
我想,成为一个架构师!!!
【第六章:缓存架构】
【第七章:架构解耦】
【第八章:架构分层】
负载均衡、数据收集、服务发现、调用链跟踪。这些非业务的功能,一般是谁实现的呢?
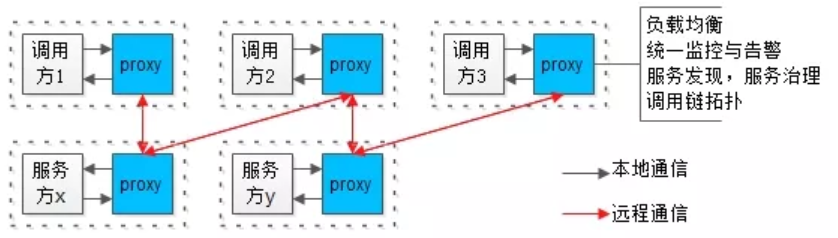

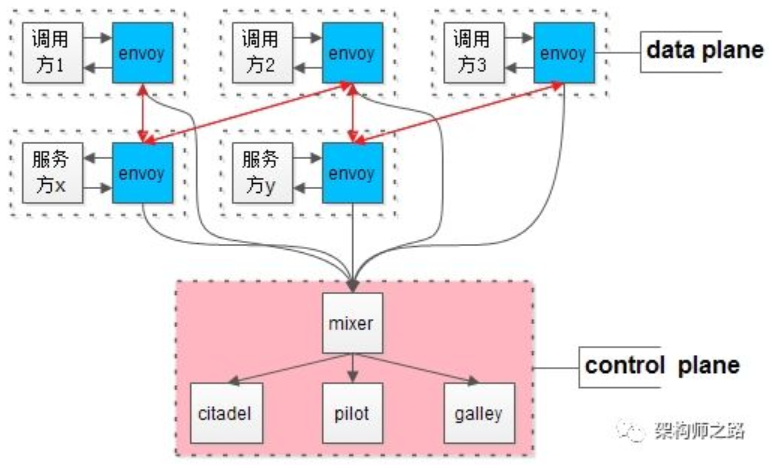
18次直播精华回看,有哪些内容?
(1)每秒100w请求,秒杀架构 (2)千万粉丝,feed架构 (3)千万同时在线,IM架构 (4)每秒100w检索,搜索引擎内核架构 (5)MQ内核细节 (6)RPC内核细节 (7)数据库架构 (8)多机房多活架构与细节 (9)分布式调用链追踪架构与细节 (10)3周自研自动化上线平台 (11)区块链中的架构理念 (12)数据库性能瓶颈定位 (13)反范式数据库设计 (14)微服务抽离与解耦 (15)经典架构10问 (16)微服务与数据库架构10问 (17)技术人职业发展规划 (18)InnoDB内核架构与细节
每次1-2小时不等,全部已放出。
第一阶:技术选型(5节,已放出)
第二阶:接入层架构(5节,已放出)
第三阶:极速性能优化(3节,已放出)
第四阶:微服务架构(7节,已放出)
第五阶:数据库架构(6节,已放出)
第六阶:缓存架构(7节,已放出)
第七阶:架构解耦(6节,已放出)
第八阶:架构分层(5节,已放出)
第九阶:架构进阶(6节,已放出)
把控住这些,应该能成为一名P8的架构师吧?

评论