
爬虫案例:拉勾网工作职位爬取
本人非IT专业,因为对python爬虫比较感兴趣,因此正在自学python爬虫,学习后就拿拉勾网练练手🤭,同时给zhenguo老师投稿,还能收获50元。
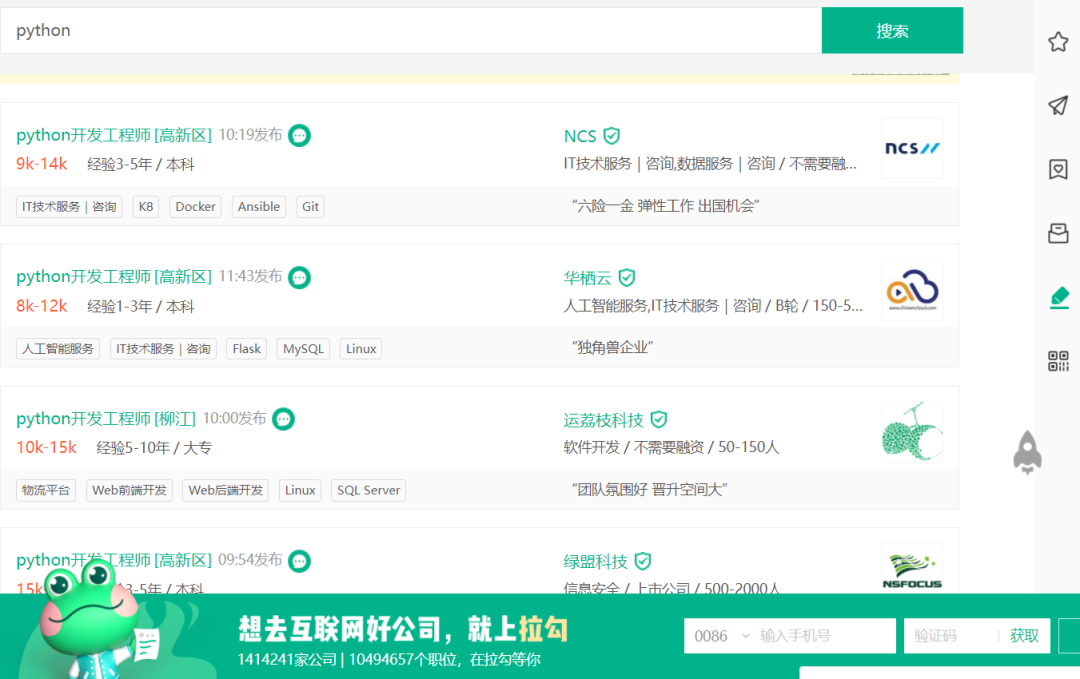


本次我们的目标是爬取拉勾网上成都的python岗位信息,包括职位名称、地区、薪水、任职要求、工作内容标签、公司名称、公司的类别及规模和福利待遇等信息,并将这些信息保存在一个CSV文件当中,废话不多说,开干!
首先我们进入拉勾网,输入Python关键信息,并选择成都,首先分析一下当前的url,url当中的pn=为页码,因此我们想爬取第几页的信息,就将pn的值设置为第几页。
'https://www.lagou.com/wn/jobs?pn=2&fromSearch=true&kd=python&city=%E6%88%90%E9%83%BD'
'https://www.lagou.com/wn/jobs?pn=1&fromSearch=true&kd=python&city=%E6%88%90%E9%83%BD'
想要爬取所有页面,只需要设置一个循环,每个循环中调用爬取工作信息的函数即可,代码如下:
if __name__ == '__main__':
# 爬取1-30页的内容
for page in range(1, 31):
url = f'https://www.lagou.com/wn/jobs?pn={page}&fromSearch=true&kd=python&city=%E6%88%90%E9%83%BD'
# 该函数的功能为爬取一页信息内容并写入到CSV文件内
get_info_job(url)
# 为了保证爬取速度过快导致IP被封,设置一下等待时间,爬取下一页的时候等待2秒
sleep(2)
接下来就是定义爬取每一页工作信息内容并写入到CSV文件内保存的函数,该函数的实现方式如下:def get_info_job(job_url):
response = requests.get(url=job_url, headers=headers).text
selector = html.etree.HTML(response)
lis = selector.xpath('//*[@id="jobList"]/div[1]/div')
for li in lis:
name_area = li.xpath('.//div[1]/div[1]/div[1]/a/text()')
# 获取职位名称
title = name_area[0]
# 获取地区
area = name_area[1].replace('[', '').replace(']', '')
# 获取薪水
salary = li.xpath('.//div[1]/div[1]/div[2]/span/text()')[0]
# 获取经验和学历要求,有时候没有要求时,xpath匹配结果是一个空列表,程序会报错,因此这里需要捕获异常,一旦捕获异常,代表该工作无要求
try:
exp_degree = li.xpath('.//div[1]/div[1]/div[2]/text()')[0]
except IndexError:
exp_degree = '无要求'
# 获取工作标签,有时候没有工作标签,没有的话就用“/”代替
tags = li.xpath('.//div[2]/div[1]/span/text()')
if not tags:
tags = '/'
# 获取公司名称
company_name = li.xpath('.//div[1]/div[2]/div[1]/a/text()')[0]
# 获取公司类别和规模,有些公司没有这些信息,xpath匹配结果是一个空列表,程序会报错,因此捕获异常,一旦捕获到异常,代表没有公司类别和规模信心,用“/”代替
try:
company_Type_Size = li.xpath('.//div[1]/div[2]/div[2]/text()')[0]
except IndexError:
company_Type_Size = '/'
# 获取福利待遇,同样有些公司不公布福利待遇,xpath匹配结果也是一个空列表,程序会报错,因此需捕获异常,一旦捕获到异常,代表公司没有公布福利待遇等信息,用“/”替代
try:
benefits = li.xpath('.//div[2]/div[2]/text()')[-1].replace('“', '').replace('”', '')
except IndexError:
benefits = '/'
job_datas = {
'职位名称': title,
'地区': area,
'薪水': salary,
'经验和学历要求': exp_degree,
'工作标签': tags,
'公司名称': company_name,
'公司类别和规模': company_Type_Size,
'福利待遇': benefits
}
# print(job_datas)
writer.writerow([
title,
area,
salary,
exp_degree,
tags,
company_name,
company_Type_Size,
benefits
])
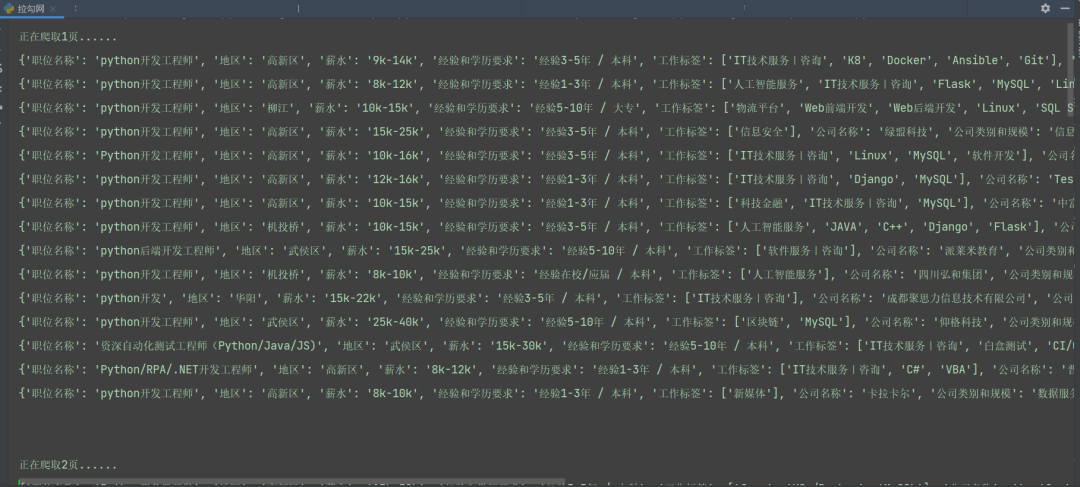
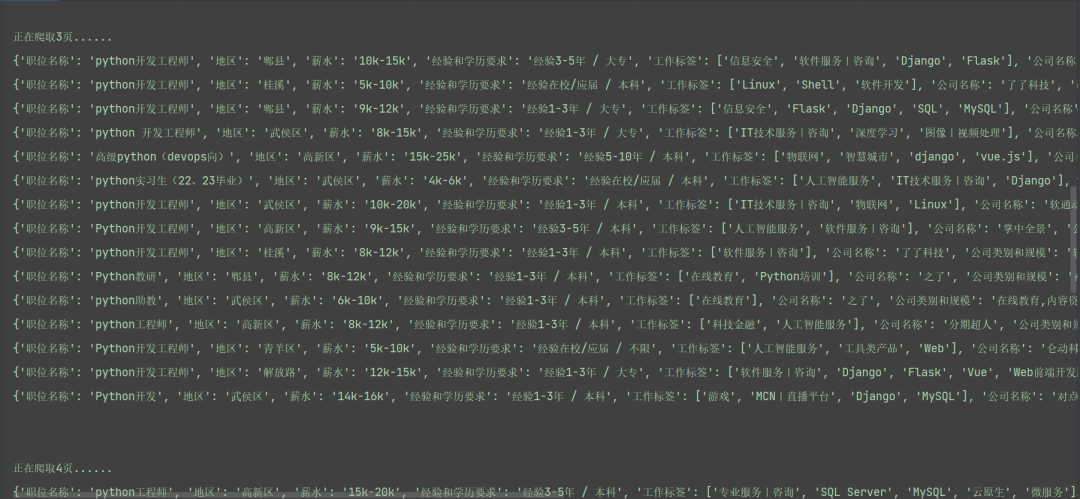
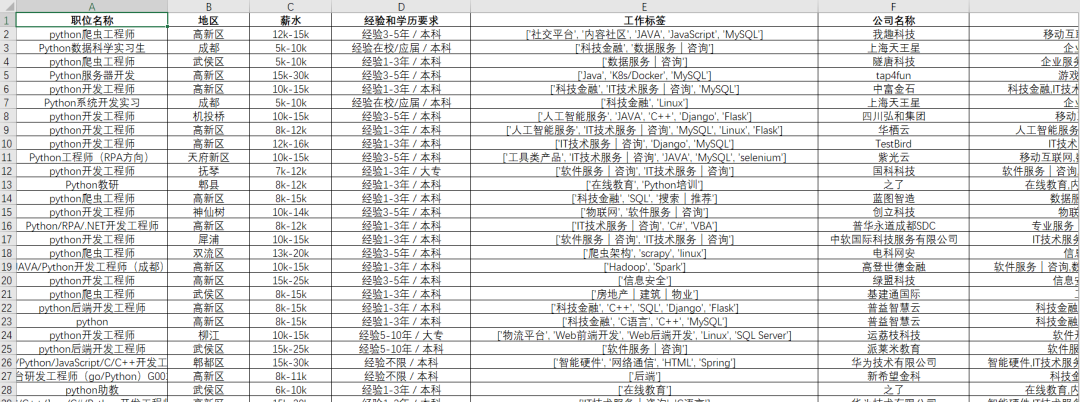
这里具体的爬取和保存的函数就定义完毕了,每次循环的时候直接调用该函数就行了,并且该程序能够适配所有地区和所有工作岗位的信息爬取,只需要更换具体的url就行了。该程序爬取成都岗位的信息效果图如下:
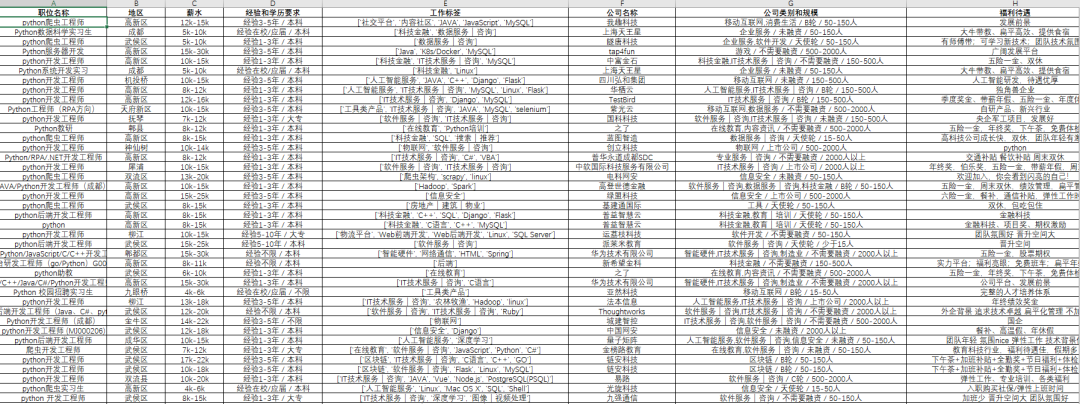
我们可以看到,我们爬取的信息有职位名称、地区、薪水、经验和学历要求、工作标签、公司名称、公司类别和规模、福利待遇等信息。
完整源码下载,请关注我的公众号,后台回复:拉勾
评论