
【Python私活案例】500元,提供exe实现批量excel文件的存入mysql数据库
下午的时候我正无聊的刷着手机,就听叮咚一声,我就顺便看了一眼,好家伙是老师在发赚钱的单子,我再一看,这不是我刚刚学过去的知识吗,二话不说立马就开启了‘抢单’模式。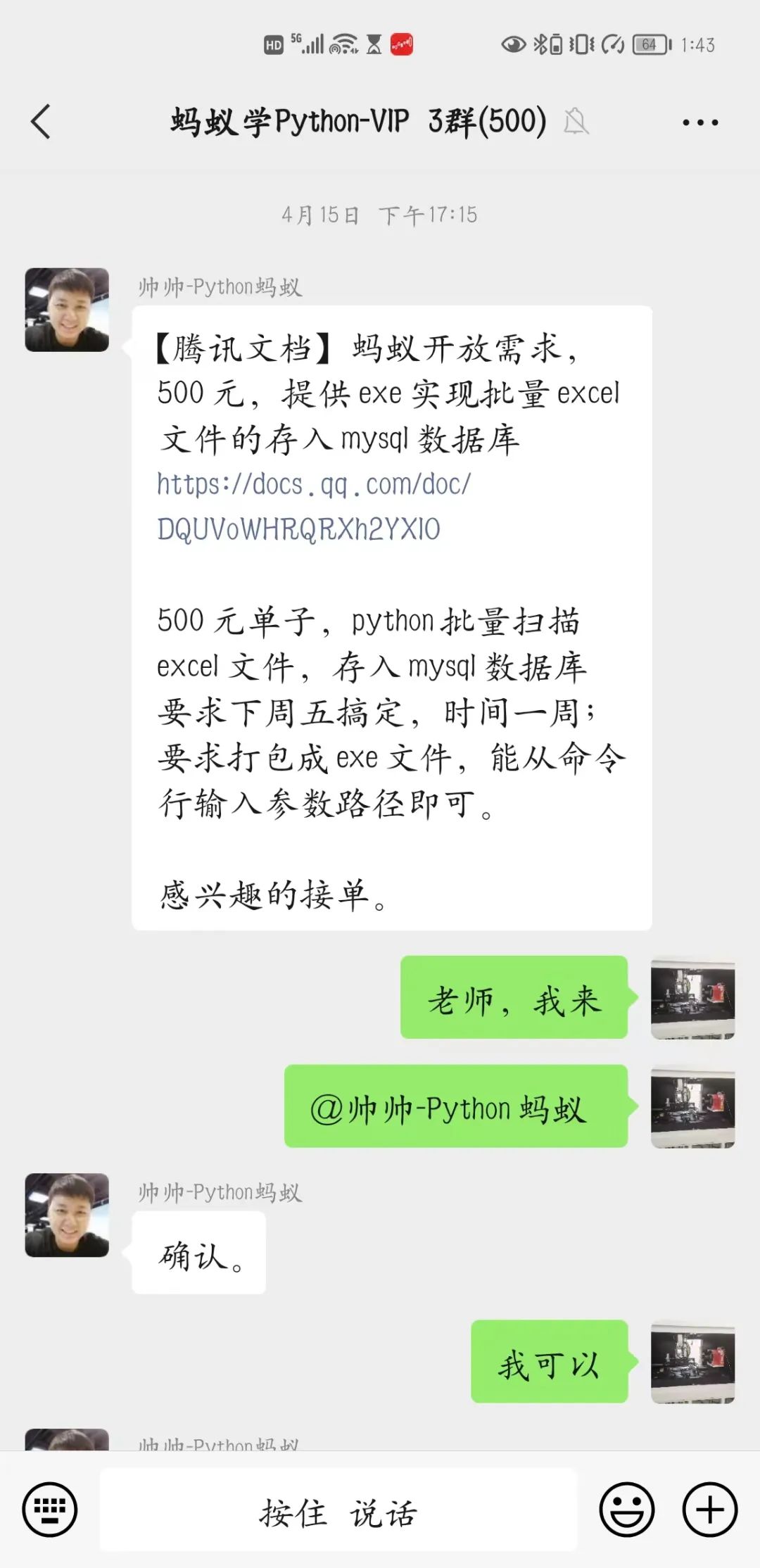 感谢老师让我得到了批量将excel文件存入mysql数据库的单子,本来以为很简单的单子,但是遇到几个我忽略的问题,让我着实头疼了一番,看来还是要多学习才行。
感谢老师让我得到了批量将excel文件存入mysql数据库的单子,本来以为很简单的单子,但是遇到几个我忽略的问题,让我着实头疼了一番,看来还是要多学习才行。
【业务需求】
打开exe后,弹出一个exe命令行窗口,输入路径,执行递归扫描很多个excel文件,存入mysql数据库
【代码实现分析】
需求分析:
需要批量读取excel; 需要存入mysql; 需要将py文件打包为exe
看起来就是如此简单 不过经过进一步沟通才知道:
是有很多excel文件存在不同级别的文件夹里,每个excel里面又有很多的表数据,幸好表的格式基本相同。 批量读取excel表内容,并简单处理用pandas更加的方便一点,果断选择pandas,不过to_sql命令我比较陌生,又去学习了一番; 打包工具,也比较简单pyinstaller,网上教程一大堆,没啥可说的。
【代码实现】
首先我想到的是编一个函数,来找到目录内所有的excel相关文件的位置,这里我用的是pathlib2的Path下的rglob函数,直接可以选出目录内包含子文件夹下的所有符合条件的文件(这里要感谢船长的提醒,让我少走了好多的弯路,不然我铁定要用循环遍历的。。。。)
#得到目录里面所有的excel文件和csv文件
def get_path():
while True:
path = input("请输入需要查找的目录:")
if Path(path).exists():
break
else:
print('您输入的目录不存在,请检查!!!!')
print('正在查找中。。。。')
return Path(path).rglob('**/*.xls*'), Path(path).rglob('**/*.csv')
其次就是根据得到的文件路径用pandas来读取,由于一个excel文件有很多表,所以我是这么写的,你发现什么问题了吗?
def readAllFiles():
excel_file_list,csv_file_list = get_path()
print('查找完成,数据整理中.....')
for file_e in excel_file_list:
df = pd.read_excel(file_e, sheet_name=None)
for sheet_name in df.keys():
df_1 = pd.read_excel(file_e,sheet_name=sheet_name,nrows=1)
df_2 = pd.read_excel(file_e,sheet_name=sheet_name,header=2)
wash_data(df_1,df_2)
需要处理的表如下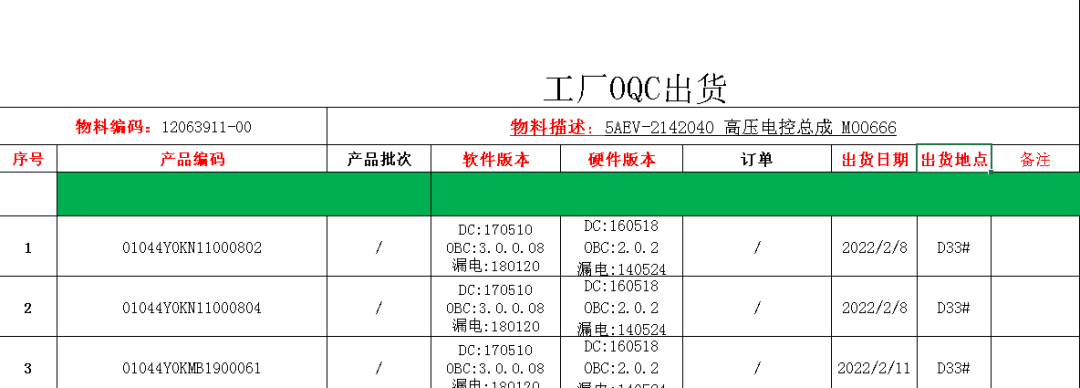
因为我要得到红色字对应的信息,所以我用了2个pd.read_excel()来实现各自的目的,实现以后程序运行竟然很慢很慢,想了很多方法———多线程,更改处理数据方式都没有让程序快起来,为什么这么慢呢?WHY??
在我百思不得要领的时候突然看到了pandas读取,脑中灵光一现,原来就是这么简单。你想到了吗?对的,就是pandas读取数据非常慢,而我竟然让它读了3遍——罪过罪过。然后我就改成了这样:
excel_file_list,csv_file_list = get_path()
print('查找完成,数据整理中.....')
for file_e in excel_file_list:
try:
df = pd.read_excel(file_e, sheet_name=None)
for sheet_name in df.keys():
df_1 = df[sheet_name].loc[0:0,:]
df_2 = df[sheet_name].iloc[2:,:-1]
df_e = wash_data(df_1,df_2)
当改成用pandas只读取一次后,程序飞了起来,我也飞了起来——哈哈哈哈哈哈哈哈——此处允许我疯一下!
剩下的数据处理,添加列,对列排队,存入数据库等等都是小意思。直接看代码吧!
#获取物料编码和物料描述
def get_wlbm_wlms(s_list):
wlbm = s_list[0].split(':')[-1].strip()
wlms = s_list[1] if '物料描述' not in s_list[1] else s_list[1].replace('(物料描述)','')
return wlbm,wlms
#数据清洗和排列
def wash_data(df_1,df_2):
df_1.dropna(axis=1, how='all', inplace=True)
list_s = df_1.loc[0].values
wlbm, wlms = get_wlbm_wlms(list_s)
if not df_2.empty:
df_2.columns = ['序号', '条码', '产品批次', '软件版本', '硬件版本', '订单', '出货日期', '出货地点', '备注']
# 删除没有用的列
df_2.dropna(axis=0,how='all',inplace=True)
df_2.drop(columns=['产品批次', '订单'], inplace=True)
df_2 = df_2.replace('/',np.NaN)
df_2['物料编码'] = wlbm
df_2['产品名称'] = wlms
df = df_2[['序号', '条码', '出货日期', '产品名称', '出货地点', '物料编码', '软件版本', '硬件版本', '备注']]
else:
data = [[np.NaN, np.NaN, np.NaN, wlms, np.NaN, wlbm, np.NaN, np.NaN, np.NaN]]
df = pd.DataFrame(data,columns=['序号', '条码', '出货日期', '产品名称', '出货地点', '物料编码', '软件版本', '硬件版本', '备注'])
return df
def get_sheet_data(sheet_name,df):
df_1 = df[sheet_name].loc[0:0,:]
df_2 = df[sheet_name].iloc[2:,:-1]
df_e = wash_data(df_1,df_2)
# print(df_e)
df_e.to_sql(sql_info['TABLE_NAME'], chunksize=10000,con=engine, if_exists='append', index=False,dtype=DATA_TYPE)
当然这里有一个细节被我忽略了,在调试的时候才发现,就是warning,看图: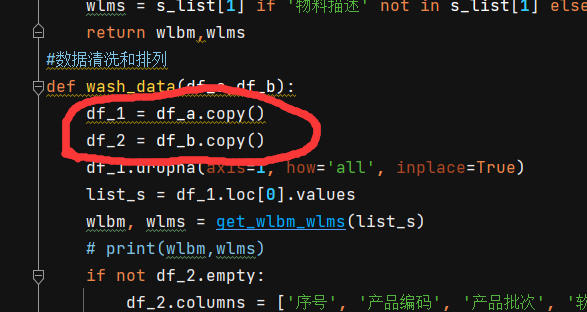 就是这里,记得一定要用copy()一下,不然你就会看到warning,想看的可以试试!!
就是这里,记得一定要用copy()一下,不然你就会看到warning,想看的可以试试!!
虽然我感觉数据清洗和处理是比较简单的,但是实际上也花了我一些的时间,由于pandas才刚刚开始学,有些东西真的是边学边写,幸好老师有很多东西都已经给出了例子,照着来一遍就可以实现效果。这个要大大的感谢一下老师,老师的视频做的实在是太详细了!!
我虽然在我的电脑上数据库用的没有任何问题,但是到了客户那边就出了各种问题,说实话我真的对数据库了解的不多,只能是有问题搜一下,根据自己的理解在自己的电脑上试一下。感慨一下,数据库真的是一个细心的功夫活!!总的来说还是解决了~~
最后就是增加了一些记录,防错,防重复的一些小功能,至少要让客户用起来舒服,客户可是上帝!!
另外多说一下,存到数据库时,一定要一一对应,类型格式也不能错,不然就是存不进去,让我白白浪费了一天时间才找到问题。感谢大家的阅读!
最后附上全部的代码:
import os
import numpy as np
import pandas as pd
from pathlib2 import Path
import pymysql
from sqlalchemy import create_engine
from sqlalchemy.types import DATE,INT,VARCHAR
DATA_TYPE = {'序号':INT,'条码':VARCHAR(255),'出货日期':DATE,'产品名称':VARCHAR(255), '出货地点':VARCHAR(255), '物料编码':VARCHAR(255), '软件版本':VARCHAR(255), '硬件版本':VARCHAR(255), '备注':VARCHAR(255)}
pymysql.install_as_MySQLdb()
#读取配置文件
def get_sql_info():
sql_dict = {}
with open('mysql_info.txt','r')as f:
f_r_l = f.readlines()
for f_r in f_r_l:
sql_dict[f_r.split(':')[0].strip()] = f_r.split(':')[1].strip()
return sql_dict
sql_info = get_sql_info()
DB_STRING = f"mysql+mysqldb://{sql_info['USER']}:{sql_info['PASSWORD']}@{sql_info['HOST']}/{sql_info['db_name']}?charset=utf8"
engine = create_engine(DB_STRING)
def clean_txt(path):
with open(path, 'w', encoding='utf-8') as f:
f.truncate()
#读取已经完成的sheet
def read_txt(path):
if not os.path.exists(path):
clean_txt(path)
return
with open(path,'r',encoding='utf-8')as f:
sheetnames = f.readlines()
return [i.strip() for i in sheetnames]
def write_txt(path,s):
with open(path,'a',encoding='utf-8')as f:
f.write(s+'\n')
#得到目录里面所有的excel文件和csv文件
def get_path():
while True:
path = input("请输入需要查找的目录:")
print(path)
if Path(path).exists():
break
else:
print('您输入的目录不存在,请检查!!!!')
print('正在查找中。。。。')
return Path(path).rglob('**/*.xls*'), Path(path).rglob('**/*.csv')
#获取物料编码和物料描述
def get_wlbm_wlms(s_list):
wlbm = s_list[0].split(':')[-1].strip()
wlms = s_list[1] if '物料描述' not in s_list[1] else s_list[1].replace('(物料描述)','')
return wlbm,wlms
#数据清洗和排列
def wash_data(df_a,df_b):
df_1 = df_a.copy()
df_2 = df_b.copy()
df_1.dropna(axis=1, how='all', inplace=True)
list_s = df_1.loc[0].values
wlbm, wlms = get_wlbm_wlms(list_s)
# print(wlbm,wlms)
if not df_2.empty:
df_2.columns = ['序号', '条码', '产品批次', '软件版本', '硬件版本', '订单', '出货日期', '出货地点', '备注']
# 删除没有用的列
df_2.dropna(axis=0,how='all',inplace=True)
df_2.drop(columns=['产品批次', '订单'], inplace=True)
df_2 = df_2.replace('/',np.NaN)
df_2['物料编码'] = wlbm
df_2['产品名称'] = wlms
df = df_2[['序号', '条码', '出货日期', '产品名称', '出货地点', '物料编码', '软件版本', '硬件版本', '备注']]
else:
data = [[np.NaN, np.NaN, np.NaN, wlms, np.NaN, wlbm, np.NaN, np.NaN, np.NaN]]
df = pd.DataFrame(data,columns=['序号', '条码', '出货日期', '产品名称', '出货地点', '物料编码', '软件版本', '硬件版本', '备注'])
return df
def get_sheet_data(sheet_name,df):
try:
df_1 = df[sheet_name].loc[0:0,:]
df_2 = df[sheet_name].iloc[2:,:-1]
df_e = wash_data(df_1,df_2)
# print(df_e)
df_e.to_sql(sql_info['TABLE_NAME'], chunksize=10000,con=engine, if_exists='append', index=False,dtype=DATA_TYPE)
except Exception as e:
print(e)
def readAllFiles():
excel_file_list,csv_file_list = get_path()
print('查找完成,数据整理中.....')
excel_names = read_txt(path_excel)
i = 0
for file_e in excel_file_list:
if file_e in excel_names:
continue
try:
df = pd.read_excel(file_e, sheet_name=None)
# print(sheets)
sheetnames = read_txt(path_sheet)
j = 1
for sheet_name in df.keys():
if sheet_name in sheetnames:
continue
get_sheet_data(sheet_name,df)
write_txt(path_sheet,sheet_name)
print(f'当前完成度{j}/{len(df.keys())}....')
j += 1
write_txt(path_excel,str(file_e))
clean_txt(path_sheet)
i += 1
print(f'已完成{i}个文件。。。。')
except Exception as e:
print(e)
for file_c in csv_file_list:
try:
df_c = pd.read_csv(file_c,encoding='gbk')
df_1 = df_c.loc[0:0, :]
df_2 = df_c.iloc[2:, :-1]
df_c = wash_data(df_1, df_2)
df_c.to_sql(sql_info['TABLE_NAME'], chunksize=10000, con=engine, if_exists='append', index=False,dtype=DATA_TYPE)
write_txt(path_excel, str(file_c))
i += 1
print(f'已完成{i}个文件。。。。')
except Exception as e:
print(e)
if __name__ == "__main__":
path_excel = 'excel_log.txt'
path_sheet = 'sheetlog.txt'
while True:
readAllFiles()
print('该目录已完成!')
clean_txt(path_excel)
input('继续就回车,不需要请直接关闭掉!')
蚂蚁老师的全栈套餐,在抖音扫码购买;有答疑服务、副业介绍等福利
