
轻松理解分库分表
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | aduner
来源 | urlify.cn/uUZBrm
前言
现代业务越来越复杂,数据量也越来越大,关系型数据库本身就比较容易形成系统瓶颈,单机存储容量,连接数,处理能力都有限。
当单表的数据量达到一定量级以后,比如1000万,由于查询维度较多,即使添加从库,优化索引,做很多操作时性能还是下降严重。
这个时候要如何提高数据的性能呢?
有人说,可以通过提升服务器硬件能力来提高数据处理能力,比如换更快的硬盘,换更强的CPU。
这种方案成本是很高的,并且瓶颈有时候往往不在硬件上,而在数据库本身。
基于这种现状,分表/分库就出现了!
什么是分别分库
分表分库是两种操作,一种是分表,一种是分库。
但是他们的中心思想都是将数据分散,使得单一数据库/表的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
例如,将某业务的数据库分为若干个独立的数据库,并且对于大表也拆分为若干小表,这样就很大程度上降低了并发数据查询时的数据冲突。
分表
垂直分表
定义:将一个表按照字段分为多表,每个表里面都存储其中一部分字段。
我们以商品表来举例子:
商品信息中,一般包括多条字段,如商品名、价格、简介……
而其中商品名和价格可能是最重要的,而简介就相对没有那么重要。
对比两者:
商品名和价格:字段很小,请求很频繁。
简介:字段很大,一般只有详情页才需要它。
大字段都如下几个坏处:
由于数据量本身大,需要更长的读取时间
跨页时,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数小,因此IO效率低
据库以行为单位将数据加载到内存中,表中字段越短,内存能加载的数据越多,命中率更高,减少了磁盘IO,从而提升了数据库性能。
因此简介这种低频数据,会拖累商品名和价格这种高频数据,这个时候,我们就可以将简介从表中拆分出来。
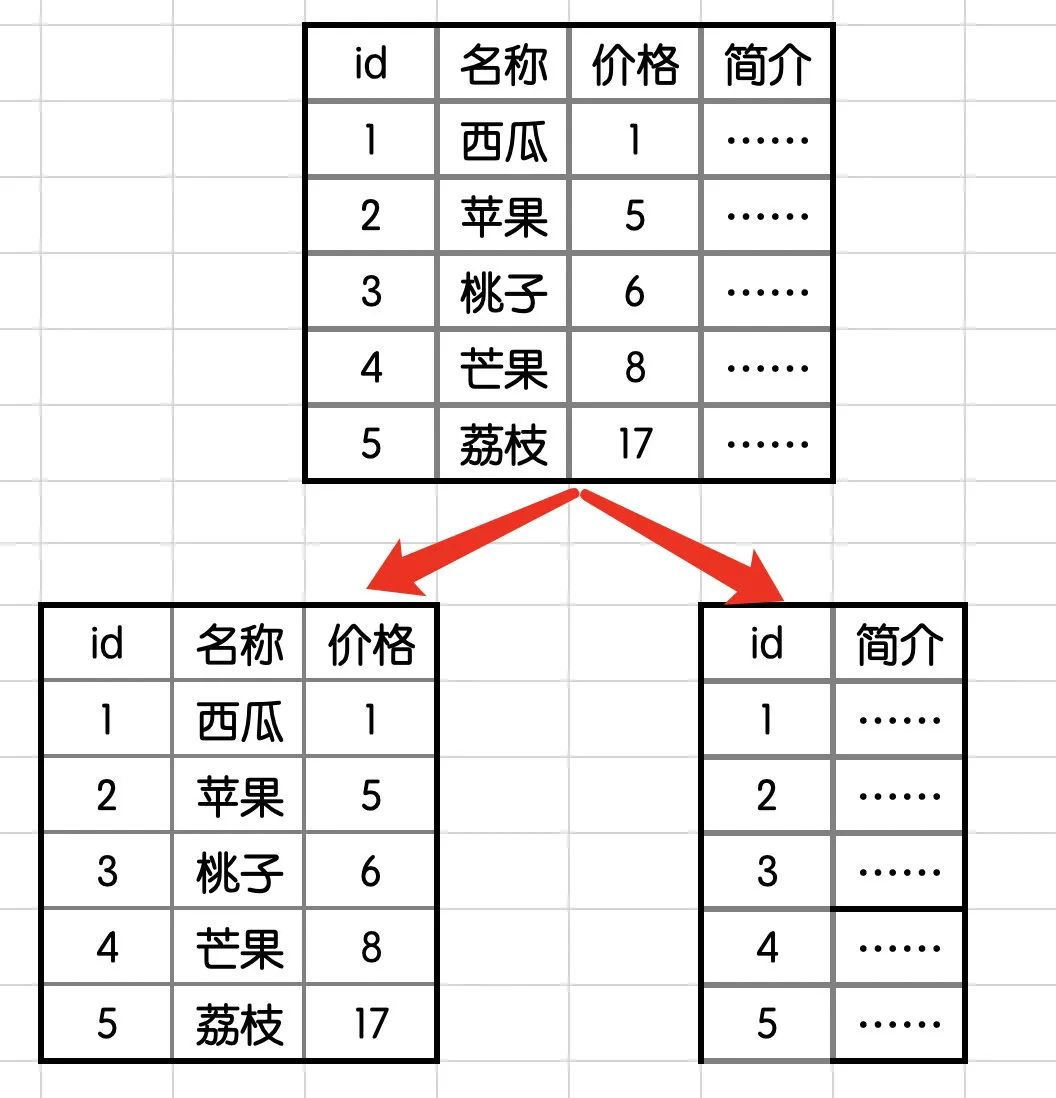
这样做的好处是:
查看详情的用户与商品信息浏览互不影响,避免了IO争抢并减少锁表的几率。
充分发挥高频数据(商品名和价格)的操作效率,商品名和价格的操作的高效率不会被商品简介的低效率所拖累。
水平分表
定义:同一个数据库内,对数据行拆分,不影响表结构。
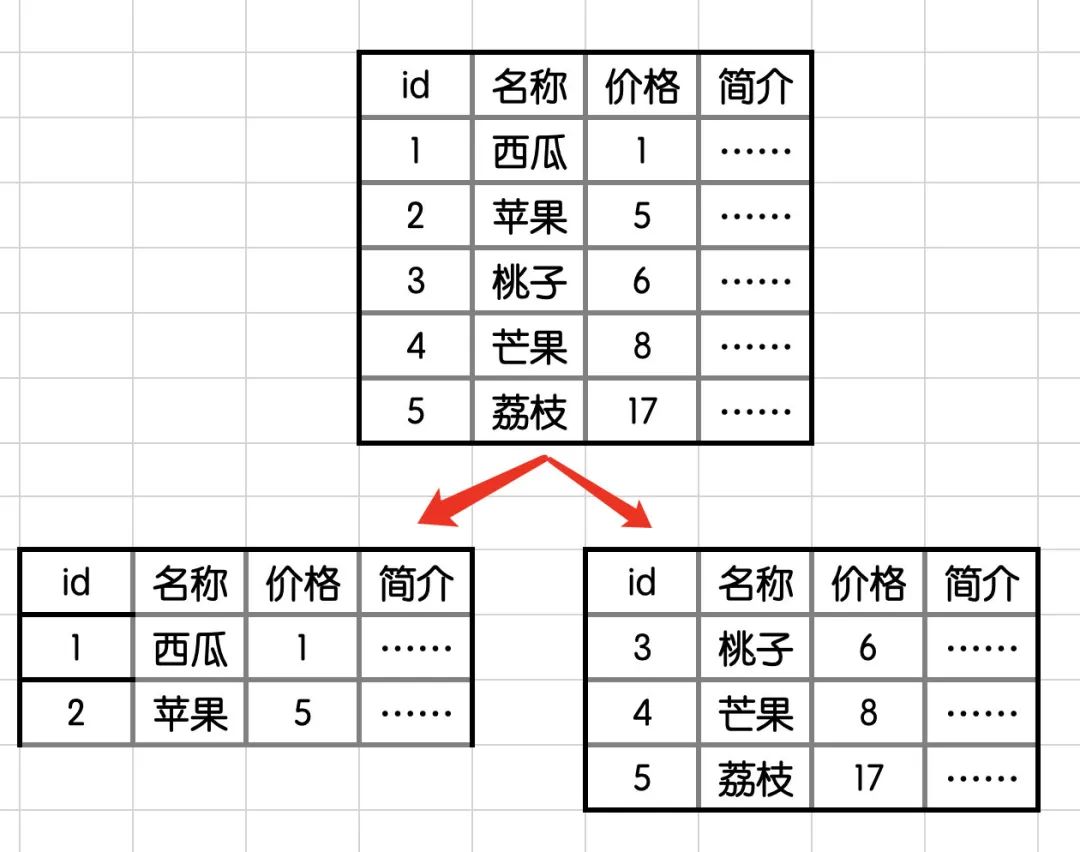
优点:
优化单一表数据量过大而产生的性能问题。
避免IO争抢而减少锁表的几率。
分库
虽然通过分表性能得到一定程度的提升,但是很多时候还无法达到预期效果。
因为数据库始终限制在一台服务器上,所以分表有如下几个局限性:
磁盘空间可能不够。
只解决了单一表数据量过大的问题。
每个表还是竞争同一个物理机的物理资源。
垂直分库
定义:专库专用,按照业务将表进行分类,分布在不同的数据库中,每个库可以放在不同的服务器上
例如,我们可以将购物车表、商品表、店铺表、买家表分在不同的服务器中。
优点:
解决业务层面的耦合,业务清晰
能对不同业务的数据进行分级管理、维护、监控、扩展等
高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
水平分库
随着业务的继续扩大,垂直分库也将在次面临单表过大的情况。
而已经经过了垂直分库,我们很难再进行进一步的垂直细分,这时候就要尝试水平分库了。
水平分库和水平分表十分相似,应该说就是水平分表是水平分库的一种延续。
定义:同一个表的数据按一定规则拆到不同的数据库中,库放在不同的服务器上。
优点:
解决了单库大数据,高并发的性能瓶颈
提高了系统的稳定性及可用性
分库分表的缺点
分页/排序
在同一张表时,只需要用limit、order by便可轻松搞定。
跨节点多库进行查询时,分页、排序,就变得很复杂。
先在不同的分片节点中将数据进行排序并返回
然后将不同分片返回的结果集进行汇总和再次排序
主键重复
分表分库会让平时经常使用的主键自增长形同虚设。生成的ID无法保证全局唯一。
因此我们需要单独设计全局主键,以便面跨库主键重复问题。
事务的一致性
因为分库分表把数据分布在不同的库、不同服务器,所以不可避免的带来分布式事务问题。
当一个请求要先请求数据库A,再请求数据库B,这两个属于同一个事务,多个库会导致分布式事务问题。
需要有一些措施来保证事务一致性的问题,这里不在展开,有兴趣自行了解。
关联查询
分库后,如果两个表不在同一个数据库,甚至不在同一台服务器上,无法进行关联查询。
解决方案:
将原关联查询分为两次查询
第一个查询的结果找出关联数据id
根据id发起第二次请求得到关联数据
最后将获得的数据进行拼装
总结
分库分表的诞生是为了解决数据库的性能瓶颈,虽然有很多好处,但相应的也有很多坏处。
但在业务量还不大的时候,我们其实应该首先考虑索引、缓存、读写分离等方案,盲目使用分表分库技术,会导致业务变得臃肿,反而徒增烦恼。
粉丝福利:Java从入门到入土学习路线图
👇👇👇

👆长按上方微信二维码 2 秒
感谢点赞支持下哈 