BERT在工业界落地已经很普遍了,主要在搜索、推荐和NLP中广泛应用,我将自己运用BERT的心得总结如下:
下面就带大家一起看看阿里、美团和百度等公司是如何将BERT应用在业务中并提升业务指标的。

业界实践
论文:ERNIE 2.0: A Continual Pre-Training Framework for Language Understandinggithub:http://github.com/PaddlePaddle/ERNIE
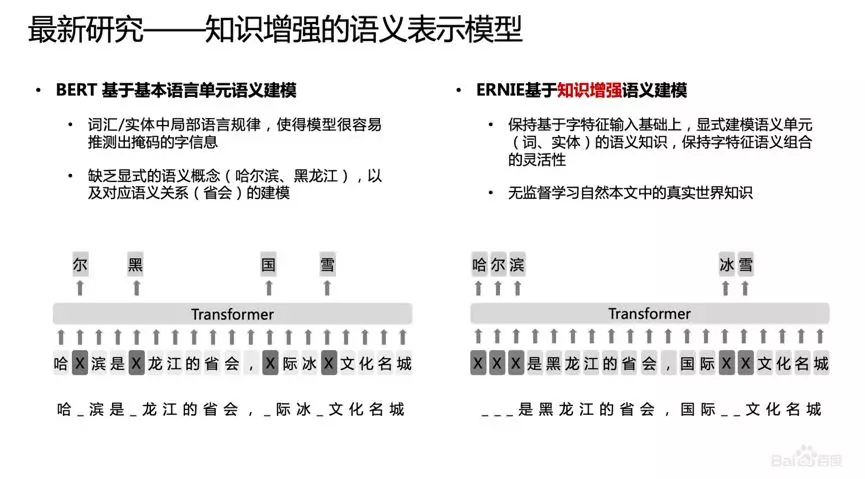
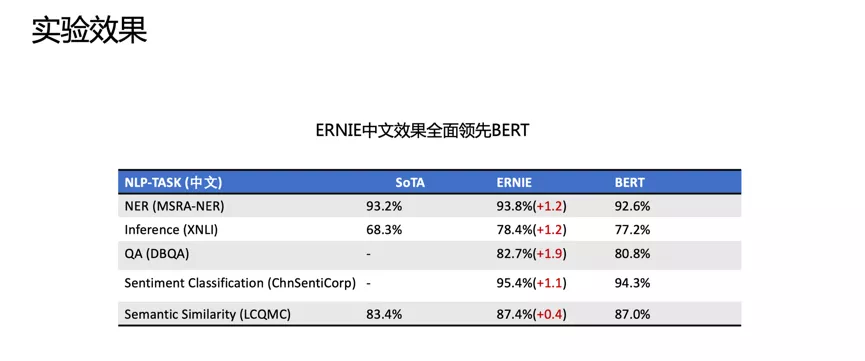
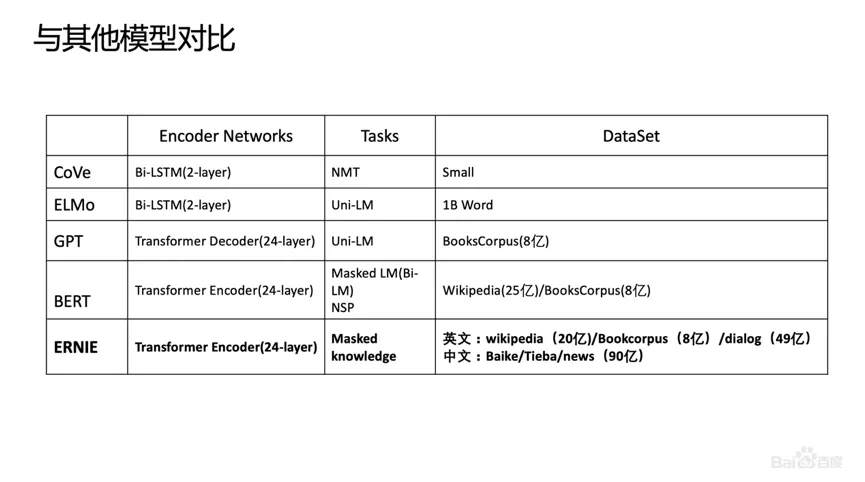
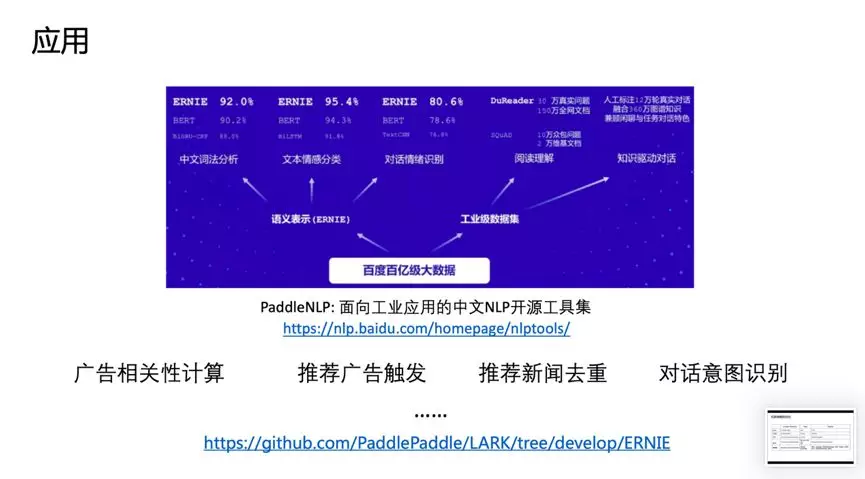
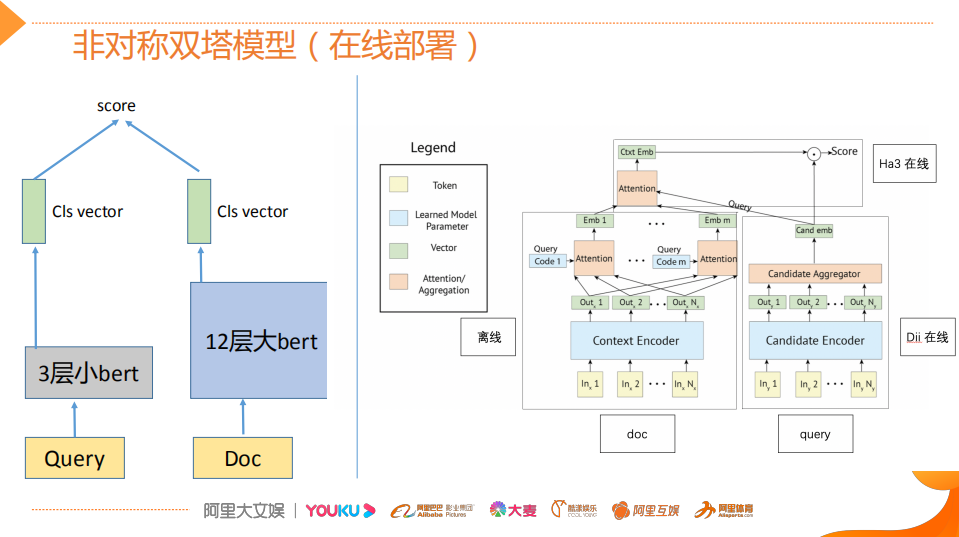
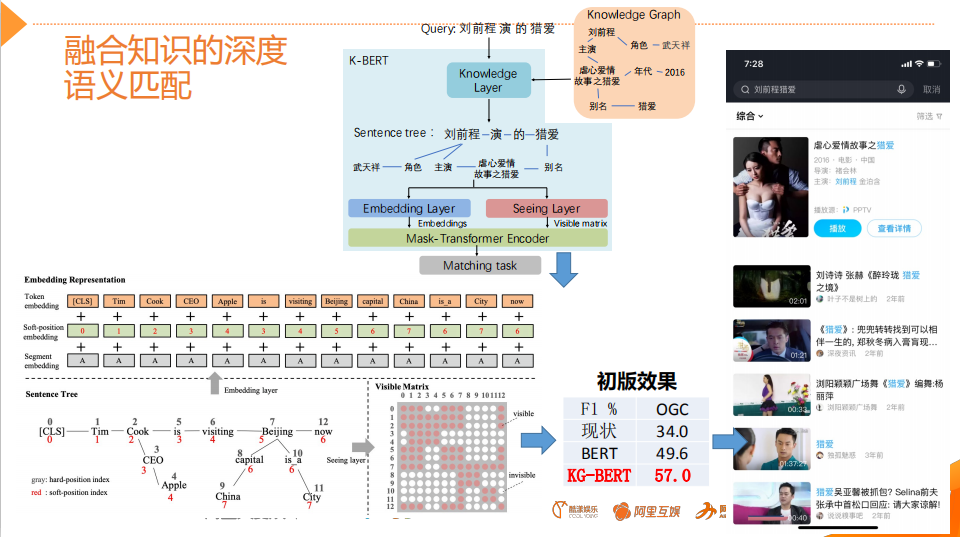
改进点:引入知识,在BERT基础上MASK 词和实体的方法,学习这个词或者实体在句子里面 Global 的信号。BERT 提出后,我们发现一个问题,它学习的还是基础语言单元的 Language Model,并没有充分利用先验语言知识,这个问题在中文很明显,它的策略是 MASK 字,没有 MASK 知识或者是短语。在用 Transformer 预测每个字的时候,很容易根据词包含字的搭配信息预测出来。比如预测“雪”字,实际上不需要用 Global 的信息去预测,可以通过“冰”字预测。基于这个假设,我们做了一个简单的改进,把它做成一个 MASK 词和实体的方法,学习这个词或者实体在句子里面 Global 的信号。基于上述思想我们发布了基于知识增强的语义表示ERNIE(1.0)。英文上验证了推广性,实验表明 ERNIE(1.0)在 GLUE 和 SQuAd1.1 上提升也是非常明显的。为了验证假设,我们做了一些定性的分析,找了完形填空的数据集,并通过 ERNIE 和 BERT 去预测,效果如上图。我们对比了 ERNIE、BERT、CoVe、GPT、ELMo 模型,结果如上图所示。ELMo 是早期做上下文相关表示模型的工作,但它没有用 Transformer,用的是 LSTM,通过单向语言模型学习。百度的 ERNIE 与 BERT、GPT 一样,都是做网络上的 Transformer,但是 ERNIE 在建模 Task 的时候做了一些改进,取得了很不错的效果。在应用上,ERNIE 在百度发布的面向工业应用的中文 NLP 开源工具集进行了验证,包括 ERNIE 与 BERT 在词法分析、情感分类这些百度内部的任务上做了对比分析。同时也有一些产品已经落地,在广告相关性的计算、推荐广告的触发、新闻推荐上都有实际应用。后来,百度艾尼 ( ERNIE ) 再升级,发布了持续学习语义理解框架 ERNIE 2.0,同时借助飞桨 ( PaddlePaddle ) 多机多卡高效训练优势发布了基于此框架的 ERNIE 2.0 预训练模型。该模型在共计 16 个中英文任务上超越了 BERT 和 XLNet,取得了 SOTA 效果。论文:Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring前置的tuner层:主要包含一些黄金的规则,在训练集上准确率超过95%的这种规则策略,当满足这些条件时,不进行模型处理,直接通过规则处理。模型层:当黄金规则处理不了时,利用分档的模型做兜底。分档的模型含有两个子模型为Recall模型和Refine模型,两个模型的结构一样,但它们使用的特征以及样本的选择是不一样的。分档模型的好处在于将整个相关性分档的功能进行了解耦,一个是用来发现高相关性的优质DOC,另外一个是用来降低相关性的岔道和进行过滤。后置的tuner层:该层对于因为样本数据不均衡、核心特征缺少等原因没有学出来的情况,会添加一些人工的兜底规则进行补充。比如说会针对视频内容理解特征做了一些规则。该层中还全局调档的一个Tuner,它的作用是基于全局的DOC匹配再做一些调整。如果直接从交互性(12层BERT)改成双塔(2个12层BERT),指标下降较多- Doc(离线):为了降低双塔模型的指标衰减,对于Doc侧,它其实保存的并不是一个Embedding,它是M组的Embedding,M组可以理解为从M个侧面刻画Doc的特征,这样也是为了最大限度的去保留Doc侧的一些丰富的信息;
- Query(在线):三层BERT,但是也会导致指标衰减;
- 对于query,通过对KG进行一个查询找到它的子图,然后把它子图的结构化信息编码成BERT通用的序列化的输入,然后再在KG层和文本层之间做一些attention的监督操作
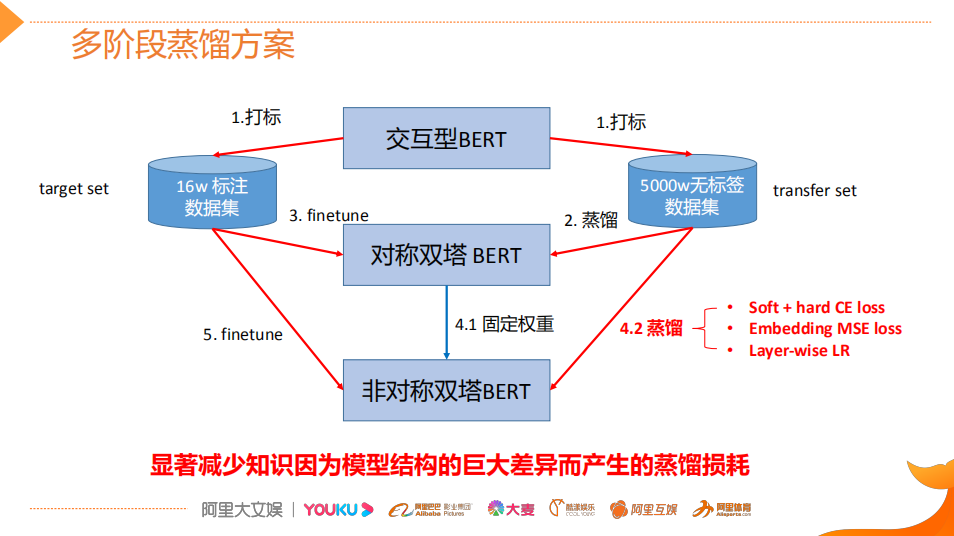
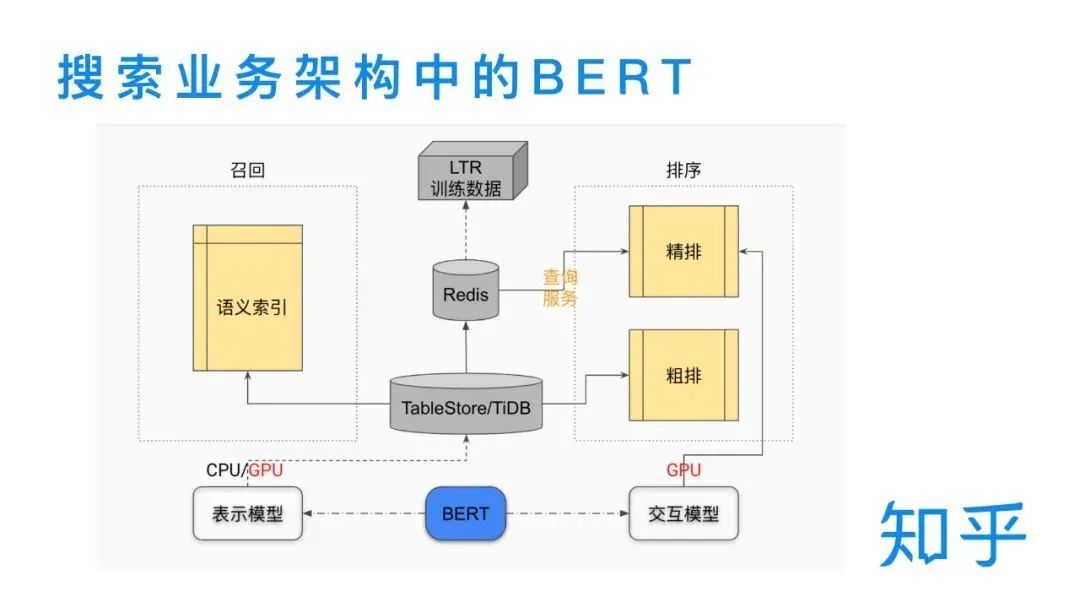
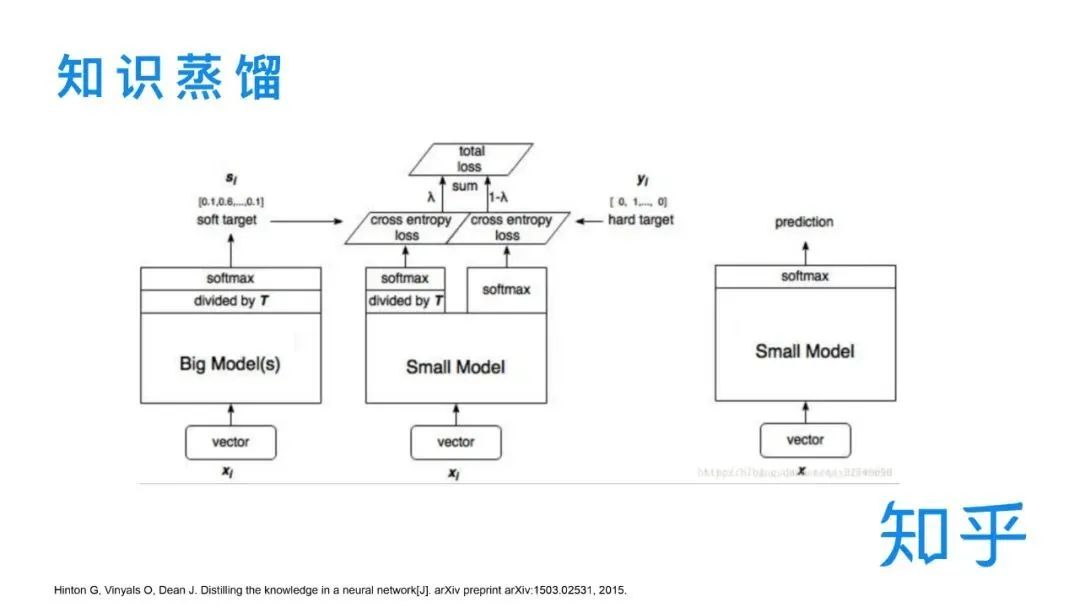
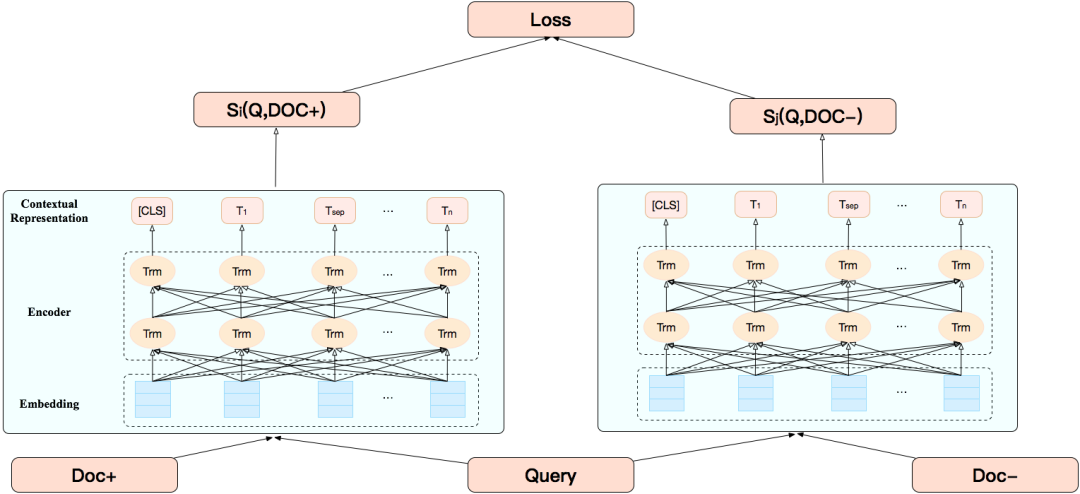
表示型BERT:用在召回、粗排,采用了 BERT 输出 token 序列向量的 average 作为句向量的表示召回:语义召回模型整体是 BERT 相关性任务中双塔表示模型的一个应用。BERT 做为 encoder 来对 query 和 doc 进行向量的表示,基于 faiss 对全量 doc 向量构建语义索引,线上实时的用 query 向量进行召回。下面详细介绍下知乎的语义召回模型。首先看个例子,对于「玛莎拉蒂 ghlib」这个 case,用户真正想搜的是「玛莎拉蒂 Ghibli」这款车,但用户一般很难记住完整的名称,可能会输错。在输错的情况下,基于传统的 term 匹配方式(Google 搜索的例子)只能召回“玛莎拉蒂”相关的 doc,而无法进行这辆车型的召回,这种场景下就需要进行语义召回。更通用的来说,语义召回可以理解为增加了字面不匹配但是语义相关的 doc 的召回。对于BERT 的蒸馏我们做了大量的调研,并对目前主流的蒸馏方案做了归纳分类。基于任务维度来说,主要对应于现在的 pretrain + fine-tune 的两段式训练。在预训练阶段和下游任务阶段都有不少的方案涉及。技巧层面来分的话,主要包括不同的迁移知识和模型结构的设计两方面。后面我会选两个典型的模型简单介绍一下。交互模型的层数从 12 层压缩到 6 层,排序相关性特征 P95 减少为原本的 1/2,整体搜索入口下降 40ms,模型部署所需的 GPU 机器数也减少了一半,降低了资源消耗。表示模型语义索引存储规模 title 减为 1/4,content 维度从 768 维压缩至 64 维,虽然维度减少了 12 倍,但增加了倒排索引 doc 的数量,所以 content 最终减为 1/6,语义索引召回也有比较大的提升,title 减少为 1/3,content 减少为 1/2。精排模块需要线上实时查询离线计算好的向量,所以查询服务也有提升。表示模型语义索引的构建时间减少为 1/4,底层知乎自研的 TableStore/TIDB 存储减为原来的 1/6,LTR 训练数据和训练时间都有很大的提升,粗排早期用的是 BM25 等基础特征,后来引入了 32 维的 BERT 向量,提升了精排精度。
用于核心搜索的“核心排序”中,蒸馏成2层交互BERT,预测的query-poi相关性分数作为排序的一个特征使用。- 使用下单数据作为正样本,使用未点击过的数据构造负样
- Skip-Above采样:受限于App搜索场景的展示屏效,无法保证召回的POI一次性得到曝光。若直接将未被点击的POI作为负例,可能会将未曝光但相关的POI错误地采样为负例。为了保证训练数据的准确性,我们采用Skip-Above方法,剔除这些噪音负例,即从用户点击过的POI之上没有被点击过的POI中采样负例(假设用户是从上往下浏览的POI)。
- 对于模型输入部分,我们将Query、Doc标题、三级类目信息拼接,并用[SEP]分割,区分3种不同来源信息。对于段向量,原始的BERT只有两种片段编码EA和EB,在引入类目信息的文本信息后,引入额外的片段编码Ec。引入额外片段编码的作用是防止额外信息对Query和Doc标题产生交叉干扰。由于我们改变了BERT的输入和输出结构,无法直接基于MT-BERT进行相关性Fine-tuning任务。我们对MT-BERT的预训练方式做了相应改进,BERT预训练的目标之一是NSP(Next Sentence Prediction),在搜索场景中没有上下句的概念,在给定用户的搜索关键词和商户文本信息后,判断用户是否点击来取代NSP任务。
- loss:除了输入样本上的变化,为了考虑搜索场景下不同样本之间的偏序关系,我们参考RankNet[34]的方式对训练损失函数做了优化。
- Partition-model的思想是利用所有数据进行全场景联合训练,同时一定程度上保留每个场景特性,从而解决多业务场景的排序问题。
损失函数:选用优化NDCG的Lambda Loss特征构造
搜索相关性的特征这里分为三个维度:基础特征、文本匹配特征以及语义匹配特征。基础特征主要包括 query 和 item 的统计特征,以及结构化相关的匹配特征,如类目是否匹配、关键属性(品类、品牌、型号等)是否匹配。文本匹配特征主要是字面上的匹配特征,如 term 匹配数、匹配率、带同义词策略的匹配、带 term weight 的匹配以及最基础的 BM25 分等。语义匹配特征则主要包括基于点击行为的表示匹配、文本和多模态语义匹配。其中基础特征和文本匹配特征相对常规,不再详细展开。下面重点对语义匹配特征做进一步的介绍:文本语义匹配
处于性能考虑,文本的语义匹配采用双塔向量匹配模型结构:基础模型使用开源的 BERT,Query 和 Item 共享相同的参数权重。同时为了适应下游的相关性分档,模型采用 Pointwise 的训练方式。篇幅原因,这里对模型细节不作展开。而相比模型结构的设计,其实闲鱼搜索中更重要的工作在于训练样本的构造。由于现阶段缺少人工标注数据的积累,所以当前该部分工作主要解决以下两个问题:•高置信样本挖掘,缓解搜索点击日志“点击但不相关”的问题。•定制化的负样本构造,避免模型收敛过快,只能判断简单语义相关性,而对上文提到的闲鱼场景"勉强相关"的难 case 无法区分。针对以上问题,参考集团相关经验并结合对闲鱼搜索数据的观察分析,做了如下采样方案: •充足曝光下高点击 ctr 样本(ctr 大于同 query 下商品点击率平均值) •高曝光低点击类目样本:同一个 query 搜索下,根据点击过商品的类目分布,取相对超低频类目样本作为负样本(如类目分布占比 < 0.05 的商品视为负样本)。 •充足曝光情况下,低于相应 query 平均曝光点击率 10%以下的样本做负样本。 •基于 query 核心 term 替换构造负样本:如对于“品牌 A+品类”结构的 Query,使用“品牌 B+品类”结构的 query 做其负样本。 •随机构造负样本:为增加随机性,该部分实现在训练时使用同 batch 中其他样本做负样本,同时引入 batch hard sample 机制。上述方式采样得到的训练数据,随机抽测准确率在 90%+,进一步采样后量级在 4kw+。在此基础上训练双塔模型,上线方式为离线抽取 Embedding,线上查表并计算向量相似度。该部分工作独立全量上线,抽测 top300 query + 随机 200query 搜索满意度+6.6%;同样文本语义向量用于 i2i 向量召回,复用到闲鱼求购场景,核心指标点击互动人次相对提升 20.45%。定义搜索 query top10 商品完全相关/基本相关占比>80%为满意,一组 query 评测结果为满意的占比为 query 满意度。
多模态语义匹配
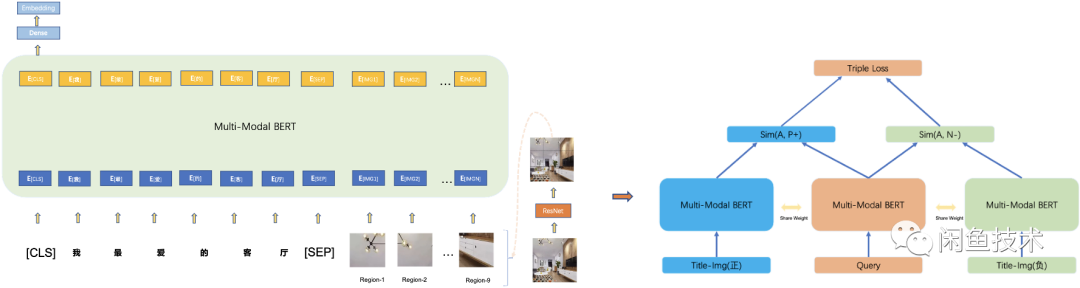
除了文本语义向量匹配,本次工作也尝试了多模态语义向量。模型侧使用预训练的多模态 BERT,类似工作集团已经有大量的尝试,本文主要参考过([1],[2]),并对模型和策略作了一些调整:• 替换多图特征抽取为首图 region 特征抽取做图像特征序列(resnet pooling 前的特征序列),提升链路效率;• 替换 Bert-base 为 Electra-small,减小模型参数(经测试 47M 的模型,下游分类任务精度损失 2 个点以内),方便与 Resnet 联合 E2E 训练。下游的匹配任务仍使用双塔模型策略,和文本语义模型不同的是,这里直接使用 Triple Loss 的方式,主要考虑加大模型之间的差异性,使后面的模型融合有更大的空间。PS: 该部分工作离线 AUC 为 0.75 相对较高,在下游特征融合 AUC 提升 1 个点以上。但在上线过程中,由于需要图像处理,增量商品特征更新回流相对其他链路延迟较大,容易造成新商品特征缺失,因此还需要进一步链路优化。
点击图表示匹配
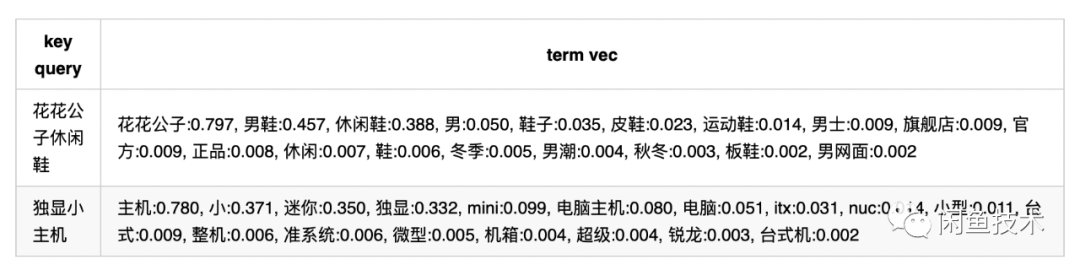
除了上文提到的通过语义向量引入语义信息,还可以借助搜索日志中的点击行为表示 query 或 item 构造图结构引入新的语义表示。其中基于图结构的 match 算法 SWING 算法,在阿里内部应用广泛,相关的文章也有很多,这里不在阐述。针对闲鱼场景首先将点击 pair 对改造为点击 pair 对,这样直接沿用现有的 swing 工具,可以得到 query2query 的列表。聚合 key query 的所有相似 query,并进行分词,对所有的 term 进行加权求和,归一化后得到 key query 的表示。其中的权重为 swing 算法输出的 score,key query 的 term 权重默认为 1。而对于行为稀疏的长尾 query 则使用上文语义向量召回最相近的头部 query,补充其语义表示。最终得到的 query 表示实例:得到 query 表示后,item 同样做类似的归一化表示。上线时使用稀疏存储的方式,在线计算匹配 term 的加权和作为点击图表示匹配分。准备好必要的相关性特征后,下一步则是对众多特征的有效融合,本文则采用经典的 GBDT 模型完成该步骤。选择 GBDT 模型的好处一方面在于检索引擎(Ha3)精排算分插件中有现成的组件可以直接复用,另一方面也在于相比于更加简单的 LR 模型可以省去很多特征预处理步骤,使得线上策略更加简单。模型的训练使用人工标注的训练数据,标注目标为四档(完全相关、基本相关、勉强相关以及完全不相关)。在训练阶段,四个档位被映射到 1、0.75、0.25 和 0 四个分位,GBDT 模型则通过回归的方式对分位进行拟合。由于该部分策略是对子特征的 ensemble,因此并不需要非常多的训练数据(这里的量级在万级别)。最终,经过常规的调参,GBDT 特征融合模型离线 AUC 可以达到 0.86,基本符合预期(最优单特征 AUC 为 0.76)。该策略全量上线,在文本语义向量的基础之上,不影响成交效率的前提下:随机 query 抽测(top 800w)DCG@10 相对提升 6.51%,query 搜索满意度+24%;头部 query 同样也有相应的提升,相应地搜索体感也得到有效提升。