
图像去噪方法总结,最全、最详细……
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
图像降噪的英文名称是Image Denoising, 图像处理中的专业术语。是指减少数字图像中噪声的过程,有时候又称为图像去噪。
01
中值滤波器[1]:它是一种常用的非线性平滑滤波器,其基本原理是把数字图像或数字序列中一点的值用该点的一个领域中各点值的中值代换,其主要功能是让周围像素灰度值的差比较大的像素改取与周围的像素值接近的值,从而可以消除孤立的噪声点,所以中值滤波对于滤除图像的椒盐噪声非常有效。 自适应维纳滤波器[2]:它能根据图像的局部方差来调整滤波器的输出,局部方差越大,滤波器的平滑作用越强。
02
这些方法在测试阶段通常涉及复杂的优化问题,使去噪过程时非常耗时的。因此,大多数基于先验图像先验方法在不牺牲计算效率的情况下很难获得高性能。 模型通常是非凸的并且涉及几个手动选择的参数,提供一些余地以提高去噪性能。
03
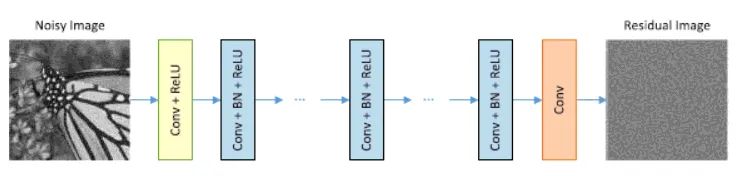

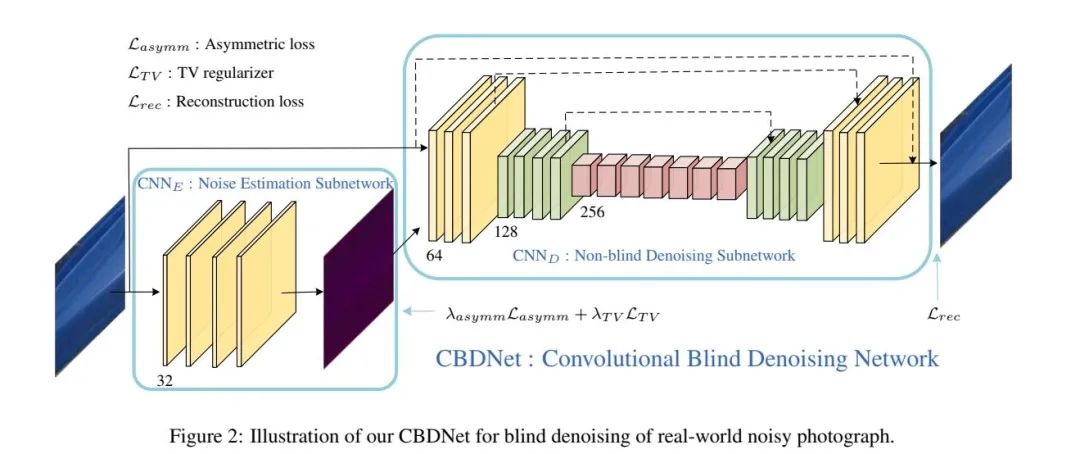
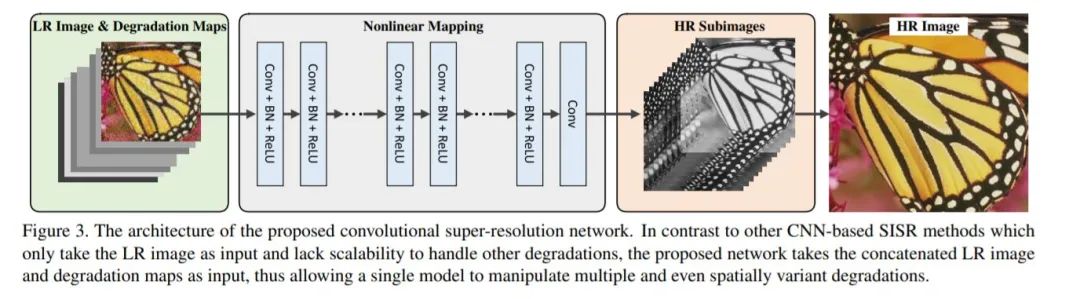
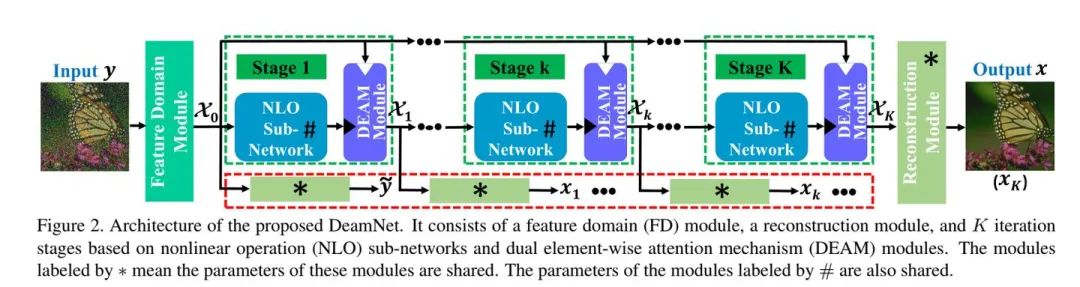
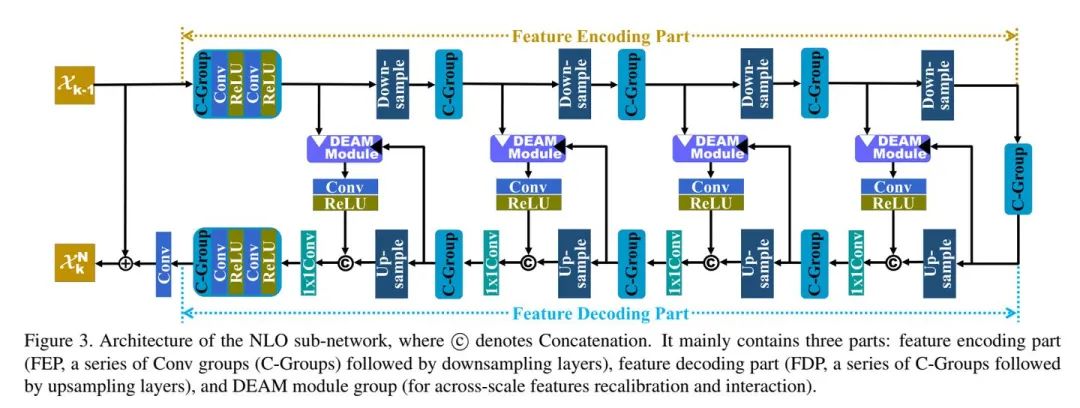
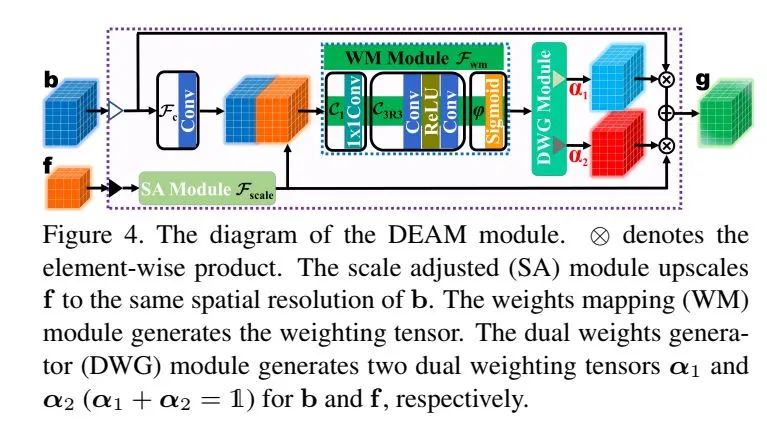
04


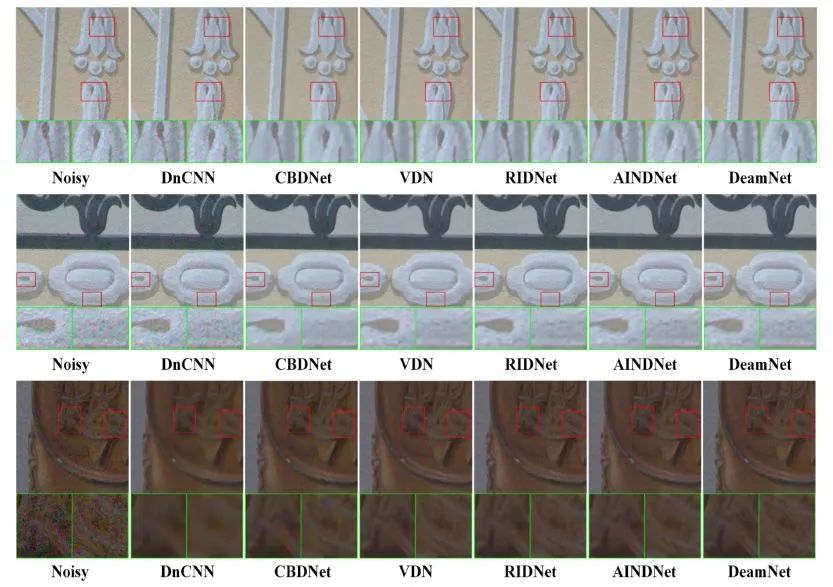


参考文献
本文仅做学术分享,如有侵权,请联系删文。
评论