
优化 Golang 服务来减少 40% 以上的 CPU
十年前,谷歌正在面临一个由 C++ 编译时间过长所造成的严重瓶颈,并且需要一个全新的方式来解决这个问题。谷歌的工程师们通过创造了一种新的被称作 Go (又名 Golang)的语言来应对挑战。这个新语言 Go 带来了 C++ 最好的部分(最主要的是它的性能和稳定性),又与 Python 的速度相结合,使得 Go 能够在实现并发的同时快速地使用多核心。
在 Coralogix(译者注:一个提供全面日志分析的服务产品,官网[1]),我们为了去给我们的客户提供关于他们日志实时的分析、警报和元数据,要去解析他们的日志。在解析阶段,我们需要非常快速地解析包含多个复杂规则的服务日志,这个目标是促使我们决定使用 Golang 的原因之一。
这项新的服务现在就全天候的跑在生产阶段,尽管我们看到了非常好的结果,但是它也需要跑在高性能的机器上。这项 Go 的服务跑在一台 AWS m4.2xlarge 实例上 ,带有 8 CPUs 和 36 GB 的配置,每天要解析几十亿的日志。
在这个阶段一切都运行正常,我们本可以自我感觉良好,但是那并不是我们在 Coralogix 想要的表现。我们想要更多的特性,比如性能等等,或者使用更少的 AWS 实例。为了改进,我们首先需要理解瓶颈的本质以及我们如何能够减少或者完全解决这些问题。
我们决定在我们的服务上进行一些分析,检查一下到底是什么造成了 CPU 的高消耗,看看我们是否能够优化。
首先,我们将 Go 升级到最新的稳定版本(这是软件生命周期中的关键一步)。我们是用的 Go 1.12.4 版本,最新的是 1.13.8(目前最新版本已经 1.14.x)。根据 文档[2] ,Go 1.13 发行版在运行时库方面和一些其他主要利用内存使用的组件方面已经有了长足的进步。总之,使用最新的稳定版本能帮助我们节省许多工作。
因此,内存消耗由大约 800 MB 降低到了仅 180 MB。
第二,为了更好的理解我们的流程以及弄清楚我们应该在哪花费时间和资源,我们开始去进行分析。
分析不同的服务和程序语言可能看起来很复杂并且令人望而生畏,但是对于 Go 来说它实际上十分容易,仅仅几个命令就能够描述清楚。Go 有一个专门的工具叫“pprof”,它通过监听一个路由(默认端口 6060)能够应用在你的 app 上,并且使用 Go 的包来管理 HTTP 连接:
import _ "net/http/pprof"
接着在你的 main 函数中或者路由包下按照如下操作初始化:
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
现在你可以启动你的服务并且连接到:
http://localhost:6060/debug/pprof
Go 官方提供的完整文档可以 在这[3] 找到。
pprof 的默认配置是每 30 秒对 CPU 的使用情况进行采样。有许多不同的选择,也可以对 CPU 的使用,堆的使用或者其他更多的使用情况进行采样。
我们主要关注 CPU 使用,因此在生产阶段采取了一个 30 秒的性能分析,并且发现了你在下图所看到的情况(提醒一下:这是在我们把 Go 版本升级并且将 Go 的内部组件降到最低之后的结果):
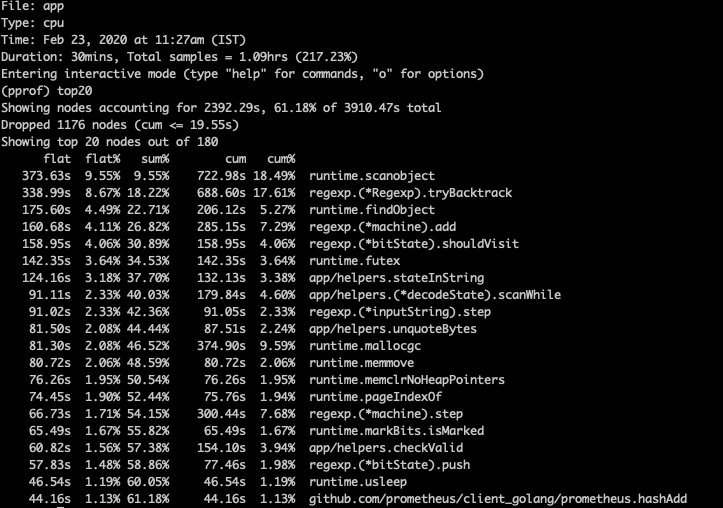 Go profiling — Coralogix
Go profiling — Coralogix
正如你所看到的,我们发现了许多运行时库的活动:GC 几乎使用了 29% 的 CPU(还仅仅只是消耗最多的前 20 个对象)。因为 Go 的 GC 非常快并且做了巨大的优化,最好的实践就是不要去改变或者修改它。因为我们的内存消耗非常低(与我们先前的 Go 版本相比),所以主要的怀疑对象就变成了较高的对象分配率。
如果是那种情况的话,我们就能做两件事情了:
调整 Go GC 活动,使其适合我们的服务行为,意味着 —— 延缓它的触发以使 GC 变的不那么频繁。这将使我们不得不补偿更多的内存使用。 找出我们代码中那些分配了太多对象的函数、区段或者行。
观察一下我们的实例类型,很明显我们有大量的内存可供使用,并且我们正在被机器的 CPU 数量所限制。因此我们仅仅需要调整一下比率。因为在 Golang 的早期有一个大多数开发者都不关注的数据,叫 GOGC。这个数值默认是 100,简单地告诉你的系统什么时候触发 GC。这个默认值使得堆的大小在到达它初始态的两倍时触发 GC。将这个数值改成一个更大的数将会延缓 GC 的触发,降低它的频率。我们基准测试了许多不同的数,最终对于我们的目标来说最好的性能是在使用 GOGC = 2000 的时候。
这立刻增加了我们的内存使用,从大约 200 MB 到 大约 2.7 GB(那还是由于我们的 Go 版本更新,在内存消耗降低的情况下),另外也减少了我们 CPU 大约 10% 的使用。
这个接下来的截图就展示了这些基准测试的结果:
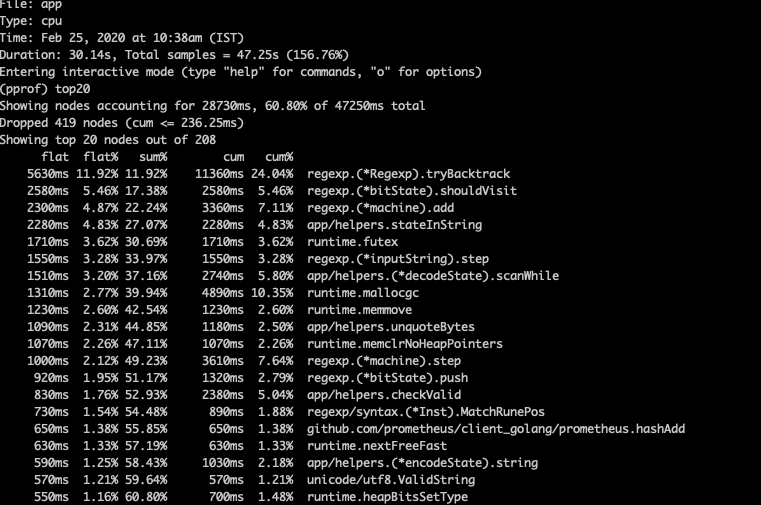 GOGC =2000 results — Coralogix benchmark
GOGC =2000 results — Coralogix benchmark
前面的四个 CPU 的消耗函数就是我们的服务函数,这十分有意义。全部的 GC 使用现在大约是 13%,是先前消耗的一半还少!
我们其实可以在这就停下来了,但是我们还是决定去揭露我们在哪并且为什么会分配这么多对象。很多时候,这么做有充分理由(比如在流式处理的情况下,我们为每条获取的消息创建了许多新的对象,并且因为它与下一条消息无关,需要去移除它),但是在某些情况下有一种简单的方法可以去优化并且动态地减少对象的创建。
首先,让我们运行一个和之前同样的命令,有一点小的改变,采用堆调试:
http://localhost:6060/debug/pprof/heap
为了查询结果文件,你可以运行如下命令在你的代码目录下来分析调试结果:
go tool pprof -alloc_objects
我们的截图看起来像这样:
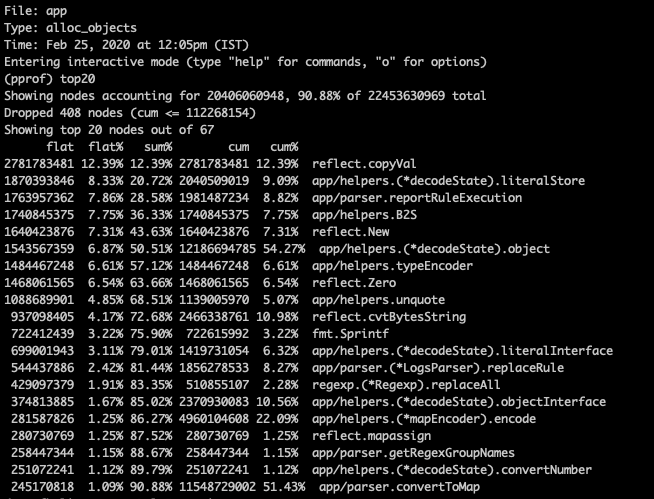 除了第三行一切似乎都很合理,这是一个监控函数,在每个 Carologix 规则解析阶段的末尾向我们的 Promethes 调用者展示结果。为了获取进一步信息,我们运行如下命令:
除了第三行一切似乎都很合理,这是一个监控函数,在每个 Carologix 规则解析阶段的末尾向我们的 Promethes 调用者展示结果。为了获取进一步信息,我们运行如下命令:
list
例如:
list reportRuleExecution
然后我们会获得如下结果:
 WithLabelValues 的两个调用都是为了软件度量的 Prometheus 函数(我们将这个留给产品去决定是否真正需要)。而且,我们可以看到第一行创建了大量的对象(由这个函数所创建的全部对象的 10%)。我们进一步查看发现它是一个对于绑定到导出数据的消费者 ID 从 int 到 string 的转换,十分重要,但是考虑到实际情况,我们数据库中消费者的数量十分有限,我们不应该采用 Prometheus 的方式来接收变量作为 string 类型。因此取代了每次创建一个新的 string 并且在函数末尾都抛弃的这种方法(浪费分配还有 GC 的多余工作),我们在对象的分配阶段定义了 map,配对了所有从 1 到 10 万的数字和一个需要执行的 “get” 方法。
WithLabelValues 的两个调用都是为了软件度量的 Prometheus 函数(我们将这个留给产品去决定是否真正需要)。而且,我们可以看到第一行创建了大量的对象(由这个函数所创建的全部对象的 10%)。我们进一步查看发现它是一个对于绑定到导出数据的消费者 ID 从 int 到 string 的转换,十分重要,但是考虑到实际情况,我们数据库中消费者的数量十分有限,我们不应该采用 Prometheus 的方式来接收变量作为 string 类型。因此取代了每次创建一个新的 string 并且在函数末尾都抛弃的这种方法(浪费分配还有 GC 的多余工作),我们在对象的分配阶段定义了 map,配对了所有从 1 到 10 万的数字和一个需要执行的 “get” 方法。
现在运行一个新的性能分析会话来验证我们的论点并且它的对的(你可以看到这一部分并不会再分配对象了):

这并不是一个显著的改进,但是总体来说为我们节省了另一个 GC 的活动,说的更具体一点就是节省了大约 1% 的 CPU。
最终的状态就是下面的截图:
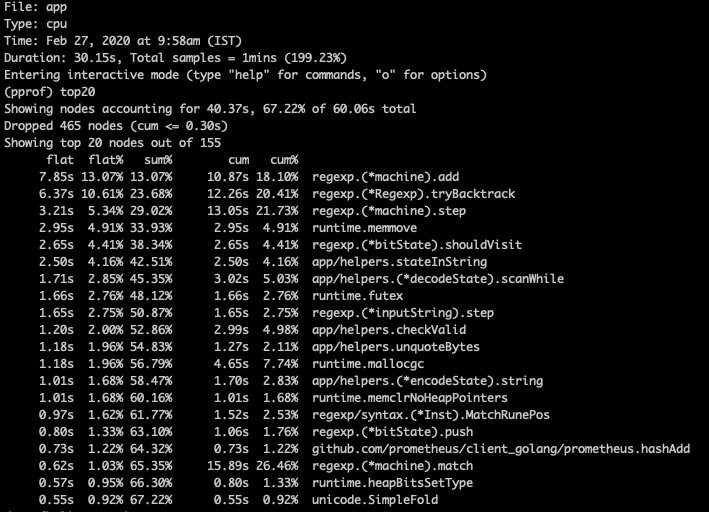
最终结果
1) 内存使用:大约 1.3 GB -> 大约 2.7 GB
2) CPU 使用:大约 2.55 avg 和 大约 5.05 峰值期 -> 大约 2.13 avg 和 大约 2.9 峰值期。
在我们 Golang 优化前的 CPU:
 在我们 Golang 优化后的 CPU:
在我们 Golang 优化后的 CPU:
 总体来说,我们可以看到主要的改进是在每秒日志处理量增加时的高峰时间。这就意味着我们的基础架构不仅不需要再为了异常值进行调整,而且变得更加稳定了。
总体来说,我们可以看到主要的改进是在每秒日志处理量增加时的高峰时间。这就意味着我们的基础架构不仅不需要再为了异常值进行调整,而且变得更加稳定了。
总结
通过对我们的 Go 解析服务进行性能测试,我们能够查明有问题的地方,更好的理解我们的服务并且确定在哪里(如果有的话)投资时间进行改进。大多数性能分析工作都会以一些基础数值或配置的调整,更合适你的使用情况并且最终展现更好的性能而结束。
via:https://medium.com/coralogix-engineering/optimizing-a-golang-service-to-reduce-over-40-cpu-366b67c67ef9
作者:Eliezer Yaacov[4]译者:sh1luo[5]校对:@unknwon[6]
本文由 GCTT[7] 原创编译,Go 中文网[8] 荣誉推出
参考资料
官网: https://coralogix.com/
[2]文档: https://golang.org/doc/devel/release.html
[3]在这: https://golang.org/pkg/net/http/pprof
[4]Eliezer Yaacov: https://medium.com/@eliezerj8
[5]sh1luo: https://github.com/sh1luo
[6]@unknwon: https://github.com/unknwon
[7]GCTT: https://github.com/studygolang/GCTT
[8]Go 中文网: https://studygolang.com/
推荐阅读
站长 polarisxu
自己的原创文章
不限于 Go 技术
职场和创业经验
Go语言中文网
每天为你
分享 Go 知识
Go爱好者值得关注