
【深度学习】聊聊Batch Normalization在网络结构中的位置
“葡萄是一点一点成熟的,知识是一天一天积累的。”

Batch Normalization
1. 什么是Batch Normalization?
谷歌在2015年就提出了Batch Normalization(BN),该方法对每个mini-batch都进行normalize,下图是BN的计算方式,会把mini-batch中的数据正规化到均值为0,标准差为1,同时还引入了两个可以学的参数,分别为scale和shift,让模型学习其适合的分布。

那么为什么在做过正规化后,又要scale和shift呢?当通过正规化后,把尺度缩放到0均值,再scale和shift,不是有可能把数据变回"原样"?因为scale和shift是模型自动学习的,神经网络可以自己琢磨前面的正规化有没有起到优化作用,没有的话就"反"正规化,抵消之前的正规化操作带来的影响。
2. 为什么要用Batch Normalization?
(1) 解决梯度消失问题
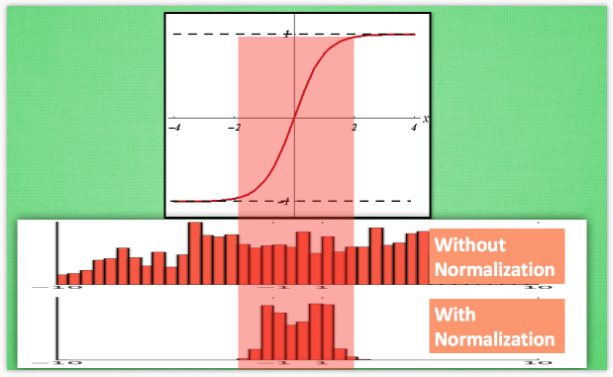
拿sigmoid激活函数距离,从图中,我们很容易知道,数据值越靠近0梯度越大,越远离0梯度越接近0,我们通过BN改变数据分布到0附近,从而解决梯度消失问题。
(2) 解决了Internal Covariate Shift(ICS)问题
先看看paper里对ICS的定义:

由于训练过程中参数的变化,导致各层数据分布变化较大,神经网络就要学习新的分布,随着层数的加深,学习过程就变的愈加困难,要解决这个问题需要使用较低的学习率,由此又产生收敛速度慢,因此引入BN可以很有效的解决这个问题。
(3)加速了模型的收敛
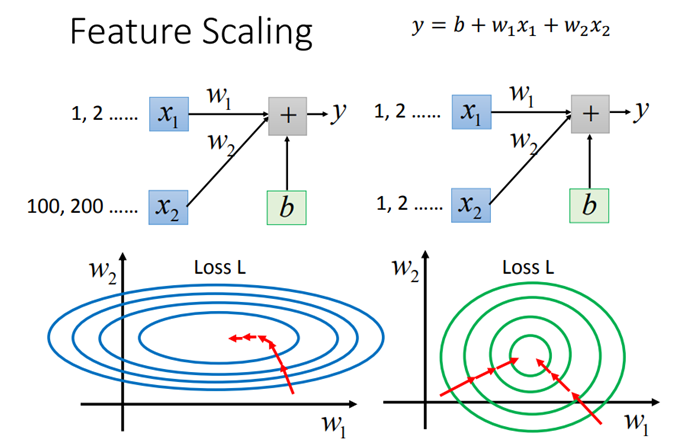
和对原始特征做归一化类似,BN使得每一维数据对结果的影响是相同的,由此就能加速模型的收敛速度。
(4)具有正则化效果
BN层和正规化/归一化不同,BN层是在mini-batch中计算均值方差,因此会带来一些较小的噪声,在神经网络中添加随机噪声可以带来正则化的效果。
3. Batch Normalization添加在哪?
所以实际使用上,BatchNorm层应该放在哪呢?层与层直接都要加吗?加在激活函数前还是激活函数后?卷积层和pooling层要不要加?有人说这个应该加在非线性层后,如下顺序。
Linear->Relu->BatchNorm->Dropout
论文里有提到,BN层常常被加到Relu之前,但是没有明确的标准,需要尝试不同配置,通过实验得出结论(很多实验结果偏向于Relu在BN之前)。
那BN层和dropout层的顺序呢?
我们可以看到这样的代码,BN在dropout之后。

也可以看到这样的代码,BN在dropout之前。

实际上,BN消除了对dropout的依赖,因为BN也有和dropout本质一样的正则化的效果,像是ResNet, DenseNet等等并没有使用dropout,如果要用并用BN和dropout,还是建议BN放在dropout之前。
注:对BN和dropout感兴趣的可以看下这篇论文《Understanding the Disharmony between Dropout and Batch Normalization by
Variance Shif》
https://arxiv.org/pdf/1801.05134.pdf

敲黑板,记重点!
1、BN层可以缓解梯度消失,解决ICS问题,加速模型的收敛,并且具有正则化效果。
2、 BN层往往添加在Relu层后,Dropout层之前。

往期精彩回顾
本站qq群851320808,加入微信群请扫码: