
主要用到requests和bf4两个库将获得的信息保存在d://hotsearch.txt下importrequests;importbs4mylist=[]r=requests.get(ur...
主要用到requests和bf4两个库
将获得的信息保存在d://hotsearch.txt下
import requests;
import bs4
mylist=[]
r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10)
print(r.status_code) # 获取返回状态
r.encoding=r.apparent_encoding
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser")
for link in soup.find('tbody') :
hotnumber=''
if isinstance(link,bs4.element.Tag):
# print(link('td'))
lis=link('td')
hotrank=lis[1]('a')[0].string#热搜排名
hotname=lis[1].find('span')#热搜名称
if isinstance(hotname,bs4.element.Tag):
hotnumber=hotname.string#热搜指数
pass
mylist.append([lis[0].string,hotrank,hotnumber,lis[2].string])
f=open("d://hotsearch.txt","w+")
for line in mylist:
f.write('%s %s %s %s\n'%(line[0],line[1],line[2],line[3]))
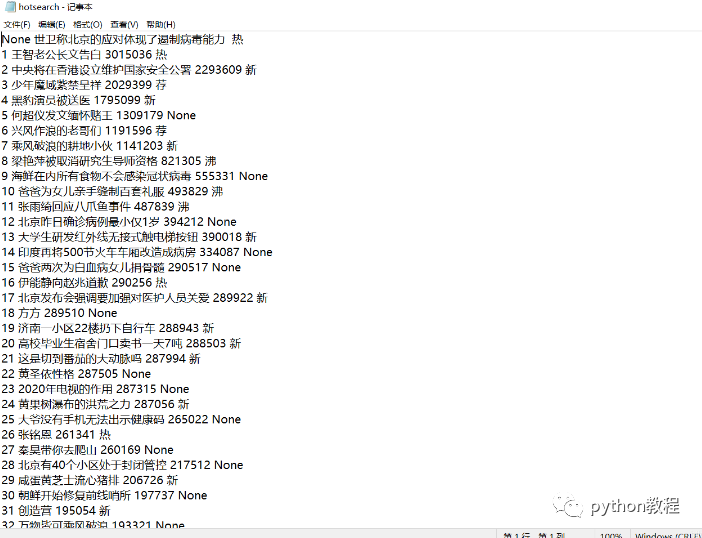
知识点扩展:利用python爬取微博热搜并进行数据分析
爬取微博热搜
import schedule
import pandas as pd
from datetime import datetime
import requests
from bs4 import BeautifulSoup
url = "https://s.weibo.com/top/summary?cate=realtimehot&sudaref=s.weibo.com&display=0&retcode=6102"
get_info_dict = {}
count = 0
def main():
global url, get_info_dict, count
get_info_list = []
print("正在爬取数据~~~")
html = requests.get(url).text
soup = BeautifulSoup(html, 'lxml')
for tr in soup.find_all(name='tr', class_=''):
get_info = get_info_dict.copy()
get_info['title'] = tr.find(class_='td-02').find(name='a').text
try:
get_info['num'] = eval(tr.find(class_='td-02').find(name='span').text)
except AttributeError:
get_info['num'] = None
get_info['time'] = datetime.now().strftime("%Y/%m/%d %H:%M")
get_info_list.append(get_info)
get_info_list = get_info_list[1:16]
df = pd.DataFrame(get_info_list)
if count == 0:
df.to_csv('datas.csv', mode='a+', index=False, encoding='gbk')
count += 1
else:
df.to_csv('datas.csv', mode='a+', index=False, header=False, encoding='gbk')
# 定时爬虫
schedule.every(1).minutes.do(main)
while True:
schedule.run_pending()
pyecharts数据分析
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline, Grid
from pyecharts.globals import ThemeType, CurrentConfig
df = pd.read_csv('datas.csv', encoding='gbk')
print(df)
t = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) # 定制主题
for i in range(int(df.shape[0]/15)):
bar = (
Bar()
.add_xaxis(list(df['title'][i*15: i*15+15][::-1])) # x轴数据
.add_yaxis('num', list(df['num'][i*15: i*15+15][::-1])) # y轴数据
.reversal_axis() # 翻转
.set_global_opts( # 全局配置项
title_opts=opts.TitleOpts( # 标题配置项
title=f"{list(df['time'])[i * 15]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#FF1493'
)
),
xaxis_opts=opts.AxisOpts( # x轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
),
yaxis_opts=opts.AxisOpts( # y轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#DC143C')
)
)
.set_series_opts( # 系列配置项
label_opts=opts.LabelOpts( # 标签配置
position="right", color='#9400D3')
)
)
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_left="24%"))
)
t.add(grid, "")
t.add_schema(
play_interval=1000, # 轮播速度
is_timeline_show=False, # 是否显示 timeline 组件
is_auto_play=True, # 是否自动播放
)
t.render('时间轮播图.html')
到此这篇关于如何用python爬取微博热搜数据并保存的文章就介绍到这了!
扫下方二维码加老师微信
或是搜索老师微信号:XTUOL1988【切记备注:学习Python】
领取Python web开发,Python爬虫,Python数据分析,人工智能等学习教程。带你从零基础系统性的学好Python!
也可以加老师建的Python技术学习教程qq裙:245345507,二者加一个就可以!
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
万水千山总是情,点个【在看】行不行
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜

