
MySQL8.0性能优化
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | Sol·wang
来源 | urlify.cn/yArUf2
MySQL8.0 引擎:
来看看MySQL8提供的引擎: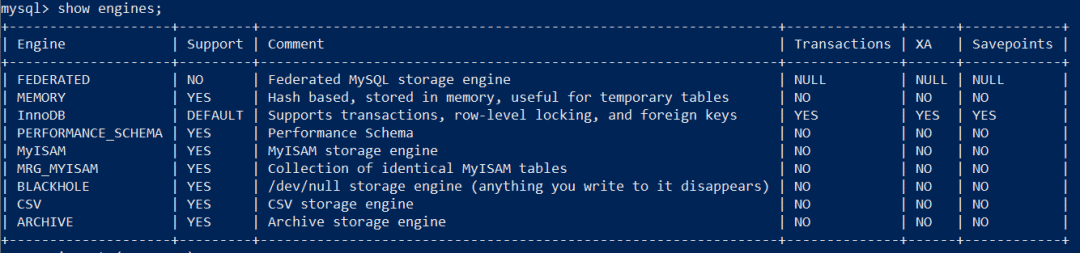
常用引擎:
InnoDB:支持事务,行级锁,外键,崩溃修复,多版本并发控制;读写效率相对较差,内存使用相对较高,占用数据空间相对较大。
MyISAM:不支持事务,不支持外键,仅支持非聚集索引,支持全文索引,仅支持到表级锁,支持数据压缩,占用空间相对小,内存使用相对较低,读写性能相对极佳。
Memory:依赖于内存空间,数据处理速度快,仅支持到表级锁。
应用场景:
InnoDB:依赖于 事务,回滚,并发,大数据量,外键,行级锁 的场景。
MyISAM:过多的大数据量的频繁的查询优势。
Memory:临时性的,大数据量表的查询优势。
在创建表的时候,可依据应用场景选择合适的引擎。
分表 / 拆表 / 分库 / 分盘
分表:解决单表数据量过大的性能瓶颈,小范围的数据处理,避免过多数据扫描;可按业务类型数据、时间跨度等实际场景分表。
拆表:按场景合理的将大表分为多个小表来降低锁竞争
分库:分实例分别各自处理,量与性能的分散优化处理,欠缺的事务一致性,可按实际场景合理分库。
分盘:主要解决磁盘IO瓶颈,多磁盘分散并行运行。
索引
索引分类
普通索引:无限制
主键索引:表中只能有一个,不能为NULL
唯一索引:值不能重复
全文索引:仅MyISAM支持,仅支持 char、varchar、text 类型
组合索引:多列一起创建的合并索引,非单列分别创建的索引
所有存储引擎对每个表至少支持了16个索引。
索引设计原则:
为经常需要排序、分组或联合操作的字段建立索引,经常需要使用 order by、group by、distinct、uninon 等的操作字段
为经常查询出的列建立索引,为经常作为查询条件的字段建立索引
推荐长度较少的列建索引,推荐列使用固定长度。
过多的索引建立对表数据变更操作的性能下降的影响
删除不再使用或很少使用的索引,减少索引对更新时的影响
索引覆盖,索引下推,避免回表查询(以下介绍)
索引命中:
依据索引查询,查询条件常以索引列开始
组合索引的最左原则:必须以组合索引列的首列开始的条件查询,按序依次。
索引覆盖,推荐要查询出的字段全部为索引列。假如页面列表呈现出个别主要的字段内容的场景;具体的详细内容在详细页呈现,透过主键查询单条数据。
避免回表查询:MySQL首先查出带索引的列数据,再透过主键列去查询非索引列的数据信息,把两次查询的数据组合后返回客户端。所以推荐索引覆盖。
脚本优化
尽量避免嵌套子查询,改用JOIN方式。
尽量减少 查询中的全表扫描次数 ,尤其是对于大表,如采用EXISTS、WHERE的条件顺序等。
避免字段以难以理解的方式转换查询,采用更为合理的转换方式。
去除不必要的括号,避免复杂逻辑查询。如 (1=1 and (b>a and b=c)) and a=5 推荐为 b>5 and b=c and a=5
简化减少WHERE条件范围区间的重叠部分。如 (key1 < 'abc' and 1=1) or (key1 < 'bar') or (false) 推荐为 key1 < 'bar'
避免WHERE后用函数临时的计算,可事先生成结果列或虚拟列。
推荐WHERE中首次出现的IS NULL赋予更大的作用,因为MySQL8仅对首次出现的IS NULL做大量优化。
某些场景对索引的失效或破坏,FORCE INDEX:指明优先使用的索引并生效;常用于JOIN。
IN的嵌套查询改为EXISTS的嵌套查询。
INNER JOIN 时,STRAIGHT_JOIN 指明优先检索的主表,使其特定场景中达到我们的预期效果。
被嵌套的查询更多的筛选和处理,使其减少外表查询的数据基数。
批量INSERT使用包含多个VALUES列表的语句一次插入多行,量越大效果越明显。(加大 bulk_insert_buffer_size、Max_allowed_packet、Net_buffer_length 的值,满足更大量的处理)
推荐默认值列,非显示的插入减少必要的解析。
某些场景下,replace into 的使用,代替 insert/update,成为单一的原子操作。
SQL片段WITH AS的运用,Memory Table 的利用。
查询仅返回需要的字段,避免 *,避免回表查询;仅返回需要的数据量。
InnoDB缓冲池
一个称为缓冲池的存储区域,用于在内存中缓存数据和索引,利用它将经常访问的数据保存在内存中,减少了SQL执行及磁盘IO的资源消耗。为了更多的需要暂存空间,满足更大数据量的暂存。
参数设置:
innodb_buffer_pool_size:缓冲池的承载总量,建议设为系统内存的50%-70%
innodb_buffer_pool_chunk_size:缓冲池每块大小,默认128M
innodb_buffer_pool_instances:多线程缓冲池实例并行运行,默认1实例,最大64实例
设置规则:
innodb_buffer_pool_size = (innodb_buffer_pool_chunk_size * {N}块 )* innodb_buffer_pool_instances
也就是说,innodb_buffer_pool_size 必须是 innodb_buffer_pool_chunk_size 的倍数
举例说明:
符合的例子:innodb_buffer_pool_size=8G,innodb_buffer_pool_chunk_size=128M,innodb_buffer_pool_instances=16
不符的例子:innodb_buffer_pool_size=9G,innodb_buffer_pool_chunk_size=128M,innodb_buffer_pool_instances=16
对于以上非倍数的状况:
MySQL会自动将 innodb_buffer_pool_size 调整为 innodb_buffer_pool_chunk_size 的倍数;所以会变为 innodb_buffer_pool_size = 10G
运行机制:
缓冲区分为 热数据区 / 冷数据区,两者空间占比约为 7/3,每区中的数据集依使用频率按顺序依次排列。
当一个新的查询结果出现后,首先考虑存放到冷数据区,当冷数据区的结果集使用达到一定频率,会被改存到热数据区,使用频率最好的数据集会被存放到热区的首位,当然也有热区转到冷区的状况。
MySQL8 去除了 [查询缓存] query_cache_type、query_cache_size、query_cache_limit
连接池
MySQL连接器中的连接池,用以提高数据库密集型应用程序的性能和可扩展性。默认启用。MySQL连接器负责管理连接池中的多个连接,自动创建、打开、关闭和破坏连接,多个连接的创建,可满足多客户端的频繁连接,连接的重复使用获得最佳性能。
MySQL连接器 每三分钟运行一次后台作业,并从池中删除闲置(未使用)超过三分钟的连接。池清理释放客户端和服务器端的资源。这是因为在客户端每个连接都使用一个Socket,而在服务器端每个连接都使用一个Socket和一个线程。
透过连接字符串参数对连接池的设定调整其性能特点:
开启连接池:Pooling=true,默认开启
复用时重置连接状态:ConnectionReset=True
保持连接设置:CacheServerProperties=True
连接超时回收(秒):ConnectionLifeTime=300
支持的最大连接数量:Max Pool Size=100
保持最小的连接数量:Min Pool Size=10
日志
MySQL在运行时,会有各种不同日志的记录,大量的各种类型的日志产生,会对资源的开销产生严重的影响,必要的时候我们选择性的开启。但在生产环境时,有些日志并不是必须,以下列出MySQL各种日志信息:
错误日志:启动、关闭、运行时 产生的异常记录,建议开启,设置 log_error
查询日志:客户端连接和执行的脚本,建议关闭,设置 general_log
慢查询日志:记录超时的查询,记录不适用索引的查询等,建议关闭,设置 slow_query_log
二进制日志:用于数据同步复制,需发送的数据日志,多用于集群,如需开启,设置 log_bin
中继日志:用于数据同步复制时,接收到的数据日志,多用于集群,如需开启,设置 relay_log

