
【软件开发】编程语言C++(下篇)
Start:关注本公众号后,可直接联系后台获取排版美化的详细文档!
Hints:本篇文章所编纂的资料均来自网络,特此感谢参与奉献的有关人员。
C++的语法组成:
-类 - 类可以定义为描述对象行为/状态的模板/蓝图。
-对象 - 对象具有状态和行为。例如:一只狗的状态 - 颜色、名称、品种,行为 - 摇动、叫唤、吃。对象是类的实例。
-方法 - 从基本上说,一个方法表示一种行为。一个类可以包含多个方法。可以在方法中写入逻辑、操作数据以及执行所有的动作。
-即时变量 - 每个对象都有其独特的即时变量。对象的状态是由这些即时变量的值创建的。
C++的内容组成:
1核心语言,提供了所有构件块,包括变量、数据类型和常量,等等。
2C++ 标准库,提供了大量的函数,用于操作文件、字符串等。
3标准模板库(STL),提供了大量的方法,用于操作数据结构等。
C++ 的标准库
C++ 标准库可以分为两部分:
-标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的。函数库继承自 C 语言。
-面向对象类库: 这个库是类及其相关函数的集合。
-标准函数库
-输入/输出 I/O
-字符串和字符处理
-数学
-时间、日期和本地化
-动态分配
-其他
-宽字符函数
-面向对象类库
标准的 C++ 面向对象类库定义了大量支持一些常见操作的类,比如输入/输出 I/O、字符串处理、数值处理。面向对象类库包含以下内容:
-标准的 C++ I/O 类
-String 类
-数值类
-STL 容器类
-STL 算法
-STL 函数对象
-STL 迭代器
-STL 分配器
-本地化库
-异常处理类
-杂项支持库
C++ 的STL库
C++ 标准模板库的核心包括以下三个组件:
组件 | 描述 |
容器(Containers) | 容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器,比如 deque、list、vector、map 等。 |
算法(Algorithms) | 算法作用于容器。它们提供了执行各种操作的方式,包括对容器内容执行初始化、排序、搜索和转换等操作。 |
迭代器(iterators) | 迭代器用于遍历对象集合的元素。这些集合可能是容器,也可能是容器的子集。 |
C++的存储类:
存储类定义 C++ 程序中变量/函数的范围(可见性)和生命周期。
auto 存储类
auto 关键字用于两种情况:声明变量时根据初始化表达式自动推断该变量的类型、声明函数时函数返回值的占位符。在C++11中已删除这一用法。
register 存储类
register 存储类用于定义存储在寄存器中而不是 RAM 中的局部变量。
static 存储类
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。
extern 存储类
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 'extern' 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
mutable 存储类
mutable 说明符仅适用于类的对象,mutable 成员可以通过 const 成员函数修改。
thread_local 存储类
使用 thread_local 说明符声明的变量仅可在它在其上创建的线程上访问。变量在创建线程时创建,并在销毁线程时销毁。每个线程都有其自己的变量副本。
C++的输入输出
C++ 的 I/O 发生在流中,流是字节序列。如果字节流是从设备(如键盘、磁盘驱动器、网络连接等)流向内存,这叫做输入操作。如果字节流是从内存流向设备(如显示屏、打印机、磁盘驱动器、网络连接等),这叫做输出操作。
/O 库头文件
下列的头文件在 C++ 编程中很重要。
头文件 | 函数和描述 |
<iostream> | 该文件定义了 cin、cout、cerr 和 clog 对象,分别对应于标准输入流、标准输出流、非缓冲标准错误流和缓冲标准错误流。 |
<iomanip> | 该文件通过所谓的参数化的流操纵器(比如 setw 和 setprecision),来声明对执行标准化 I/O 有用的服务。 |
<fstream> | 该文件为用户控制的文件处理声明服务。我们将在文件和流的相关章节讨论它的细节。 |
标准输入流(cin)
预定义的对象 cin 是 iostream 类的一个实例。cin 对象附属到标准输入设备,通常是键盘。cin 是与流提取运算符 >> 结合使用的
标准错误流(cerr)
预定义的对象 cerr 是 iostream 类的一个实例。cerr 对象附属到标准错误设备,通常也是显示屏,但是 cerr 对象是非缓冲的,且每个流插入到 cerr 都会立即输出。
标准日志流(clog)
预定义的对象 clog 是 iostream 类的一个实例。clog 对象附属到标准错误设备,通常也是显示屏,但是 clog 对象是缓冲的。这意味着每个流插入到 clog 都会先存储在缓冲区,直到缓冲填满或者缓冲区刷新时才会输出。
C++ 文件和流
使用了 iostream 标准库,它提供了 cin 和 cout 方法分别用于从标准输入读取流和向标准输出写入流。
数据类型 | 描述 |
ofstream | 该数据类型表示输出文件流,用于创建文件并向文件写入信息。 |
ifstream | 该数据类型表示输入文件流,用于从文件读取信息。 |
fstream | 该数据类型通常表示文件流,且同时具有 ofstream 和 ifstream 两种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。 |
在从文件读取信息或者向文件写入信息之前,必须先打开文件。ofstream 和 fstream 对象都可以用来打开文件进行写操作,如果只需要打开文件进行读操作,则使用 ifstream 对象。
下面是 open() 函数的标准语法,open() 函数是 fstream、ifstream 和 ofstream 对象的一个成员。
void open(const char *filename, ios::openmodemode);
模式标志 | 描述 |
ios::app | 追加模式。所有写入都追加到文件末尾。 |
ios::ate | 文件打开后定位到文件末尾。 |
ios::in | 打开文件用于读取。 |
ios::out | 打开文件用于写入。 |
ios::trunc | 如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为 0。 |
当 C++ 程序终止时,它会自动关闭刷新所有流,释放所有分配的内存,并关闭所有打开的文件。但程序员应该养成一个好习惯,在程序终止前关闭所有打开的文件。
下面是 close() 函数的标准语法,close() 函数是 fstream、ifstream 和 ofstream 对象的一个成员。
void close();
写入文件
在 C++ 编程中,我们使用流插入运算符( << )向文件写入信息,就像使用该运算符输出信息到屏幕上一样。唯一不同的是,在这里您使用的是 ofstream 或 fstream 对象,而不是 cout 对象。
读取文件
在 C++ 编程中,我们使用流提取运算符( >> )从文件读取信息,就像使用该运算符从键盘输入信息一样。唯一不同的是,在这里您使用的是 ifstream 或 fstream 对象,而不是 cin 对象。
文件位置指针
istream 和 ostream 都提供了用于重新定位文件位置指针的成员函数。这些成员函数包括关于 istream 的 seekg("seekget")和关于 ostream 的 seekp("seek put")。
seekg 和 seekp 的参数通常是一个长整型。第二个参数可以用于指定查找方向。查找方向可以是 ios::beg(默认的,从流的开头开始定位),也可以是 ios::cur(从流的当前位置开始定位),也可以是 ios::end(从流的末尾开始定位)。
C++ 的异常处理
异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。
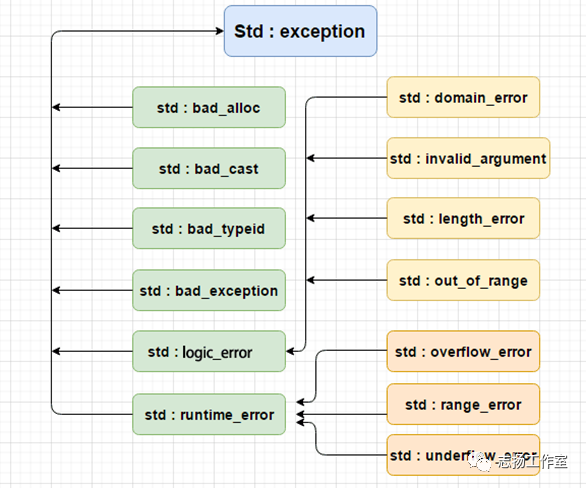
异常提供了一种转移程序控制权的方式。C++ 异常处理涉及到三个关键字:try、catch、throw。
-throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
-catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
-try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
异常 | 描述 |
std::exception | 该异常是所有标准 C++ 异常的父类。 |
std::bad_alloc | 该异常可以通过 new 抛出。 |
std::bad_cast | 该异常可以通过 dynamic_cast 抛出。 |
std::bad_exception | 这在处理 C++ 程序中无法预期的异常时非常有用。 |
std::bad_typeid | 该异常可以通过 typeid 抛出。 |
std::logic_error | 理论上可以通过读取代码来检测到的异常。 |
std::domain_error | 当使用了一个无效的数学域时,会抛出该异常。 |
std::invalid_argument | 当使用了无效的参数时,会抛出该异常。 |
std::length_error | 当创建了太长的 std::string 时,会抛出该异常。 |
std::out_of_range | 该异常可以通过方法抛出,例如 std::vector 和 std::bitset<>::operator[]()。 |
std::runtime_error | 理论上不可以通过读取代码来检测到的异常。 |
std::overflow_error | 当发生数学上溢时,会抛出该异常。 |
std::range_error | 当尝试存储超出范围的值时,会抛出该异常。 |
std::underflow_error | 当发生数学下溢时,会抛出该异常。 |
C++ 的动态内存
C++ 程序中的内存分为两个部分:
-栈:在函数内部声明的所有变量都将占用栈内存。
-堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。如果您不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
malloc() 函数在 C 语言中就出现了,在 C++ 中仍然存在,但建议尽量不要使用 malloc() 函数。new 与 malloc() 函数相比,其主要的优点是,new 不只是分配了内存,它还创建了对象。
C++ 的信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序。
信号 | 描述 |
SIGABRT | 程序的异常终止,如调用 abort。 |
SIGFPE | 错误的算术运算,比如除以零或导致溢出的操作。 |
SIGILL | 检测非法指令。 |
SIGINT | 程序终止(interrupt)信号。 |
SIGSEGV | 非法访问内存。 |
SIGTERM | 发送到程序的终止请求。 |
C++ 的多线程
多线程是多任务处理的一种特殊形式,多任务处理允许让电脑同时运行两个或两个以上的程序。一般情况下,两种类型的多任务处理:基于进程和基于线程。
基于进程的多任务处理是程序的并发执行。
基于线程的多任务处理是同一程序的片段的并发执行。
多线程程序包含可以同时运行的两个或多个部分。这样的程序中的每个部分称为一个线程,每个线程定义了一个单独的执行路径。
创建线程
下面的程序,我们可以用它来创建一个POSIX 线程:
#include <pthread.h>
pthread_create (thread, attr, start_routine,arg)
在这里,pthread_create 创建一个新的线程,并让它可执行。下面是关于参数的说明:
参数 | 描述 |
thread | 指向线程标识符指针。 |
attr | 一个不透明的属性对象,可以被用来设置线程属性。您可以指定线程属性对象,也可以使用默认值 NULL。 |
start_routine | 线程运行函数起始地址,一旦线程被创建就会执行。 |
arg | 运行函数的参数。它必须通过把引用作为指针强制转换为 void 类型进行传递。如果没有传递参数,则使用 NULL。 |
创建线程成功时,函数返回 0,若返回值不为 0 则说明创建线程失败。
终止线程
使用下面的程序,我们可以用它来终止一个POSIX 线程:
#include <pthread.h>
pthread_exit (status)
在这里,pthread_exit 用于显式地退出一个线程。通常情况下,pthread_exit() 函数是在线程完成工作后无需继续存在时被调用。
如果 main() 是在它所创建的线程之前结束,并通过 pthread_exit() 退出,那么其他线程将继续执行。否则,它们将在 main() 结束时自动被终止。
C++ 的Web编程
公共网关接口(CGI),是使得应用程序(称为 CGI 程序或 CGI 脚本)能够与 Web 服务器以及客户端进行交互的标准协议。
CGI 的架构:
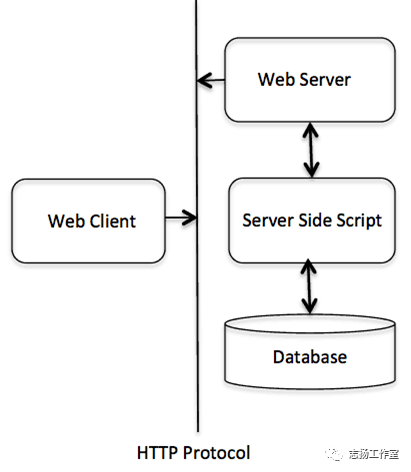
Web 服务器配置
在您进行 CGI 编程之前,请确保您的 Web 服务器支持 CGI,并已配置成可以处理 CGI 程序。所有由 HTTP服务器执行的 CGI 程序,都必须在预配置的目录中。该目录称为 CGI 目录,按照惯例命名为 /var/www/cgi-bin。虽然 CGI 文件是 C++ 可执行文件,但是按照惯例它的扩展名是 .cgi。
HTTP 头信息
行 Content-type:text/html\r\n\r\n 是 HTTP 头信息的组成部分,它被发送到浏览器,以便更好地理解页面内容。HTTP 头信息的形式如下:
HTTP 字段名称: 字段内容
例如
Content-type: text/html\r\n\r\n
还有一些其他的重要的 HTTP 头信息,这些在您的 CGI 编程中都会经常被用到。
头信息 | 描述 |
Content-type: | MIME 字符串,定义返回的文件格式。例如 Content-type:text/html。 |
Expires: Date | 信息变成无效的日期。浏览器使用它来判断一个页面何时需要刷新。一个有效的日期字符串的格式应为 01 Jan 1998 12:00:00 GMT。 |
Location: URL | 这个 URL 是指应该返回的 URL,而不是请求的 URL。你可以使用它来重定向一个请求到任意的文件。 |
Last-modified: Date | 资源的最后修改日期。 |
Content-length: N | 要返回的数据的长度,以字节为单位。浏览器使用这个值来表示一个文件的预计下载时间。 |
Set-Cookie: String | 通过 string 设置 cookie。 |
CGI 环境变量
所有的 CGI 程序都可以访问下列的环境变量。这些变量在编写 CGI 程序时扮演了非常重要的角色。
变量名 | 描述 |
CONTENT_TYPE | 内容的数据类型。当客户端向服务器发送附加内容时使用。例如,文件上传等功能。 |
CONTENT_LENGTH | 查询的信息长度。只对 POST 请求可用。 |
HTTP_COOKIE | 以键 & 值对的形式返回设置的 cookies。 |
HTTP_USER_AGENT | 用户代理请求标头字段,递交用户发起请求的有关信息,包含了浏览器的名称、版本和其他平台性的附加信息。 |
PATH_INFO | CGI 脚本的路径。 |
QUERY_STRING | 通过 GET 方法发送请求时的 URL 编码信息,包含 URL 中问号后面的参数。 |
REMOTE_ADDR | 发出请求的远程主机的 IP 地址。这在日志记录和认证时是非常有用的。 |
REMOTE_HOST | 发出请求的主机的完全限定名称。如果此信息不可用,则可以用 REMOTE_ADDR 来获取 IP 地址。 |
REQUEST_METHOD | 用于发出请求的方法。最常见的方法是 GET 和 POST。 |
SCRIPT_FILENAME | CGI 脚本的完整路径。 |
SCRIPT_NAME | CGI 脚本的名称。 |
SERVER_NAME | 服务器的主机名或 IP 地址。 |
SERVER_SOFTWARE | 服务器上运行的软件的名称和版本。 |
在 CGI 中使用 Cookies
HTTP 协议是一种无状态的协议。但对于一个商业网站,它需要在不同页面间保持会话信息。例如,一个用户在完成多个页面的步骤之后结束注册。但是,如何在所有网页中保持用户的会话信息。
在许多情况下,使用 cookies 是记忆和跟踪有关用户喜好、购买、佣金以及其他为追求更好的游客体验或网站统计所需信息的最有效的方法。
它是如何工作的
服务器以 cookie 的形式向访客的浏览器发送一些数据。如果浏览器接受了 cookie,则 cookie 会以纯文本记录的形式存储在访客的硬盘上。现在,当访客访问网站上的另一个页面时,会检索 cookie。一旦找到 cookie,服务器就知道存储了什么。
cookie 是一种纯文本的数据记录,带有 5 个可变长度的字段:
Expires : cookie 的过期日期。如果此字段留空,cookie 会在访客退出浏览器时过期。
Domain : 网站的域名。
Path : 设置 cookie 的目录或网页的路径。如果您想从任意的目录或网页检索 cookie,此字段可以留空。
Secure : 如果此字段包含单词 "secure",那么 cookie 只能通过安全服务器进行检索。如果此字段留空,则不存在该限制。
Name=Value : cookie 以键值对的形式被设置和获取。
设置 Cookies
向浏览器发送 cookies 是非常简单的。这些 cookies 会在 Content-type 字段之前,与 HTTP 头一起被发送。假设您想设置 UserID 和 Password 为 cookies
C++的编译规则:
-结束符
在 C++ 中,分号是语句结束符。也就是说,每个语句必须以分号结束。它表明一个逻辑实体的结束。
-空白符
在 C++ 中,空格用于描述空白符、制表符、换行符和注释。空格分隔语句的各个部分,让编译器能识别语句中的某个元素(比如 int)在哪里结束,下一个元素在哪里开始。
-变量类型
变量的类型大小会根据编译器和所使用的电脑而有所不同。
-变量定义
变量其实只不过是程序可操作的存储区的名称。C++ 中每个变量都有指定的类型,类型决定了变量存储的大小和布局,该范围内的值都可以存储在内存中,运算符可应用于变量上。
-变量声明
变量声明向编译器保证变量以给定的类型和名称存在,这样编译器在不需要知道变量完整细节的情况下也能继续进一步的编译。变量声明只在编译时有它的意义,在程序连接时编译器需要实际的变量声明。当您使用多个文件且只在其中一个文件中定义变量时(定义变量的文件在程序连接时是可用的),变量声明就显得非常有用。您可以使用 extern 关键字在任何地方声明一个变量。
-左值与右值
C++ 中有两种类型的表达式:
-左值(lvalue):指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
-右值(rvalue):术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
变量是左值,因此可以出现在赋值号的左边。数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。
-变量作用域
在函数或一个代码块内部声明的变量,称为局部变量。
在函数参数的定义中声明的变量,称为形式参数。
在所有函数外部声明的变量,称为全局变量。
-变量初始化
当局部变量被定义时,系统不会对其初始化,您必须自行对其初始化。定义全局变量时,系统会自动初始化为默认值
-运算符
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。
-在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。这种运算符即 new 运算符。如果您不再需要动态分配的内存空间,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
-命名空间,可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
C++的相关术语:
-gcc & g++
Linux上的gcc是Gnu的C语言编译器,至于C++编译器,它的名字叫做g++。
-ram
随机存取存储器RAM也叫主存,是与CPU直接交换数据的内部存储器。
-cgi
公共网关接口(CGI),是一套标准,定义了信息是如何在 Web 服务器和客户端脚本之间进行交换的。
参考资料:
C++ 教程 | 菜鸟教程 (runoob.com)
https://www.runoob.com/cplusplus/cpp-tutorial.html
公众号二维码
End:如果有兴趣了解量化交易、数据分析和互联网+的实用技术,欢迎关注本公众号