
【CV】目标检测:常用名词与mAP评价指标的引出

计算机视觉|机器视觉|机器学习|深度学习
编者荐语
mAP(mean average precision)是目标检测中衡量识别精度的一种重要的人为设计的评价指标。文章首先给大家介绍几种常见的目标检测领域名词,然后逐步引出今天的主角mAP。
本文主要是为了引出mAP,其他过于浅显的地方大家可以在公众中搜索详细的文章(基本都会有的。。。如果没有我后期补上)了解。
IOU(Intersection over Union,交并比)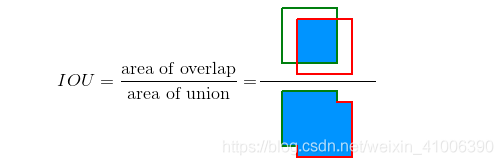
预测框(Prediction)与原标记框(Ground truth)之间的交集面积除以他们之间的并集面积。
Confidence Score
Confidence Score 置信度分数是一个分类器(Classifier)预测一个锚框(Anchor Box)中包含某个对象的概率(Probability)。通过设置Confidence Threshold置信度阈值可以过滤掉(不显示)小于threshold的预测对象。
Confidence Score和IoU共同决定一个检测结果(detection)是Ture Positive还是False Positive。
在目标检测中当一个检测结果(detection)被认为是True Positive时,需要同时满足下面三个条件:
1.Confidence Score > Confidence Threshold;
2.预测类别匹配(match)真实值(Ground truth)的类别;
3.预测边界框(Bounding box)的IoU大于设定阈值。
不满足条件2或条件3,则认为是False Positive。
当对应同一个真值有多个预测结果时(In case multiple predictions correspond to the same ground-truth),只有最高置信度分数的预测结果被认为是True Positive,其余被认为是False Positive。
正样本&负样本
对于分类问题:正样本是我们想要正确分类出的类别样本,而负样本原则上是可以选择任意非正样本的样本,但应考虑实际应用场景加以选择;
对于检测问题:常见的两阶段检测框架,一般会按照一定规则生成一些预测框Anchor boxes,从中选择一部分作为正样本,一部分作为负样本,其余部分则进行舍弃处理,虽然在不同的框架里有不同的选择策略,但大多都是根据IOU来决定的(通常情况下正样本只有一个,负样本则有许多。CNN一般0.5以上则认为是正样本);一阶段检测框架同上。
TP、FP、FN与TN(混淆矩阵(confusion matrix)中得到的分类指标)
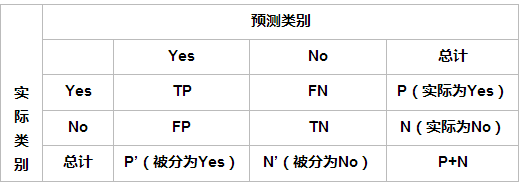
TP(True Positives):预测框与Ground truth(“数据真实值”,物体的类别及其真实边界框)之间的IOU大于阈值(一般取0.5)的个数(同一Ground Truth只计算一次);
FP(False Positives):预测框与Ground truth之间的IOU小于等于阈值的个数;
FN(False Negatives):应该有Ground truth,但未被检测出的个数。
理论上剩余部分则为TN(True Negative)。
P.S.因为在一般的目标检测中,没有真正的负例之说。自然也不存在TN。
Accuracy(ACC,正确率)、Precision(P,)与Recall (R,查全率)
正确率表示:实际为正样本被预测为正样本个数占所有样本个数的比例,公式为:
Accuracy=TP/(TP+FP+TN+FN);
查准率表示:实际为正样本被预测为正样本个数占所有被预测为正样本个数的比例,公式为:
Precision = TP/(TP+FP);
查全率表示:实际为正样本被预测为正样本个数占所有正样本个数的比例,公式为:
Recall = TP/(TP+FN)。
从上面的公式中可以看出,理想情况下我们希望P(Precision)与R(Recall)的值越高越好,但某些情况下P与R的值却是矛盾的。不同的情况下对P与R的偏重不同,可以引入F1-Measure或者绘制P-R曲线来进行综合考虑。
F-Measure(F-Score)评价指标
F-Measure:
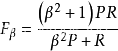
其中:β是参数,P是准确率,R是召回率。
F-Measure是精准率(查准率,Precision)和召回率(查全率,Recall)的加权调和平均,是IR(信息检索)领域的常用的一个评价标准,常用于评价分类模型的好坏。
当参数β=1时,变成F1-Measure:
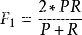
在不同的情况下,对精准率和召回率的偏重是不一样的,可以通过调节参数β的值使F-Measure满足我们的偏重要求。
下面分析一下参数β(取值范围0-正无穷)对F-Measure的影响。
当参数β=0,F=P,退化为精准率;
当参数β>1时,召回率有更大影响,可以考虑为,β无穷大时,分母中的R和分子中的1都可忽略不计,则F=R,只有召回率起作用;
当参数0<β<1时,精准率有更大影响,可以考虑为,β无限接近0时,分母中的β2P和分子中的β2都可忽略不计,则F=P,只有精准率起作用。
P-R曲线
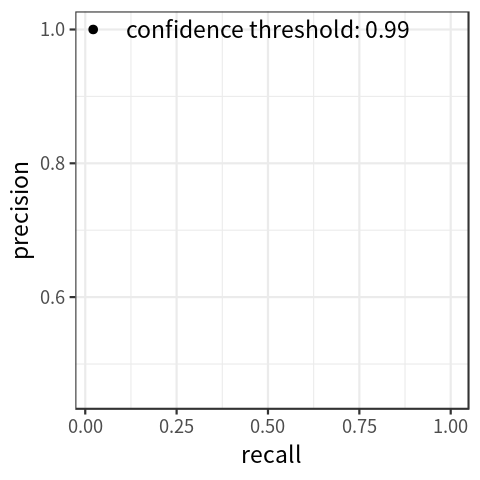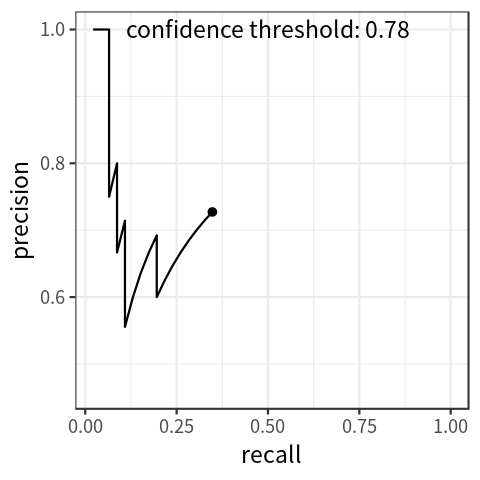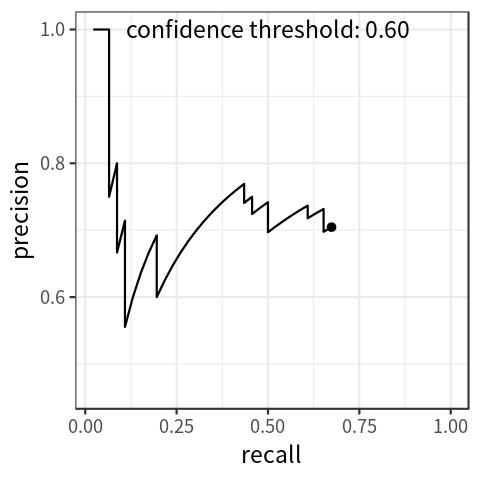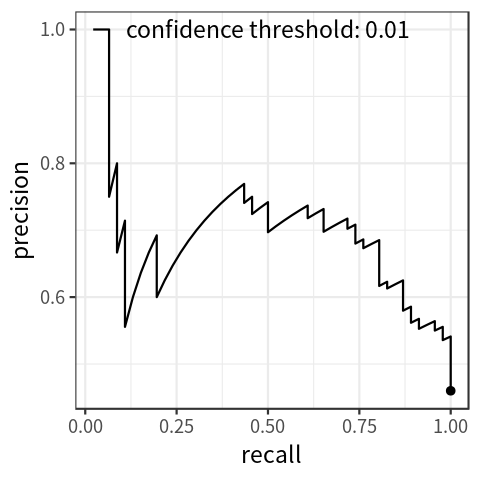
纵坐标为Precision,横坐标为Recall。Precision-Recall曲线可以衡量目标检测模型的好坏,但不便于模型和模型之间比较,所以我们引入了P-R曲线以解决此类问题。
改变不同的置信度阈值,可以获得多对Precision和Recall值,Recall值放X轴,Precision值放Y轴,可以画出一个Precision-Recall曲线,简称P-R曲线。
AP(Average precision)
根据2010年后的新标准,在Precision-Recall曲线基础上,通过计算每一个recall值对应的Precision值的平均值,可以获得一个数值形式(numerical metric)的评估指标:AP(Average Precision),用于衡量的是训练出来的模型在感兴趣的类别上的检测能力的好坏。
在计算AP前,为了平滑P-R曲线,减少曲线抖动的影响,首先对P-R曲线进行插值(interpolation)。
给定某个recall值r,用于插值的P_interp为下一个recall值r’,与当前r值之间的最大的Precision值。
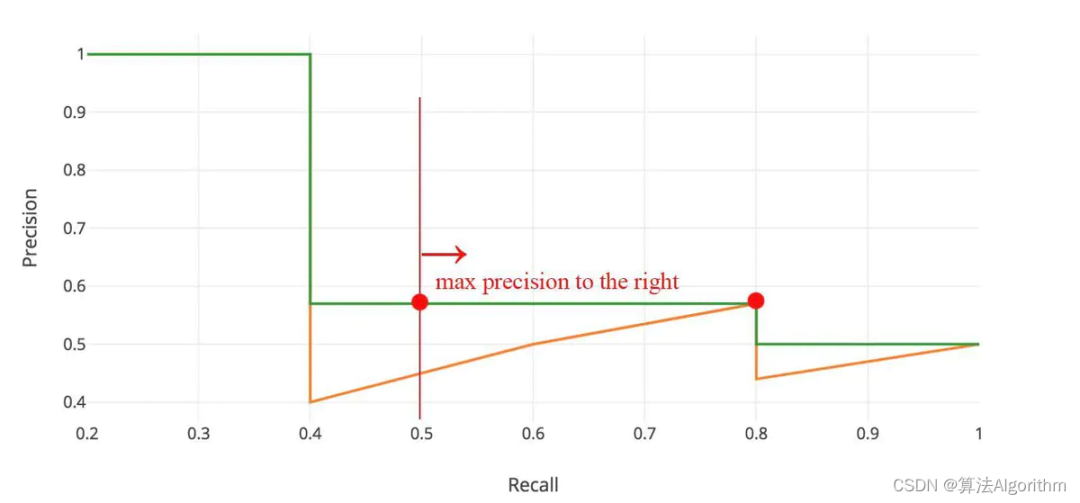
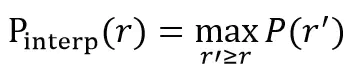
插值效果动图如下图所示:
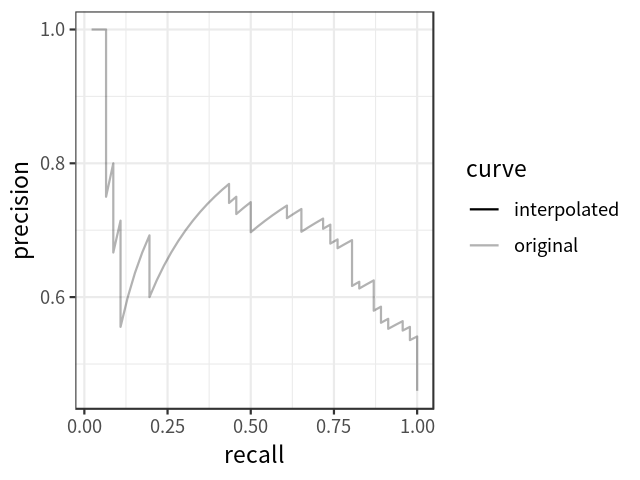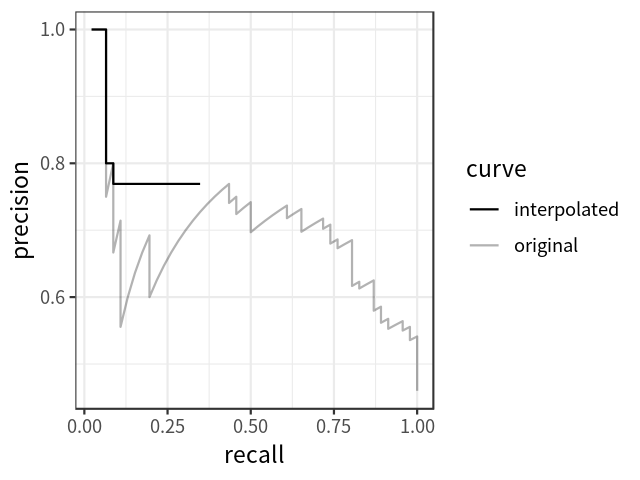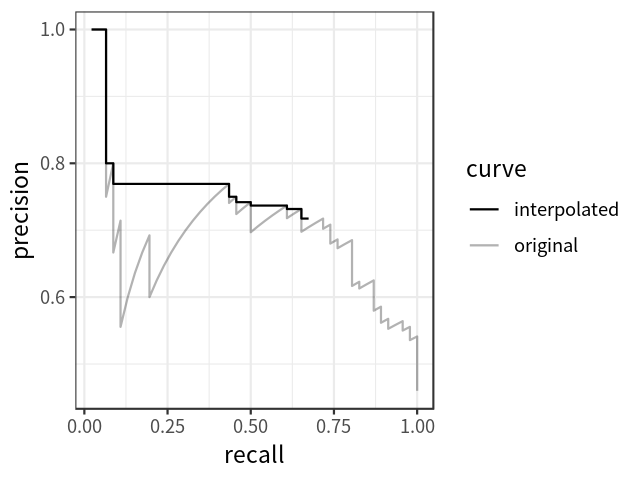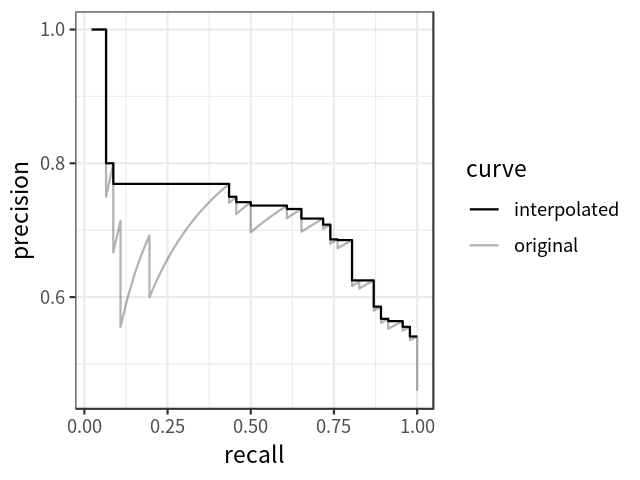
根据新标准,AP计算也可以定义为经过插值的precision-recall曲线、X轴与Y轴围成的多边形的面积。这种方式称为:AUC (Area under curve)
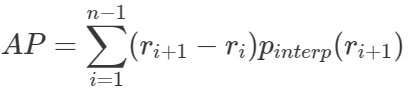
r1,r2,…,rn是按升序排列的Precision插值段第一个插值处对应的recall值。
mAP(Mean Average Precision)
多个类别的目标检测中,每一个类别都可以绘制一条P-R曲线,各类别AP的均值(即所有类别的AP和/类别数目)即是mAP,mAP衡量的是训练出来的模型在所有类别上的检测能力的好坏。
假设有K种类别,K>1,那么mAP的计算公式为:
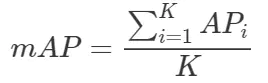
总结
mAP曾主要针对COCO数据集,AP曾主要针对VOC数据集,二者都属于人为定义的评价指标,初学者不必深究为何如此设计,先大致了解他们的主要作用,随着严重的深入,认识自然会逐渐清晰。
—THE END—
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: