
并发编程必看的内功心法
本篇文章我们来探讨一下并发设计模型。
可以使用不同的并发模型来实现并发系统,并发模型说的是系统中的线程如何协作完成并发任务。不同的并发模型以不同的方式拆分任务,线程可以以不同的方式进行通信和协作。
并发模型和分布式系统很相似
并发模型其实和分布式系统模型非常相似,在并发模型中是线程彼此进行通信,而在分布式系统模型中是 进程 彼此进行通信。然而本质上,进程和线程也非常相似。这也就是为什么并发模型和分布式模型非常相似的原因。
分布式系统通常要比并发系统面临更多的挑战和问题比如进程通信、网络可能出现异常,或者远程机器挂掉等等。但是一个并发模型同样面临着比如 CPU 故障、网卡出现问题、硬盘出现问题等。
因为并发模型和分布式模型很相似,因此他们可以相互借鉴,例如用于线程分配的模型就类似于分布式系统环境中的负载均衡模型。
其实说白了,分布式模型的思想就是借鉴并发模型的基础上推演发展来的。
认识两个状态
并发模型的一个重要的方面是,线程是否应该共享状态,是具有共享状态还是独立状态。共享状态也就意味着在不同线程之间共享某些状态
状态其实就是数据,比如一个或者多个对象。当线程要共享数据时,就会造成 竞态条件 或者 死锁 等问题。当然,这些问题只是可能会出现,具体实现方式取决于你是否安全的使用和访问共享对象。

独立的状态表明状态不会在多个线程之间共享,如果线程之间需要通信的话,他们可以访问不可变的对象来实现,这是一种最有效的避免并发问题的一种方式,如下图所示
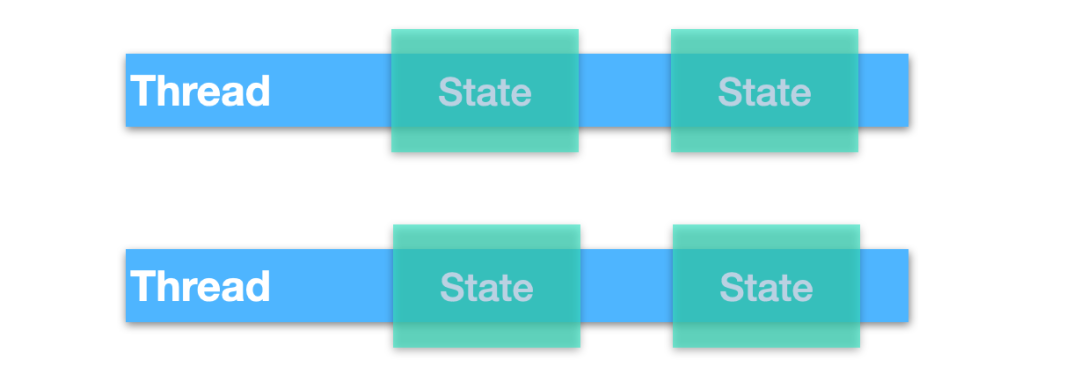
使用独立状态让我们的设计更加简单,因为只有一个线程能够访问对象,即使交换对象,也是不可变的对象。
并发模型
并行 Worker
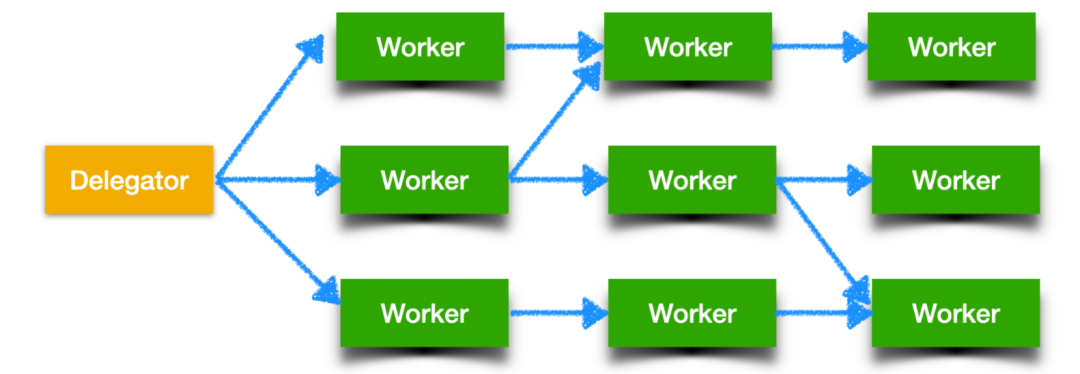
第一个并发模型是并行 worker 模型,客户端会把任务交给 代理人(Delegator),然后由代理人把工作分配给不同的 工人(worker)。如下图所示
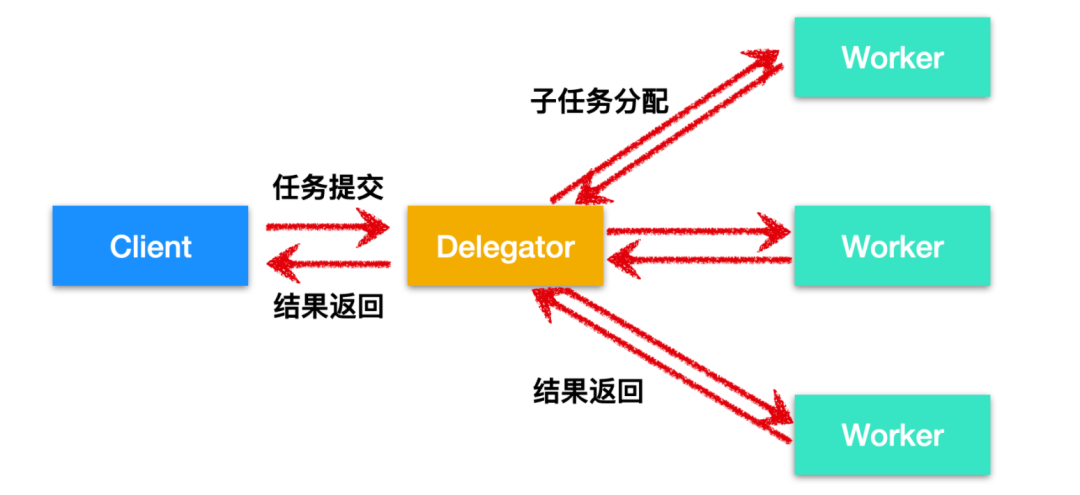
并行 worker 的核心思想是,它主要有两个进程即代理人和工人,Delegator 负责接收来自客户端的任务并把任务下发,交给具体的 Worker 进行处理,Worker 处理完成后把结果返回给 Delegator,在 Delegator 接收到 Worker 处理的结果后对其进行汇总,然后交给客户端。
并行 Worker 模型是 Java 并发模型中非常常见的一种模型。许多 java.util.concurrent 包下的并发工具都使用了这种模型。
并行 Worker 的优点
并行 Worker 模型的一个非常明显的特点就是很容易理解,为了提高系统的并行度你可以增加多个 Worker 完成任务。
并行 Worker 模型的另外一个好处就是,它会将一个任务拆分成多个小任务,并发执行,Delegator 在接受到 Worker 的处理结果后就会返回给 Client,整个 Worker -> Delegator -> Client 的过程是异步的。
并行 Worker 的缺点
同样的,并行 Worker 模式同样会有一些隐藏的缺点
共享状态会变得很复杂
实际的并行 Worker 要比我们图中画出的更复杂,主要是并行 Worker 通常会访问内存或共享数据库中的某些共享数据。

这些共享状态可能会使用一些工作队列来保存业务数据、数据缓存、数据库的连接池等。在线程通信中,线程需要确保共享状态是否能够让其他线程共享,而不是仅仅停留在 CPU 缓存中让自己可用,当然这些都是程序员在设计时就需要考虑的问题。线程需要避免 竞态条件,死锁 和许多其他共享状态造成的并发问题。
多线程在访问共享数据时,会丢失并发性,因为操作系统要保证只有一个线程能够访问数据,这会导致共享数据的争用和抢占。未抢占到资源的线程会 阻塞。
现代的非阻塞并发算法可以减少争用提高性能,但是非阻塞算法比较难以实现。
可持久化的数据结构(Persistent data structures) 是另外一个选择。可持久化的数据结构在修改后始终会保留先前版本。因此,如果多个线程同时修改一个可持久化的数据结构,并且一个线程对其进行了修改,则修改的线程会获得对新数据结构的引用。
虽然可持久化的数据结构是一个新的解决方法,但是这种方法实行起来却有一些问题,比如,一个持久列表会将新元素添加到列表的开头,并返回所添加的新元素的引用,但是其他线程仍然只持有列表中先前的第一个元素的引用,他们看不到新添加的元素。
持久化的数据结构比如 链表(LinkedList) 在硬件性能上表现不佳。列表中的每个元素都是一个对象,这些对象散布在计算机内存中。现代 CPU 的顺序访问往往要快的多,因此使用数组等顺序访问的数据结构则能够获得更高的性能。CPU 高速缓存可以将一个大的矩阵块加载到高速缓存中,并让 CPU 在加载后直接访问 CPU 高速缓存中的数据。对于链表,将元素分散在整个 RAM 上,这实际上是不可能的。
无状态的 worker
共享状态可以由其他线程所修改,因此,worker 必须在每次操作共享状态时重新读取,以确保在副本上能够正确工作。不在线程内部保持状态的 worker 成为无状态的 worker。
作业顺序是不确定的
并行工作模型的另一个缺点是作业的顺序不确定,无法保证首先执行或最后执行哪些作业。任务 A 在任务 B 之前分配给 worker,但是任务 B 可能在任务 A 之前执行。
流水线
第二种并发模型就是我们经常在生产车间遇到的 流水线并发模型,下面是流水线设计模型的流程图

这种组织架构就像是工厂中装配线中的 worker,每个 worker 只完成全部工作的一部分,完成一部分后,worker 会将工作转发给下一个 worker。
每道程序都在自己的线程中运行,彼此之间不会共享状态,这种模型也被称为无共享并发模型。
使用流水线并发模型通常被设计为非阻塞I/O,也就是说,当没有给 worker 分配任务时,worker 会做其他工作。非阻塞I/O 意味着当 worker 开始 I/O 操作,例如从网络中读取文件,worker 不会等待 I/O 调用完成。因为 I/O 操作很慢,所以等待 I/O 非常耗费时间。在等待 I/O 的同时,CPU 可以做其他事情,I/O 操作完成后的结果将传递给下一个 worker。下面是非阻塞 I/O 的流程图
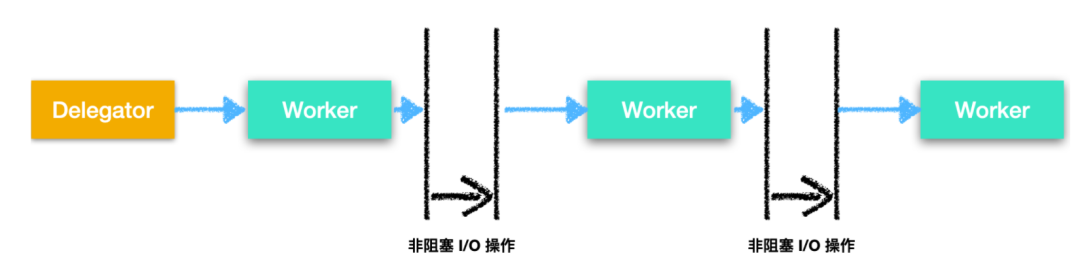
在实际情况中,任务通常不会按着一条装配线流动,由于大多数程序需要做很多事情,因此需要根据完成的不同工作在不同的 worker 之间流动,如下图所示
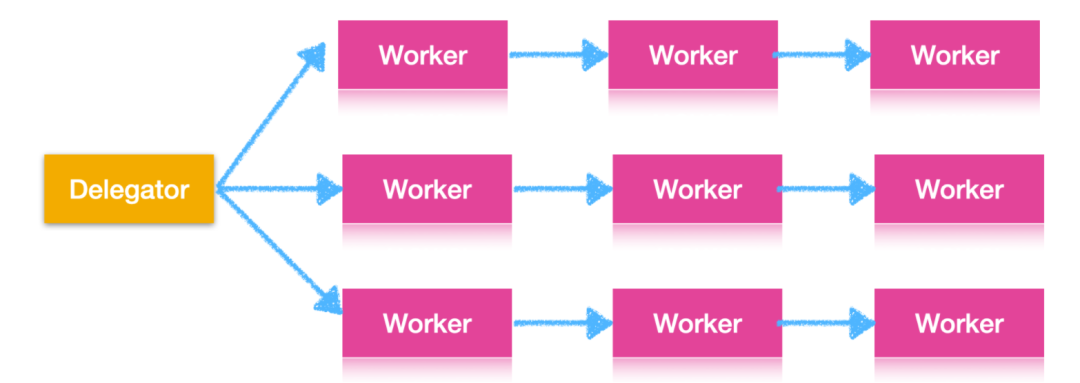
任务还可能需要多个 worker 共同参与完成
响应式 - 事件驱动系统
使用流水线模型的系统有时也被称为 响应式 或者 事件驱动系统,这种模型会根据外部的事件作出响应,事件可能是某个 HTTP 请求或者某个文件完成加载到内存中。
Actor 模型
在 Actor 模型中,每一个 Actor 其实就是一个 Worker, 每一个 Actor 都能够处理任务。
简单来说,Actor 模型是一个并发模型,它定义了一系列系统组件应该如何动作和交互的通用规则,最著名的使用这套规则的编程语言是 Erlang。一个参与者Actor对接收到的消息做出响应,然后可以创建出更多的 Actor 或发送更多的消息,同时准备接收下一条消息。

Channels 模型
在 Channel 模型中,worker 通常不会直接通信,与此相对的,他们通常将事件发送到不同的 通道(Channel)上,然后其他 worker 可以在这些通道上获取消息,下面是 Channel 的模型图
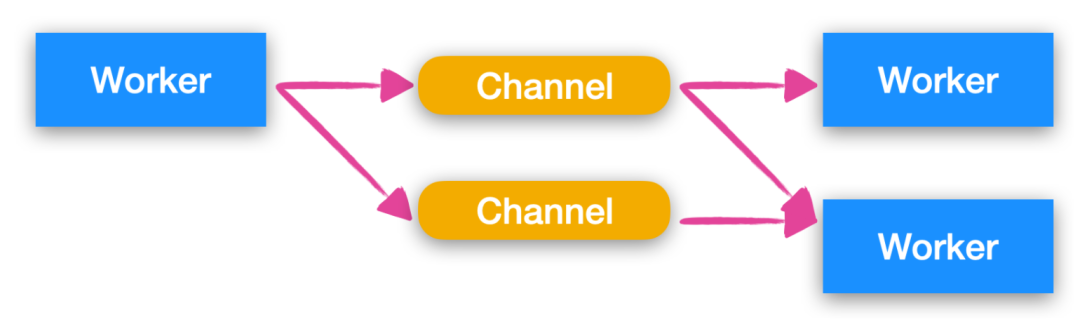
有的时候 worker 不需要明确知道接下来的 worker 是谁,他们只需要将作者写入通道中,监听 Channel 的 worker 可以订阅或者取消订阅,这种方式降低了 worker 和 worker 之间的耦合性。
流水线设计的优点
与并行设计模型相比,流水线模型具有一些优势,具体优势如下
不会存在共享状态
因为流水线设计能够保证 worker 在处理完成后再传递给下一个 worker,所以 worker 与 worker 之间不需要共享任何状态,也就不用无需考虑以为并发而引起的并发问题。你甚至可以在实现上把每个 worker 看成是单线程的一种。
有状态 worker
因为 worker 知道没有其他线程修改自身的数据,所以流水线设计中的 worker 是有状态的,有状态的意思是他们可以将需要操作的数据保留在内存中,有状态通常比无状态更快。
更好的硬件整合
因为你可以把流水线看成是单线程的,而单线程的工作优势在于它能够和硬件的工作方式相同。因为有状态的 worker 通常在 CPU 中缓存数据,这样可以更快地访问缓存的数据。
使任务更加有效的进行
可以对流水线并发模型中的任务进行排序,一般用来日志的写入和恢复。
流水线设计的缺点
流水线并发模型的缺点是任务会涉及多个 worker,因此可能会分散在项目代码的多个类中。因此很难确定每个 worker 都在执行哪个任务。流水线的代码编写也比较困难,设计许多嵌套回调处理程序的代码通常被称为 回调地狱。回调地狱很难追踪 debug。
函数性并行
函数性并行模型是最近才提出的一种并发模型,它的基本思路是使用函数调用来实现。消息的传递就相当于是函数的调用。传递给函数的参数都会被拷贝,因此在函数之外的任何实体都无法操纵函数内的数据。这使得函数执行类似于原子操作。每个函数调用都可以独立于任何其他函数调用执行。
当每个函数调用独立执行时,每个函数都可以在单独的 CPU 上执行。这也就是说,函数式并行并行相当于是各个 CPU 单独执行各自的任务。
JDK 1.7 中的 ForkAndJoinPool 类就实现了函数性并行的功能。Java 8 提出了 stream 的概念,使用并行流也能够实现大量集合的迭代。
函数性并行的难点是要知道函数的调用流程以及哪些 CPU 执行了哪些函数,跨 CPU 函数调用会带来额外的开销。
完

觉得不错,点个在看~
