程度上依赖于可用的RAM来通过GPU传输数据。
CUDA核心和Tensor 核心
这其实很简单,越多越好。
首先考虑RAM,然后就是CUDA。对于机器/深度学习来说,Tensor 核比CUDA核更好(更快,更有效)。这是因为它们是为机器/深度学习领域所需的计算而精确设计的。
但是这并不重要,因为CUDA内核已经足够快了。如果你能得到一张包含Tensor 核的卡,这是一个很好的加分点,只是不要太纠结于它。
后面你会看到“CUDA”被提到很多次,我们先总结一下它:
CUDA核心——这些是显卡上的物理处理器,通常有数千个,4090已经1万6了。
CUDA 11 -数字可能会改变,但这是指安装的软件/驱动程序,以允许显卡正常的工作。
NV会定期发布新版本,它可以像任何其他软件一样安装和更新。
CUDA代数(或计算能力)-这描述了显卡卡在它的更新迭代的代号。这在硬件上是固定的,因此只能通过升级到新卡来改变。它由数字和一个代号来区分。例子:3。x[Kepler],5。x [Maxwell], 6。x [Pascal], 7。x[Turing]和8。x(Ampere)。
芯片架构
这实际上比你想象的更重要。我们这里不讨论AMD,我的眼里只有”老黄“。
上面我们已经说了,30系列的卡就是Ampere架构,最新的40系列是 Ada Lovelace。一般老黄都会使用一个著名科学家和数学家来对架构命名,这次选择的是著名英国诗人拜伦之女,建立了循环和子程序概念的女数学家、计算机程序创始人Ada Lovelace来命名。
了解对于卡的计算能力,我们要了解2个方面:
显着的功能改进
这里一个重要的功能就是, 混合精度训练:
使用精度低于 32 位浮点数的数字格式有很多好处。首先它们需要更少的内存,从而能够训练和部署更大的神经网络。其次它们需要更少的内存带宽,从而加快数据传输操作。第三数学运算在精度降低的情况下运行得更快,尤其是在具有 Tensor Core 的 GPU 上。混合精度训练实现了所有这些好处,同时确保与完全精度训练相比不会丢失特定于任务的准确性。它通过识别需要完全精度的步骤并仅对这些步骤使用 32 位浮点而在其他任何地方使用 16 位浮点来实现这一点。
如果您的 GPU 具有 7.x (Turing) 或更高的架构,才有可能使用混合精确训练。也就是说 桌面的RTX 20 系列或高版本,或服务器上的 “T”或“A”系列。
混合精度训练具有如此优势的主要原因是它降低了 RAM 使用率,Tensor Core 的 GPU会加速混精度训练,如果没有的话使用FP16也会节省显存,可以训练更大的批大小,间接提升训练速度。
是否会被弃用
如果你对RAM有特别高的要求,但又没有足够的钱买高端卡,那么你可能会选择二手市场上的老款GPU。这有一个相当大的缺点……这张卡的寿命结束了。
一个典型的例子就是Tesla K80,它有4992个CUDA核心和24GB的RAM。2014年,它零售价约为7000美元。现在的价格从 150到170美元不等!(咸鱼的价格600-700左右)这么小的价格却有这么大的内存,你一定很兴奋。
但是这有一个非常大的问题。K80的计算架构是3.7 (Kepler),CUDA 11起已经不支持(当前CUDA版本为11.7)。这意味着这张卡已经废了,所以它才卖的这么便宜。

所以在选择2手卡时一定要看清楚是否支持最新版本的驱动和CUDA,这是最重要的。
高端游戏卡 VS 工作站/服务器卡
老黄基本上把卡分成了两部分。消费类显卡和工作站/服务器的显卡(即专业显卡)。
这两个部分之间有明显的区别,对于相同的规格(RAM, CUDA内核,架构),消费类显卡通常会更便宜。但是专业卡通常会有更好的质量,和较低的能源消耗(其实涡轮的噪音挺大的,放机房还可以,放家里或者试验室有点吵)。
高端(非常昂贵)的专业卡,你可能会注意到它们有很大的RAM(例如RTX A6000有48GB, A100有80GB!)。这是因为它们通常直接针对3D建模、渲染和机器/深度学习专业市场,这些市场需要高水平的RAM。再说一次,如果你有钱,买A100就对了!(H100是A100的新版,目前无法评价)
但是我个人认为,我们还是选择消费者的高端游戏卡,因为如果你不差钱,你也不会看这篇文章,对吧。
选择建议
所以在最后我根据预算和需求提出一些建议。我将其分为三个部分:
低预算
中等预算
高预算
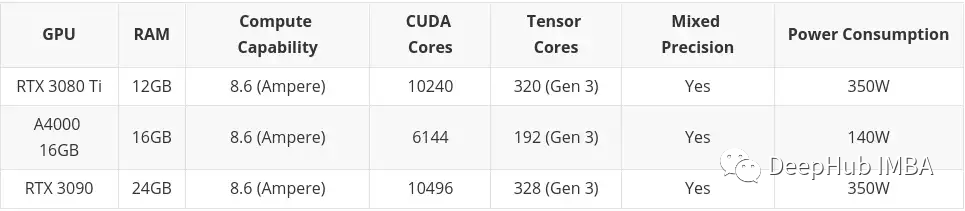
高预算不考虑任何超出高端消费显卡。还是那句话如果你有钱:A100,H100随便买。
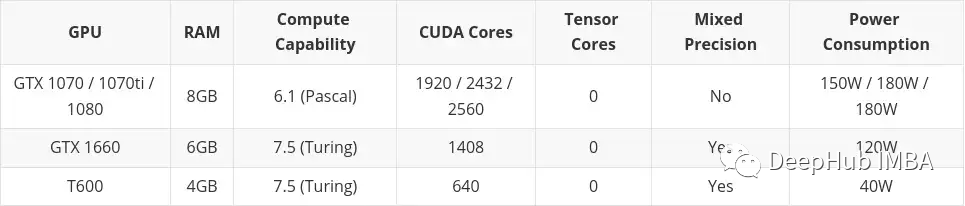
本文中会包含在二手市场买到的卡片。这主要是因为我认为在低预算的情况下,二手是可以考虑的。这里还包括了专业桌面系列卡(T600、A2000和A4000),因为它的一些配置比同类消费类显卡稍差,但功耗明显更好。
低预算
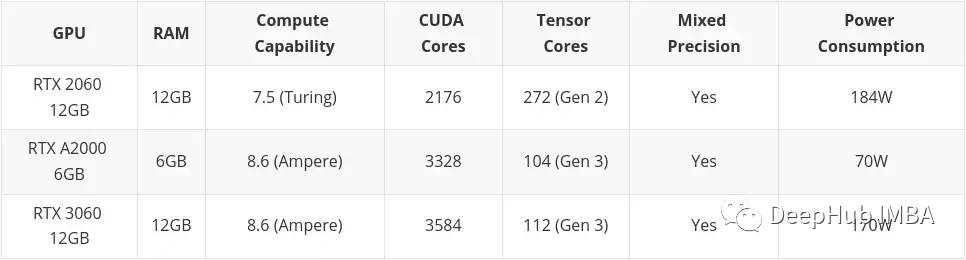
中等预算
高预算
在线/云服务
如果你决定花钱买显卡不适合你,你可以利用谷歌Colab,它可以让你免费使用GPU。
但这是有时间限制的,如果你使用GPU太长时间,他们会把你踢出去,然后回到CPU上。如果GPU处于非活动状态太长时间,可能是在你写代码的时候,它也会把GPU拿回来。GPU也是自动分配的,所以你不能选择你想要的确切的GPU(你也可以每月9.9刀弄个Colab Pro,我个人觉得要比低预算好很多,但是要求有梯子,$49.99的Colab Pro+有点贵,不建议)。
在写本文时,通过Colab可以获得以下GPU:
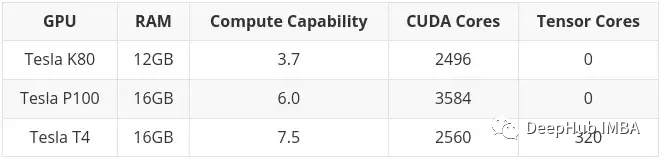
在前面也提到了,K80有24GB的RAM和4992个CUDA核心,它基本上是两个K40卡连在一起。这意味着当你在Colab中使用K80时,你实际上可以访问一半的卡,所以也就是只有12GB和2496个CUDA内核。
总结
最后现在4090还是处于耍猴的状态,基本上要抢购或者加价找黄牛。
但是16384 CUDA + 24GB,对比3090 的10496 CUDA ,真的很香。
而4080 16G的9728CUDA 如果价格能到7000内,应该是一个性价比很高的选择。12G的 4080就别考虑了,它配不上这个名字。
对于AMD的 7900XTX 应该也是一个很好的选择,但是兼容性是个大问题,如果有人测试的话可以留言。
40系列老黄一直在耍猴,所以如果不着急的话还再等等把:
你不买,我不买,明天还能降两百。

编辑:于腾凯
校对:林亦霖