
工程Tricks | PyTorch有什么节省显存的小技巧?
来源 | 知乎问答
地址 | https://www.zhihu.com/question/274635237
本文仅作学术分享,若侵权请联系后台删文处理
回答一:作者-朱小霖
节省显存方面,欢迎关注我们团队最近开源的工作:https://github.com/Tencent/PatrickStar
个人认为这个工作把单卡训练,或者是数据并行下的显存节省做到极致了~
这里主要介绍一下单机训练上的思路。
随着模型越来越大,GPU 逐渐从一个计算单元变成一个存储单元了,显存的大小限制了能够训练的模型大小。微软的 DeepSpeed 团队提出我们其实可以把优化器状态(Adam 的 momentum 和 variance)放在 CPU 上,用一个实现的比较快的 CPU Adam 来做更新,这样既不会变慢很多,也可以明显省出来很多空间。我们把这个思想再往前推一步,我们是不是可以只把需要计算的模型参数放在 GPU 上,其余的模型参数,优化器状态都放在 CPU 上,这样就可以尽最大能力降低对显存的需求,让 GPU 回归它计算单元的本色。
为了达成这样的效果,我们就需要一个动态的显存调度——相对于 DeepSpeed 在训练前就规定好哪些放在 CPU 上,哪些放在 GPU 上,我们需要在训练过程中实时把下一步需要的模型参数拿到 GPU 上来。利用 pytorch 的 module hook 可以让我们在每个 nn.Module 前后调用回调函数,从而动态把参数从 CPU 拿到 GPU,或者放回去。
但是,相信大家能够想象到,如果每次都运行到一个 submodule 前,再现把参数传上来,肯定就很慢,因为计算得等着 CPU-GPU 的传输。为了解决计算效率的问题,我们提出了 chunk-based management。这是什么意思呢?就是我们把参数按照调用的顺序存储在了固定大小的 chunk 里(一般是 64M 左右),让内存/显存的调度以 chunk 为单位,第一次想把某个 chunk 中的参数放到 GPU 来的时候,就会直接把整个 chunk 搬到 GPU,这意味着虽然这一次的传输可能需要等待,但是在计算下一个 submodule 的时候,因为连着的 module 的参数都是存在一个 chunk 里的,这些参数已经被传到 GPU 上来了,从而实现了 prefetch,明显提升了计算效率。同时,因为 torch 的 allocator 会缓存之前分配的显存,固定大小的 chunk 可以更高效利用这一机制,提升显存利用效率。
在 chunk 的帮助下,我们的模型可以做到,CPU 内存加 GPU 显存有多大,模型就能训多大。和 DeepSpeed 相比,在同等环境下模型规模可以提升 50%,计算效率(Tflops)也更高。
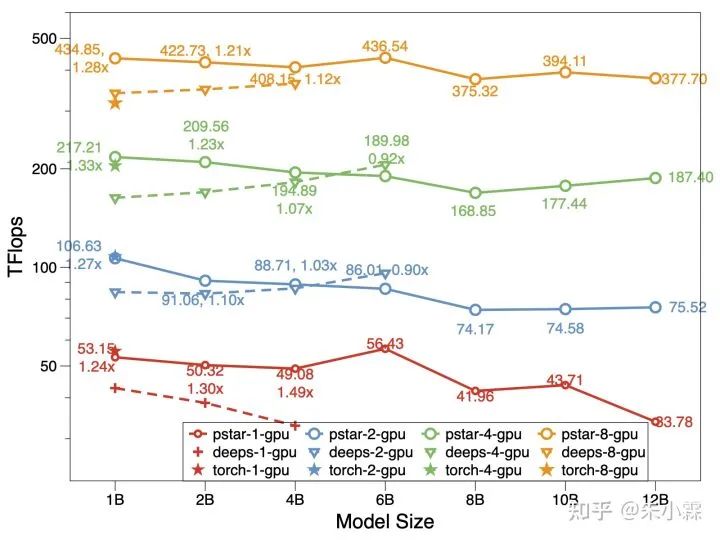 对于多卡的数据并行场景,我们扩展了上述方法,可以做到多卡中只有 1 整份模型,1 整份优化器状态,同时具备了数据并行的易用性和模型并行的显存使用效率。如果想了解多卡训练的方案,以及更详细的一些优化,也欢迎来看看我们的论文:https://arxiv.org/abs/2108.05818
对于多卡的数据并行场景,我们扩展了上述方法,可以做到多卡中只有 1 整份模型,1 整份优化器状态,同时具备了数据并行的易用性和模型并行的显存使用效率。如果想了解多卡训练的方案,以及更详细的一些优化,也欢迎来看看我们的论文:https://arxiv.org/abs/2108.05818
回答二:作者-郑哲东
在不修改网络结构的情况下, 有如下操作:
1.同意@Jiaming, 尽可能使用inplace操作, 比如relu 可以使用 inplace=True 。一个简单的使用方法,如下:
def inplace_relu(m):
classname = m.__class__.__name__
if classname.find('ReLU') != -1:
m.inplace=True
model.apply(inplace_relu)
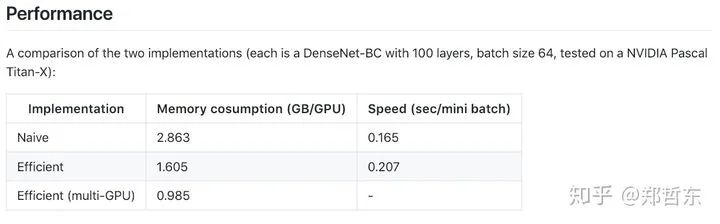
2.进一步,比如ResNet 和 DenseNet 可以将 batchnorm 和relu打包成inplace,在bp时再重新计算。使用到了pytorch新的checkpoint特性,有以下两个代码。由于需要重新计算bn后的结果,所以会慢一些。
https://github.com/gpleiss/efficient_densenet_pytorch
https://github.com/mapillary/inplace_abn
3. 每次循环结束时 删除 loss,可以节约很少显存,但聊胜于无。可见如下issue
https://discuss.pytorch.org/t/tensor-to-variable-and-memory-freeing-best-practices/6000/2
4. 使用float16精度混合计算。我用过NVIDIA的apex,很好用,可以节约将近50%的显存,但是要小心一些不安全的操作如 mean和sum,溢出fp16。
https://github.com/NVIDIA/apex

补充:最近我也尝试在我CVPR19的GAN模型中加入fp16的训练,可以从15G的显存需求降到约10G,这样大多数1080Ti等较为常见的显卡就可以训练了。欢迎大家star一波 https://github.com/NVlabs/DG-Net
5. 对于不需要bp的forward,如validation 请使用 torch.no_grad , 注意model.eval() 不等于 torch.no_grad() 请看如下讨论。
https://discuss.pytorch.org/t/model-eval-vs-with-torch-no-grad/19615
6. torch.cuda.empty_cache() 这是del的进阶版,使用nvidia-smi 会发现显存有明显的变化。但是训练时最大的显存占用似乎没变。大家可以试试。
https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530
另外,会影响精度的骚操作还有:
把一个batchsize=64分为两个32的batch,两次forward以后,backward一次。但会影响 batchnorm等和batchsize相关的层。
相关链接:老外写的提高pytorch效率的方法,包含data prefetch等
https://sagivtech.com/2017/09/19/optimizing-pytorch-training-code/
03回答三:作者-Lyken
咦,大家都没看过陈天奇的 Training Deep Nets with Sublinear Memory Cost 吗?
训练 CNN 时,Memory 主要的开销来自于储存用于计算 backward 的 activation,一般的 workflow 是这样的
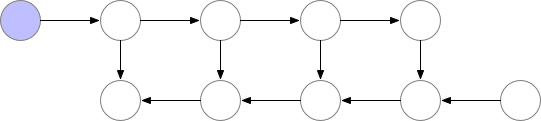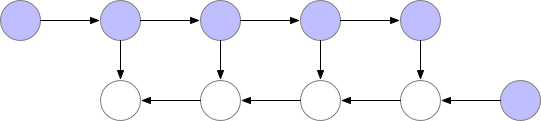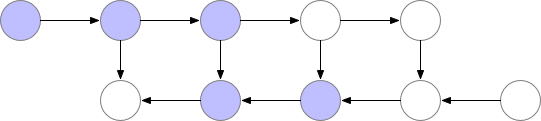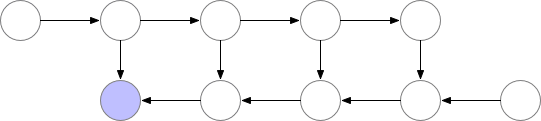
Vanilla backprop
对于一个长度为 N 的 CNN,需要 O(N) 的内存。这篇论文给出了一个思路,每隔 sqrt(N) 个 node 存一个 activation,中需要的时候再算,这样显存就从 O(N) 降到了 O(sqrt(N))。
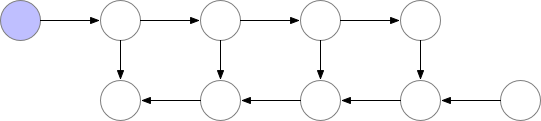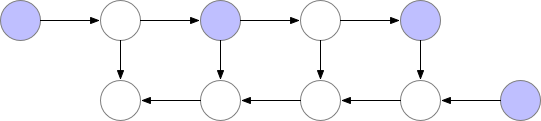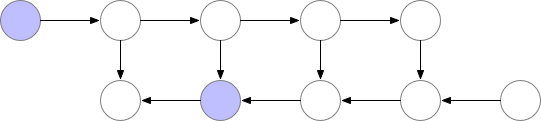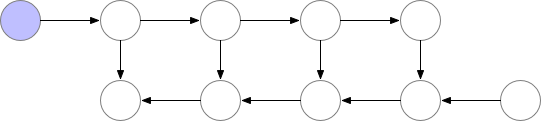
Checkpointed backprop
对于越深的模型,这个方法省的显存就越多,且速度不会明显变慢。
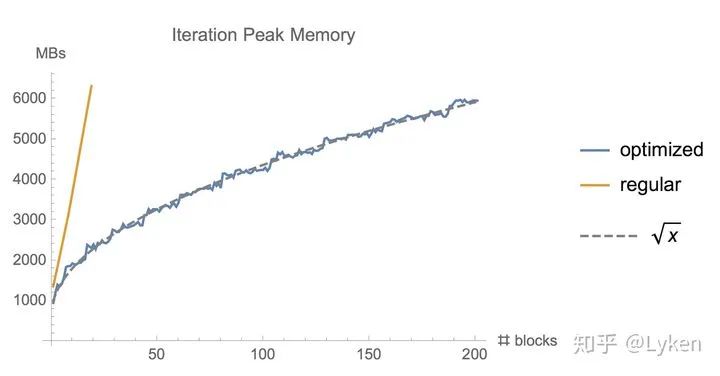
PyTorch 我实现了一版,有兴趣的同学可以来试试 https://github.com/Lyken17/pytorch-memonger
往期精彩: