点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:机器之心
世界上从来不缺少抠图工具,但始终缺少更完美的抠图工具(尤其是对于手残党来说)。

在传统年代,人们能想到最精准的抠图方法,大概是 Photoshop 之类的专业图像处理软件,显然这种处理方式会很繁琐。随着人工智能技术的发展,从业者开始尝试将最先进的机器学习技术融入到图像处理工作之中。这些开源算法最终变成了各种各样的在线抠图程序,最重要的是——它们的操作方法非常简单且完全免费。
比如「Remove.bg」,你只需要上传图片,网站就能识别其中的主体并去除背景,最终返回一张透明背景的 PNG 格式图片。尽管在前景与背景之间边界处理上存在瑕疵,但借助 AI 来抠图确实比自己动手要便捷,不是吗?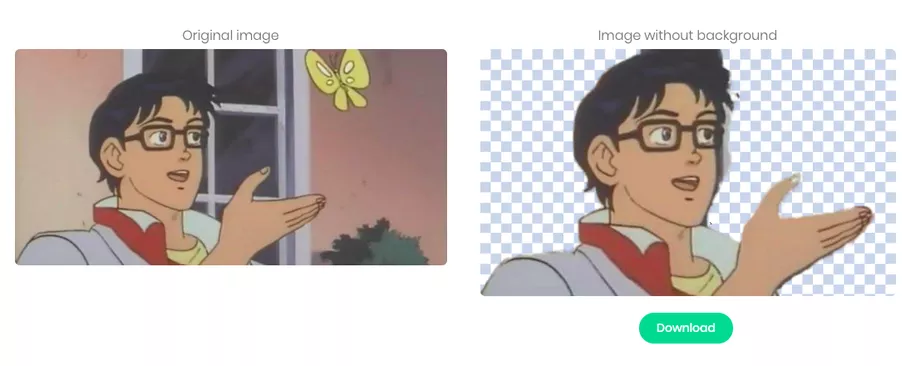
网站地址:https://www.remove.bg/近日,一款名为「ObjectCut」的图像处理新工具进入了大家的视野。你甚至不需事先将图片下载到本地,只需要输入图片网址,即可得到一张去除背景后的图片。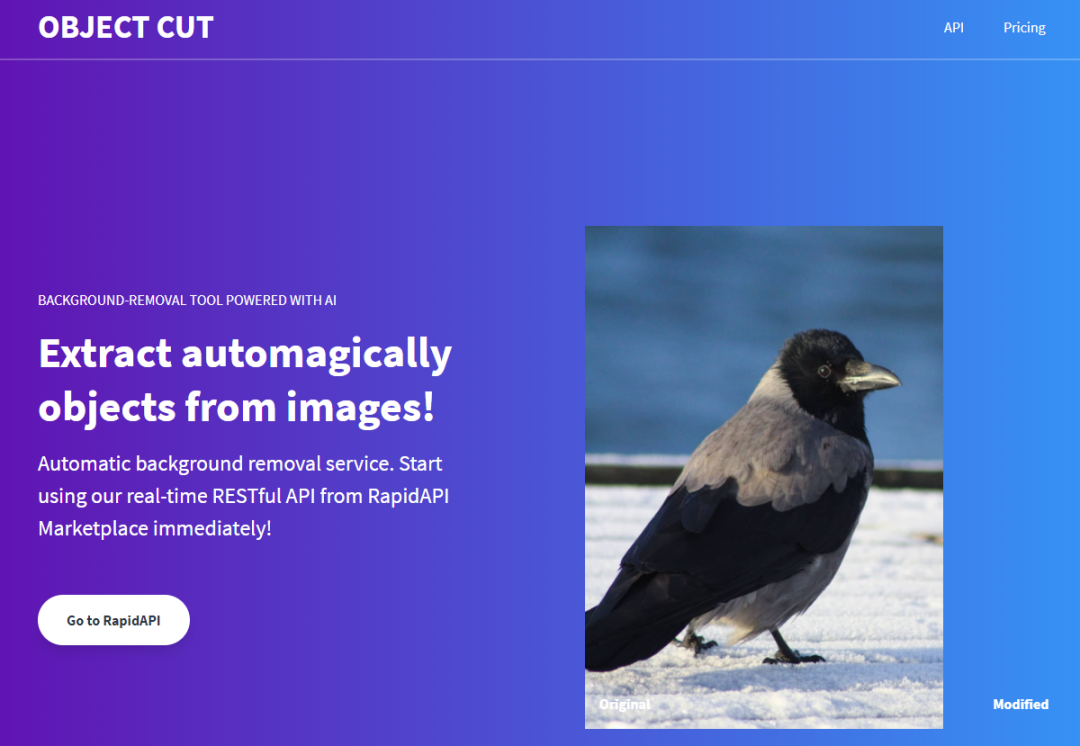
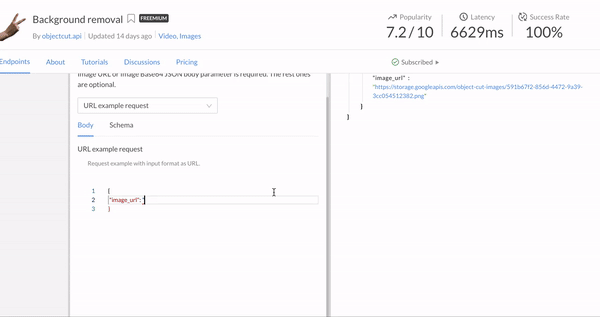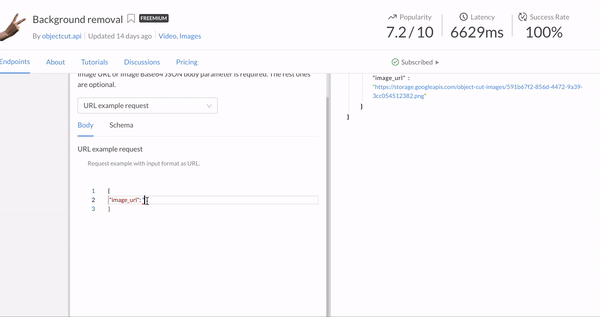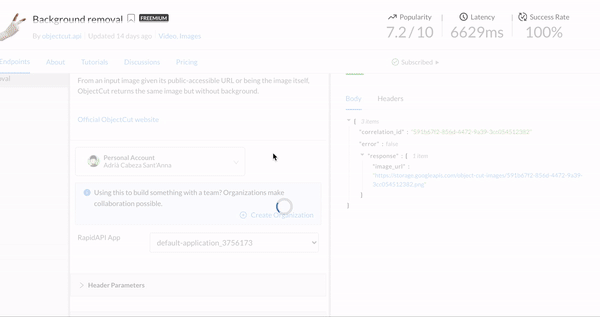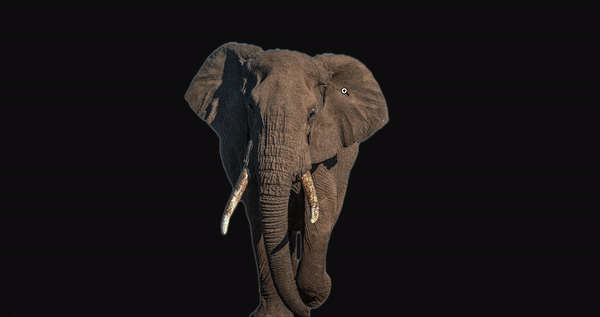
项目作者表示,这一工具所使用方法基于 CVPR 2019 论文《BASNet: Boundary-Aware Salient Object Detection》,并使用了一些相关的公开数据集来进行训练,包括 ECSSD、SOD、DUTS 等。
论文地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Qin_BASNet_Boundary-Aware_Salient_Object_Detection_CVPR_2019_paper.pdf巧合的是,前段时间在社交网络上大火的「隔空移物」神器 AR Cut & Paste,也是基于 BASNet 来执行显著目标检测和背景移除的,不管是盆栽、衣服还是书本,可见即可拷,一键操作就能将任何主体挪进 Photoshop 变为图像素材。深度卷积神经网络已经被用于显著目标检测(Salient object detection),并获得了 SOTA 的性能。但先前研究的重点大多集中在区域准确率而非边界质量上。因此,在本文中,来自加拿大阿尔伯塔大学的研究者提出了一种预测优化架构 BASNet,以及一种用于边界感知显著目标检测(Boundary-Aware Salient object detection)的新型混合损失。论文的第一作者秦雪彬曾就读于山东农业大学和北京大学,现在是阿尔伯塔大学的博士后研究员。具体而言,该架构由密集监督的编码器 - 解码器网络和残差优化模块组成。它们分别负责显著性预测和显著图优化。混合损失通过集合二进制交叉熵(Binary Cross Entropy, BCE)、结构相似性(Structural SIMilarity, SSIM)和交并比(Intersectionover-Union, IoU)损失,指导网络学习输入图像和真值(ground-truth)之间的转换。借助于混合损失,预测优化架构能够有效地分割显著目标区域,并准确地预测具有清晰边界的精细结构。在六个公开数据集上的实验结果表明,无论是在区域评估还是在边界评估方面,该研究提出的方法都优于当前 SOTA 方法。如下图 2 所示,本研究提出的 BASNet 包含两个模块,分别是预测模块(Predict Module)和残差优化模块(Residual Refinement Module, RRM)。预测模块是一个类 U-Net 的密集监督式编码器 - 解码器网络,它学习预测出自输入图像的显著图;多尺度残差精炼模块通过学习显著图和真值之间的残差来优化预测模块得到的显著图。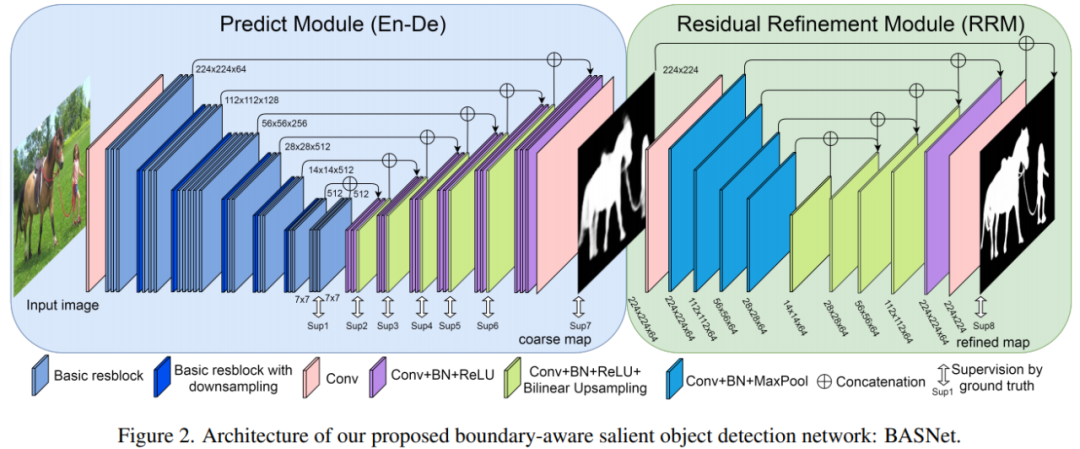
受 U-Net[57] 和 SegNet[2] 的启发,研究者在设计中将显著目标预测模块作为编码器 - 解码器网络,因为这种架构能够同时捕获高级全局上下文和低级细节。为了减少过拟合,每个解码器阶段的最后一层都受到了 HED[67] 启发的真值的监督。编码器部分具有一个输入卷积层和六个由基本残差块组成的阶段。输入卷积层和前四个阶段均采用 ResNet-34[16]。优化模块(RM)[22, 6] 通常被设计成残差块,通过学习显著图和真值之间的残差 S_residual 来细化预测的粗略显著图 S_coarse,其中: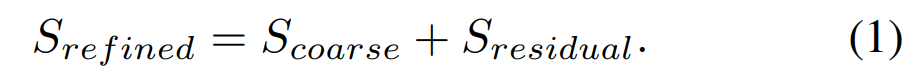
在提出优化模块之前,研究者定义了术语「粗略(coarse)」。在此,粗略包含两方面的意思:一种是模糊和有噪声的边界(如下图 3(b) 中 one-dimension(1D) 所示)。另一种情况是不均匀预测的区域概率(如图 3(c) 所示)。实际预测的粗略显著图通常包含两种情况(见图 3(d))。如下图 4(a) 所示,基于局部上下文的残差细化模块(RRM LC)最初是用于边界优化。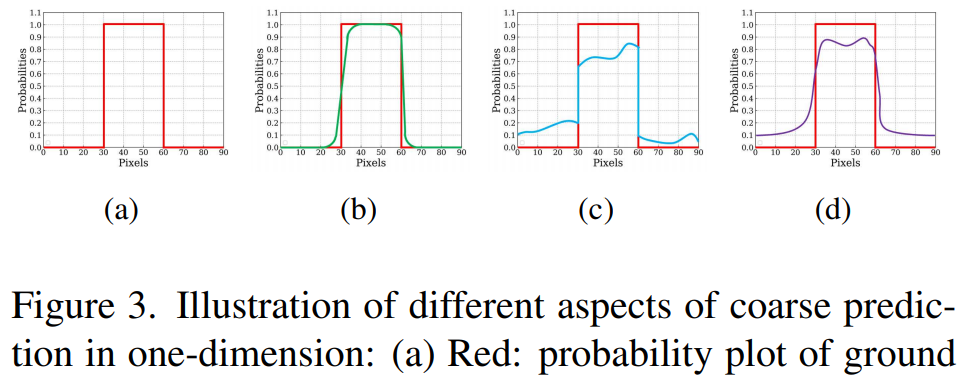
为了在粗略显著图中同时优化区域和边界,研究者提出了一种新的残差优化模块,它采用残差编码器 - 解码器架构 RRM_ Ours(如上图 2 和下图 4(c) 所示)。RRM_Ours 的主要架构与预测模块相似,但更加简单,包含输入层、编码器、桥、解码器和输出层。与预测模块不同的是,它的编码器和解码器都有 4 个阶段,每个阶段都只有一个卷积层。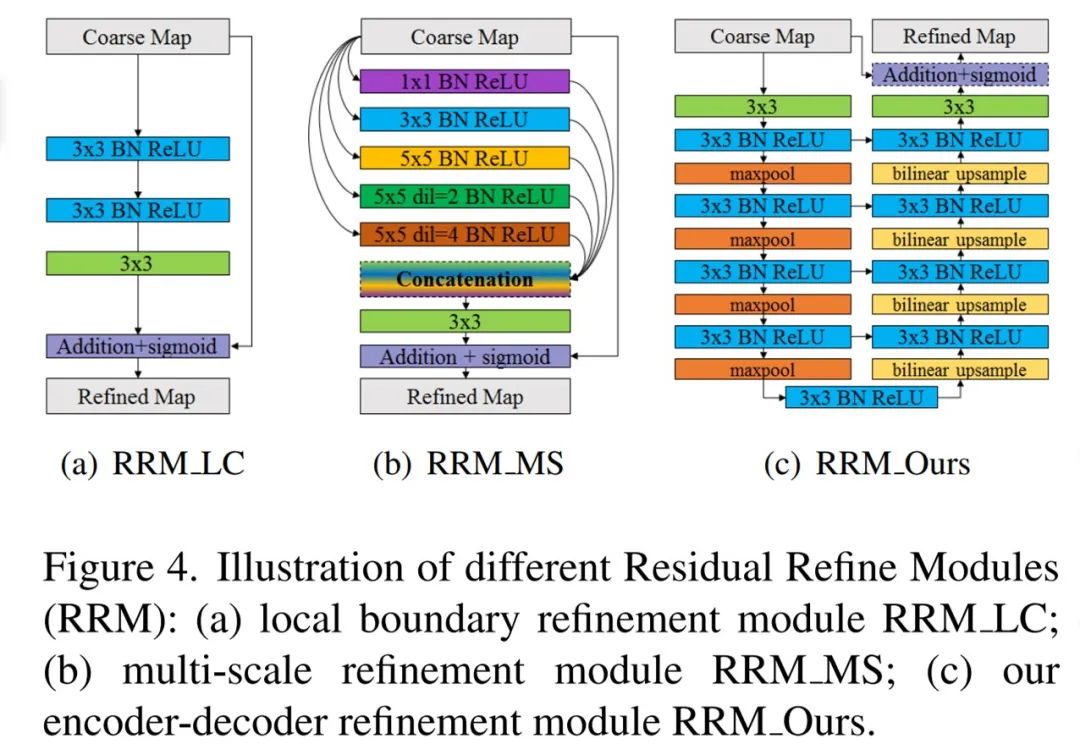
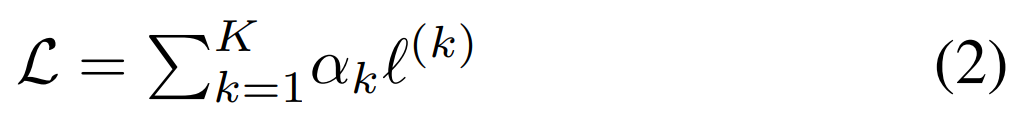
为了获得高质区域分割和清晰边界,研究者提出将 ℓ^ (k) 定义为一个混合损失: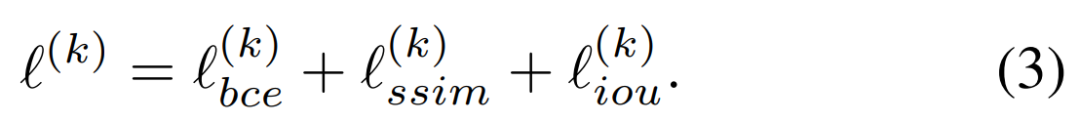
其中,ℓ^ (k)_ bce 表示 BCE 损失,ℓ ^(k)_ ssim 表示 SSIM 损失, ℓ ^(k)_ iou 表示 IoU 损失,这三种损失的影响如下图 5 所示: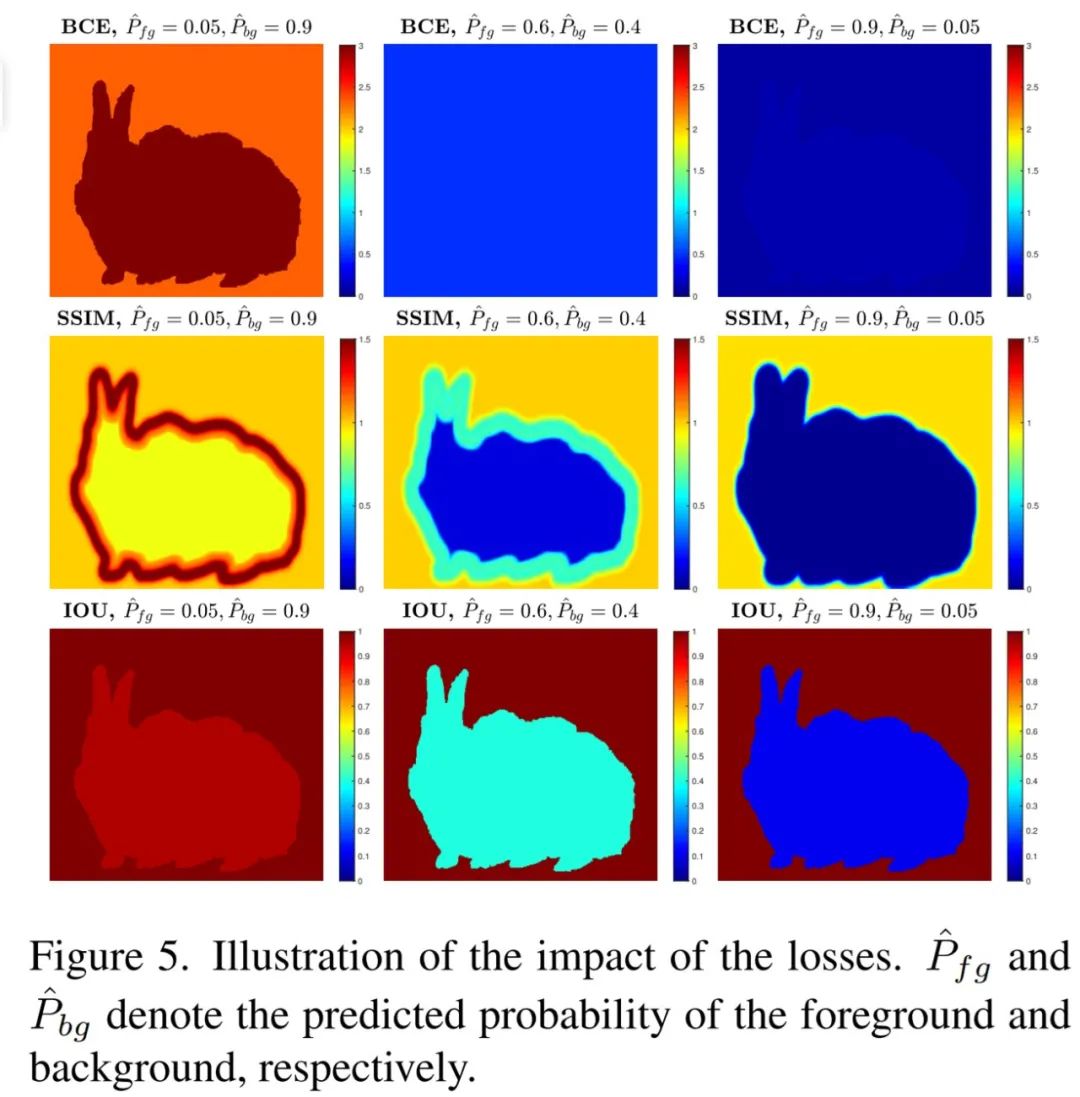
研究者在 6 个常用的基准数据集上对该方法展开评估,它们分别为 SOD、ECSSD、DUT-OMRON、PASCAL-S、HKU-IS 和 DUTS。实验采用的评估指标有 4 种,分别为精确率 - 召回率(Rrecision-Recall, PR)曲线、F 度量(F-measure)、平均绝对误差(Mean Absolute Error, MAE)和 relaxed F-measure of boundary(relaxF^b_β)。研究者首先验证了模型中每个关键组件的有效性。控制变量研究包含两部分内容:架构和损失,并且相关实验在 ECSSD 数据集上展开。下表 1 展示了控制变量研究的结果。可以看到,BASNet 架构在这些配置下实现了最佳性能: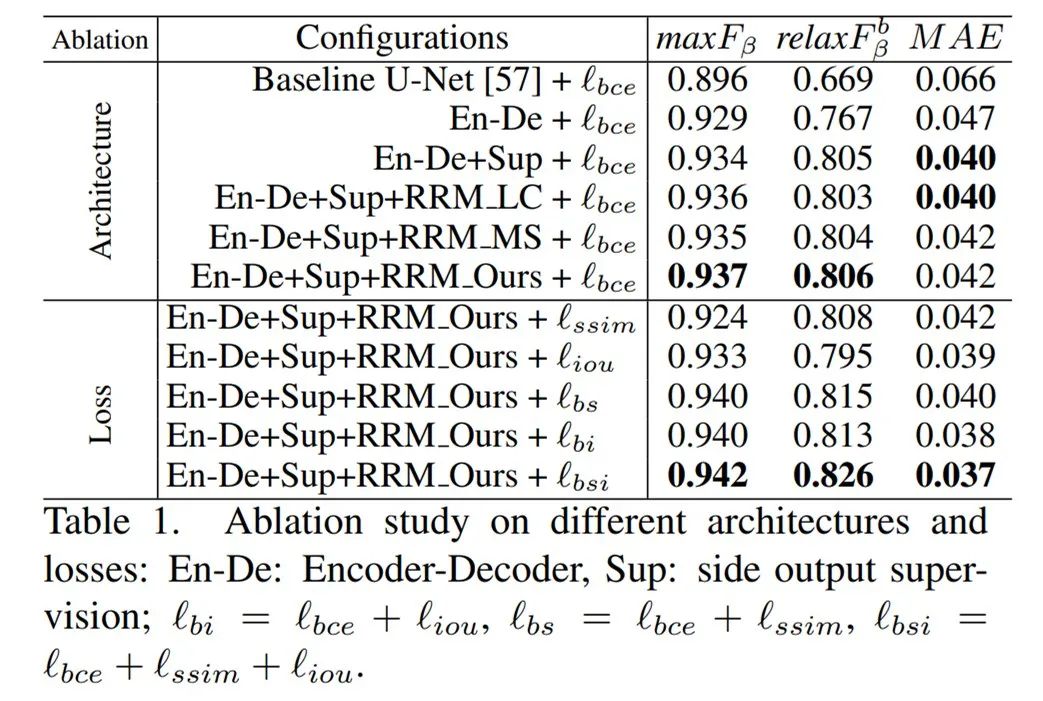
为了进一步阐释损失的定性效果,研究者在不同的损失设置下对 BASNet 进行训练,结果如下图 7 所示。很明显,本研究提出的混合损失取得了非常好的定性结果。
此外,为了评估分割显著性目标(salient object)的质量,研究者在图 6 中展示了 ECSSD、DUT-OMRON、PASCAL-S、HKU-IS 和 DUTS-TE 等 5 个最大数据集的 PR 曲线和 F-measure 曲线。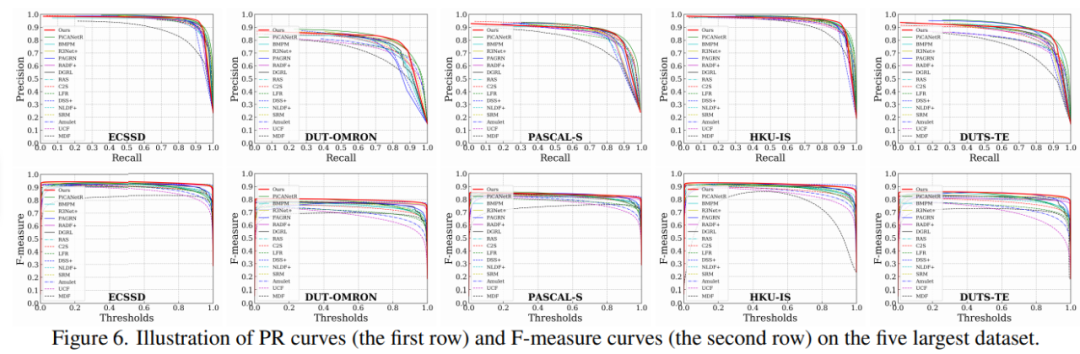
如下表 2 所示,研究者展示了 BASNet 与其他 15 种方法在 SOD、ECSSD 等 6 个数据集上的最大 F-measure(maxF_β)、relaxed boundary F-measure(relaxF^b_β)和 MAE 结果比较: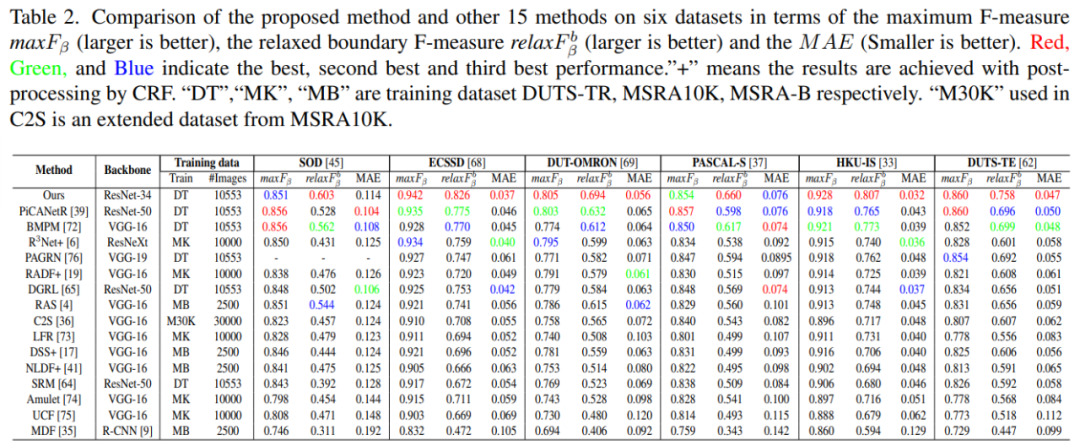
最后,为了进一步阐释 BASNet 的优越性能,研究者在下图 8 中展示了与其他 7 种同类方法的定性比较结果,可以看到,BASNet 可以对不同挑战性场景中的显著性目标实现准确分割。
下载1:动手学深度学习
在「AI算法与图像处理」公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
在「AI算法与图像处理」公众号后台回复:OpenCV实战项目20讲,即可下载20个有趣的OpenCV实战项目

